Copyright © 2010-2014 Linux Foundation
Permission is granted to copy, distribute and/or modify this document under the terms of the Creative Commons Attribution-Share Alike 2.0 UK: England & Wales as published by Creative Commons.
Note
For the latest version of this manual associated with this Yocto Project release, see the Yocto Project Quick Start from the Yocto Project website.Abstract
Welcome to the Yocto Project! The Yocto Project is an open-source collaboration project focused on embedded Linux developers. Among other things, the Yocto Project uses a build system based on the Poky project to construct complete Linux images. The Poky project, in turn, draws from and contributes back to the OpenEmbedded project.
If you don't have a system that runs Linux and you want to give the Yocto Project a test run, you might consider using the Yocto Project Build Appliance. The Build Appliance allows you to build and boot a custom embedded Linux image with the Yocto Project using a non-Linux development system. See the Yocto Project Build Appliance for more information.
On the other hand, if you know all about open-source development, Linux development environments, Git source repositories and the like and you just want some quick information that lets you try out the Yocto Project on your Linux system, skip right to the "Super User" section at the end of this quick start.
For the rest of you, this short document will give you some basic information about the environment and let you experience it in its simplest form. After reading this document, you will have a basic understanding of what the Yocto Project is and how to use some of its core components. This document steps you through a simple example showing you how to build a small image and run it using the Quick EMUlator (QEMU emulator).
For more detailed information on the Yocto Project, you should check out these resources:
Website: The Yocto Project Website provides the latest builds, breaking news, full development documentation, and a rich Yocto Project Development Community into which you can tap.
FAQs: Lists commonly asked Yocto Project questions and answers. You can find two FAQs: Yocto Project FAQ on a wiki, and the "FAQ" chapter in the Yocto Project Reference Manual.
Developer Screencast: The Getting Started with the Yocto Project - New Developer Screencast Tutorial provides a 30-minute video for the user new to the Yocto Project but familiar with Linux build systems.
The Yocto Project through the OpenEmbedded build system provides an open source development environment targeting the ARM, MIPS, PowerPC and x86 architectures for a variety of platforms including x86-64 and emulated ones. You can use components from the Yocto Project to design, develop, build, debug, simulate, and test the complete software stack using Linux, the X Window System, GNOME Mobile-based application frameworks, and Qt frameworks.
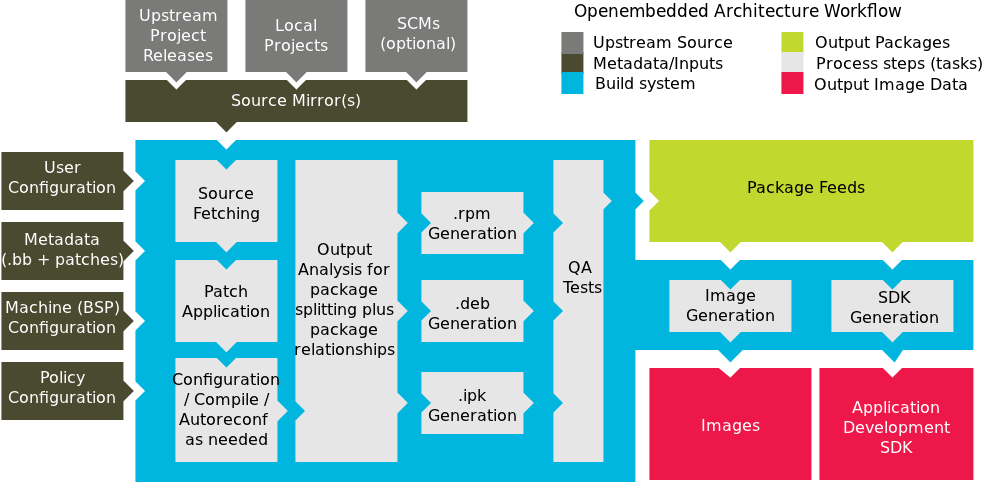 |
The Yocto Project Development Environment
Here are some highlights for the Yocto Project:
Provides a recent Linux kernel along with a set of system commands and libraries suitable for the embedded environment.
Makes available system components such as X11, GTK+, Qt, Clutter, and SDL (among others) so you can create a rich user experience on devices that have display hardware. For devices that don't have a display or where you wish to use alternative UI frameworks, these components need not be installed.
Creates a focused and stable core compatible with the OpenEmbedded project with which you can easily and reliably build and develop.
Fully supports a wide range of hardware and device emulation through the QEMU Emulator.
The Yocto Project can generate images for many kinds of devices. However, the standard example machines target QEMU full-system emulation for x86, x86-64, ARM, MIPS, and PPC-based architectures as well as specific hardware such as the Intel® Desktop Board DH55TC. Because an image developed with the Yocto Project can boot inside a QEMU emulator, the development environment works nicely as a test platform for developing embedded software.
Another important Yocto Project feature is the Sato reference User Interface. This optional GNOME mobile-based UI, which is intended for devices with restricted screen sizes, sits neatly on top of a device using the GNOME Mobile Stack and provides a well-defined user experience. Implemented in its own layer, it makes it clear to developers how they can implement their own user interface on top of a Linux image created with the Yocto Project.
You need these things to develop in the Yocto Project environment:
A host system running a supported Linux distribution (i.e. recent releases of Fedora, openSUSE, CentOS, Debian, and Ubuntu). If the host system supports multiple cores and threads, you can configure the Yocto Project build system to decrease the time needed to build images significantly.
The right packages.
A release of the Yocto Project.
The Yocto Project team is continually verifying more and more Linux distributions with each release. In general, if you have the current release minus one of the following distributions you should have no problems.
Ubuntu
Fedora
openSUSE
CentOS
Debian
For a more detailed list of distributions that support the Yocto Project, see the "Supported Linux Distributions" section in the Yocto Project Reference Manual.
The OpenEmbedded build system should be able to run on any modern distribution that has the following versions for Git, tar, and Python.
Git 1.7.5 or greater
tar 1.24 or greater
Python 2.7.3 or greater excluding Python 3.x, which is not supported.
Earlier releases of Python are known to not work and the system does not support Python 3 at this time. If your system does not meet any of these three listed version requirements, you can take steps to prepare the system so that you can still use the build system. See the "Required Git, tar, and Python Versions" section in the Yocto Project Reference Manual for information.
This document assumes you are running one of the previously noted distributions on your Linux-based host systems.
Note
If you attempt to use a distribution not in the above list, you may or may not have success. Yocto Project releases are tested against the stable Linux distributions listed in the "Supported Linux Distributions" section of the Yocto Project Reference Manual. If you encounter problems, please go to Yocto Project Bugzilla and submit a bug. We are interested in hearing about your experience.
Packages and package installation vary depending on your development system and on your intent. For example, if you want to build an image that can run on QEMU in graphical mode (a minimal, basic build requirement), then the number of packages is different than if you want to build an image on a headless system or build out the Yocto Project documentation set. Collectively, the number of required packages is large if you want to be able to cover all cases.
Note
In general, you need to have root access and then install the required packages. Thus, the commands in the following section may or may not work depending on whether or not your Linux distribution hassudo installed.
The next few sections list, by supported Linux Distributions, the required packages needed to build an image that runs on QEMU in graphical mode (e.g. essential plus graphics support).
For lists of required packages for other scenarios, see the "Required Packages for the Host Development System" section in the Yocto Project Reference Manual.
The essential and graphical support packages you need for a supported Ubuntu or Debian distribution are shown in the following command:
$ sudo apt-get install gawk wget git-core diffstat unzip texinfo gcc-multilib \
build-essential chrpath libsdl1.2-dev xterm
The essential and graphical packages you need for a supported Fedora distribution are shown in the following command:
$ sudo yum install gawk make wget tar bzip2 gzip python unzip perl patch \
diffutils diffstat git cpp gcc gcc-c++ glibc-devel texinfo chrpath \
ccache perl-Data-Dumper perl-Text-ParseWords SDL-devel xterm
The essential and graphical packages you need for a supported OpenSUSE distribution are shown in the following command:
$ sudo zypper install python gcc gcc-c++ git chrpath make wget python-xml \
diffstat texinfo python-curses patch libSDL-devel xterm
The essential and graphical packages you need for a supported CentOS distribution are shown in the following command:
$ sudo yum install gawk make wget tar bzip2 gzip python unzip perl patch \
diffutils diffstat git cpp gcc gcc-c++ glibc-devel texinfo chrpath SDL-devel xterm
Note
Depending on the CentOS version you are using, other requirements and dependencies might exist. For details, you should look at the CentOS sections on the Poky/GettingStarted/Dependencies wiki page.
You can download the latest Yocto Project release by going to the Yocto Project website clicking "Downloads" in the navigation pane to the left to view all available Yocto Project releases. Current and archived releases are available for download to the right. Nightly and developmental builds are also maintained at http://autobuilder.yoctoproject.org/nightly/. However, for this document a released version of Yocto Project is used.
You can also get the Yocto Project files you need by setting up (cloning in Git terms)
a local copy of the poky Git repository on your host development
system.
Doing so allows you to contribute back to the Yocto Project project.
For information on how to get set up using this method, see the
"Yocto
Project Release" item in the Yocto Project Development Manual.
Now that you have your system requirements in order, you can give the Yocto Project a try. This section presents some steps that let you do the following:
Build an image and run it in the QEMU emulator
Use a pre-built image and run it in the QEMU emulator
In the development environment you will need to build an image whenever you change hardware support, add or change system libraries, or add or change services that have dependencies.
Building an Image
Use the following commands to build your image. The OpenEmbedded build process creates an entire Linux distribution, including the toolchain, from source.
Note
The build process using Sato currently consumes about 50GB of disk space. To allow for variations in the build process and for future package expansion, we recommend having at least 100GB of free disk space.
Note
By default, the build process searches for source code using a pre-determined order through a set of locations. If you encounter problems with the build process finding and downloading source code, see the "How does the OpenEmbedded build system obtain source code and will it work behind my firewall or proxy server?" in the Yocto Project Reference Manual.
$ wget http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/poky-dora-10.0.2.tar.bz2
$ tar xjf poky-dora-10.0.2.tar.bz2
$ cd poky-dora-10.0.2
$ source oe-init-build-env
Tip
To help conserve disk space during builds, you can add the following statement
to your project's configuration file, which for this example
is poky-dora-10.0.2/build/conf/local.conf.
Adding this statement deletes the work directory used for building a package
once the package is built.
INHERIT += "rm_work"
In the previous example, the first command retrieves the Yocto Project release tarball from the source repositories using the
wgetcommand. Alternatively, you can go to the Yocto Project website's "Downloads" page to retrieve the tarball.The second command extracts the files from the tarball and places them into a directory named
poky-dora-10.0.2in the current directory.The third and fourth commands change the working directory to the Source Directory and run the Yocto Project
oe-init-build-envenvironment setup script. Running this script defines OpenEmbedded build environment settings needed to complete the build. The script also creates the Build Directory, which isbuildin this case and is located in the Source Directory. After the script runs, your current working directory is set to the Build Directory. Later, when the build completes, the Build Directory contains all the files created during the build.Note
For information on running a memory-resident BitBake, see theoe-init-build-env-memressetup script.
Take some time to examine your local.conf file
in your project's configuration directory, which is found in the Build Directory.
The defaults in that file should work fine.
However, there are some variables of interest at which you might look.
By default, the target architecture for the build is qemux86,
which produces an image that can be used in the QEMU emulator and is targeted at an
Intel® 32-bit based architecture.
To change this default, edit the value of the
MACHINE
variable in the configuration file before launching the build.
Another couple of variables of interest are the
BB_NUMBER_THREADS and the
PARALLEL_MAKE variables.
By default, these variables are commented out.
However, if you have a multi-core CPU you might want to uncomment
the lines and set both variables equal to twice the number of your
host's processor cores.
Setting these variables can significantly shorten your build time.
Another consideration before you build is the package manager used when creating
the image.
By default, the OpenEmbedded build system uses the RPM package manager.
You can control this configuration by using the
PACKAGE_CLASSESpackage*.bbclass"
section in the Yocto Project Reference Manual.
Continue with the following command to build an OS image for the target, which is
core-image-sato in this example.
For information on the -k option use the
bitbake --help command or see the
"BitBake" section in
the Yocto Project Reference Manual.
$ bitbake -k core-image-sato
Note
BitBake requires Python 2.6 or 2.7. For more information on this requirement, see the FAQ in the Yocto Project Reference Manual.
The final command runs the image:
$ runqemu qemux86
Note
Depending on the number of processors and cores, the amount or RAM, the speed of your Internet connection and other factors, the build process could take several hours the first time you run it. Subsequent builds run much faster since parts of the build are cached.
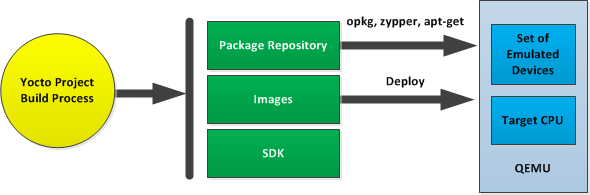
If hardware, libraries and services are stable, you can get started by using a pre-built binary of the filesystem image, kernel, and toolchain and run it using the QEMU emulator. This scenario is useful for developing application software.
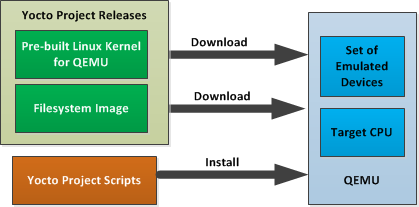
Using a Pre-Built Image
For this scenario, you need to do several things:
Install the appropriate stand-alone toolchain tarball.
Download the pre-built image that will boot with QEMU. You need to be sure to get the QEMU image that matches your target machine’s architecture (e.g. x86, ARM, etc.).
Download the filesystem image for your target machine's architecture.
Set up the environment to emulate the hardware and then start the QEMU emulator.
You can download a tarball installer, which includes the
pre-built toolchain, the runqemu
script, and support files from the appropriate directory under
http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/toolchain/.
Toolchains are available for 32-bit and 64-bit x86 development
systems from the i686 and
x86_64 directories, respectively.
The toolchains the Yocto Project provides are based off the
core-image-sato image and contain
libraries appropriate for developing against that image.
Each type of development system supports five or more target
architectures.
The names of the tarball installer scripts are such that a string representing the host system appears first in the filename and then is immediately followed by a string that represents the target architecture.
poky-eglibc-<host_system>-<image_type>-<arch>-toolchain-<release_version>.sh
Where:
<host_system> is a string representing your development system:
i686 or x86_64.
<image_type> is a string representing the image you wish to
develop a Software Development Toolkit (SDK) for use against.
The Yocto Project builds toolchain installers using the
following BitBake command:
bitbake core-image-sato -c do_populatesdk core-image-sato
<arch> is a string representing the tuned target architecture:
i586, x86_64, powerpc, mips, armv7a or armv5te
<release_version> is a string representing the release number of the
Yocto Project:
1.5.2, 1.5.2+snapshot
For example, the following toolchain installer is for a 64-bit
development host system and a i586-tuned target architecture
based off the SDK for core-image-sato:
poky-eglibc-x86_64-core-image-sato-i586-toolchain-1.5.2.sh
Toolchains are self-contained and by default are installed into
/opt/poky.
However, when you run the toolchain installer, you can choose an
installation directory.
The following command shows how to run the installer given a toolchain tarball for a 64-bit x86 development host system and a 32-bit x86 target architecture. You must change the permissions on the toolchain installer script so that it is executable.
The example assumes the toolchain installer is located in ~/Downloads/.
Note
If you do not have write permissions for the directory into which you are installing the toolchain, the toolchain installer notifies you and exits. Be sure you have write permissions in the directory and run the installer again.
$ ~/Downloads/poky-eglibc-x86_64-core-image-sato-i586-toolchain-1.5.2.sh
For more information on how to install tarballs, see the "Using a Cross-Toolchain Tarball" and "Using BitBake and the Build Directory" sections in the Yocto Project Application Developer's Guide.
You can download the pre-built Linux kernel suitable for running in the QEMU emulator from
http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/machines/qemu.
Be sure to use the kernel that matches the architecture you want to simulate.
Download areas exist for the five supported machine architectures:
qemuarm, qemumips, qemuppc,
qemux86, and qemux86-64.
Most kernel files have one of the following forms:
*zImage-qemu<arch>.bin
vmlinux-qemu<arch>.bin
Where:
<arch> is a string representing the target architecture:
x86, x86-64, ppc, mips, or arm.
You can learn more about downloading a Yocto Project kernel in the "Yocto Project Kernel" bulleted item in the Yocto Project Development Manual.
You can also download the filesystem image suitable for your target architecture from http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/machines/qemu. Again, be sure to use the filesystem that matches the architecture you want to simulate.
The filesystem image has two tarball forms: ext3 and
tar.
You must use the ext3 form when booting an image using the
QEMU emulator.
The tar form can be flattened out in your host development system
and used for build purposes with the Yocto Project.
core-image-<profile>-qemu<arch>.ext3
core-image-<profile>-qemu<arch>.tar.bz2
Where:
<profile> is the filesystem image's profile:
lsb, lsb-dev, lsb-sdk, lsb-qt3, minimal, minimal-dev, sato,
sato-dev, or sato-sdk. For information on these types of image
profiles, see the "Images" chapter in the Yocto Project
Reference Manual.
<arch> is a string representing the target architecture:
x86, x86-64, ppc, mips, or arm.
Before you start the QEMU emulator, you need to set up the emulation environment. The following command form sets up the emulation environment.
$ source /opt/poky/1.5.2/environment-setup-<arch>-poky-linux-<if>
Where:
<arch> is a string representing the target architecture:
i586, x86_64, ppc603e, mips, or armv5te.
<if> is a string representing an embedded application binary interface.
Not all setup scripts include this string.
Finally, this command form invokes the QEMU emulator
$ runqemu <qemuarch> <kernel-image> <filesystem-image>
Where:
<qemuarch> is a string representing the target architecture: qemux86, qemux86-64,
qemuppc, qemumips, or qemuarm.
<kernel-image> is the architecture-specific kernel image.
<filesystem-image> is the .ext3 filesystem image.
Continuing with the example, the following two commands setup the emulation
environment and launch QEMU.
This example assumes the root filesystem (.ext3 file) and
the pre-built kernel image file both reside in your home directory.
The kernel and filesystem are for a 32-bit target architecture.
$ cd $HOME
$ source /opt/poky/1.5.2/environment-setup-i586-poky-linux
$ runqemu qemux86 bzImage-qemux86.bin \
core-image-sato-qemux86.ext3
The environment in which QEMU launches varies depending on the filesystem image and on the target architecture. For example, if you source the environment for the ARM target architecture and then boot the minimal QEMU image, the emulator comes up in a new shell in command-line mode. However, if you boot the SDK image, QEMU comes up with a GUI.
Note
Booting the PPC image results in QEMU launching in the same shell in command-line mode.
This section [1] gives you a minimal description of how to use the Yocto Project to build images for a BeagleBoard xM starting from scratch. The steps were performed on a 64-bit Ubuntu 10.04 system.
Set up your Source Directory one of two ways:
Tarball: Use if you want the latest stable release:
$ wget http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/poky-dora-10.0.2.tar.bz2 $ tar xvjf poky-dora-10.0.2.tar.bz2Git Repository: Use if you want to work with cutting edge development content:
$ git clone git://git.yoctoproject.org/poky
The remainder of the section assumes the Git repository method.
You need some packages for everything to work. Rather than duplicate them here, look at the "The Packages" section earlier in this quick start.
From the parent directory your Source Directory, initialize your environment and provide a meaningful Build Directory name:
$ source poky/oe-init-build-env mybuilds
At this point, the mybuilds directory has been created for you
and it is now your current working directory.
If you don't provide your own directory name it defaults to build,
which is inside the Source Directory.
Initializing the build environment creates a conf/local.conf configuration file
in the Build Directory.
You need to manually edit this file to specify the machine you are building and to optimize
your build time.
Here are the minimal changes to make:
BB_NUMBER_THREADS = "8"
PARALLEL_MAKE = "-j 8"
MACHINE ?= "beagleboard"
Briefly, set BB_NUMBER_THREADS
and PARALLEL_MAKE to
twice your host processor's number of cores.
A good deal that goes into a Yocto Project build is simply
downloading all of the source tarballs.
Maybe you have been working with another build system
(OpenEmbedded or Angstrom) for which you have built up a sizable
directory of source tarballs.
Or, perhaps someone else has such a directory for which you have
read access.
If so, you can save time by adding statements to your
configuration file so that the build process checks local
directories first for existing tarballs before checking the
Internet.
Here is an efficient way to set it up in your
local.conf file:
SOURCE_MIRROR_URL ?= "file:///home/you/your-download-dir/"
INHERIT += "own-mirrors"
BB_GENERATE_MIRROR_TARBALLS = "1"
# BB_NO_NETWORK = "1"
In the previous example, the
BB_GENERATE_MIRROR_TARBALLS
variable causes the OpenEmbedded build system to generate tarballs
of the Git repositories and store them in the
DL_DIR
directory.
Due to performance reasons, generating and storing these tarballs
is not the build system's default behavior.
You can also use the
PREMIRRORS
variable.
For an example, see the variable's glossary entry in the
Yocto Project Reference Manual.
At this point, you need to select an image to build for the BeagleBoard xM. If this is your first build using the Yocto Project, you should try the smallest and simplest image:
$ bitbake core-image-minimal
Now you just wait for the build to finish.
Here are some variations on the build process that could be helpful:
Fetch all the necessary sources without starting the build:
$ bitbake -c fetchall core-image-minimalThis variation guarantees that you have all the sources for that BitBake target should you disconnect from the net and want to do the build later offline.
Specify to continue the build even if BitBake encounters an error. By default, BitBake aborts the build when it encounters an error. This command keeps a faulty build going:
$ bitbake -k core-image-minimal
Once you have your image, you can take steps to load and boot it on the target hardware.
[1] Kudos and thanks to Robert P. J. Day of CrashCourse for providing the basis for this "expert" section with information from one of his wiki pages.
 |
Copyright © 2010-2014 Linux Foundation
Permission is granted to copy, distribute and/or modify this document under the terms of the Creative Commons Attribution-Share Alike 2.0 UK: England & Wales as published by Creative Commons.
Note
For the latest version of this manual associated with this Yocto Project release, see the Yocto Project Development Manual from the Yocto Project website.| Revision History | |
|---|---|
| Revision 1.1 | 6 October 2011 |
| The initial document released with the Yocto Project 1.1 Release. | |
| Revision 1.2 | April 2012 |
| Released with the Yocto Project 1.2 Release. | |
| Revision 1.3 | October 2012 |
| Released with the Yocto Project 1.3 Release. | |
| Revision 1.4 | April 2013 |
| Released with the Yocto Project 1.4 Release. | |
| Revision 1.5 | October 2013 |
| Released with the Yocto Project 1.5 Release. | |
| Revision 1.5.1 | January 2014 |
| Released with the Yocto Project 1.5.1 Release. | |
| Revision 1.5.2 | May 2014 |
| Released with the Yocto Project 1.5.2 Release. | |
Welcome to the Yocto Project Development Manual! This manual provides information on how to use the Yocto Project to develop embedded Linux images and user-space applications that run on targeted devices. The manual provides an overview of image, kernel, and user-space application development using the Yocto Project. Because much of the information in this manual is general, it contains many references to other sources where you can find more detail. For example, you can find detailed information on Git, repositories, and open source in general in many places on the Internet. Another example specific to the Yocto Project is how to quickly set up your host development system and build an image, which you find in the Yocto Project Quick Start.
The Yocto Project Development Manual does, however, provide guidance and examples on how to change the kernel source code, reconfigure the kernel, and develop an application using the popular Eclipse™ IDE.
Note
By default, using the Yocto Project creates a Poky distribution. However, you can create your own distribution by providing key Metadata. A good example is Angstrom, which has had a distribution based on the Yocto Project since its inception. Other examples include commercial distributions like Wind River Linux, Mentor Embedded Linux, and ENEA Linux. See the "Creating Your Own Distribution" section for more information.The following list describes what you can get from this manual:
Information that lets you get set up to develop using the Yocto Project.
Information to help developers who are new to the open source environment and to the distributed revision control system Git, which the Yocto Project uses.
An understanding of common end-to-end development models and tasks.
Information about common development tasks generally used during image development for embedded devices.
Many references to other sources of related information.
This manual will not give you the following:
Step-by-step instructions when those instructions exist in other Yocto Project documentation: For example, the Yocto Project Application Developer's Guide contains detailed instructions on how to run the ADT Installer, which is used to set up a cross-development environment.
Reference material: This type of material resides in an appropriate reference manual. For example, system variables are documented in the Yocto Project Reference Manual.
Detailed public information that is not specific to the Yocto Project: For example, exhaustive information on how to use Git is covered better through the Internet than in this manual.
Because this manual presents overview information for many different topics, supplemental information is recommended for full comprehension. The following list presents other sources of information you might find helpful:
Yocto Project Website: The home page for the Yocto Project provides lots of information on the project as well as links to software and documentation.
Yocto Project Quick Start: This short document lets you get started with the Yocto Project and quickly begin building an image.
Yocto Project Reference Manual: This manual is a reference guide to the OpenEmbedded build system, which is based on BitBake. The build system is sometimes referred to as "Poky".
Yocto Project Application Developer's Guide: This guide provides information that lets you get going with the Application Development Toolkit (ADT) and stand-alone cross-development toolchains to develop projects using the Yocto Project.
Yocto Project Board Support Package (BSP) Developer's Guide: This guide defines the structure for BSP components. Having a commonly understood structure encourages standardization.
Yocto Project Linux Kernel Development Manual: This manual describes how to work with Linux Yocto kernels as well as provides a bit of conceptual information on the construction of the Yocto Linux kernel tree.
Yocto Project Profiling and Tracing Manual: This manual presents a set of common and generally useful tracing and profiling schemes along with their applications (as appropriate) to each tool.
Eclipse IDE Yocto Plug-in: A step-by-step instructional video that demonstrates how an application developer uses Yocto Plug-in features within the Eclipse IDE.
FAQ: A list of commonly asked questions and their answers.
Release Notes: Features, updates and known issues for the current release of the Yocto Project.
Hob: A graphical user interface for BitBake. Hob's primary goal is to enable a user to perform common tasks more easily.
Build Appliance: A virtual machine that enables you to build and boot a custom embedded Linux image with the Yocto Project using a non-Linux development system. For more information, see the Build Appliance page.
Bugzilla: The bug tracking application the Yocto Project uses. If you find problems with the Yocto Project, you should report them using this application.
Yocto Project Mailing Lists: To subscribe to the Yocto Project mailing lists, click on the following URLs and follow the instructions:
http://lists.yoctoproject.org/listinfo/yocto for a Yocto Project Discussions mailing list.
http://lists.yoctoproject.org/listinfo/poky for a Yocto Project Discussions mailing list about the OpenEmbedded build system (Poky).
http://lists.yoctoproject.org/listinfo/yocto-announce for a mailing list to receive official Yocto Project announcements as well as Yocto Project milestones.
http://lists.yoctoproject.org/listinfo for a listing of all public mailing lists on
lists.yoctoproject.org.
Internet Relay Chat (IRC): Two IRC channels on freenode are available for Yocto Project and Poky discussions:
#yoctoand#poky, respectively.OpenEmbedded: The build system used by the Yocto Project. This project is the upstream, generic, embedded distribution that the Yocto Project derives its build system (Poky) from and to which it contributes.
BitBake: The tool used by the OpenEmbedded build system to process project metadata.
BitBake User Manual: A comprehensive guide to the BitBake tool. If you want information on BitBake, see the user manual included in the
bitbake/doc/manualdirectory of the Source Directory.Quick EMUlator (QEMU): An open-source machine emulator and virtualizer.
This chapter introduces the Yocto Project and gives you an idea of what you need to get started. You can find enough information to set up your development host and build or use images for hardware supported by the Yocto Project by reading the Yocto Project Quick Start.
The remainder of this chapter summarizes what is in the Yocto Project Quick Start and provides some higher-level concepts you might want to consider.
The Yocto Project is an open-source collaboration project focused on embedded Linux development. The project currently provides a build system that is referred to as the OpenEmbedded build system in the Yocto Project documentation. The Yocto Project provides various ancillary tools for the embedded developer and also features the Sato reference User Interface, which is optimized for stylus driven, low-resolution screens.
You can use the OpenEmbedded build system, which uses BitBake, to develop complete Linux images and associated user-space applications for architectures based on ARM, MIPS, PowerPC, x86 and x86-64.
Note
By default, using the Yocto Project creates a Poky distribution. However, you can create your own distribution by providing key Metadata. See the "Creating Your Own Distribution" section for more information.While the Yocto Project does not provide a strict testing framework, it does provide or generate for you artifacts that let you perform target-level and emulated testing and debugging. Additionally, if you are an Eclipse™ IDE user, you can install an Eclipse Yocto Plug-in to allow you to develop within that familiar environment.
Here is what you need to use the Yocto Project:
Host System: You should have a reasonably current Linux-based host system. You will have the best results with a recent release of Fedora, openSUSE, Debian, Ubuntu, or CentOS as these releases are frequently tested against the Yocto Project and officially supported. For a list of the distributions under validation and their status, see the "Supported Linux Distributions" section in the Yocto Project Reference Manual and the wiki page at Distribution Support.
You should also have about 100 gigabytes of free disk space for building images.
Packages: The OpenEmbedded build system requires that certain packages exist on your development system (e.g. Python 2.6 or 2.7). See "The Packages" section in the Yocto Project Quick Start and the "Required Packages for the Host Development System" section in the Yocto Project Reference Manual for the exact package requirements and the installation commands to install them for the supported distributions.
Yocto Project Release: You need a release of the Yocto Project installed locally on your development system. This local area is referred to as the Source Directory and is created when you use Git to clone a local copy of the upstream
pokyrepository, or when you download an official release of the corresponding tarball.Working from a copy of the upstream repository allows you to contribute back into the Yocto Project or simply work with the latest software on a development branch. Because Git maintains and creates an upstream repository with a complete history of changes and you are working with a local clone of that repository, you have access to all the Yocto Project development branches and tag names used in the upstream repository.
Note
You can view the Yocto Project Source Repositories at http://git.yoctoproject.org/cgit.cgiTarball Extraction: If you are not going to contribute back into the Yocto Project, you can simply go to the Yocto Project Website, select the "Downloads" tab, and choose what you want. Once you have the tarball, just extract it into a directory of your choice.
For example, the following command extracts the Yocto Project 1.5.2 release tarball into the current working directory and sets up the local Source Directory with a top-level folder named
poky-dora-10.0.2:$ tar xfj poky-dora-10.0.2.tar.bz2This method does not produce a local Git repository. Instead, you simply end up with a snapshot of the release.
Git Repository Method: If you are going to be contributing back into the Yocto Project or you simply want to keep up with the latest developments, you should use Git commands to set up a local Git repository of the upstream
pokysource repository. Doing so creates a repository with a complete history of changes and allows you to easily submit your changes upstream to the project. Because you clone the repository, you have access to all the Yocto Project development branches and tag names used in the upstream repository.Note
You can view the Yocto Project Source Repositories at http://git.yoctoproject.org/cgit.cgiThe following transcript shows how to clone the
pokyGit repository into the current working directory. The command creates the local repository in a directory namedpoky. For information on Git used within the Yocto Project, see the "Git" section.$ git clone git://git.yoctoproject.org/poky Cloning into 'poky'... remote: Counting objects: 203728, done. remote: Compressing objects: 100% (52371/52371), done. remote: Total 203728 (delta 147444), reused 202891 (delta 146614) Receiving objects: 100% (203728/203728), 95.54 MiB | 308 KiB/s, done. Resolving deltas: 100% (147444/147444), done.For another example of how to set up your own local Git repositories, see this wiki page, which describes how to create both
pokyandmeta-intelGit repositories.
Yocto Project Kernel: If you are going to be making modifications to a supported Yocto Project kernel, you need to establish local copies of the source. You can find Git repositories of supported Yocto Project kernels organized under "Yocto Linux Kernel" in the Yocto Project Source Repositories at http://git.yoctoproject.org/cgit.cgi.
This setup can involve creating a bare clone of the Yocto Project kernel and then copying that cloned repository. You can create the bare clone and the copy of the bare clone anywhere you like. For simplicity, it is recommended that you create these structures outside of the Source Directory (usually
poky).As an example, the following transcript shows how to create the bare clone of the
linux-yocto-3.10kernel and then create a copy of that clone.Note
When you have a local Yocto Project kernel Git repository, you can reference that repository rather than the upstream Git repository as part of theclonecommand. Doing so can speed up the process.In the following example, the bare clone is named
linux-yocto-3.10.git, while the copy is namedmy-linux-yocto-3.10-work:$ git clone ‐‐bare git://git.yoctoproject.org/linux-yocto-3.10 linux-yocto-3.10.git Cloning into bare repository 'linux-yocto-3.10.git'... remote: Counting objects: 3364487, done. remote: Compressing objects: 100% (507178/507178), done. remote: Total 3364487 (delta 2827715), reused 3364481 (delta 2827709) Receiving objects: 100% (3364487/3364487), 722.95 MiB | 423 KiB/s, done. Resolving deltas: 100% (2827715/2827715), done.Now create a clone of the bare clone just created:
$ git clone linux-yocto-3.10.git my-linux-yocto-3.10-work Cloning into 'my-linux-yocto-3.10-work'... done.The
meta-yocto-kernel-extrasGit Repository: Themeta-yocto-kernel-extrasGit repository contains Metadata needed only if you are modifying and building the kernel image. In particular, it contains the kernel BitBake append (.bbappend) files that you edit to point to your locally modified kernel source files and to build the kernel image. Pointing to these local files is much more efficient than requiring a download of the kernel's source files from upstream each time you make changes to the kernel.You can find the
meta-yocto-kernel-extrasGit Repository in the "Yocto Metadata Layers" area of the Yocto Project Source Repositories at http://git.yoctoproject.org/cgit.cgi. It is good practice to create this Git repository inside the Source Directory.Following is an example that creates the
meta-yocto-kernel-extrasGit repository inside the Source Directory, which is namedpokyin this case:$ cd ~/poky $ git clone git://git.yoctoproject.org/meta-yocto-kernel-extras meta-yocto-kernel-extras Cloning into 'meta-yocto-kernel-extras'... remote: Counting objects: 727, done. remote: Compressing objects: 100% (452/452), done. remote: Total 727 (delta 260), reused 719 (delta 252) Receiving objects: 100% (727/727), 536.36 KiB | 102 KiB/s, done. Resolving deltas: 100% (260/260), done.Supported Board Support Packages (BSPs): The Yocto Project provides a layer called
meta-inteland it is maintained in its own separate Git repository. Themeta-intellayer contains many supported BSP Layers.Similar considerations exist for setting up the
meta-intellayer. You can get set up for BSP development one of two ways: tarball extraction or with a local Git repository. It is a good idea to use the same method that you used to set up the Source Directory. Regardless of the method you use, the Yocto Project uses the following BSP layer naming scheme:meta-<BSP_name>where
<BSP_name>is the recognized BSP name. Here are some examples:meta-crownbay meta-emenlow meta-n450See the "BSP Layers" section in the Yocto Project Board Support Package (BSP) Developer's Guide for more information on BSP Layers.
Tarball Extraction: You can download any released BSP tarball from the same "Downloads" page of the Yocto Project Website to get the Yocto Project release. Once on the "Download" page, look to the right of the page and scroll down to find the BSP tarballs.
Once you have the tarball, just extract it into a directory of your choice. Again, this method just produces a snapshot of the BSP layer in the form of a hierarchical directory structure.
Git Repository Method: If you are working with a local Git repository for your Source Directory, you should also use this method to set up the
meta-intelGit repository. You can locate themeta-intelGit repository in the "Yocto Metadata Layers" area of the Yocto Project Source Repositories at http://git.yoctoproject.org/cgit.cgi.Using Git to create a local clone of the upstream repository can be helpful if you are working with BSPs. Typically, you set up the
meta-intelGit repository inside the Source Directory. For example, the following transcript shows the steps to clonemeta-intel.$ cd ~/poky $ git clone git://git.yoctoproject.org/meta-intel.git Cloning into 'meta-intel'... remote: Counting objects: 7366, done. remote: Compressing objects: 100% (2491/2491), done. remote: Total 7366 (delta 3997), reused 7299 (delta 3930) Receiving objects: 100% (7366/7366), 2.31 MiB | 95 KiB/s, done. Resolving deltas: 100% (3997/3997), done.The same wiki page referenced earlier covers how to set up the
meta-intelGit repository.
Eclipse Yocto Plug-in: If you are developing applications using the Eclipse Integrated Development Environment (IDE), you will need this plug-in. See the "Setting up the Eclipse IDE" section for more information.
The build process creates an entire Linux distribution, including the toolchain, from source. For more information on this topic, see the "Building an Image" section in the Yocto Project Quick Start.
The build process is as follows:
Make sure you have set up the Source Directory described in the previous section.
Initialize the build environment by sourcing a build environment script.
Optionally ensure the
conf/local.confconfiguration file, which is found in the Build Directory, is set up how you want it. This file defines many aspects of the build environment including the target machine architecture through theMACHINEvariable, the development machine's processor use through theBB_NUMBER_THREADSandPARALLEL_MAKEvariables, and a centralized tarball download directory through theDL_DIRvariable.Build the image using the
bitbakecommand. If you want information on BitBake, see the user manual included in thebitbake/doc/manualdirectory of the Source Directory.Run the image either on the actual hardware or using the QEMU emulator.
Another option you have to get started is to use pre-built binaries. The Yocto Project provides many types of binaries with each release. See the "Images" chapter in the Yocto Project Reference Manual for descriptions of the types of binaries that ship with a Yocto Project release.
Using a pre-built binary is ideal for developing software applications to run on your target hardware. To do this, you need to be able to access the appropriate cross-toolchain tarball for the architecture on which you are developing. If you are using an SDK type image, the image ships with the complete toolchain native to the architecture. If you are not using an SDK type image, you need to separately download and install the stand-alone Yocto Project cross-toolchain tarball.
Regardless of the type of image you are using, you need to download the pre-built kernel that you will boot in the QEMU emulator and then download and extract the target root filesystem for your target machine’s architecture. You can get architecture-specific binaries and file systems from machines. You can get installation scripts for stand-alone toolchains from toolchains. Once you have all your files, you set up the environment to emulate the hardware by sourcing an environment setup script. Finally, you start the QEMU emulator. You can find details on all these steps in the "Using Pre-Built Binaries and QEMU" section of the Yocto Project Quick Start.
Using QEMU to emulate your hardware can result in speed issues
depending on the target and host architecture mix.
For example, using the qemux86 image in the emulator
on an Intel-based 32-bit (x86) host machine is fast because the target and
host architectures match.
On the other hand, using the qemuarm image on the same Intel-based
host can be slower.
But, you still achieve faithful emulation of ARM-specific issues.
To speed things up, the QEMU images support using distcc
to call a cross-compiler outside the emulated system.
If you used runqemu to start QEMU, and the
distccd application is present on the host system, any
BitBake cross-compiling toolchain available from the build system is automatically
used from within QEMU simply by calling distcc.
You can accomplish this by defining the cross-compiler variable
(e.g. export CC="distcc").
Alternatively, if you are using a suitable SDK image or the appropriate
stand-alone toolchain is present,
the toolchain is also automatically used.
Note
Several mechanisms exist that let you connect to the system running on the QEMU emulator:QEMU provides a framebuffer interface that makes standard consoles available.
Generally, headless embedded devices have a serial port. If so, you can configure the operating system of the running image to use that port to run a console. The connection uses standard IP networking.
SSH servers exist in some QEMU images. The
core-image-satoQEMU image has a Dropbear secure shell (SSH) server that runs with the root password disabled. Thecore-image-basicandcore-image-lsbQEMU images have OpenSSH instead of Dropbear. Including these SSH servers allow you to use standardsshandscpcommands. Thecore-image-minimalQEMU image, however, contains no SSH server.You can use a provided, user-space NFS server to boot the QEMU session using a local copy of the root filesystem on the host. In order to make this connection, you must extract a root filesystem tarball by using the
runqemu-extract-sdkcommand. After running the command, you must then point therunqemuscript to the extracted directory instead of a root filesystem image file.
This chapter helps you understand the Yocto Project as an open source development project. In general, working in an open source environment is very different from working in a closed, proprietary environment. Additionally, the Yocto Project uses specific tools and constructs as part of its development environment. This chapter specifically addresses open source philosophy, using the Yocto Project in a team environment, source repositories, Yocto Project terms, licensing, the open source distributed version control system Git, workflows, bug tracking, and how to submit changes.
Open source philosophy is characterized by software development directed by peer production and collaboration through an active community of developers. Contrast this to the more standard centralized development models used by commercial software companies where a finite set of developers produces a product for sale using a defined set of procedures that ultimately result in an end product whose architecture and source material are closed to the public.
Open source projects conceptually have differing concurrent agendas, approaches, and production. These facets of the development process can come from anyone in the public (community) that has a stake in the software project. The open source environment contains new copyright, licensing, domain, and consumer issues that differ from the more traditional development environment. In an open source environment, the end product, source material, and documentation are all available to the public at no cost.
A benchmark example of an open source project is the Linux Kernel, which was initially conceived and created by Finnish computer science student Linus Torvalds in 1991. Conversely, a good example of a non-open source project is the Windows® family of operating systems developed by Microsoft® Corporation.
Wikipedia has a good historical description of the Open Source Philosophy here. You can also find helpful information on how to participate in the Linux Community here.
It might not be immediately clear how you can use the Yocto Project in a team environment, or scale it for a large team of developers. One of the strengths of the Yocto Project is that it is extremely flexible. Thus, you can adapt it to many different use cases and scenarios. However, these characteristics can cause a struggle if you are trying to create a working setup that scales across a large team.
To help with these types of situations, this section presents some of the project's most successful experiences, practices, solutions, and available technologies that work well. Keep in mind, the information here is a starting point. You can build off it and customize it to fit any particular working environment and set of practices.
Systems across a large team should meet the needs of two types of developers: those working on the contents of the operating system image itself and those developing applications. Regardless of the type of developer, their workstations must be both reasonably powerful and run Linux.
For developers who mainly do application level work on top of an existing software stack, here are some practices that work best:
Use a pre-built toolchain that contains the software stack itself. Then, develop the application code on top of the stack. This method works well for small numbers of relatively isolated applications.
When possible, use the Yocto Project plug-in for the Eclipse™ IDE and other pieces of Application Development Technology (ADT). For more information, see the "Application Development Workflow" section as well as the Yocto Project Application Developer's Guide.
Keep your cross-development toolchains updated. You can do this through provisioning either as new toolchain downloads or as updates through a package update mechanism using
opkgto provide updates to an existing toolchain. The exact mechanics of how and when to do this are a question for local policy.Use multiple toolchains installed locally into different locations to allow development across versions.
For core system development, it is often best to have the build system itself available on the developer workstations so developers can run their own builds and directly rebuild the software stack. You should keep the core system unchanged as much as possible and do your work in layers on top of the core system. Doing so gives you a greater level of portability when upgrading to new versions of the core system or Board Support Packages (BSPs). You can share layers amongst the developers of a particular project and contain the policy configuration that defines the project.
Aside from the previous best practices, there exists a number of tips and tricks that can help speed up core development projects:
Use a Shared State Cache (sstate) among groups of developers who are on a fast network. The best way to share sstate is through a Network File System (NFS) share. The first user to build a given component for the first time contributes that object to the sstate, while subsequent builds from other developers then reuse the object rather than rebuild it themselves.
Although it is possible to use other protocols for the sstate such as HTTP and FTP, you should avoid these. Using HTTP limits the sstate to read-only and FTP provides poor performance.
Have autobuilders contribute to the sstate pool similarly to how the developer workstations contribute. For information, see the Autobuilders section.
Build stand-alone tarballs that contain "missing" system requirements if for some reason developer workstations do not meet minimum system requirements such as latest Python versions,
chrpath, or other tools. You can install and relocate the tarball exactly as you would the usual cross-development toolchain so that all developers can meet minimum version requirements on most distributions.Use a small number of shared, high performance systems for testing purposes (e.g. dual six core Xeons with 24GB RAM and plenty of disk space). Developers can use these systems for wider, more extensive testing while they continue to develop locally using their primary development system.
Enable the PR Service when package feeds need to be incremental with continually increasing PR values. Typically, this situation occurs when you use or publish package feeds and use a shared state. You should enable the PR Service for all users who use the shared state pool. For more information on the PR Service, see the "Working With a PR Service".
Keeping your Metadata and any software you are developing under the control of an SCM system that is compatible with the OpenEmbedded build system is advisable. Of the SCMs BitBake supports, the Yocto Project team strongly recommends using Git. Git is a distributed system that is easy to backup, allows you to work remotely, and then connects back to the infrastructure.
Note
For information about BitBake and SCMs, see the BitBake manual located in thebitbake/doc/manual directory of the
Source Directory.
It is relatively easy to set up Git services and create
infrastructure like
http://git.yoctoproject.org,
which is based on server software called
gitolite with cgit
being used to generate the web interface that lets you view the
repositories.
The gitolite software identifies users
using ssh keys and allows branch-based
access controls to repositories that you can control as little
or as much as necessary.
Note
The setup of these services is beyond the scope of this manual. However, sites such as these exist that describe how to perform setup:Git documentation: Describes how to install
gitoliteon the server.The
gitolitemaster index: All topics forgitolite.Interfaces, frontends, and tools: Documentation on how to create interfaces and frontends for Git.
Autobuilders are often the core of a development project. It is here that changes from individual developers are brought together and centrally tested and subsequent decisions about releases can be made. Autobuilders also allow for "continuous integration" style testing of software components and regression identification and tracking.
See "Yocto Project Autobuilder" for more information and links to buildbot. The Yocto Project team has found this implementation works well in this role. A public example of this is the Yocto Project Autobuilders, which we use to test the overall health of the project.
The features of this system are:
Highlights when commits break the build.
Populates an sstate cache from which developers can pull rather than requiring local builds.
Allows commit hook triggers, which trigger builds when commits are made.
Allows triggering of automated image booting and testing under the QuickEMUlator (QEMU).
Supports incremental build testing and from scratch builds.
Shares output that allows developer testing and historical regression investigation.
Creates output that can be used for releases.
Allows scheduling of builds so that resources can be used efficiently.
The Yocto Project itself uses a hierarchical structure and a
pull model.
Scripts exist to create and send pull requests
(i.e. create-pull-request and
send-pull-request).
This model is in line with other open source projects where
maintainers are responsible for specific areas of the project
and a single maintainer handles the final "top-of-tree" merges.
Note
You can also use a more collective push model. Thegitolite software supports both the
push and pull models quite easily.
As with any development environment, it is important to document the policy used as well as any main project guidelines so they are understood by everyone. It is also a good idea to have well structured commit messages, which are usually a part of a project's guidelines. Good commit messages are essential when looking back in time and trying to understand why changes were made.
If you discover that changes are needed to the core layer of the project, it is worth sharing those with the community as soon as possible. Chances are if you have discovered the need for changes, someone else in the community needs them also.
This section summarizes the key recommendations described in the previous sections:
Use Git as the source control system.
Maintain your Metadata in layers that make sense for your situation. See the "Understanding and Creating Layers" section for more information on layers.
Separate the project's Metadata and code by using separate Git repositories. See the "Yocto Project Source Repositories" section for information on these repositories. See the "Getting Set Up" section for information on how to set up various Yocto Project related Git repositories.
Set up the directory for the shared state cache (
SSTATE_DIR) where it makes sense. For example, set up the sstate cache on a system used by developers in the same organization and share the same source directories on their machines.Set up an Autobuilder and have it populate the sstate cache and source directories.
The Yocto Project community encourages you to send patches to the project to fix bugs or add features. If you do submit patches, follow the project commit guidelines for writing good commit messages. See the "How to Submit a Change" section.
Send changes to the core sooner than later as others likely run into the same issues. For some guidance on mailing lists to use, see the list in the "How to Submit a Change" section. For a description of the available mailing lists, see the "Mailing Lists" section in the Yocto Project Reference Manual.
The Yocto Project team maintains complete source repositories for all Yocto Project files at http://git.yoctoproject.org/cgit/cgit.cgi. This web-based source code browser is organized into categories by function such as IDE Plugins, Matchbox, Poky, Yocto Linux Kernel, and so forth. From the interface, you can click on any particular item in the "Name" column and see the URL at the bottom of the page that you need to clone a Git repository for that particular item. Having a local Git repository of the Source Directory (poky) allows you to make changes, contribute to the history, and ultimately enhance the Yocto Project's tools, Board Support Packages, and so forth.
Conversely, if you are a developer that is not interested in contributing back to the Yocto Project, you have the ability to simply download and extract release tarballs and use them within the Yocto Project environment. All that is required is a particular release of the Yocto Project and your application source code.
For any supported release of Yocto Project, you can go to the
Yocto Project Website and
select the "Downloads" tab and get a released tarball of the
poky repository or any supported BSP tarballs.
Unpacking these tarballs gives you a snapshot of the released
files.
Note
The recommended method for setting up the Yocto Project Source Directory and the files for supported BSPs (e.g.,meta-intel) is to
use Git to create a local copy of the
upstream repositories.
In summary, here is where you can get the project files needed for development:
Source Repositories: This area contains IDE Plugins, Matchbox, Poky, Poky Support, Tools, Yocto Linux Kernel, and Yocto Metadata Layers. You can create local copies of Git repositories for each of these areas.
Index of /releases: This area contains index releases such as the Eclipse™ Yocto Plug-in, miscellaneous support, poky, pseudo, installers for cross-development toolchains, and all released versions of Yocto Project in the form of images or tarballs. Downloading and extracting these files does not produce a local copy of the Git repository but rather a snapshot of a particular release or image.
"Downloads" page for the Yocto Project Website: Access this page by going to the website and then selecting the "Downloads" tab. This page allows you to download any Yocto Project release or Board Support Package (BSP) in tarball form. The tarballs are similar to those found in the Index of /releases: area.
Following is a list of terms and definitions users new to the Yocto Project development environment might find helpful. While some of these terms are universal, the list includes them just in case:
Append Files: Files that append build information to a recipe file. Append files are known as BitBake append files and
.bbappendfiles. The OpenEmbedded build system expects every append file to have a corresponding recipe (.bb) file. Furthermore, the append file and corresponding recipe file must use the same root filename. The filenames can differ only in the file type suffix used (e.g.formfactor_0.0.bbandformfactor_0.0.bbappend).Information in append files overrides the information in the similarly-named recipe file. For an example of an append file in use, see the "Using .bbappend Files" section.
BitBake: The task executor and scheduler used by the OpenEmbedded build system to build images. For more information on BitBake, see the BitBake documentation in the
bitbake/doc/manualdirectory of the Source Directory.Build Directory: This term refers to the area used by the OpenEmbedded build system for builds. The area is created when you
sourcethe setup environment script that is found in the Source Directory (i.e.oe-init-build-envoroe-init-build-env-memres). TheTOPDIRvariable points to the Build Directory.You have a lot of flexibility when creating the Build Directory. Following are some examples that show how to create the directory. The examples assume your Source Directory is named
poky:Create the Build Directory inside your Source Directory and let the name of the Build Directory default to
build:$ cd $HOME/poky $ source oe-init-build-envCreate the Build Directory inside your home directory and specifically name it
test-builds:$ cd $HOME $ source poky/oe-init-build-env test-buildsProvide a directory path and specifically name the build directory. Any intermediate folders in the pathname must exist. This next example creates a Build Directory named
YP-10.0.2in your home directory within the existing directorymybuilds:$cd $HOME $ source $HOME/poky/oe-init-build-env $HOME/mybuilds/YP-10.0.2
Build System: In the context of the Yocto Project, this term refers to the OpenEmbedded build system used by the project. This build system is based on the project known as "Poky." For some historical information about Poky, see the Poky term.
Classes: Files that provide for logic encapsulation and inheritance so that commonly used patterns can be defined once and then easily used in multiple recipes. Class files end with the
.bbclassfilename extension.Configuration File: Configuration information in various
.conffiles provides global definitions of variables. Theconf/local.confconfiguration file in the Build Directory contains user-defined variables that affect each build. Themeta-yocto/conf/distro/poky.confconfiguration file defines Yocto "distro" configuration variables used only when building with this policy. Machine configuration files, which are located throughout the Source Directory, define variables for specific hardware and are only used when building for that target (e.g. themachine/beagleboard.confconfiguration file defines variables for the Texas Instruments ARM Cortex-A8 development board). Configuration files end with a.conffilename extension.Cross-Development Toolchain: In general, a cross-development toolchain is a collection of software development tools and utilities that run on one architecture and allow you to develop software for a different, or targeted, architecture. These toolchains contain cross-compilers, linkers, and debuggers that are specific to the target architecture.
The Yocto Project supports two different cross-development toolchains:
A toolchain only used by and within BitBake when building an image for a target architecture.
A relocatable toolchain used outside of BitBake by developers when developing applications that will run on a targeted device. Sometimes this relocatable cross-development toolchain is referred to as the meta-toolchain.
Creation of these toolchains is simple and automated. For information on toolchain concepts as they apply to the Yocto Project, see the "Cross-Development Toolchain Generation" section in the Yocto Project Reference Manual. You can also find more information on using the relocatable toolchain in the Yocto Project Application Developer's Guide.
Image: An image is the result produced when BitBake processes a given collection of recipes and related Metadata. Images are the binary output that run on specific hardware or QEMU and for specific use cases. For a list of the supported image types that the Yocto Project provides, see the "Images" chapter in the Yocto Project Reference Manual.
Layer: A collection of recipes representing the core, a BSP, or an application stack. For a discussion on BSP Layers, see the "BSP Layers" section in the Yocto Project Board Support Packages (BSP) Developer's Guide.
Meta-Toolchain: A term sometimes used for Cross-Development Toolchain.
Metadata: The files that BitBake parses when building an image. In general, Metadata includes recipes, classes, and configuration files. In the context of the kernel ("kernel Metadata"), it refers to Metadata in the
metabranches of the kernel source Git repositories.OE-Core: A core set of Metadata originating with OpenEmbedded (OE) that is shared between OE and the Yocto Project. This Metadata is found in the
metadirectory of the Source Directory.Package: In the context of the Yocto Project, this term refers to the packaged output from a baked recipe. A package is generally the compiled binaries produced from the recipe's sources. You "bake" something by running it through BitBake.
It is worth noting that the term "package" can, in general, have subtle meanings. For example, the packages referred to in the "The Packages" section are compiled binaries that when installed add functionality to your Linux distribution.
Another point worth noting is that historically within the Yocto Project, recipes were referred to as packages - thus, the existence of several BitBake variables that are seemingly mis-named, (e.g.
PR,PRINC,PV, andPE).Package Groups: Arbitrary groups of software Recipes. You use package groups to hold recipes that, when built, usually accomplish a single task. For example, a package group could contain the recipes for a company’s proprietary or value-add software. Or, the package group could contain the recipes that enable graphics. A package group is really just another recipe. Because package group files are recipes, they end with the
.bbfilename extension.Poky: The term "poky" can mean several things. In its most general sense, it is an open-source project that was initially developed by OpenedHand. With OpenedHand, poky was developed off of the existing OpenEmbedded build system becoming a build system for embedded images. After Intel Corporation acquired OpenedHand, the project poky became the basis for the Yocto Project's build system. Within the Yocto Project source repositories,
pokyexists as a separate Git repository that can be cloned to yield a local copy on the host system. Thus, "poky" can refer to the local copy of the Source Directory used to develop within the Yocto Project.Recipe: A set of instructions for building packages. A recipe describes where you get source code and which patches to apply. Recipes describe dependencies for libraries or for other recipes, and they also contain configuration and compilation options. Recipes contain the logical unit of execution, the software/images to build, and use the
.bbfile extension.Source Directory: This term refers to the directory structure created as a result of either downloading and unpacking a Yocto Project release tarball or creating a local copy of the
pokyGit repositorygit://git.yoctoproject.org/poky. Sometimes you might hear the term "poky directory" used to refer to this directory structure.Note
The OpenEmbedded build system does not support file or directory names that contain spaces. Be sure that the Source Directory you use does not contain these types of names.The Source Directory contains BitBake, Documentation, Metadata and other files that all support the Yocto Project. Consequently, you must have the Source Directory in place on your development system in order to do any development using the Yocto Project.
For tarball expansion, the name of the top-level directory of the Source Directory is derived from the Yocto Project release tarball. For example, downloading and unpacking
poky-dora-10.0.2.tar.bz2results in a Source Directory whose top-level folder is namedpoky-dora-10.0.2. If you create a local copy of the Git repository, you can name the repository anything you like. Throughout much of the documentation,pokyis used as the name of the top-level folder of the local copy of the poky Git repository. So, for example, cloning thepokyGit repository results in a local Git repository whose top-level folder is also namedpoky.It is important to understand the differences between the Source Directory created by unpacking a released tarball as compared to cloning
git://git.yoctoproject.org/poky. When you unpack a tarball, you have an exact copy of the files based on the time of release - a fixed release point. Any changes you make to your local files in the Source Directory are on top of the release. On the other hand, when you clone thepokyGit repository, you have an active development repository. In this case, any local changes you make to the Source Directory can be later applied to active development branches of the upstreampokyGit repository.Finally, if you want to track a set of local changes while starting from the same point as a release tarball, you can create a local Git branch that reflects the exact copy of the files at the time of their release. You do this by using Git tags that are part of the repository.
For more information on concepts related to Git repositories, branches, and tags, see the "Repositories, Tags, and Branches" section.
Task: A unit of execution for BitBake (e.g.
do_compile,do_fetch,do_patch, and so forth).Upstream: A reference to source code or repositories that are not local to the development system but located in a master area that is controlled by the maintainer of the source code. For example, in order for a developer to work on a particular piece of code, they need to first get a copy of it from an "upstream" source.
Because open source projects are open to the public, they have different licensing structures in place. License evolution for both Open Source and Free Software has an interesting history. If you are interested in this history, you can find basic information here:
In general, the Yocto Project is broadly licensed under the Massachusetts Institute of Technology (MIT) License. MIT licensing permits the reuse of software within proprietary software as long as the license is distributed with that software. MIT is also compatible with the GNU General Public License (GPL). Patches to the Yocto Project follow the upstream licensing scheme. You can find information on the MIT license at here. You can find information on the GNU GPL here.
When you build an image using the Yocto Project, the build process uses a
known list of licenses to ensure compliance.
You can find this list in the
Source Directory at
meta/files/common-licenses.
Once the build completes, the list of all licenses found and used during that build are
kept in the
Build Directory at
tmp/deploy/licenses.
If a module requires a license that is not in the base list, the build process generates a warning during the build. These tools make it easier for a developer to be certain of the licenses with which their shipped products must comply. However, even with these tools it is still up to the developer to resolve potential licensing issues.
The base list of licenses used by the build process is a combination of the Software Package Data Exchange (SPDX) list and the Open Source Initiative (OSI) projects. SPDX Group is a working group of the Linux Foundation that maintains a specification for a standard format for communicating the components, licenses, and copyrights associated with a software package. OSI is a corporation dedicated to the Open Source Definition and the effort for reviewing and approving licenses that are OSD-conformant.
You can find a list of the combined SPDX and OSI licenses that the Yocto Project uses here.
For information that can help you to maintain compliance with various open source licensing during the lifecycle of a product created using the Yocto Project, see the "Maintaining Open Source License Compliance During Your Product's Lifecycle" section.
The Yocto Project makes extensive use of Git, which is a free, open source distributed version control system. Git supports distributed development, non-linear development, and can handle large projects. It is best that you have some fundamental understanding of how Git tracks projects and how to work with Git if you are going to use the Yocto Project for development. This section provides a quick overview of how Git works and provides you with a summary of some essential Git commands.
For more information on Git, see http://git-scm.com/documentation. If you need to download Git, go to http://git-scm.com/download.
As mentioned earlier in the section "Yocto Project Source Repositories", the Yocto Project maintains source repositories at http://git.yoctoproject.org/cgit.cgi. If you look at this web-interface of the repositories, each item is a separate Git repository.
Git repositories use branching techniques that track content change (not files) within a project (e.g. a new feature or updated documentation). Creating a tree-like structure based on project divergence allows for excellent historical information over the life of a project. This methodology also allows for an environment from which you can do lots of local experimentation on projects as you develop changes or new features.
A Git repository represents all development efforts for a given project.
For example, the Git repository poky contains all changes
and developments for Poky over the course of its entire life.
That means that all changes that make up all releases are captured.
The repository maintains a complete history of changes.
You can create a local copy of any repository by "cloning" it with the Git
clone command.
When you clone a Git repository, you end up with an identical copy of the
repository on your development system.
Once you have a local copy of a repository, you can take steps to develop locally.
For examples on how to clone Git repositories, see the
"Getting Set Up" section.
It is important to understand that Git tracks content change and not files.
Git uses "branches" to organize different development efforts.
For example, the poky repository has
denzil, danny,
dylan, dora,
and master branches among others.
You can see all the branches by going to
http://git.yoctoproject.org/cgit.cgi/poky/ and
clicking on the
[...]
link beneath the "Branch" heading.
Each of these branches represents a specific area of development.
The master branch represents the current or most recent
development.
All other branches represent off-shoots of the master
branch.
When you create a local copy of a Git repository, the copy has the same set
of branches as the original.
This means you can use Git to create a local working area (also called a branch)
that tracks a specific development branch from the source Git repository.
in other words, you can define your local Git environment to work on any development
branch in the repository.
To help illustrate, here is a set of commands that creates a local copy of the
poky Git repository and then creates and checks out a local
Git branch that tracks the Yocto Project 1.5.2 Release (dora) development:
$ cd ~
$ git clone git://git.yoctoproject.org/poky
$ cd poky
$ git checkout -b dora origin/dora
In this example, the name of the top-level directory of your local
Source Directory
is poky,
and the name of that local working area (local branch) you just
created and checked out is dora.
The files in your local repository now reflect the same files that
are in the dora development
branch of the Yocto Project's poky
upstream repository.
It is important to understand that when you create and checkout a
local working branch based on a branch name,
your local environment matches the "tip" of that development branch
at the time you created your local branch, which could be
different from the files at the time of a similarly named release.
In other words, creating and checking out a local branch based on the
dora branch name is not the same as
cloning and checking out the master branch.
Keep reading to see how you create a local snapshot of a Yocto Project Release.
Git uses "tags" to mark specific changes in a repository.
Typically, a tag is used to mark a special point such as the final change
before a project is released.
You can see the tags used with the poky Git repository
by going to http://git.yoctoproject.org/cgit.cgi/poky/ and
clicking on the
[...]
link beneath the "Tag" heading.
Some key tags are bernard-5.0, denzil-7.0,
and dora-10.0.2.
These tags represent Yocto Project releases.
When you create a local copy of the Git repository, you also have access to all the tags. Similar to branches, you can create and checkout a local working Git branch based on a tag name. When you do this, you get a snapshot of the Git repository that reflects the state of the files when the change was made associated with that tag. The most common use is to checkout a working branch that matches a specific Yocto Project release. Here is an example:
$ cd ~
$ git clone git://git.yoctoproject.org/poky
$ cd poky
$ git checkout -b my-dora-10.0.2 dora-10.0.2
In this example, the name of the top-level directory of your local Yocto Project
Files Git repository is poky.
And, the name of the local branch you have created and checked out is
my-dora-10.0.2.
The files in your repository now exactly match the Yocto Project 1.5.2
Release tag (dora-10.0.2).
It is important to understand that when you create and checkout a local
working branch based on a tag, your environment matches a specific point
in time and not the entire development branch.
Git has an extensive set of commands that lets you manage changes and perform collaboration over the life of a project. Conveniently though, you can manage with a small set of basic operations and workflows once you understand the basic philosophy behind Git. You do not have to be an expert in Git to be functional. A good place to look for instruction on a minimal set of Git commands is here. If you need to download Git, you can do so here.
If you don’t know much about Git, you should educate yourself by visiting the links previously mentioned.
The following list briefly describes some basic Git operations as a way to get started. As with any set of commands, this list (in most cases) simply shows the base command and omits the many arguments they support. See the Git documentation for complete descriptions and strategies on how to use these commands:
git init: Initializes an empty Git repository. You cannot use Git commands unless you have a.gitrepository.git clone: Creates a clone of a repository. During collaboration, this command allows you to create a local repository that is on equal footing with a fellow developer’s repository.git add: Stages updated file contents to the index that Git uses to track changes. You must stage all files that have changed before you can commit them.git commit: Creates a "commit" that documents the changes you made. Commits are used for historical purposes, for determining if a maintainer of a project will allow the change, and for ultimately pushing the change from your local Git repository into the project’s upstream (or master) repository.git status: Reports any modified files that possibly need to be staged and committed.git checkout <branch-name>: Changes your working branch. This command is analogous to "cd".git checkout –b <working-branch>: Creates a working branch on your local machine where you can isolate work. It is a good idea to use local branches when adding specific features or changes. This way if you do not like what you have done you can easily get rid of the work.git branch: Reports existing local branches and tells you the branch in which you are currently working.git branch -D <branch-name>: Deletes an existing local branch. You need to be in a local branch other than the one you are deleting in order to delete<branch-name>.git pull: Retrieves information from an upstream Git repository and places it in your local Git repository. You use this command to make sure you are synchronized with the repository from which you are basing changes (.e.g. the master branch).git push: Sends all your committed local changes to an upstream Git repository (e.g. a contribution repository). The maintainer of the project draws from these repositories when adding changes to the project’s master repository or other development branch.git merge: Combines or adds changes from one local branch of your repository with another branch. When you create a local Git repository, the default branch is named "master". A typical workflow is to create a temporary branch for isolated work, make and commit your changes, switch to your local master branch, merge the changes from the temporary branch into the local master branch, and then delete the temporary branch.git cherry-pick: Choose and apply specific commits from one branch into another branch. There are times when you might not be able to merge all the changes in one branch with another but need to pick out certain ones.gitk: Provides a GUI view of the branches and changes in your local Git repository. This command is a good way to graphically see where things have diverged in your local repository.git log: Reports a history of your changes to the repository.git diff: Displays line-by-line differences between your local working files and the same files in the upstream Git repository that your branch currently tracks.
This section provides some overview on workflows using Git. In particular, the information covers basic practices that describe roles and actions in a collaborative development environment. Again, if you are familiar with this type of development environment, you might want to just skip this section.
The Yocto Project files are maintained using Git in a "master" branch whose Git history tracks every change and whose structure provides branches for all diverging functionality. Although there is no need to use Git, many open source projects do so. For the Yocto Project, a key individual called the "maintainer" is responsible for the "master" branch of a given Git repository. The "master" branch is the “upstream” repository where the final builds of the project occur. The maintainer is responsible for allowing changes in from other developers and for organizing the underlying branch structure to reflect release strategies and so forth.
Note
For information on finding out who is responsible (maintains) for a particular area of code, see the "How to Submit a Change" section.
The project also has contribution repositories known as "contrib" areas. These areas temporarily hold changes to the project that have been submitted or committed by the Yocto Project development team and by community members that contribute to the project. The maintainer determines if the changes are qualified to be moved from the "contrib" areas into the "master" branch of the Git repository.
Developers (including contributing community members) create and maintain cloned repositories of the upstream "master" branch. These repositories are local to their development platforms and are used to develop changes. When a developer is satisfied with a particular feature or change, they "push" the changes to the appropriate "contrib" repository.
Developers are responsible for keeping their local repository up-to-date with "master". They are also responsible for straightening out any conflicts that might arise within files that are being worked on simultaneously by more than one person. All this work is done locally on the developer’s machines before anything is pushed to a "contrib" area and examined at the maintainer’s level.
A somewhat formal method exists by which developers commit changes and push them into the "contrib" area and subsequently request that the maintainer include them into "master" This process is called “submitting a patch” or "submitting a change." For information on submitting patches and changes, see the "How to Submit a Change" section.
To summarize the environment: we have a single point of entry for changes into the project’s "master" branch of the Git repository, which is controlled by the project’s maintainer. And, we have a set of developers who independently develop, test, and submit changes to "contrib" areas for the maintainer to examine. The maintainer then chooses which changes are going to become a permanent part of the project.
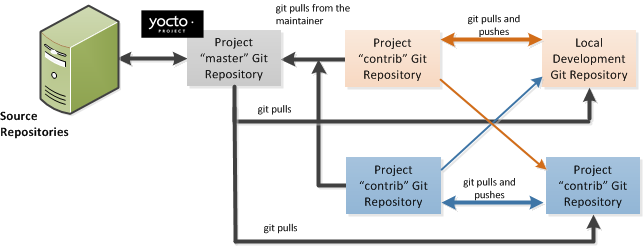 |
While each development environment is unique, there are some best practices or methods that help development run smoothly. The following list describes some of these practices. For more information about Git workflows, see the workflow topics in the Git Community Book.
Make Small Changes: It is best to keep the changes you commit small as compared to bundling many disparate changes into a single commit. This practice not only keeps things manageable but also allows the maintainer to more easily include or refuse changes.
It is also good practice to leave the repository in a state that allows you to still successfully build your project. In other words, do not commit half of a feature, then add the other half as a separate, later commit. Each commit should take you from one buildable project state to another buildable state.
Use Branches Liberally: It is very easy to create, use, and delete local branches in your working Git repository. You can name these branches anything you like. It is helpful to give them names associated with the particular feature or change on which you are working. Once you are done with a feature or change and have merged it into your local master branch, simply discard the temporary branch.
Merge Changes: The
git mergecommand allows you to take the changes from one branch and fold them into another branch. This process is especially helpful when more than a single developer might be working on different parts of the same feature. Merging changes also automatically identifies any collisions or "conflicts" that might happen as a result of the same lines of code being altered by two different developers.Manage Branches: Because branches are easy to use, you should use a system where branches indicate varying levels of code readiness. For example, you can have a "work" branch to develop in, a "test" branch where the code or change is tested, a "stage" branch where changes are ready to be committed, and so forth. As your project develops, you can merge code across the branches to reflect ever-increasing stable states of the development.
Use Push and Pull: The push-pull workflow is based on the concept of developers "pushing" local commits to a remote repository, which is usually a contribution repository. This workflow is also based on developers "pulling" known states of the project down into their local development repositories. The workflow easily allows you to pull changes submitted by other developers from the upstream repository into your work area ensuring that you have the most recent software on which to develop. The Yocto Project has two scripts named
create-pull-requestandsend-pull-requestthat ship with the release to facilitate this workflow. You can find these scripts in thescriptsfolder of the Source Directory. For information on how to use these scripts, see the "Using Scripts to Push a Change Upstream and Request a Pull" section.Patch Workflow: This workflow allows you to notify the maintainer through an email that you have a change (or patch) you would like considered for the "master" branch of the Git repository. To send this type of change, you format the patch and then send the email using the Git commands
git format-patchandgit send-email. For information on how to use these scripts, see the "How to Submit a Change" section.
The Yocto Project uses its own implementation of Bugzilla to track bugs. Implementations of Bugzilla work well for group development because they track bugs and code changes, can be used to communicate changes and problems with developers, can be used to submit and review patches, and can be used to manage quality assurance. The home page for the Yocto Project implementation of Bugzilla is http://bugzilla.yoctoproject.org.
Sometimes it is helpful to submit, investigate, or track a bug against the Yocto Project itself such as when discovering an issue with some component of the build system that acts contrary to the documentation or your expectations. Following is the general procedure for submitting a new bug using the Yocto Project Bugzilla. You can find more information on defect management, bug tracking, and feature request processes all accomplished through the Yocto Project Bugzilla on the wiki page here.
Always use the Yocto Project implementation of Bugzilla to submit a bug.
When submitting a new bug, be sure to choose the appropriate Classification, Product, and Component for which the issue was found. Defects for the Yocto Project fall into one of six classifications: Yocto Project Components, Infrastructure, Build System & Metadata, Documentation, QA/Testing, and Runtime. Each of these Classifications break down into multiple Products and, in some cases, multiple Components.
Use the bug form to choose the correct Hardware and Architecture for which the bug applies.
Indicate the Yocto Project version you were using when the issue occurred.
Be sure to indicate the Severity of the bug. Severity communicates how the bug impacted your work.
Select the appropriate "Documentation change" item for the bug. Fixing a bug may or may not affect the Yocto Project documentation.
Provide a brief summary of the issue. Try to limit your summary to just a line or two and be sure to capture the essence of the issue.
Provide a detailed description of the issue. You should provide as much detail as you can about the context, behavior, output, and so forth that surrounds the issue. You can even attach supporting files for output from logs by using the "Add an attachment" button.
Be sure to copy the appropriate people in the "CC List" for the bug. See the "How to Submit a Change" section for information about finding out who is responsible for code.
Submit the bug by clicking the "Submit Bug" button.
Contributions to the Yocto Project and OpenEmbedded are very welcome. Because the system is extremely configurable and flexible, we recognize that developers will want to extend, configure or optimize it for their specific uses. You should send patches to the appropriate mailing list so that they can be reviewed and merged by the appropriate maintainer.
Before submitting any change, be sure to find out who you should be notifying. Several methods exist through which you find out who you should be copying or notifying:
Maintenance File: Examine the
maintainers.incfile, which is located in the Source Directory atmeta-yocto/conf/distro/include, to see who is responsible for code.Board Support Package (BSP) README Files: For BSP maintainers of supported BSPs, you can examine individual BSP
READMEfiles. In addition, some layers (such as themeta-intellayer), include aMAINTAINERSfile which contains a list of all supported BSP maintainers for that layer.Search by File: Using Git, you can enter the following command to bring up a short list of all commits against a specific file:
git shortlog -- <filename>Just provide the name of the file for which you are interested. The information returned is not ordered by history but does include a list of all committers grouped by name. From the list, you can see who is responsible for the bulk of the changes against the file.
For a list of the Yocto Project and related mailing lists, see the "Mailing lists" section in the Yocto Project Reference Manual.
Here is some guidance on which mailing list to use for what type of change:
For changes to the core Metadata, send your patch to the openembedded-core mailing list. For example, a change to anything under the
metaorscriptsdirectories should be sent to this mailing list.For changes to BitBake (anything under the
bitbakedirectory), send your patch to the bitbake-devel mailing list.For changes to
meta-yocto, send your patch to the poky mailing list.For changes to other layers hosted on
yoctoproject.org(unless the layer's documentation specifies otherwise), tools, and Yocto Project documentation, use the yocto mailing list.For additional recipes that do not fit into the core Metadata, you should determine which layer the recipe should go into and submit the change in the manner recommended by the documentation (e.g. README) supplied with the layer. If in doubt, please ask on the yocto or openembedded-devel mailing lists.
When you send a patch, be sure to include a "Signed-off-by:" line in the same style as required by the Linux kernel. Adding this line signifies that you, the submitter, have agreed to the Developer's Certificate of Origin 1.1 as follows:
Developer's Certificate of Origin 1.1
By making a contribution to this project, I certify that:
(a) The contribution was created in whole or in part by me and I
have the right to submit it under the open source license
indicated in the file; or
(b) The contribution is based upon previous work that, to the best
of my knowledge, is covered under an appropriate open source
license and I have the right under that license to submit that
work with modifications, whether created in whole or in part
by me, under the same open source license (unless I am
permitted to submit under a different license), as indicated
in the file; or
(c) The contribution was provided directly to me by some other
person who certified (a), (b) or (c) and I have not modified
it.
(d) I understand and agree that this project and the contribution
are public and that a record of the contribution (including all
personal information I submit with it, including my sign-off) is
maintained indefinitely and may be redistributed consistent with
this project or the open source license(s) involved.
In a collaborative environment, it is necessary to have some sort of standard or method through which you submit changes. Otherwise, things could get quite chaotic. One general practice to follow is to make small, controlled changes. Keeping changes small and isolated aids review, makes merging/rebasing easier and keeps the change history clean when anyone needs to refer to it in future.
When you make a commit, you must follow certain standards established by the OpenEmbedded and Yocto Project development teams. For each commit, you must provide a single-line summary of the change and you should almost always provide a more detailed description of what you did (i.e. the body of the commit message). The only exceptions for not providing a detailed description would be if your change is a simple, self-explanatory change that needs no further description beyond the summary. Here are the guidelines for composing a commit message:
Provide a single-line, short summary of the change. This summary is typically viewable in the "shortlist" of changes. Thus, providing something short and descriptive that gives the reader a summary of the change is useful when viewing a list of many commits. This short description should be prefixed by the recipe name (if changing a recipe), or else the short form path to the file being changed.
For the body of the commit message, provide detailed information that describes what you changed, why you made the change, and the approach you used. It may also be helpful if you mention how you tested the change. Provide as much detail as you can in the body of the commit message.
If the change addresses a specific bug or issue that is associated with a bug-tracking ID, include a reference to that ID in your detailed description. For example, the Yocto Project uses a specific convention for bug references - any commit that addresses a specific bug should include the bug ID in the description (typically at the beginning) as follows:
[YOCTO #<bug-id>] <detailed description of change>
You can find more guidance on creating well-formed commit messages at this OpenEmbedded wiki page: http://www.openembedded.org/wiki/Commit_Patch_Message_Guidelines.
The next two sections describe general instructions for both pushing changes upstream and for submitting changes as patches.
The basic flow for pushing a change to an upstream "contrib" Git repository is as follows:
Make your changes in your local Git repository.
Stage your changes by using the
git addcommand on each file you changed.Commit the change by using the
git commitcommand and push it to the "contrib" repository. Be sure to provide a commit message that follows the project’s commit message standards as described earlier.Notify the maintainer that you have pushed a change by making a pull request. The Yocto Project provides two scripts that conveniently let you generate and send pull requests to the Yocto Project. These scripts are
create-pull-requestandsend-pull-request. You can find these scripts in thescriptsdirectory within the Source Directory.Using these scripts correctly formats the requests without introducing any whitespace or HTML formatting. The maintainer that receives your patches needs to be able to save and apply them directly from your emails. Using these scripts is the preferred method for sending patches.
For help on using these scripts, simply provide the
-hargument as follows:$ poky/scripts/create-pull-request -h $ poky/scripts/send-pull-request -h
You can find general Git information on how to push a change upstream in the Git Community Book.
You can submit patches without using the create-pull-request and
send-pull-request scripts described in the previous section.
However, keep in mind, the preferred method is to use the scripts.
Depending on the components changed, you need to submit the email to a specific mailing list. For some guidance on which mailing list to use, see the list in the "How to Submit a Change" section. For a description of the available mailing lists, see the "Mailing Lists" section in the Yocto Project Reference Manual.
Here is the general procedure on how to submit a patch through email without using the scripts:
Make your changes in your local Git repository.
Stage your changes by using the
git addcommand on each file you changed.Commit the change by using the
git commit --signoffcommand. Using the--signoffoption identifies you as the person making the change and also satisfies the Developer's Certificate of Origin (DCO) shown earlier.When you form a commit, you must follow certain standards established by the Yocto Project development team. See the earlier section "How to Submit a Change" for Yocto Project commit message standards.
Format the commit into an email message. To format commits, use the
git format-patchcommand. When you provide the command, you must include a revision list or a number of patches as part of the command. For example, either of these two commands takes your most recent single commit and formats it as an email message in the current directory:$ git format-patch -1or
$ git format-patch HEAD~After the command is run, the current directory contains a numbered
.patchfile for the commit.If you provide several commits as part of the command, the
git format-patchcommand produces a series of numbered files in the current directory – one for each commit. If you have more than one patch, you should also use the--coveroption with the command, which generates a cover letter as the first "patch" in the series. You can then edit the cover letter to provide a description for the series of patches. For information on thegit format-patchcommand, seeGIT_FORMAT_PATCH(1)displayed using theman git-format-patchcommand.Note
If you are or will be a frequent contributor to the Yocto Project or to OpenEmbedded, you might consider requesting a contrib area and the necessary associated rights.Import the files into your mail client by using the
git send-emailcommand.Note
In order to usegit send-email, you must have the the proper Git packages installed. For Ubuntu, Debian, and Fedora the package isgit-email.The
git send-emailcommand sends email by using a local or remote Mail Transport Agent (MTA) such asmsmtp,sendmail, or through a directsmtpconfiguration in your Gitconfigfile. If you are submitting patches through email only, it is very important that you submit them without any whitespace or HTML formatting that either you or your mailer introduces. The maintainer that receives your patches needs to be able to save and apply them directly from your emails. A good way to verify that what you are sending will be applicable by the maintainer is to do a dry run and send them to yourself and then save and apply them as the maintainer would.The
git send-emailcommand is the preferred method for sending your patches since there is no risk of compromising whitespace in the body of the message, which can occur when you use your own mail client. The command also has several options that let you specify recipients and perform further editing of the email message. For information on how to use thegit send-emailcommand, seeGIT-SEND-EMAIL(1)displayed using theman git-send-emailcommand.
Many development models exist for which you can use the Yocto Project. This chapter overviews simple methods that use tools provided by the Yocto Project:
System Development: System Development covers Board Support Package (BSP) development and kernel modification or configuration. For an example on how to create a BSP, see the "Creating a New BSP Layer Using the yocto-bsp Script" section in the Yocto Project Board Support Package (BSP) Developer's Guide. For more complete information on how to work with the kernel, see the Yocto Project Linux Kernel Development Manual.
User Application Development: User Application Development covers development of applications that you intend to run on target hardware. For information on how to set up your host development system for user-space application development, see the Yocto Project Application Developer's Guide. For a simple example of user-space application development using the Eclipse™ IDE, see the "Application Development Workflow" section.
Temporary Source Code Modification: Direct modification of temporary source code is a convenient development model to quickly iterate and develop towards a solution. Once you implement the solution, you should of course take steps to get the changes upstream and applied in the affected recipes.
Image Development using Hob: You can use the Hob to build custom operating system images within the build environment. Hob provides an efficient interface to the OpenEmbedded build system.
Using a Development Shell: You can use a
devshellto efficiently debug commands or simply edit packages. Working inside a development shell is a quick way to set up the OpenEmbedded build environment to work on parts of a project.
System development involves modification or creation of an image that you want to run on a specific hardware target. Usually, when you want to create an image that runs on embedded hardware, the image does not require the same number of features that a full-fledged Linux distribution provides. Thus, you can create a much smaller image that is designed to use only the features for your particular hardware.
To help you understand how system development works in the Yocto Project, this section covers two types of image development: BSP creation and kernel modification or configuration.
A BSP is a package of recipes that, when applied during a build, results in an image that you can run on a particular board. Thus, the package when compiled into the new image, supports the operation of the board.
Note
For a brief list of terms used when describing the development process in the Yocto Project, see the "Yocto Project Terms" section.
The remainder of this section presents the basic
steps used to create a BSP using the Yocto Project's
BSP Tools.
Although not required for BSP creation, the
meta-intel repository, which contains
many BSPs supported by the Yocto Project, is part of the example.
For an example that shows how to create a new layer using the tools, see the "Creating a New BSP Layer Using the yocto-bsp Script" section in the Yocto Project Board Support Package (BSP) Developer's Guide.
The following illustration and list summarize the BSP creation general workflow.
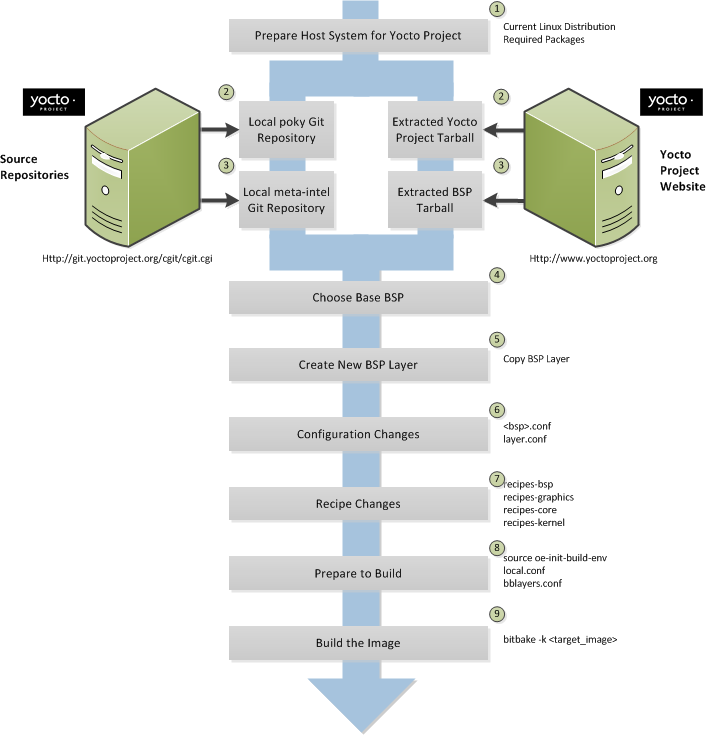 |
Set up your host development system to support development using the Yocto Project: See the "The Linux Distribution" and the "The Packages" sections both in the Yocto Project Quick Start for requirements.
Establish a local copy of the project files on your system: You need this Source Directory available on your host system. Having these files on your system gives you access to the build process and to the tools you need. For information on how to set up the Source Directory, see the "Getting Set Up" section.
Establish the
meta-intelrepository on your system: Having local copies of these supported BSP layers on your system gives you access to layers you might be able to build on or modify to create your BSP. For information on how to get these files, see the "Getting Set Up" section.Create your own BSP layer using the
yocto-bspscript: Layers are ideal for isolating and storing work for a given piece of hardware. A layer is really just a location or area in which you place the recipes and configurations for your BSP. In fact, a BSP is, in itself, a special type of layer. The simplest way to create a new BSP layer that is compliant with the Yocto Project is to use theyocto-bspscript. For information about that script, see the "Creating a New BSP Layer Using the yocto-bsp Script" section in the Yocto Project Board Support (BSP) Developer's Guide.Another example that illustrates a layer is an application. Suppose you are creating an application that has library or other dependencies in order for it to compile and run. The layer, in this case, would be where all the recipes that define those dependencies are kept. The key point for a layer is that it is an isolated area that contains all the relevant information for the project that the OpenEmbedded build system knows about. For more information on layers, see the "Understanding and Creating Layers" section. For more information on BSP layers, see the "BSP Layers" section in the Yocto Project Board Support Package (BSP) Developer's Guide.
Note
Five BSPs exist that are part of the Yocto Project release:genericx86,genericx86-64,beagleboard,mpc8315e, androuterstationpro. The recipes and configurations for these five BSPs are located and dispersed within the Source Directory. On the other hand, BSP layers for Chief River, Crown Bay, Crystal Forest, Emenlow, Fish River Island 2, Jasper Forest, N450, NUC DC3217IYE, Romley, sys940x, Sugar Bay, and tlk exist in their own separate layers within the largermeta-intellayer.When you set up a layer for a new BSP, you should follow a standard layout. This layout is described in the "Example Filesystem Layout" section of the Board Support Package (BSP) Development Guide. In the standard layout, you will notice a suggested structure for recipes and configuration information. You can see the standard layout for a BSP by examining any supported BSP found in the
meta-intellayer inside the Source Directory.Make configuration changes to your new BSP layer: The standard BSP layer structure organizes the files you need to edit in
confand severalrecipes-*directories within the BSP layer. Configuration changes identify where your new layer is on the local system and identify which kernel you are going to use. When you run theyocto-bspscript, you are able to interactively configure many things for the BSP (e.g. keyboard, touchscreen, and so forth).Make recipe changes to your new BSP layer: Recipe changes include altering recipes (
.bbfiles), removing recipes you don't use, and adding new recipes or append files (.bbappend) that you need to support your hardware.Prepare for the build: Once you have made all the changes to your BSP layer, there remains a few things you need to do for the OpenEmbedded build system in order for it to create your image. You need to get the build environment ready by sourcing an environment setup script and you need to be sure two key configuration files are configured appropriately: the
conf/local.confand theconf/bblayers.conffile. You must make the OpenEmbedded build system aware of your new layer. See the "Enabling Your Layer" section for information on how to let the build system know about your new layer.The entire process for building an image is overviewed in the section "Building an Image" section of the Yocto Project Quick Start. You might want to reference this information.
Build the image: The OpenEmbedded build system uses the BitBake tool to build images based on the type of image you want to create. You can find more information about BitBake in the user manual, which is found in the
bitbake/doc/manualdirectory of the Source Directory.The build process supports several types of images to satisfy different needs. See the "Images" chapter in the Yocto Project Reference Manual for information on supported images.
You can view a video presentation on "Building Custom Embedded Images with Yocto" at Free Electrons. You can also find supplemental information in the Yocto Project Board Support Package (BSP) Developer's Guide. Finally, there is a wiki page write up of the example also located here that you might find helpful.
Kernel modification involves changing the Yocto Project kernel, which could involve changing
configuration options as well as adding new kernel recipes.
Configuration changes can be added in the form of configuration fragments, while recipe
modification comes through the kernel's recipes-kernel area
in a kernel layer you create.
The remainder of this section presents a high-level overview of the Yocto Project kernel architecture and the steps to modify the kernel. You can reference the "Patching the Kernel" section for an example that changes the source code of the kernel. For information on how to configure the kernel, see the "Configuring the Kernel" section. For more information on the kernel and on modifying the kernel, see the Yocto Project Linux Kernel Development Manual.
Traditionally, when one thinks of a patched kernel, they think of a base kernel source tree and a fixed structure that contains kernel patches. The Yocto Project, however, employs mechanisms that, in a sense, result in a kernel source generator. By the end of this section, this analogy will become clearer.
You can find a web interface to the Yocto Project kernel source repositories at http://git.yoctoproject.org. If you look at the interface, you will see to the left a grouping of Git repositories titled "Yocto Linux Kernel." Within this group, you will find several kernels supported by the Yocto Project:
linux-yocto-3.4- The stable Yocto Project kernel to use with the Yocto Project Release 1.3. This kernel is based on the Linux 3.4 released kernel.linux-yocto-3.8- The stable Yocto Project kernel to use with the Yocto Project Release 1.4. This kernel is based on the Linux 3.8 released kernel.linux-yocto-3.10- The stable Yocto Project kernel to use with the Yocto Project Release 1.5. This kernel is based on the Linux 3.10 released kernel.linux-yocto-dev- A development kernel based on the latest upstream release candidate available.
The kernels are maintained using the Git revision control system that structures them using the familiar "tree", "branch", and "leaf" scheme. Branches represent diversions from general code to more specific code, while leaves represent the end-points for a complete and unique kernel whose source files, when gathered from the root of the tree to the leaf, accumulate to create the files necessary for a specific piece of hardware and its features. The following figure displays this concept:
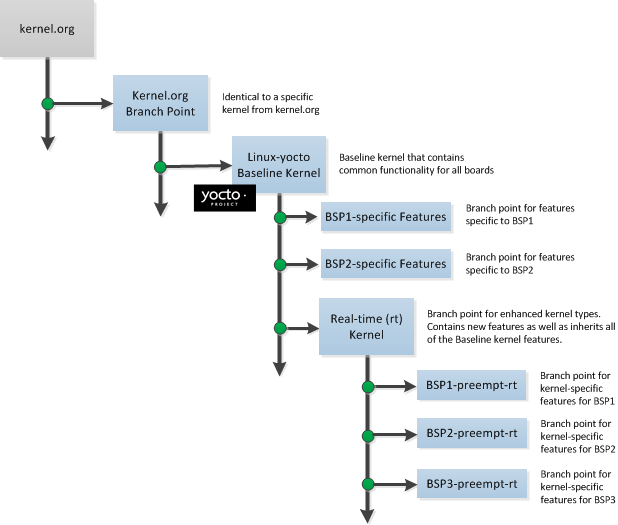 |
Within the figure, the "Kernel.org Branch Point" represents the point in the tree
where a supported base kernel is modified from the Linux kernel.
For example, this could be the branch point for the linux-yocto-3.4
kernel.
Thus, everything further to the right in the structure is based on the
linux-yocto-3.4 kernel.
Branch points to right in the figure represent where the
linux-yocto-3.4 kernel is modified for specific hardware
or types of kernels, such as real-time kernels.
Each leaf thus represents the end-point for a kernel designed to run on a specific
targeted device.
The overall result is a Git-maintained repository from which all the supported kernel types can be derived for all the supported devices. A big advantage to this scheme is the sharing of common features by keeping them in "larger" branches within the tree. This practice eliminates redundant storage of similar features shared among kernels.
Note
Keep in mind the figure does not take into account all the supported Yocto Project kernel types, but rather shows a single generic kernel just for conceptual purposes. Also keep in mind that this structure represents the Yocto Project source repositories that are either pulled from during the build or established on the host development system prior to the build by either cloning a particular kernel's Git repository or by downloading and unpacking a tarball.
Upstream storage of all the available kernel source code is one thing, while representing and using the code on your host development system is another. Conceptually, you can think of the kernel source repositories as all the source files necessary for all the supported kernels. As a developer, you are just interested in the source files for the kernel on which you are working. And, furthermore, you need them available on your host system.
Kernel source code is available on your host system a couple of different ways. If you are working in the kernel all the time, you probably would want to set up your own local Git repository of the kernel tree. If you just need to make some patches to the kernel, you can access temporary kernel source files that were extracted and used during a build. We will just talk about working with the temporary source code. For more information on how to get kernel source code onto your host system, see the "Yocto Project Kernel" bulleted item earlier in the manual.
What happens during the build?
When you build the kernel on your development system, all files needed for the build
are taken from the source repositories pointed to by the
SRC_URI variable
and gathered in a temporary work area
where they are subsequently used to create the unique kernel.
Thus, in a sense, the process constructs a local source tree specific to your
kernel to generate the new kernel image - a source generator if you will.
The following figure shows the temporary file structure created on your host system when the build occurs. This Build Directory contains all the source files used during the build.
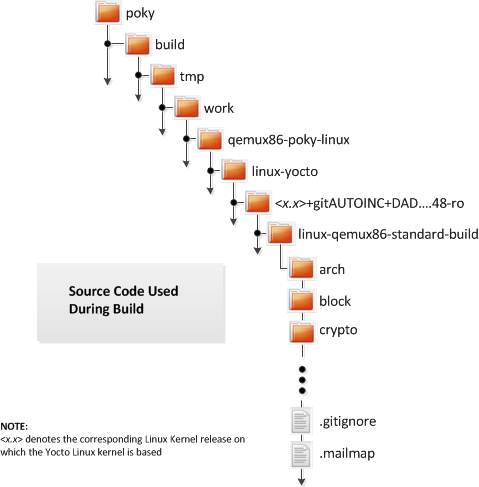 |
Again, for additional information the Yocto Project kernel's architecture and its branching strategy, see the Yocto Project Linux Kernel Development Manual. You can also reference the "Patching the Kernel" section for a detailed example that modifies the kernel.
This illustration and the following list summarizes the kernel modification general workflow.
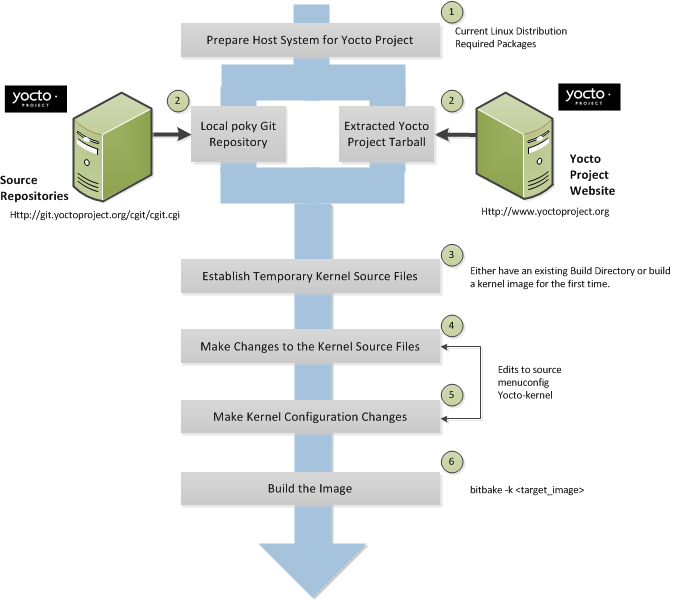 |
Set up your host development system to support development using the Yocto Project: See "The Linux Distribution" and "The Packages" sections both in the Yocto Project Quick Start for requirements.
Establish a local copy of project files on your system: Having the Source Directory on your system gives you access to the build process and tools you need. For information on how to get these files, see the bulleted item "Yocto Project Release" earlier in this manual.
Establish the temporary kernel source files: Temporary kernel source files are kept in the Build Directory created by the OpenEmbedded build system when you run BitBake. If you have never built the kernel you are interested in, you need to run an initial build to establish local kernel source files.
If you are building an image for the first time, you need to get the build environment ready by sourcing the environment setup script. You also need to be sure two key configuration files (
local.confandbblayers.conf) are configured appropriately.The entire process for building an image is overviewed in the "Building an Image" section of the Yocto Project Quick Start. You might want to reference this information. You can find more information on BitBake in the user manual, which is found in the
bitbake/doc/manualdirectory of the Source Directory.The build process supports several types of images to satisfy different needs. See the "Images" chapter in the Yocto Project Reference Manual for information on supported images.
Make changes to the kernel source code if applicable: Modifying the kernel does not always mean directly changing source files. However, if you have to do this, you make the changes to the files in the Build directory.
Make kernel configuration changes if applicable: If your situation calls for changing the kernel's configuration, you can use the
yocto-kernelscript ormenuconfigto enable and disable kernel configurations. Using the script lets you interactively set up kernel configurations. Usingmenuconfigallows you to interactively develop and test the configuration changes you are making to the kernel. When saved, changes usingmenuconfigupdate the kernel's.configfile. Try to resist the temptation of directly editing the.configfile found in the Build Directory attmp/sysroots/<machine-name>/kernel. Doing so, can produce unexpected results when the OpenEmbedded build system regenerates the configuration file.Once you are satisfied with the configuration changes made using
menuconfig, you can directly compare the.configfile against a saved original and gather those changes into a config fragment to be referenced from within the kernel's.bbappendfile.Rebuild the kernel image with your changes: Rebuilding the kernel image applies your changes.
Application development involves creating an application that you want to run on your target hardware, which is running a kernel image created using the OpenEmbedded build system. The Yocto Project provides an Application Development Toolkit (ADT) and stand-alone cross-development toolchains that facilitate quick development and integration of your application into its runtime environment. Using the ADT and toolchains, you can compile and link your application. You can then deploy your application to the actual hardware or to the QEMU emulator for testing. If you are familiar with the popular Eclipse™ IDE, you can use an Eclipse Yocto Plug-in to allow you to develop, deploy, and test your application all from within Eclipse.
While we strongly suggest using the ADT to develop your application, this option might not be best for you. If this is the case, you can still use pieces of the Yocto Project for your development process. However, because the process can vary greatly, this manual does not provide detail on the process.
To help you understand how application development works using the ADT, this section provides an overview of the general development process and a detailed example of the process as it is used from within the Eclipse IDE.
The following illustration and list summarize the application development general workflow.
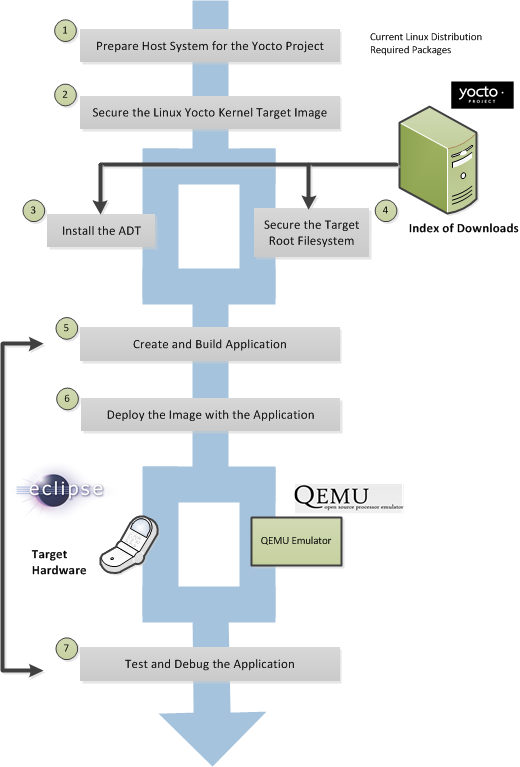 |
Prepare the host system for the Yocto Project: See "The Linux Distribution" and "The Packages" sections both in the Yocto Project Quick Start for requirements.
Secure the Yocto Project kernel target image: You must have a target kernel image that has been built using the OpenEmbedded build system.
Depending on whether the Yocto Project has a pre-built image that matches your target architecture and where you are going to run the image while you develop your application (QEMU or real hardware), the area from which you get the image differs.
Download the image from
machinesif your target architecture is supported and you are going to develop and test your application on actual hardware.Download the image from
machines/qemuif your target architecture is supported and you are going to develop and test your application using the QEMU emulator.Build your image if you cannot find a pre-built image that matches your target architecture. If your target architecture is similar to a supported architecture, you can modify the kernel image before you build it. See the "Patching the Kernel" section for an example.
For information on pre-built kernel image naming schemes for images that can run on the QEMU emulator, see the "Downloading the Pre-Built Linux Kernel" section in the Yocto Project Quick Start.
Install the ADT: The ADT provides a target-specific cross-development toolchain, the root filesystem, the QEMU emulator, and other tools that can help you develop your application. While it is possible to get these pieces separately, the ADT Installer provides an easy, inclusive method. You can get these pieces by running an ADT installer script, which is configurable. For information on how to install the ADT, see the "Using the ADT Installer" section in the Yocto Project Application Developer's Guide.
If applicable, secure the target root filesystem and the Cross-development toolchain: If you choose not to install the ADT using the ADT Installer, you need to find and download the appropriate root filesystem and the cross-development toolchain.
You can find the tarballs for the root filesystem in the same area used for the kernel image. Depending on the type of image you are running, the root filesystem you need differs. For example, if you are developing an application that runs on an image that supports Sato, you need to get a root filesystem that supports Sato.
You can find the cross-development toolchains at
toolchains. Be sure to get the correct toolchain for your development host and your target architecture. See the "Using a Cross-Toolchain Tarball" section in the Yocto Project Application Developer's Guide for information and the "Installing the Toolchain" in the Yocto Project Quick Start for information on finding and installing the correct toolchain based on your host development system and your target architecture.Create and build your application: At this point, you need to have source files for your application. Once you have the files, you can use the Eclipse IDE to import them and build the project. If you are not using Eclipse, you need to use the cross-development tools you have installed to create the image.
Deploy the image with the application: If you are using the Eclipse IDE, you can deploy your image to the hardware or to QEMU through the project's preferences. If you are not using the Eclipse IDE, then you need to deploy the application to the hardware using other methods. Or, if you are using QEMU, you need to use that tool and load your image in for testing.
Test and debug the application: Once your application is deployed, you need to test it. Within the Eclipse IDE, you can use the debugging environment along with the set of user-space tools installed along with the ADT to debug your application. Of course, the same user-space tools are available separately if you choose not to use the Eclipse IDE.
The Eclipse IDE is a popular development environment and it fully supports development using the Yocto Project.
Note
This release of the Yocto Project supports both the Kepler and Juno versions of the Eclipse IDE. Thus, the following information provides setup information for both versions.
When you install and configure the Eclipse Yocto Project Plug-in into the Eclipse IDE, you maximize your Yocto Project experience. Installing and configuring the Plug-in results in an environment that has extensions specifically designed to let you more easily develop software. These extensions allow for cross-compilation, deployment, and execution of your output into a QEMU emulation session as well as actual target hardware. You can also perform cross-debugging and profiling. The environment also supports a suite of tools that allows you to perform remote profiling, tracing, collection of power data, collection of latency data, and collection of performance data.
This section describes how to install and configure the Eclipse IDE Yocto Plug-in and how to use it to develop your application.
To develop within the Eclipse IDE, you need to do the following:
Install the optimal version of the Eclipse IDE.
Configure the Eclipse IDE.
Install the Eclipse Yocto Plug-in.
Configure the Eclipse Yocto Plug-in.
Note
Do not install Eclipse from your distribution's package repository. Be sure to install Eclipse from the official Eclipse download site as directed in the next section.
It is recommended that you have the Kepler 4.3 version of the Eclipse IDE installed on your development system. However, if you currently have the Juno 4.2 version installed and you do not want to upgrade the IDE, you can configure Juno to work with the Yocto Project.
If you do not have the Kepler 4.3 Eclipse IDE installed, you can find the tarball at http://www.eclipse.org/downloads. From that site, choose the Eclipse Standard 4.3 version particular to your development host. This version contains the Eclipse Platform, the Java Development Tools (JDT), and the Plug-in Development Environment.
Once you have downloaded the tarball, extract it into a
clean directory.
For example, the following commands unpack and install the
downloaded Eclipse IDE tarball into a clean directory
using the default name eclipse:
$ cd ~
$ tar -xzvf ~/Downloads/eclipse-standard-kepler-R-linux-gtk-x86_64.tar.gz
This section presents the steps needed to configure the Eclipse IDE.
Before installing and configuring the Eclipse Yocto Plug-in, you need to configure the Eclipse IDE. Follow these general steps:
Start the Eclipse IDE.
Make sure you are in your Workbench and select "Install New Software" from the "Help" pull-down menu.
Select
Kepler - http://download.eclipse.org/releases/keplerfrom the "Work with:" pull-down menu.Note
For Juno, selectJuno - http://download.eclipse.org/releases/junoExpand the box next to "Linux Tools" and select the
LTTng - Linux Tracing Toolkitboxes.Expand the box next to "Mobile and Device Development" and select the following boxes:
C/C++ Remote LaunchRemote System Explorer End-user RuntimeRemote System Explorer User ActionsTarget Management TerminalTCF Remote System Explorer add-inTCF Target Explorer
Expand the box next to "Programming Languages" and select the
Autotools Support for CDTandC/C++ Development Toolsboxes.Complete the installation and restart the Eclipse IDE.
You can install the Eclipse Yocto Plug-in into the Eclipse IDE one of two ways: use the Yocto Project's Eclipse Update site to install the pre-built plug-in or build and install the plug-in from the latest source code.
To install the Eclipse Yocto Plug-in from the update site, follow these steps:
Start up the Eclipse IDE.
In Eclipse, select "Install New Software" from the "Help" menu.
Click "Add..." in the "Work with:" area.
Enter
http://downloads.yoctoproject.org/releases/eclipse-plugin/1.5.2/keplerin the URL field and provide a meaningful name in the "Name" field.Note
If you are using Juno, usehttp://downloads.yoctoproject.org/releases/eclipse-plugin/1.5.2/junoin the URL field.Click "OK" to have the entry added to the "Work with:" drop-down list.
Select the entry for the plug-in from the "Work with:" drop-down list.
Check the boxes next to
Yocto Project ADT Plug-in,Yocto Project Bitbake Commander Plug-in, andYocto Project Documentation plug-in.Complete the remaining software installation steps and then restart the Eclipse IDE to finish the installation of the plug-in.
To install the Eclipse Yocto Plug-in from the latest source code, follow these steps:
Be sure your development system is not using OpenJDK to build the plug-in by doing the following:
Use the Oracle JDK. If you don't have that, go to http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html and download the appropriate tarball for your development system and extract it into your home directory.
In the shell you are going to do your work, export the location of the Oracle Java as follows:
export PATH=~/jdk1.7.0_40/bin:$PATH
In the same shell, create a Git repository with:
$ cd ~ $ git clone git://git.yoctoproject.org/eclipse-poky-keplerNote
If you are using Juno, the repository is located atgit://git.yoctoproject.org/eclipse-poky-juno.For this example, the repository is named
~/eclipse-poky-kepler.Change to the directory where you set up the Git repository:
$ cd ~/eclipse-poky-keplerBe sure you are in the right branch for your Git repository. For this release set the branch to
dora:$ git checkout doraChange to the
scriptsdirectory within the Git repository:$ cd scriptsSet up the local build environment by running the setup script:
$ ./setup.shWhen the script finishes execution, it prompts you with instructions on how to run the
build.shscript, which is also in thescriptsof the Git repository created earlier.Run the
build.shscript as directed. Be sure to provide the name of the Git branch along with the Yocto Project release you are using. Here is an example that uses thedorabranch:$ ECLIPSE_HOME=/home/scottrif/eclipse-poky-kepler/scripts/eclipse ./build.sh dora doraAfter running the script, the file
org.yocto.sdk-<release>-<date>-archive.zipis in the current directory.If necessary, start the Eclipse IDE and be sure you are in the Workbench.
Select "Install New Software" from the "Help" pull-down menu.
Click "Add".
Provide anything you want in the "Name" field.
Click "Archive" and browse to the ZIP file you built in step seven. This ZIP file should not be "unzipped", and must be the
*archive.zipfile created by running thebuild.shscript.Click through the "Okay" buttons.
Check the boxes in the installation window and complete the installation.
Restart the Eclipse IDE if necessary.
At this point you should be able to configure the Eclipse Yocto Plug-in as described in the "Configuring the Eclipse Yocto Plug-in" section.
Configuring the Eclipse Yocto Plug-in involves setting the Cross Compiler options and the Target options. The configurations you choose become the default settings for all projects. You do have opportunities to change them later when you configure the project (see the following section).
To start, you need to do the following from within the Eclipse IDE:
Choose "Preferences" from the "Windows" menu to display the Preferences Dialog.
Click "Yocto Project ADT".
To configure the Cross Compiler Options, you must select the type of toolchain, point to the toolchain, specify the sysroot location, and select the target architecture.
Selecting the Toolchain Type: Choose between
Standalone pre-built toolchainandBuild system derived toolchainfor Cross Compiler Options.Standalone Pre-built Toolchain:Select this mode when you are using a stand-alone cross-toolchain. For example, suppose you are an application developer and do not need to build a target image. Instead, you just want to use an architecture-specific toolchain on an existing kernel and target root filesystem.Build System Derived Toolchain:Select this mode if the cross-toolchain has been installed and built as part of the Build Directory. When you selectBuild system derived toolchain, you are using the toolchain bundled inside the Build Directory.
Point to the Toolchain: If you are using a stand-alone pre-built toolchain, you should be pointing to where it is installed. If you used the ADT Installer script and accepted the default installation directory, the toolchain will be installed in the
/opt/poky/1.5.2directory. Sections "Configuring and Running the ADT Installer Script" and "Using a Cross-Toolchain Tarball" in the Yocto Project Application Developer's Guide describe how to install a stand-alone cross-toolchain.If you are using a system-derived toolchain, the path you provide for the
Toolchain Root Locationfield is the Build Directory. See the "Using BitBake and the Build Directory" section in the Yocto Project Application Developer's Guide for information on how to install the toolchain into the Build Directory.Specify the Sysroot Location: This location is where the root filesystem for the target hardware resides. If you used the ADT Installer script and accepted the default installation directory, then the location is
/opt/poky/<release>. Additionally, when you use the ADT Installer script, the same location is used for the QEMU user-space tools and the NFS boot process.If you used either of the other two methods to install the toolchain or did not accept the ADT Installer script's default installation directory, then the location of the sysroot filesystem depends on where you separately extracted and installed the filesystem.
For information on how to install the toolchain and on how to extract and install the sysroot filesystem, see the "Installing the ADT and Toolchains" section.
Select the Target Architecture: The target architecture is the type of hardware you are going to use or emulate. Use the pull-down
Target Architecturemenu to make your selection. The pull-down menu should have the supported architectures. If the architecture you need is not listed in the menu, you will need to build the image. See the "Building an Image" section of the Yocto Project Quick Start for more information.
You can choose to emulate hardware using the QEMU emulator, or you can choose to run your image on actual hardware.
QEMU:Select this option if you will be using the QEMU emulator. If you are using the emulator, you also need to locate the kernel and specify any custom options.If you selected
Build system derived toolchain, the target kernel you built will be located in the Build Directory intmp/deploy/images/<machine>directory. If you selectedStandalone pre-built toolchain, the pre-built image you downloaded is located in the directory you specified when you downloaded the image.Most custom options are for advanced QEMU users to further customize their QEMU instance. These options are specified between paired angled brackets. Some options must be specified outside the brackets. In particular, the options
serial,nographic, andkvmmust all be outside the brackets. Use theman qemucommand to get help on all the options and their use. The following is an example:serial ‘<-m 256 -full-screen>’Regardless of the mode, Sysroot is already defined as part of the Cross-Compiler Options configuration in the
Sysroot Location:field.External HW:Select this option if you will be using actual hardware.
Click the "OK" to save your plug-in configurations.
You can create two types of projects: Autotools-based, or Makefile-based. This section describes how to create Autotools-based projects from within the Eclipse IDE. For information on creating Makefile-based projects in a terminal window, see the section "Using the Command Line" in the Yocto Project Application Developer's Guide.
To create a project based on a Yocto template and then display the source code, follow these steps:
Select "Project" from the "File -> New" menu.
Double click
CC++.Double click
C Projectto create the project.Expand
Yocto Project ADT Project.Select
Hello World ANSI C Autotools Project. This is an Autotools-based project based on a Yocto template.Put a name in the
Project name:field. Do not use hyphens as part of the name.Click "Next".
Add information in the
AuthorandCopyright noticefields.Be sure the
Licensefield is correct.Click "Finish".
If the "open perspective" prompt appears, click "Yes" so that you in the C/C++ perspective.
The left-hand navigation pane shows your project. You can display your source by double clicking the project's source file.
The earlier section, "Configuring the Eclipse Yocto Plug-in", sets up the default project configurations. You can override these settings for a given project by following these steps:
Select "Change Yocto Project Settings" from the "Project" menu. This selection brings up the Yocto Project Settings Dialog and allows you to make changes specific to an individual project.
By default, the Cross Compiler Options and Target Options for a project are inherited from settings you provide using the Preferences Dialog as described earlier in the "Configuring the Eclipse Yocto Plug-in" section. The Yocto Project Settings Dialog allows you to override those default settings for a given project.
Make your configurations for the project and click "OK". If you are running the Juno version of Eclipse, you can skip down to the next section where you build the project. If you are not working with Juno, you need to reconfigure the project as described in the next step.
Select "Reconfigure Project" from the "Project" menu. This selection reconfigures the project by running
autogen.shin the workspace for your project. The script also runslibtoolize,aclocal,autoconf,autoheader,automake --a, and./configure. Click on the "Console" tab beneath your source code to see the results of reconfiguring your project.
To build the project in Juno, right click on the project in the navigator pane and select "Build Project". If you are not running Juno, select "Build Project" from the "Project" menu. The console should update and you can note the cross-compiler you are using.
To start the QEMU emulator from within Eclipse, follow these steps:
Expose and select "External Tools" from the "Run" menu. Your image should appear as a selectable menu item.
Select your image from the menu to launch the emulator in a new window.
If needed, enter your host root password in the shell window at the prompt. This sets up a
Tap 0connection needed for running in user-space NFS mode.Wait for QEMU to launch.
Once QEMU launches, you can begin operating within that environment. For example, you could determine the IP Address for the user-space NFS by using the
ifconfigcommand.
Once the QEMU emulator is running the image, you can deploy your application using the Eclipse IDE and use then use the emulator to perform debugging. Follow these steps to deploy the application.
Select "Debug Configurations..." from the "Run" menu.
In the left area, expand
C/C++Remote Application.Locate your project and select it to bring up a new tabbed view in the Debug Configurations Dialog.
Enter the absolute path into which you want to deploy the application. Use the "Remote Absolute File Path for C/C++Application:" field. For example, enter
/usr/bin/<programname>.Click on the "Debugger" tab to see the cross-tool debugger you are using.
Click on the "Main" tab.
Create a new connection to the QEMU instance by clicking on "new".
Select
TCF, which means Target Communication Framework.Click "Next".
Clear out the "host name" field and enter the IP Address determined earlier.
Click "Finish" to close the New Connections Dialog.
Use the drop-down menu now in the "Connection" field and pick the IP Address you entered.
Click "Run" to bring up a login screen and login.
Accept the debug perspective.
As mentioned earlier in the manual, several tools exist that enhance your development experience. These tools are aids in developing and debugging applications and images. You can run these user-space tools from within the Eclipse IDE through the "YoctoTools" menu.
Once you pick a tool, you need to configure it for the remote target. Every tool needs to have the connection configured. You must select an existing TCF-based RSE connection to the remote target. If one does not exist, click "New" to create one.
Here are some specifics about the remote tools:
OProfile: Selecting this tool causes theoprofile-serveron the remote target to launch on the local host machine. Theoprofile-viewermust be installed on the local host machine and theoprofile-servermust be installed on the remote target, respectively, in order to use. You must compile and install theoprofile-viewerfrom the source code on your local host machine. Furthermore, in order to convert the target's sample format data into a form that the host can use, you must have OProfile version 0.9.4 or greater installed on the host.You can locate both the viewer and server from http://git.yoctoproject.org/cgit/cgit.cgi/oprofileui/. You can also find more information on setting up and using this tool in the "OProfile" section of the Yocto Project Profiling and Tracing Manual.
Note
Theoprofile-serveris installed by default on thecore-image-sato-sdkimage.Lttng2.0 ust trace import: Selecting this tool transfers the remote target'sLttngtracing data back to the local host machine and uses the Lttng Eclipse plug-in to graphically display the output. For information on how to use Lttng to trace an application, see http://lttng.org/documentation and the "LTTng (Linux Trace Toolkit, next generation)" section, which is in the Yocto Project Profiling and Tracing Manual.Note
Do not useLttng-user space (legacy)tool. This tool no longer has any upstream support.Before you use the
Lttng2.0 ust trace importtool, you need to setup the Lttng Eclipse plug-in and create a Tracing project. Do the following:Select "Open Perspective" from the "Window" menu and then select "Tracing".
Click "OK" to change the Eclipse perspective into the Tracing perspective.
Create a new Tracing project by selecting "Project" from the "File -> New" menu.
Choose "Tracing Project" from the "Tracing" menu.
Generate your tracing data on the remote target.
Select "Lttng2.0 ust trace import" from the "Yocto Project Tools" menu to start the data import process.
Specify your remote connection name.
For the Ust directory path, specify the location of your remote tracing data. Make sure the location ends with
ust(e.g./usr/mysession/ust).Click "OK" to complete the import process. The data is now in the local tracing project you created.
Right click on the data and then use the menu to Select "Generic CTF Trace" from the "Trace Type... -> Common Trace Format" menu to map the tracing type.
Right click the mouse and select "Open" to bring up the Eclipse Lttng Trace Viewer so you view the tracing data.
PowerTOP: Selecting this tool runs PowerTOP on the remote target machine and displays the results in a new view called PowerTOP.The "Time to gather data(sec):" field is the time passed in seconds before data is gathered from the remote target for analysis.
The "show pids in wakeups list:" field corresponds to the
-pargument passed toPowerTOP.LatencyTOP and Perf: LatencyTOP identifies system latency, while Perf monitors the system's performance counter registers. Selecting either of these tools causes an RSE terminal view to appear from which you can run the tools. Both tools refresh the entire screen to display results while they run. For more information on setting up and usingperf, see the "perf" section in the Yocto Project Profiling and Tracing Manual.
Within the Eclipse IDE, you can create a Yocto BitBake Commander project, edit the Metadata, and then use Hob to build a customized image all within one IDE.
To create a Yocto BitBake Commander project, follow these steps:
Select "Other" from the "Window -> Open Perspective" menu and then choose "Bitbake Commander".
Click "OK" to change the perspective to Bitbake Commander.
Select "Project" from the "File -> New" menu to create a new Yocto Bitbake Commander project.
Choose "New Yocto Project" from the "Yocto Project Bitbake Commander" menu and click "Next".
Enter the Project Name and choose the Project Location. The Yocto project's Metadata files will be put under the directory
<project_location>/<project_name>. If that directory does not exist, you need to check the "Clone from Yocto Git Repository" box, which would execute agit clonecommand to get the project's Metadata files.Note
Do not specify your BitBake Commander project location as your Eclipse workspace. Doing so causes an error indicating that the current project overlaps the location of another project. This error occurs even if no such project exits.Select
Finishto create the project.
After you create the Yocto Bitbake Commander project, you
can modify the Metadata
files by opening them in the project.
When editing recipe files (.bb files),
you can view BitBake variable values and information by
hovering the mouse pointer over the variable name and
waiting a few seconds.
To edit the Metadata, follow these steps:
Select your Yocto Bitbake Commander project.
Select "BitBake Recipe" from the "File -> New -> Yocto BitBake Commander" menu to open a new recipe wizard.
Point to your source by filling in the "SRC_URL" field. For example, you can add a recipe to your Source Directory by defining "SRC_URL" as follows:
ftp://ftp.gnu.org/gnu/m4/m4-1.4.9.tar.gzClick "Populate" to calculate the archive md5, sha256, license checksum values and to auto-generate the recipe filename.
Fill in the "Description" field.
Be sure values for all required fields exist.
Click "Finish".
To build and customize the image using Hob from within the Eclipse IDE, follow these steps:
Select your Yocto Bitbake Commander project.
Select "Launch Hob" from the "Project" menu.
Enter the Build Directory where you want to put your final images.
Click "OK" to launch Hob.
Use Hob to customize and build your own images. For information on Hob, see the Hob Project Page on the Yocto Project website.
If you want to develop an application without prior installation of the ADT, you still can employ the Cross Development Toolchain, the QEMU emulator, and a number of supported target image files. You just need to follow these general steps:
Install the cross-development toolchain for your target hardware: For information on how to install the toolchain, see the "Using a Cross-Toolchain Tarball" section in the Yocto Project Application Developer's Guide.
Download the Target Image: The Yocto Project supports several target architectures and has many pre-built kernel images and root filesystem images.
If you are going to develop your application on hardware, go to the
machinesdownload area and choose a target machine area from which to download the kernel image and root filesystem. This download area could have several files in it that support development using actual hardware. For example, the area might contain.hddimgfiles that combine the kernel image with the filesystem, boot loaders, and so forth. Be sure to get the files you need for your particular development process.If you are going to develop your application and then run and test it using the QEMU emulator, go to the
machines/qemudownload area. From this area, go down into the directory for your target architecture (e.g.qemux86_64for an Intel®-based 64-bit architecture). Download kernel, root filesystem, and any other files you need for your process.Note
In order to use the root filesystem in QEMU, you need to extract it. See the "Extracting the Root Filesystem" section for information on how to extract the root filesystem.Develop and Test your Application: At this point, you have the tools to develop your application. If you need to separately install and use the QEMU emulator, you can go to QEMU Home Page to download and learn about the emulator.
You might find it helpful during development to modify the temporary source code used by recipes to build packages. For example, suppose you are developing a patch and you need to experiment a bit to figure out your solution. After you have initially built the package, you can iteratively tweak the source code, which is located in the Build Directory, and then you can force a re-compile and quickly test your altered code. Once you settle on a solution, you can then preserve your changes in the form of patches. You can accomplish these steps all within either a Quilt or Git workflow.
During a build, the unpacked temporary source code used by recipes
to build packages is available in the Build Directory as
defined by the
S variable.
Below is the default value for the S variable as defined in the
meta/conf/bitbake.conf configuration file in the
Source Directory:
S = "${WORKDIR}/${BP}"
You should be aware that many recipes override the S variable.
For example, recipes that fetch their source from Git usually set
S to ${WORKDIR}/git.
Note
TheBP
represents the base recipe name, which consists of the name and version:
BP = "${BPN}-${PV}"
The path to the work directory for the recipe
(WORKDIR) depends
on the recipe name and the architecture of the target device.
For example, here is the work directory for recipes and resulting packages that are
not device-dependent:
${TMPDIR}/work/${PACKAGE_ARCH}-poky-${TARGET_OS}/${PN}/${EXTENDPE}${PV}-${PR}
Let's look at an example without variables.
Assuming a top-level Source Directory
named poky
and a default Build Directory of poky/build,
the following is the work directory for the acl recipe that
creates the acl package:
poky/build/tmp/work/i586-poky-linux/acl/2.2.51-r3/
If your resulting package is dependent on the target device, the work directory varies slightly:
${TMPDIR}/work/${MACHINE}-poky-${TARGET_OS}/${PN}/${EXTENDPE}${PV}-${PR}
Again, assuming top-level Source Directory named poky
and a default Build Directory of poky/build, the
following are the work and temporary source directories, respectively,
for the acl package that is being
built for a MIPS-based device:
poky/build/tmp/work/mips-poky-linux/acl/2.2.51-r2
poky/build/tmp/work/mips-poky-linux/acl/2.2.51-r2/acl-2.2.51
Note
To better understand how the OpenEmbedded build system resolves directories during the build process, see the glossary entries for theWORKDIR,
TMPDIR,
TOPDIR,
PACKAGE_ARCH,
MULTIMACH_TARGET_SYS,
TARGET_OS,
PN,
PV,
EXTENDPE,
and
PR
variables in the Yocto Project Reference Manual.
Now that you know where to locate the directory that has the temporary source code, you can use a Quilt or Git workflow to make your edits, test the changes, and preserve the changes in the form of patches.
Quilt is a powerful tool that allows you to capture source code changes without having a clean source tree. This section outlines the typical workflow you can use to modify temporary source code, test changes, and then preserve the changes in the form of a patch all using Quilt.
Follow these general steps:
Find the Source Code: The temporary source code used by the OpenEmbedded build system is kept in the Build Directory. See the "Finding the Temporary Source Code" section to learn how to locate the directory that has the temporary source code for a particular package.
Change Your Working Directory: You need to be in the directory that has the temporary source code. That directory is defined by the
Svariable.Create a New Patch: Before modifying source code, you need to create a new patch. To create a new patch file, use
quilt newas below:$ quilt new my_changes.patchNotify Quilt and Add Files: After creating the patch, you need to notify Quilt about the files you plan to edit. You notify Quilt by adding the files to the patch you just created:
$ quilt add file1.c file2.c file3.cEdit the Files: Make your changes in the temporary source code to the files you added to the patch.
Test Your Changes: Once you have modified the source code, the easiest way to test your changes is by calling the
compiletask as shown in the following example:$ bitbake -c compile -f <name_of_package>The
-for--forceoption forces the specified task to execute. If you find problems with your code, you can just keep editing and re-testing iteratively until things work as expected.Note
All the modifications you make to the temporary source code disappear once you-c cleanor-c cleanallwith BitBake for the package. Modifications will also disappear if you use therm_workfeature as described in the "Building an Image" section of the Yocto Project Quick Start.Generate the Patch: Once your changes work as expected, you need to use Quilt to generate the final patch that contains all your modifications.
$ quilt refreshAt this point, the
my_changes.patchfile has all your edits made to thefile1.c,file2.c, andfile3.cfiles.You can find the resulting patch file in the
patches/subdirectory of the source (S) directory.Copy the Patch File: For simplicity, copy the patch file into a directory named
files, which you can create in the same directory that holds the recipe (.bb) file or the append (.bbappend) file. Placing the patch here guarantees that the OpenEmbedded build system will find the patch. Next, add the patch into theSRC_URIof the recipe. Here is an example:SRC_URI += "file://my_changes.patch"Increment the Recipe Revision Number: Finally, don't forget to 'bump' the
PRvalue in the recipe since the resulting packages have changed.
Git is an even more powerful tool that allows you to capture source code changes without having a clean source tree. This section outlines the typical workflow you can use to modify temporary source code, test changes, and then preserve the changes in the form of a patch all using Git. For general information on Git as it is used in the Yocto Project, see the "Git" section.
Note
This workflow uses Git only for its ability to manage local changes to the source code and produce patches independent of any version control system used with the Yocto Project.Follow these general steps:
Find the Source Code: The temporary source code used by the OpenEmbedded build system is kept in the Build Directory. See the "Finding the Temporary Source Code" section to learn how to locate the directory that has the temporary source code for a particular package.
Change Your Working Directory: You need to be in the directory that has the temporary source code. That directory is defined by the
Svariable.If needed, initialize a Git Repository: If the recipe you are working with does not use a Git fetcher, you need to set up a Git repository as follows:
$ git init $ git add * $ git commit -m "initial revision"The above Git commands initialize a Git repository that is based on the files in your current working directory, stage all the files, and commit the files. At this point, your Git repository is aware of all the source code files. Any edits you now make to files can be committed later and will be tracked by Git.
Edit the Files: Make your changes to the temporary source code.
Test Your Changes: Once you have modified the source code, the easiest way to test your changes is by calling the
compiletask as shown in the following example:$ bitbake -c compile -f <name_of_package>The
-for--forceoption forces the specified task to execute. If you find problems with your code, you can just keep editing and re-testing iteratively until things work as expected.Note
All the modifications you make to the temporary source code disappear once you-c clean,-c cleansstate, or-c cleanallwith BitBake for the package. Modifications will also disappear if you use therm_workfeature as described in the "Building an Image" section of the Yocto Project Quick Start.See the List of Files You Changed: Use the
git statuscommand to see what files you have actually edited. The ability to have Git track the files you have changed is an advantage that this workflow has over the Quilt workflow. Here is the Git command to list your changed files:$ git statusStage the Modified Files: Use the
git addcommand to stage the changed files so they can be committed as follows:$ git add file1.c file2.c file3.cCommit the Staged Files and View Your Changes: Use the
git commitcommand to commit the changes to the local repository. Once you have committed the files, you can use thegit logcommand to see your changes:$ git commit -m "<commit-summary-message>" $ git logNote
The name of the patch file created in the next step is based on yourcommit-summary-message.Generate the Patch: Once the changes are committed, use the
git format-patchcommand to generate a patch file:$ git format-patch -1Specifying "-1" causes Git to generate the patch file for the most recent commit.
At this point, the patch file has all your edits made to the
file1.c,file2.c, andfile3.cfiles. You can find the resulting patch file in the current directory and it is named according to thegit commitsummary line. The patch file ends with.patch.Copy the Patch File: For simplicity, copy the patch file into a directory named
files, which you can create in the same directory that holds the recipe (.bb) file or the append (.bbappend) file. Placing the patch here guarantees that the OpenEmbedded build system will find the patch. Next, add the patch into theSRC_URIof the recipe. Here is an example:SRC_URI += "file://0001-<commit-summary-message>.patch"Increment the Recipe Revision Number: Finally, don't forget to 'bump' the
PRvalue in the recipe since the resulting packages have changed.
The Hob is a graphical user interface for the OpenEmbedded build system, which is based on BitBake. You can use the Hob to build custom operating system images within the Yocto Project build environment. Hob simply provides a friendly interface over the build system used during development. In other words, building images with the Hob lets you take care of common build tasks more easily.
For a better understanding of Hob, see the project page at http://www.yoctoproject.org/tools-resources/projects/hob on the Yocto Project website. If you follow the "Documentation" link from the Hob page, you will find a short introductory training video on Hob. The following lists some features of Hob:
You can setup and run Hob using these commands:
$ source oe-init-build-env $ hobYou can set the
MACHINEfor which you are building the image.You can modify various policy settings such as the package format with which to build, the parallelism BitBake uses, whether or not to build an external toolchain, and which host to build against.
You can manage layers.
You can select a base image and then add extra packages for your custom build.
You can launch and monitor the build from within Hob.
When debugging certain commands or even when just editing packages,
devshell can be a useful tool.
When you invoke devshell, source files are
extracted into your working directory and patches are applied.
Then, a new terminal is opened and you are placed in the working directory.
In the new terminal, all the OpenEmbedded build-related environment variables are
still defined so you can use commands such as configure and
make.
The commands execute just as if the OpenEmbedded build system were executing them.
Consequently, working this way can be helpful when debugging a build or preparing
software to be used with the OpenEmbedded build system.
Following is an example that uses devshell on a target named
matchbox-desktop:
$ bitbake matchbox-desktop -c devshell
This command spawns a terminal with a shell prompt within the OpenEmbedded build environment.
The OE_TERMINAL
variable controls what type of shell is opened.
For spawned terminals, the following occurs:
The
PATHvariable includes the cross-toolchain.The
pkgconfigvariables find the correct.pcfiles.The
configurecommand finds the Yocto Project site files as well as any other necessary files.
Within this environment, you can run configure or compile
commands as if they were being run by
the OpenEmbedded build system itself.
As noted earlier, the working directory also automatically changes to the
Source Directory (S).
When you are finished, you just exit the shell or close the terminal window.
Note
It is worth remembering that when using devshell
you need to use the full compiler name such as arm-poky-linux-gnueabi-gcc
instead of just using gcc.
The same applies to other applications such as binutils,
libtool and so forth.
BitBake sets up environment variables such as CC
to assist applications, such as make to find the correct tools.
It is also worth noting that devshell still works over
X11 forwarding and similar situations.
- 5.1. Understanding and Creating Layers
- 5.2. Customizing Images
- 5.3. Writing a Recipe to Add a Package to Your Image
- 5.4. Adding a New Machine
- 5.5. Working With Libraries
- 5.6. Creating Partitioned Images
- 5.7. Configuring the Kernel
- 5.8. Patching the Kernel
- 5.9. Creating Your Own Distribution
- 5.10. Building a Tiny System
- 5.11. Working with Packages
- 5.12. Building Software from an External Source
- 5.13. Selecting an Initialization Manager
- 5.14. Excluding Recipes From the Build
- 5.15. Using an External SCM
- 5.16. Creating a Read-Only Root Filesystem
- 5.17. Performing Automated Runtime Testing
- 5.18. Debugging With the GNU Project Debugger (GDB) Remotely
- 5.19. Examining Builds Using the Toaster API
- 5.20. Profiling with OProfile
- 5.21. Maintaining Open Source License Compliance During Your Product's Lifecycle
This chapter describes fundamental procedures such as creating layers, adding new software packages, extending or customizing images, porting work to new hardware (adding a new machine), and so forth. You will find that the procedures documented here occur often in the development cycle using the Yocto Project.
The OpenEmbedded build system supports organizing Metadata into multiple layers. Layers allow you to isolate different types of customizations from each other. You might find it tempting to keep everything in one layer when working on a single project. However, the more modular your Metadata, the easier it is to cope with future changes.
To illustrate how layers are used to keep things modular, consider
machine customizations.
These types of customizations typically reside in a special layer,
rather than a general layer, called a Board Support Package (BSP)
Layer.
Furthermore, the machine customizations should be isolated from
recipes and Metadata that support a new GUI environment,
for example.
This situation gives you a couple of layers: one for the machine
configurations, and one for the GUI environment.
It is important to understand, however, that the BSP layer can
still make machine-specific additions to recipes within the GUI
environment layer without polluting the GUI layer itself
with those machine-specific changes.
You can accomplish this through a recipe that is a BitBake append
(.bbappend) file, which is described later
in this section.
The Source Directory
contains both general layers and BSP
layers right out of the box.
You can easily identify layers that ship with a
Yocto Project release in the Source Directory by their
folder names.
Folders that represent layers typically have names that begin with
the string meta-.
Note
It is not a requirement that a layer name begin with the prefixmeta-, but it's a commonly accepted
standard in the Yocto Project community.
For example, when you set up the Source Directory structure,
you will see several layers:
meta, meta-hob,
meta-skeleton,
meta-yocto, and
meta-yocto-bsp.
Each of these folders represents a distinct layer.
As another example, if you set up a local copy of the
meta-intel Git repository
and then explore the folder of that general layer,
you will discover many Intel-specific BSP layers inside.
For more information on BSP layers, see the
"BSP Layers"
section in the Yocto Project Board Support Package (BSP)
Developer's Guide.
It is very easy to create your own layers to use with the OpenEmbedded build system. The Yocto Project ships with scripts that speed up creating general layers and BSP layers. This section describes the steps you perform by hand to create a layer so that you can better understand them. For information about the layer-creation scripts, see the "Creating a New BSP Layer Using the yocto-bsp Script" section in the Yocto Project Board Support Package (BSP) Developer's Guide and the "Creating a General Layer Using the yocto-layer Script" section further down in this manual.
Follow these general steps to create your layer:
Check Existing Layers: Before creating a new layer, you should be sure someone has not already created a layer containing the Metadata you need. You can see the
OpenEmbedded Metadata Indexfor a list of layers from the OpenEmbedded community that can be used in the Yocto Project.Create a Directory: Create the directory for your layer. While not strictly required, prepend the name of the folder with the string
meta-. For example:meta-mylayer meta-GUI_xyz meta-mymachineCreate a Layer Configuration File: Inside your new layer folder, you need to create a
conf/layer.conffile. It is easiest to take an existing layer configuration file and copy that to your layer'sconfdirectory and then modify the file as needed.The
meta-yocto-bsp/conf/layer.conffile demonstrates the required syntax:# We have a conf and classes directory, add to BBPATH BBPATH .= ":${LAYERDIR}" # We have recipes-* directories, add to BBFILES BBFILES += "${LAYERDIR}/recipes-*/*/*.bb \ ${LAYERDIR}/recipes-*/*/*.bbappend" BBFILE_COLLECTIONS += "yoctobsp" BBFILE_PATTERN_yoctobsp = "^${LAYERDIR}/" BBFILE_PRIORITY_yoctobsp = "5" LAYERVERSION_yoctobsp = "2"Here is an explanation of the example:
The configuration and classes directory is appended to
BBPATH.Note
All non-distro layers, which include all BSP layers, are expected to append the layer directory to theBBPATH. On the other hand, distro layers, such asmeta-yocto, can choose to enforce their own precedence overBBPATH. For an example of that syntax, see thelayer.conffile for themeta-yoctolayer.The recipes for the layers are appended to
BBFILES.The
BBFILE_COLLECTIONSvariable is then appended with the layer name.The
BBFILE_PATTERNvariable is set to a regular expression and is used to match files fromBBFILESinto a particular layer. In this case,LAYERDIRis used to makeBBFILE_PATTERNmatch within the layer's path.The
BBFILE_PRIORITYvariable then assigns a priority to the layer. Applying priorities is useful in situations where the same package might appear in multiple layers and allows you to choose what layer should take precedence.The
LAYERVERSIONvariable optionally specifies the version of a layer as a single number.
Note the use of the
LAYERDIRvariable, which expands to the directory of the current layer.Through the use of the
BBPATHvariable, BitBake locates.bbclassfiles, configuration files, and files that are included withincludeandrequirestatements. For these cases, BitBake uses the first file that matches the name found inBBPATH. This is similar to the way thePATHvariable is used for binaries. We recommend, therefore, that you use unique.bbclassand configuration filenames in your custom layer.Add Content: Depending on the type of layer, add the content. If the layer adds support for a machine, add the machine configuration in a
conf/machine/file within the layer. If the layer adds distro policy, add the distro configuration in aconf/distro/file within the layer. If the layer introduces new recipes, put the recipes you need inrecipes-*subdirectories within the layer.Note
In order to be compliant with the Yocto Project, a layer must contain a README file.
To create layers that are easier to maintain and that will not impact builds for other machines, you should consider the information in the following sections.
Avoid "overlaying" entire recipes from other layers in your
configuration.
In other words, do not copy an entire recipe into your
layer and then modify it.
Rather, use .bbappend files to override
only those parts of the original recipe you need to modify.
Avoid duplicating include files.
Use .bbappend files for each recipe
that uses an include file.
Or, if you are introducing a new recipe that requires
the included file, use the path relative to the original
layer directory to refer to the file.
For example, use
require recipes-core/somepackage/somefile.inc
instead of require somefile.inc.
If you're finding you have to overlay the include file,
it could indicate a deficiency in the include file in
the layer to which it originally belongs.
If this is the case, you need to address that deficiency
instead of overlaying the include file.
For example, consider how support plug-ins for the Qt 4
database are configured.
The Source Directory does not have MySQL or PostgreSQL.
However, OpenEmbedded's layer meta-oe
does.
Consequently, meta-oe uses
.bbappend files to modify the
QT_SQL_DRIVER_FLAGS variable to
enable the appropriate plug-ins.
This variable was added to the qt4.inc
include file in the Source Directory specifically to allow
the meta-oe layer to be able to control
which plug-ins are built.
Proper use of overrides within append files and placement of machine-specific files within your layer can ensure that a build is not using the wrong Metadata and negatively impacting a build for a different machine. Following are some examples:
Modifying Variables to Support a Different Machine: Suppose you have a layer named
meta-onethat adds support for building machine "one". To do so, you use an append file namedbase-files.bbappendand create a dependency on "foo" by altering theDEPENDSvariable:DEPENDS = "foo"The dependency is created during any build that includes the layer
meta-one. However, you might not want this dependency for all machines. For example, suppose you are building for machine "two" but yourbblayers.conffile has themeta-onelayer included. During the build, thebase-filesfor machine "two" will also have the dependency onfoo.To make sure your changes apply only when building machine "one", use a machine override with the
DEPENDSstatement:DEPENDS_one = "foo"You should follow the same strategy when using
_appendand_prependoperations:DEPENDS_append_one = " foo" DEPENDS_prepend_one = "foo "Note
Avoiding "+=" and "=+" and using machine-specific_appendand_prependoperations is recommended as well.Place Machine-Specific Files in Machine-Specific Locations: When you have a base recipe, such as
base-files.bb, that contains aSRC_URIstatement to a file, you can use an append file to cause the build to use your own version of the file. For example, an append file in your layer atmeta-one/recipes-core/base-files/base-files.bbappendcould extendFILESPATHusingFILESEXTRAPATHSas follows:FILESEXTRAPATHS_prepend := "${THISDIR}/${BPN}:"The build for machine "one" will pick up your machine-specific file as long as you have the file in
meta-one/recipes-core/base-files/base-files/. However, if you are building for a different machine and thebblayers.conffile includes themeta-onelayer and the location of your machine-specific file is the first location where that file is found according toFILESPATH, builds for all machines will also use that machine-specific file.You can make sure that a machine-specific file is used for a particular machine by putting the file in a subdirectory specific to the machine. For example, rather than placing the file in
meta-one/recipes-core/base-files/base-files/as shown above, put it inmeta-one/recipes-core/base-files/base-files/one/. Not only does this make sure the file is used only when building for machine "one" but the build process locates the file more quickly.In summary, you need to place all files referenced from
SRC_URIin a machine-specific subdirectory within the layer in order to restrict those files to machine-specific builds.
We also recommend the following:
Store custom layers in a Git repository that uses the
meta-<layer_name>format.Clone the repository alongside other
metadirectories in the Source Directory.
Following these recommendations keeps your Source Directory and its configuration entirely inside the Yocto Project's core base.
Before the OpenEmbedded build system can use your new layer,
you need to enable it.
To enable your layer, simply add your layer's path to the
BBLAYERS
variable in your conf/bblayers.conf file,
which is found in the
Build Directory.
The following example shows how to enable a layer named
meta-mylayer:
LCONF_VERSION = "6"
BBPATH = "${TOPDIR}"
BBFILES ?= ""
BBLAYERS ?= " \
$HOME/poky/meta \
$HOME/poky/meta-yocto \
$HOME/poky/meta-yocto-bsp \
$HOME/poky/meta-mylayer \
"
BBLAYERS_NON_REMOVABLE ?= " \
$HOME/poky/meta \
$HOME/poky/meta-yocto \
"
BitBake parses each conf/layer.conf file
as specified in the BBLAYERS variable
within the conf/bblayers.conf file.
During the processing of each
conf/layer.conf file, BitBake adds the
recipes, classes and configurations contained within the
particular layer to the source directory.
Recipes used to append Metadata to other recipes are called
BitBake append files.
BitBake append files use the .bbappend file
type suffix, while the corresponding recipes to which Metadata
is being appended use the .bb file type
suffix.
A .bbappend file allows your layer to make
additions or changes to the content of another layer's recipe
without having to copy the other recipe into your layer.
Your .bbappend file resides in your layer,
while the main .bb recipe file to
which you are appending Metadata resides in a different layer.
Append files must have the same root names as their corresponding
recipes.
For example, the append file
someapp_1.5.2.bbappend must apply to
someapp_1.5.2.bb.
This means the original recipe and append file names are version
number-specific.
If the corresponding recipe is renamed to update to a newer
version, the corresponding .bbappend file must
be renamed (and possibly updated) as well.
During the build process, BitBake displays an error on starting
if it detects a .bbappend file that does
not have a corresponding recipe with a matching name.
See the
BB_DANGLINGAPPENDS_WARNONLY
variable for information on how to handle this error.
Being able to append information to an existing recipe not only avoids duplication, but also automatically applies recipe changes in a different layer to your layer. If you were copying recipes, you would have to manually merge changes as they occur.
As an example, consider the main formfactor recipe and a
corresponding formfactor append file both from the
Source Directory.
Here is the main formfactor recipe, which is named
formfactor_0.0.bb and located in the
"meta" layer at
meta/recipes-bsp/formfactor:
DESCRIPTION = "Device formfactor information"
SECTION = "base"
LICENSE = "MIT"
LIC_FILES_CHKSUM = "file://${COREBASE}/LICENSE;md5=3f40d7994397109285ec7b81fdeb3b58 \
file://${COREBASE}/meta/COPYING.MIT;md5=3da9cfbcb788c80a0384361b4de20420"
PR = "r41"
SRC_URI = "file://config file://machconfig"
S = "${WORKDIR}"
PACKAGE_ARCH = "${MACHINE_ARCH}"
INHIBIT_DEFAULT_DEPS = "1"
do_install() {
# Only install file if it has a contents
install -d ${D}${sysconfdir}/formfactor/
install -m 0644 ${S}/config ${D}${sysconfdir}/formfactor/
if [ -s "${S}/machconfig" ]; then
install -m 0644 ${S}/machconfig ${D}${sysconfdir}/formfactor/
fi
}
In the main recipe, note the
SRC_URI
variable, which tells the OpenEmbedded build system where to
find files during the build.
Following is the append file, which is named
formfactor_0.0.bbappend and is from the
Crown Bay BSP Layer named
meta-intel/meta-crownbay.
The file is in recipes-bsp/formfactor:
FILESEXTRAPATHS_prepend := "${THISDIR}/${PN}:"
By default, the build system uses the
FILESPATH
variable to locate files.
This append file extends the locations by setting the
FILESEXTRAPATHS
variable.
Setting this variable in the .bbappend
file is the most reliable and recommended method for adding
directories to the search path used by the build system
to find files.
The statement in this example extends the directories to include
${THISDIR}/${PN},
which resolves to a directory named
formfactor in the same directory
in which the append file resides (i.e.
meta-intel/meta-crownbay/recipes-bsp/formfactor/formfactor.
This implies that you must have the supporting directory
structure set up that will contain any files or patches you
will be including from the layer.
Using the immediate expansion assignment operator
:= is important because of the reference to
THISDIR.
The trailing colon character is important as it ensures that
items in the list remain colon-separated.
Note
BitBake automatically defines the
THISDIR variable.
You should never set this variable yourself.
Using _prepend ensures your path will
be searched prior to other paths in the final list.
Also, not all append files add extra files.
Many append files simply exist to add build options
(e.g. systemd).
For these cases, it is not necessary to use the
"_prepend" part of the statement.
Each layer is assigned a priority value.
Priority values control which layer takes precedence if there
are recipe files with the same name in multiple layers.
For these cases, the recipe file from the layer with a higher
priority number takes precedence.
Priority values also affect the order in which multiple
.bbappend files for the same recipe are
applied.
You can either specify the priority manually, or allow the
build system to calculate it based on the layer's dependencies.
To specify the layer's priority manually, use the
BBFILE_PRIORITY
variable.
For example:
BBFILE_PRIORITY_mylayer = "1"
Note
It is possible for a recipe with a lower version number
PV
in a layer that has a higher priority to take precedence.
Also, the layer priority does not currently affect the
precedence order of .conf
or .bbclass files.
Future versions of BitBake might address this.
You can use the BitBake layer management tool to provide a view
into the structure of recipes across a multi-layer project.
Being able to generate output that reports on configured layers
with their paths and priorities and on
.bbappend files and their applicable
recipes can help to reveal potential problems.
Use the following form when running the layer management tool.
$ bitbake-layers <command> [arguments]
The following list describes the available commands:
help:Displays general help or help on a specified command.show-layers:Shows the current configured layers.show-recipes:Lists available recipes and the layers that provide them.show-overlayed:Lists overlayed recipes. A recipe is overlayed when a recipe with the same name exists in another layer that has a higher layer priority.show-appends:Lists.bbappendfiles and the recipe files to which they apply.show-cross-depends:Lists dependency relationships between recipes that cross layer boundaries.flatten:Flattens the layer configuration into a separate output directory. Flattening your layer configuration builds a "flattened" directory that contains the contents of all layers, with any overlayed recipes removed and any.bbappendfiles appended to the corresponding recipes. You might have to perform some manual cleanup of the flattened layer as follows:Non-recipe files (such as patches) are overwritten. The flatten command shows a warning for these files.
Anything beyond the normal layer setup has been added to the
layer.conffile. Only the lowest priority layer'slayer.confis used.Overridden and appended items from
.bbappendfiles need to be cleaned up. The contents of each.bbappendend up in the flattened recipe. However, if there are appended or changed variable values, you need to tidy these up yourself. Consider the following example. Here, thebitbake-layerscommand adds the line#### bbappended ...so that you know where the following lines originate:... DESCRIPTION = "A useful utility" ... EXTRA_OECONF = "--enable-something" ... #### bbappended from meta-anotherlayer #### DESCRIPTION = "Customized utility" EXTRA_OECONF += "--enable-somethingelse"Ideally, you would tidy up these utilities as follows:
... DESCRIPTION = "Customized utility" ... EXTRA_OECONF = "--enable-something --enable-somethingelse" ...
The yocto-layer script simplifies
creating a new general layer.
Note
For information on BSP layers, see the "BSP Layers" section in the Yocto Project Board Specific (BSP) Developer's Guide.The default mode of the script's operation is to prompt you for information needed to generate the layer:
The layer priority
Whether or not to create a sample recipe.
Whether or not to create a sample append file.
Use the yocto-layer create sub-command
to create a new general layer.
In its simplest form, you can create a layer as follows:
$ yocto-layer create mylayer
The previous example creates a layer named
meta-mylayer in the current directory.
As the yocto-layer create command runs,
default values for the prompts appear in brackets.
Pressing enter without supplying anything for the prompts
or pressing enter and providing an invalid response causes the
script to accept the default value.
Once the script completes, the new layer
is created in the current working directory.
The script names the layer by prepending
meta- to the name you provide.
Minimally, the script creates the following within the layer:
The
confdirectory: This directory contains the layer's configuration file. The root name for the file is the same as the root name your provided for the layer (e.g.<layer>.conf).The
COPYING.MITfile: The copyright and use notice for the software.The
READMEfile: A file describing the contents of your new layer.
If you choose to generate a sample recipe file, the script
prompts you for the name for the recipe and then creates it
in <layer>/recipes-example/example/.
The script creates a .bb file and a
directory, which contains a sample
helloworld.c source file, along with
a sample patch file.
If you do not provide a recipe name, the script uses
"example".
If you choose to generate a sample append file, the script
prompts you for the name for the file and then creates it
in <layer>/recipes-example-bbappend/example-bbappend/.
The script creates a .bbappend file and a
directory, which contains a sample patch file.
If you do not provide a recipe name, the script uses
"example".
The script also prompts you for the version of the append file.
The version should match the recipe to which the append file
is associated.
The easiest way to see how the yocto-layer
script works is to experiment with the script.
You can also read the usage information by entering the
following:
$ yocto-layer help
Once you create your general layer, you must add it to your
bblayers.conf file.
Here is an example where a layer named
meta-mylayer is added:
BBLAYERS = ?" \
/usr/local/src/yocto/meta \
/usr/local/src/yocto/meta-yocto \
/usr/local/src/yocto/meta-yocto-bsp \
/usr/local/src/yocto/meta-mylayer \
"
BBLAYERS_NON_REMOVABLE ?= " \
/usr/local/src/yocto/meta \
/usr/local/src/yocto/meta-yocto \
"
Adding the layer to this file enables the build system to locate the layer during the build.
You can customize images to satisfy particular requirements. This section describes several methods and provides guidelines for each.
Probably the easiest way to customize an image is to add a
package by way of the local.conf
configuration file.
Because it is limited to local use, this method generally only
allows you to add packages and is not as flexible as creating
your own customized image.
When you add packages using local variables this way, you need
to realize that these variable changes affect all images at
the same time and might not be what you require.
To add a package to your image using the local configuration
file, use the
IMAGE_INSTALL
variable with the _append operator:
IMAGE_INSTALL_append = " strace"
Use of the syntax is important - specifically, the space between
the quote and the package name, which is
strace in this example.
This space is required since the _append
operator does not add the space.
Furthermore, you must use _append instead
of the += operator if you want to avoid
ordering issues.
The reason for this is because doing so unconditionally appends
to the variable and avoids ordering problems due to the
variable being set in image recipes and
.bbclass files with operators like
?=.
Using _append ensures the operation takes
affect.
As shown in its simplest use,
IMAGE_INSTALL_append affects all images.
It is possible to extend the syntax so that the variable
applies to a specific image only.
Here is an example:
IMAGE_INSTALL_append_pn-core-image-minimal = " strace"
This example adds strace to
core-image-minimal only.
You can add packages using a similar approach through the
CORE_IMAGE_EXTRA_INSTALL
variable.
If you use this variable, only
core-image-* images are affected.
Another method for customizing your image is to enable or
disable high-level image features by using the
IMAGE_FEATURES
and EXTRA_IMAGE_FEATURES
variables.
Although the functions for both variables are nearly equivalent,
best practices dictate using IMAGE_FEATURES
from within a recipe and using
EXTRA_IMAGE_FEATURES from within
your local.conf file, which is found in the
Build Directory.
To understand how these features work, the best reference is
meta/classes/core-image.bbclass.
In summary, the file looks at the contents of the
IMAGE_FEATURES variable and then maps
those contents into a set of package groups.
Based on this information, the build system automatically
adds the appropriate packages to the
IMAGE_INSTALL
variable.
Effectively, you are enabling extra features by extending the
class or creating a custom class for use with specialized image
.bb files.
Use the EXTRA_IMAGE_FEATURES variable
from within your local configuration file.
Using a separate area from which to enable features with
this variable helps you avoid overwriting the features in the
image recipe that are enabled with
IMAGE_FEATURES.
The value of EXTRA_IMAGE_FEATURES is added
to IMAGE_FEATURES within
meta/conf/bitbake.conf.
To illustrate how you can use these variables to modify your
image, consider an example that selects the SSH server.
The Yocto Project ships with two SSH servers you can use
with your images: Dropbear and OpenSSH.
Dropbear is a minimal SSH server appropriate for
resource-constrained environments, while OpenSSH is a
well-known standard SSH server implementation.
By default, the core-image-sato image
is configured to use Dropbear.
The core-image-basic and
core-image-lsb images both
include OpenSSH.
The core-image-minimal image does not
contain an SSH server.
You can customize your image and change these defaults.
Edit the IMAGE_FEATURES variable
in your recipe or use the
EXTRA_IMAGE_FEATURES in your
local.conf file so that it configures the
image you are working with to include
ssh-server-dropbear or
ssh-server-openssh.
Note
See the "Images" section in the Yocto Project Reference Manual for a complete list of image features that ship with the Yocto Project.You can also customize an image by creating a custom recipe that defines additional software as part of the image. The following example shows the form for the two lines you need:
IMAGE_INSTALL = "packagegroup-core-x11-base package1 package2"
inherit core-image
Defining the software using a custom recipe gives you total
control over the contents of the image.
It is important to use the correct names of packages in the
IMAGE_INSTALL
variable.
You must use the OpenEmbedded notation and not the Debian notation for the names
(e.g. eglibc-dev instead of libc6-dev).
The other method for creating a custom image is to base it on an existing image.
For example, if you want to create an image based on core-image-sato
but add the additional package strace to the image,
copy the meta/recipes-sato/images/core-image-sato.bb to a
new .bb and add the following line to the end of the copy:
IMAGE_INSTALL += "strace"
For complex custom images, the best approach for customizing
an image is to create a custom package group recipe that is
used to build the image or images.
A good example of a package group recipe is
meta/recipes-core/packagegroups/packagegroup-core-boot.bb.
The
PACKAGES
variable lists the package group packages you wish to produce.
inherit packagegroup sets appropriate
default values and automatically adds -dev,
-dbg, and -ptest
complementary packages for every package specified in
PACKAGES.
Note that the inherit line should be towards
the top of the recipe, certainly before you set
PACKAGES.
For each package you specify in PACKAGES,
you can use
RDEPENDS
and
RRECOMMENDS
entries to provide a list of packages the parent task package
should contain.
Following is an example:
DESCRIPTION = "My Custom Package Groups"
inherit packagegroup
PACKAGES = "\
packagegroup-custom-apps \
packagegroup-custom-tools \
"
RDEPENDS_packagegroup-custom-apps = "\
dropbear \
portmap \
psplash"
RDEPENDS_packagegroup-custom-tools = "\
oprofile \
oprofileui-server \
lttng-control \
lttng-viewer"
RRECOMMENDS_packagegroup-custom-tools = "\
kernel-module-oprofile"
In the previous example, two package group packages are created with their dependencies and their
recommended package dependencies listed: packagegroup-custom-apps, and
packagegroup-custom-tools.
To build an image using these package group packages, you need to add
packagegroup-custom-apps and/or
packagegroup-custom-tools to
IMAGE_INSTALL.
For other forms of image dependencies see the other areas of this section.
Recipes let you define packages you can add to your image.
Writing a recipe means creating a .bb file that sets some
variables.
For information on variables that are useful for recipes and for information about recipe naming
issues, see the
"Required"
section of the Yocto Project Reference Manual.
Before writing a recipe from scratch, it is often useful to check whether someone else has written one already. OpenEmbedded is a good place to look as it has a wider scope and range of packages. Because the Yocto Project aims to be compatible with OpenEmbedded, most recipes you find there should work for you.
For new packages, the simplest way to add a recipe is to base it on a similar pre-existing recipe. The sections that follow provide some examples that show how to add standard types of packages.
Note
When writing shell functions, you need to be aware of BitBake's curly brace parsing. If a recipe uses a closing curly brace within the function and the character has no leading spaces, BitBake produces a parsing error. If you use a pair of curly brace in a shell function, the closing curly brace must not be located at the start of the line without leading spaces.
Here is an example that causes BitBake to produce a parsing error:
fakeroot create_shar() {
cat << "EOF" > ${SDK_DEPLOY}/${TOOLCHAIN_OUTPUTNAME}.sh
usage()
{
echo "test"
###### The following "}" at the start of the line causes a parsing error ######
}
EOF
}
Writing the recipe this way avoids the error:
fakeroot create_shar() {
cat << "EOF" > ${SDK_DEPLOY}/${TOOLCHAIN_OUTPUTNAME}.sh
usage()
{
echo "test"
######The following "}" with a leading space at the start of the line avoids the error ######
}
EOF
}
Building an application from a single file that is stored locally (e.g. under
files/) requires a recipe that has the file listed in
the
SRC_URI
variable.
Additionally, you need to manually write the do_compile and
do_install tasks.
The S
variable defines the
directory containing the source code, which is set to
WORKDIR in this case - the directory BitBake uses for the build.
DESCRIPTION = "Simple helloworld application"
SECTION = "examples"
LICENSE = "MIT"
LIC_FILES_CHKSUM = "file://${COMMON_LICENSE_DIR}/MIT;md5=0835ade698e0bcf8506ecda2f7b4f302"
PR = "r0"
SRC_URI = "file://helloworld.c"
S = "${WORKDIR}"
do_compile() {
${CC} helloworld.c -o helloworld
}
do_install() {
install -d ${D}${bindir}
install -m 0755 helloworld ${D}${bindir}
}
By default, the helloworld, helloworld-dbg,
and helloworld-dev packages are built.
For information on how to customize the packaging process, see the
"Splitting an Application
into Multiple Packages" section.
Applications that use Autotools such as autoconf and
automake require a recipe that has a source archive listed in
SRC_URI and
also inherits Autotools, which instructs BitBake to use the
autotools.bbclass file, which contains the definitions of all the steps
needed to build an Autotool-based application.
The result of the build is automatically packaged.
And, if the application uses NLS for localization, packages with local information are
generated (one package per language).
Following is one example: (hello_2.3.bb)
DESCRIPTION = "GNU Helloworld application"
SECTION = "examples"
LICENSE = "GPLv2+"
LIC_FILES_CHKSUM = "file://COPYING;md5=751419260aa954499f7abaabaa882bbe"
PR = "r0"
SRC_URI = "${GNU_MIRROR}/hello/hello-${PV}.tar.gz"
inherit autotools gettext
The variable
LIC_FILES_CHKSUM
is used to track source license changes as described in the
"Tracking License Changes" section.
You can quickly create Autotool-based recipes in a manner similar to the previous example.
Applications that use GNU make also require a recipe that has
the source archive listed in
SRC_URI.
You do not need to add a do_compile step since by default BitBake
starts the make command to compile the application.
If you need additional make options, you should store them in the
EXTRA_OEMAKE
variable.
BitBake passes these options into the make GNU invocation.
Note that a do_install task is still required.
Otherwise, BitBake runs an empty do_install task by default.
Some applications might require extra parameters to be passed to the compiler.
For example, the application might need an additional header path.
You can accomplish this by adding to the
CFLAGS variable.
The following example shows this:
CFLAGS_prepend = "-I ${S}/include "
In the following example, mtd-utils is a makefile-based package:
DESCRIPTION = "Tools for managing memory technology devices."
SECTION = "base"
DEPENDS = "zlib lzo e2fsprogs util-linux"
HOMEPAGE = "http://www.linux-mtd.infradead.org/"
LICENSE = "GPLv2+"
LIC_FILES_CHKSUM = "file://COPYING;md5=0636e73ff0215e8d672dc4c32c317bb3 \
file://include/common.h;beginline=1;endline=17;md5=ba05b07912a44ea2bf81ce409380049c"
SRC_URI = "git://git.infradead.org/mtd-utils.git;protocol=git;tag=995cfe51b0a3cf32f381c140bf72b21bf91cef1b \
file://add-exclusion-to-mkfs-jffs2-git-2.patch"
S = "${WORKDIR}/git/"
PR = "r1"
EXTRA_OEMAKE = "'CC=${CC}' 'RANLIB=${RANLIB}' 'AR=${AR}' \
'CFLAGS=${CFLAGS} -I${S}/include -DWITHOUT_XATTR' 'BUILDDIR=${S}'"
do_install () {
oe_runmake install DESTDIR=${D} SBINDIR=${sbindir} MANDIR=${mandir} \
INCLUDEDIR=${includedir}
install -d ${D}${includedir}/mtd/
for f in ${S}/include/mtd/*.h; do
install -m 0644 $f ${D}${includedir}/mtd/
done
}
PARALLEL_MAKE = ""
BBCLASSEXTEND = "native"
If your sources are available as a tarball instead of a Git repository, you
will need to provide the URL to the tarball as well as an
md5 or sha256 sum of
the download.
Here is an example:
SRC_URI="ftp://ftp.infradead.org/pub/mtd-utils/mtd-utils-1.4.9.tar.bz2"
SRC_URI[md5sum]="82b8e714b90674896570968f70ca778b"
You can generate the md5 or sha256 sums
by using the md5sum or sha256sum commands
with the target file as the only argument.
Here is an example:
$ md5sum mtd-utils-1.4.9.tar.bz2
82b8e714b90674896570968f70ca778b mtd-utils-1.4.9.tar.bz2
You can use the variables
PACKAGES and
FILES
to split an application into multiple packages.
Following is an example that uses the libXpm recipe.
By default, this recipe generates a single package that contains the library along
with a few binaries.
You can modify the recipe to split the binaries into separate packages:
require xorg-lib-common.inc
DESCRIPTION = "X11 Pixmap library"
LICENSE = "X-BSD"
LIC_FILES_CHKSUM = "file://COPYING;md5=3e07763d16963c3af12db271a31abaa5"
DEPENDS += "libxext libsm libxt"
PR = "r3"
PE = "1"
XORG_PN = "libXpm"
PACKAGES =+ "sxpm cxpm"
FILES_cxpm = "${bindir}/cxpm"
FILES_sxpm = "${bindir}/sxpm"
In the previous example, we want to ship the sxpm
and cxpm binaries in separate packages.
Since bindir would be packaged into the main
PN
package by default, we prepend the PACKAGES
variable so additional package names are added to the start of list.
This results in the extra FILES_*
variables then containing information that define which files and
directories go into which packages.
Files included by earlier packages are skipped by latter packages.
Thus, the main PN package
does not include the above listed files.
To add a post-installation script to a package, add a
pkg_postinst_PACKAGENAME() function to the
.bb file and use
PACKAGENAME as the name of the package you want to attach to the
postinst script.
Normally,
PN
can be used, which automatically expands to PACKAGENAME.
A post-installation function has the following structure:
pkg_postinst_PACKAGENAME () {
#!/bin/sh -e
# Commands to carry out
}
The script defined in the post-installation function is called when the root filesystem is created. If the script succeeds, the package is marked as installed. If the script fails, the package is marked as unpacked and the script is executed when the image boots again.
Sometimes it is necessary for the execution of a post-installation script to be delayed until the first boot. For example, the script might need to be executed on the device itself. To delay script execution until boot time, use the following structure in the post-installation script:
pkg_postinst_PACKAGENAME () {
#!/bin/sh -e
if [ x"$D" = "x" ]; then
# Actions to carry out on the device go here
else
exit 1
fi
}
The previous example delays execution until the image boots again because the
D
variable points
to the directory containing the image when the root filesystem is created at build time but
is unset when executed on the first boot.
Adding a new machine to the Yocto Project is a straightforward process.
This section provides information that gives you an idea of the changes you must make.
The information covers adding machines similar to those the Yocto Project already supports.
Although well within the capabilities of the Yocto Project, adding a totally new architecture
might require
changes to gcc/eglibc and to the site information, which is
beyond the scope of this manual.
For a complete example that shows how to add a new machine, see the "Creating a New BSP Layer Using the yocto-bsp Script" in the Yocto Project Board Support Package (BSP) Developer's Guide.
To add a machine configuration, you need to add a .conf file
with details of the device being added to the conf/machine/ file.
The name of the file determines the name the OpenEmbedded build system
uses to reference the new machine.
The most important variables to set in this file are as follows:
TARGET_ARCH(e.g. "arm")PREFERRED_PROVIDER_virtual/kernel(see below)MACHINE_FEATURES(e.g. "apm screen wifi")
You might also need these variables:
SERIAL_CONSOLES(e.g. "115200;ttyS0 115200;ttyS1")KERNEL_IMAGETYPE(e.g. "zImage")IMAGE_FSTYPES(e.g. "tar.gz jffs2")
You can find full details on these variables in the reference section.
You can leverage many existing machine .conf files from
meta/conf/machine/.
The OpenEmbedded build system needs to be able to build a kernel for the machine.
You need to either create a new kernel recipe for this machine, or extend an
existing recipe.
You can find several kernel examples in the
Source Directory at meta/recipes-kernel/linux
that you can use as references.
If you are creating a new recipe, normal recipe-writing rules apply for setting
up a
SRC_URI.
Thus, you need to specify any necessary patches and set
S to point at the source code.
You need to create a configure task that configures the
unpacked kernel with a defconfig.
You can do this by using a make defconfig command or,
more commonly, by copying in a suitable defconfig file and then running
make oldconfig.
By making use of inherit kernel and potentially some of the
linux-*.inc files, most other functionality is
centralized and the defaults of the class normally work well.
If you are extending an existing kernel, it is usually a matter of adding a
suitable defconfig file.
The file needs to be added into a location similar to defconfig files
used for other machines in a given kernel.
A possible way to do this is by listing the file in the
SRC_URI and adding the machine to the expression in
COMPATIBLE_MACHINE:
COMPATIBLE_MACHINE = '(qemux86|qemumips)'
A formfactor configuration file provides information about the target hardware for which the image is being built and information that the build system cannot obtain from other sources such as the kernel. Some examples of information contained in a formfactor configuration file include framebuffer orientation, whether or not the system has a keyboard, the positioning of the keyboard in relation to the screen, and the screen resolution.
The build system uses reasonable defaults in most cases.
However, if customization is
necessary, you need to create a machconfig file
in the meta/recipes-bsp/formfactor/files
directory.
This directory contains directories for specific machines such as
qemuarm and qemux86.
For information about the settings available and the defaults, see the
meta/recipes-bsp/formfactor/files/config file found in the
same area.
Following is an example for qemuarm:
HAVE_TOUCHSCREEN=1
HAVE_KEYBOARD=1
DISPLAY_CAN_ROTATE=0
DISPLAY_ORIENTATION=0
#DISPLAY_WIDTH_PIXELS=640
#DISPLAY_HEIGHT_PIXELS=480
#DISPLAY_BPP=16
DISPLAY_DPI=150
DISPLAY_SUBPIXEL_ORDER=vrgb
Libraries are an integral part of your system. This section describes some common practices you might find helpful when working with libraries to build your system:
If you are building a library and the library offers static linking, you can control
which static library files (*.a files) get included in the
built library.
The PACKAGES
and FILES_*
variables in the
meta/conf/bitbake.conf configuration file define how files installed
by the do_install task are packaged.
By default, the PACKAGES variable contains
${PN}-staticdev, which includes all static library files.
Note
Some previously released versions of the Yocto Project defined the static library files through${PN}-dev.
Following, is part of the BitBake configuration file. You can see where the static library files are defined:
PACKAGES = "${PN}-dbg ${PN} ${PN}-doc ${PN}-dev ${PN}-staticdev ${PN}-locale"
PACKAGES_DYNAMIC = "${PN}-locale-*"
FILES = ""
FILES_${PN} = "${bindir}/* ${sbindir}/* ${libexecdir}/* ${libdir}/lib*${SOLIBS} \
${sysconfdir} ${sharedstatedir} ${localstatedir} \
${base_bindir}/* ${base_sbindir}/* \
${base_libdir}/*${SOLIBS} \
${datadir}/${BPN} ${libdir}/${BPN}/* \
${datadir}/pixmaps ${datadir}/applications \
${datadir}/idl ${datadir}/omf ${datadir}/sounds \
${libdir}/bonobo/servers"
FILES_${PN}-doc = "${docdir} ${mandir} ${infodir} ${datadir}/gtk-doc \
${datadir}/gnome/help"
SECTION_${PN}-doc = "doc"
FILES_${PN}-dev = "${includedir} ${libdir}/lib*${SOLIBSDEV} ${libdir}/*.la \
${libdir}/*.o ${libdir}/pkgconfig ${datadir}/pkgconfig \
${datadir}/aclocal ${base_libdir}/*.o"
SECTION_${PN}-dev = "devel"
ALLOW_EMPTY_${PN}-dev = "1"
RDEPENDS_${PN}-dev = "${PN} (= ${EXTENDPKGV})"
FILES_${PN}-staticdev = "${libdir}/*.a ${base_libdir}/*.a"
SECTION_${PN}-staticdev = "devel"
RDEPENDS_${PN}-staticdev = "${PN}-dev (= ${EXTENDPKGV})"
The build system offers the ability to build libraries with different target optimizations or architecture formats and combine these together into one system image. You can link different binaries in the image against the different libraries as needed for specific use cases. This feature is called "Multilib."
An example would be where you have most of a system compiled in 32-bit mode using 32-bit libraries, but you have something large, like a database engine, that needs to be a 64-bit application and uses 64-bit libraries. Multilib allows you to get the best of both 32-bit and 64-bit libraries.
While the Multilib feature is most commonly used for 32 and 64-bit differences, the approach the build system uses facilitates different target optimizations. You could compile some binaries to use one set of libraries and other binaries to use other different sets of libraries. The libraries could differ in architecture, compiler options, or other optimizations.
This section overviews the Multilib process only. For more details on how to implement Multilib, see the Multilib wiki page.
Aside from this wiki page, several examples exist in the
meta-skeleton
layer found in the
Source Directory:
conf/multilib-example.confconfiguration fileconf/multilib-example2.confconfiguration filerecipes-multilib/images/core-image-multilib-example.bbrecipe
User-specific requirements drive the Multilib feature. Consequently, there is no one "out-of-the-box" configuration that likely exists to meet your needs.
In order to enable Multilib, you first need to ensure your recipe is
extended to support multiple libraries.
Many standard recipes are already extended and support multiple libraries.
You can check in the meta/conf/multilib.conf
configuration file in the
Source Directory to see how this is
done using the
BBCLASSEXTEND
variable.
Eventually, all recipes will be covered and this list will be unneeded.
For the most part, the Multilib class extension works automatically to
extend the package name from ${PN} to
${MLPREFIX}${PN}, where MLPREFIX
is the particular multilib (e.g. "lib32-" or "lib64-").
Standard variables such as
DEPENDS,
RDEPENDS,
RPROVIDES,
RRECOMMENDS,
PACKAGES,
and PACKAGES_DYNAMIC are automatically extended by the system.
If you are extending any manual code in the recipe, you can use the
${MLPREFIX} variable to ensure those names are extended
correctly.
This automatic extension code resides in multilib.bbclass.
After you have set up the recipes, you need to define the actual
combination of multiple libraries you want to build.
You accomplish this through your local.conf
configuration file in the
Build Directory.
An example configuration would be as follows:
MACHINE = "qemux86-64"
require conf/multilib.conf
MULTILIBS = "multilib:lib32"
DEFAULTTUNE_virtclass-multilib-lib32 = "x86"
IMAGE_INSTALL = "lib32-connman"
This example enables an
additional library named lib32 alongside the
normal target packages.
When combining these "lib32" alternatives, the example uses "x86" for tuning.
For information on this particular tuning, see
meta/conf/machine/include/ia32/arch-ia32.inc.
The example then includes lib32-connman
in all the images, which illustrates one method of including a
multiple library dependency.
You can use a normal image build to include this dependency,
for example:
$ bitbake core-image-sato
You can also build Multilib packages specifically with a command like this:
$ bitbake lib32-connman
Different packaging systems have different levels of native Multilib support. For the RPM Package Management System, the following implementation details exist:
A unique architecture is defined for the Multilib packages, along with creating a unique deploy folder under
tmp/deploy/rpmin the Build Directory. For example, considerlib32in aqemux86-64image. The possible architectures in the system are "all", "qemux86_64", "lib32_qemux86_64", and "lib32_x86".The
${MLPREFIX}variable is stripped from${PN}during RPM packaging. The naming for a normal RPM package and a Multilib RPM package in aqemux86-64system resolves to something similar tobash-4.1-r2.x86_64.rpmandbash-4.1.r2.lib32_x86.rpm, respectively.When installing a Multilib image, the RPM backend first installs the base image and then installs the Multilib libraries.
The build system relies on RPM to resolve the identical files in the two (or more) Multilib packages.
For the IPK Package Management System, the following implementation details exist:
The
${MLPREFIX}is not stripped from${PN}during IPK packaging. The naming for a normal RPM package and a Multilib IPK package in aqemux86-64system resolves to something likebash_4.1-r2.x86_64.ipkandlib32-bash_4.1-rw_x86.ipk, respectively.The IPK deploy folder is not modified with
${MLPREFIX}because packages with and without the Multilib feature can exist in the same folder due to the${PN}differences.IPK defines a sanity check for Multilib installation using certain rules for file comparison, overridden, etc.
Situations can exist where you need to install and use multiple versions of the same library on the same system at the same time. These situations almost always exist when a library API changes and you have multiple pieces of software that depend on the separate versions of the library. To accommodate these situations, you can install multiple versions of the same library in parallel on the same system.
The process is straight forward as long as the libraries use
proper versioning.
With properly versioned libraries, all you need to do to
individually specify the libraries is create separate,
appropriately named recipes where the
PN part of the
name includes a portion that differentiates each library version
(e.g.the major part of the version number).
Thus, instead of having a single recipe that loads one version
of a library (e.g. clutter), you provide
multiple recipes that result in different versions
of the libraries you want.
As an example, the following two recipes would allow the
two separate versions of the clutter
library to co-exist on the same system:
clutter-1.6_1.6.20.bb
clutter-1.8_1.8.4.bb
Additionally, if you have other recipes that depend on a given
library, you need to use the
DEPENDS
variable to create the dependency.
Continuing with the same example, if you want to have a recipe
depend on the 1.8 version of the clutter
library, use the following in your recipe:
DEPENDS = "clutter-1.8"
Creating an image for a particular hardware target using the OpenEmbedded build system does not necessarily mean you can boot that image as is on your device. Physical devices accept and boot images in various ways depending on the specifics of the device. Usually, information about the hardware can tell you what image format the device requires. Should your device require multiple partitions on an SD card, flash, or an HDD, you can use the OpenEmbedded Image Creator () to create the properly partitioned image.
The wic command generates partitioned images
from existing OpenEmbedded build artifacts.
Image generation is driven by partitioning commands contained
in an Openembedded kickstart file (.wks)
specified either directly on the command-line or as one of a
selection of canned .wks files
(see 'wic list images').
When applied to a given set of build artifacts, the result is an
image or set of images that can be directly written onto media and
used on a particular system.
This section provides some background information on
wic, describes what you need to have in
place to run the tool, provides instruction on how to use
wic, and provides several examples.
This section provides some background on the
wic utility.
While none of this information is required to use
wic, you might find it interesting.
The name "wic" is derived from OpenEmbedded Image Creator (oeic). The "oe" diphthong in "oeic" was promoted to the letter "w", because "oeic" is both difficult to remember and pronounce.
wicis loosely based on the Meego Image Creator (mic) framework. Thewicimplementation has been heavily modified to make direct use of OpenEmbedded build artifacts instead of package installation and configuration, which are already incorporated within the OpenEmbedded artifacts.wicis a completely independent standalone utility that initially provides easier-to-use and more flexible replacements for a couple bits of existing functionality in OE Core'sdirectdisk.bbclassandmkefidisk.shscript. The replaced scripts are implemented by a general-purpose partitioning language based on Red Hat kickstart syntax. Underlying code forwicsucceeded from several projects over time.
In order to use the wic utility with the
OpenEmbedded Build system, you need to meet the following
requirements:
The Linux distribution on your development host must support the Yocto Project. See the "Supported Linux Distributions" section in the Yocto Project Reference Manual for this list of distributions.
The standard system utilities, such as
cp, must be installed on your development host system.The GNU Parted package must be installed on your development host system.
Have the build artifacts already available. You must already have created an image using the Openembedded build system (e.g.
core-image-minimal. It might seem redundant to generate an image in order to create an image usingwic, but the artifacts are needed and they are generated with the build system.You must have sourced one of the build environment setup scripts (i.e.
oe-init-build-envoroe-init-build-env-memres) found in the Build Directory.
You can get general help for the wic
by entering the wic command by itself
or by entering the command with a help argument as follows:
$ wic -h
$ wic --help
Currently, wic supports two commands:
create and list.
You can get help for these commands as follows:
$ wic help <command>
You can find more out about the images
wic creates using the provided
kickstart files with the following form of the command:
$ wic list <image> help
Where <image> is either
directdisk or
mkefidisk.
You can run wic in two modes: Raw and
Cooked:
Raw Mode: You explicitly specify build artifacts through command-line arguments.
Cooked Mode: The current
MACHINEsetting and image name are used to automatically locate and provide the build artifacts.
The general form of the 'wic' command in raw mode is:
$ wic create <image_name>.wks -r <rootfs_dir> -b <bootimg_dir> /
-k <kernel_dir> -n <native_sysroot>
Note
You do not need root privileges to runwic.
In fact, you should not run as root when using the
utility.
Following is a description of the wic
parameters and options:
<image_name>.wks: An OpenEmbedded kickstart file. You can provide your own custom file or use a file from a set of provided files as described following this list.-r <rootfs_dir>: Specifies the path to the root filesystem directory to be used and the.wksroot filesystem source.-b <bootimg_dir>: Specifies the path to the directory that contains the boot artifacts (e.g. theEFIorsyslinuxdirectories) to use as the.wksboot image source.-k <kernel_dir>: Specifies the path to the dir containing the kernel to use in the.wksboot image.-n <native_sysroot>: Specifies the path to the native sysroot that contains the tools used to build the image.
The general form of the wic command
using Cooked Mode is:
$ wic create <kickstart_file> -e <image_name>
This form is the simplest and most user-friendly, as it
does not require specifying all individual parameters.
All you need to provide is your own
.wks file or one provided with the
release.
Following is a description of the wic
parameters and options:
<kickstart>: An OpenEmbedded kickstart file. You can provide your own custom file or supplied file.-e <image_name>: Specifies the image built using the OpenEmbedded build system.
If you do not want to create your own
.wks file, you can use a provided
file.
Use the following command to list the available files:
$ wic list images
mkefidisk Create an EFI disk image
directdisk Create a 'pcbios' direct disk image
When you use a provided file, you do not have to use the
.wks extension.
Here is an example in Raw Mode that uses the
directdisk file:
$ wic create directdisk -r <rootfs_dir> -b <bootimg_dir> \
-k <kernel_dir> -n <native_sysroot>
Here are the actual partition language commands
used in the mkefidisk.wks file to generate
an image:
# short-description: Create an EFI disk image
# long-description: Creates a partitioned EFI disk image that the user
# can directly dd to boot media.
part /boot --source bootimg --ondisk sda --fstype=efi --label msdos --active --align 1024
part / --source rootfs --ondisk sda --fstype=ext3 --label platform --align 1024
part swap --ondisk sda --size 44 --label swap1 --fstype=swap
bootloader --timeout=10 --append="rootwait rootfstype=ext3 console=ttyPCH0,115200 console=tty0 vmalloc=256MB snd-hda- intel.enable_msi=0"
This section provides several examples that show how to use
the wic utility.
All the examples assume the list of requirements in the
"Requirements" section
have been met.
The examples assume the previously generated image is
core-image-minimal.
This example runs in Cooked Mode and uses the
mkefidisk kickstart file:
$ wic create mkefidisk -e core-image-minimal
Checking basic build environment...
Done.
Creating image(s)...
Info: The new image(s) can be found here:
/var/tmp/wic/build/mkefidisk-201310230946-sda.direct
The following build artifacts were used to create the image(s):
ROOTFS_DIR: /home/trz/yocto/yocto-image/build/tmp/work/minnow-poky-linux/core-image-minimal/1.0-r0/rootfs
BOOTIMG_DIR: /home/trz/yocto/yocto-image/build/tmp/work/minnow-poky-linux/core-image-minimal/1.0-r0/core-image-minimal-1.0/hddimg
KERNEL_DIR: /home/trz/yocto/yocto-image/build/tmp/sysroots/minnow/usr/src/kernel
NATIVE_SYSROOT: /home/trz/yocto/yocto-image/build/tmp/sysroots/x86_64-linux
The image(s) were created using OE kickstart file:
/home/trz/yocto/yocto-image/scripts/lib/image/canned-wks/mkefidisk.wks
This example shows the easiest way to create an image
by running in Cooked Mode and using the
-e option with a provided kickstart
file.
All that is necessary is to specify the image used to
generate the artifacts.
Your local.conf needs to have the
MACHINE
variable set to the machine you are using, which is
"minnow" in this example.
The output specifies exactly which image was
created as well as where it was created.
The output also names the artifacts used and the exact
.wks script that was used to generate
the image.
Note
You should always verify the details provided in the output to make sure that the image was indeed created exactly as expected.
Continuing with the example, you can now directly
dd the image to a USB stick, or
whatever media for which you built your image,
and boot the resulting media:
$ sudo dd if=/var/tmp/wic/build/mkefidisk-201310230946-sda.direct of=/dev/sdb
[sudo] password for trz:
182274+0 records in
182274+0 records out
93324288 bytes (93 MB) copied, 14.4777 s, 6.4 MB/s
[trz@empanada ~]$ sudo eject /dev/sdb
Because wic image creation is driven
by the kickstart file, it is easy to affect image creation
by changing the parameters in the file.
This next example demonstrates that through modification
of the directdisk kickstart file.
As mentioned earlier, you can use the command
wic list images to show the list
of provided kickstart files.
The directory in which these files reside is
scripts/lib/image/canned-wks/
located in the
Source Directory.
Because the available files reside in this directory, you
can create and add your own custom files to the directory.
Subsequent use of the wic list images
command would then include your kickstart files.
In this example, the existing
directdisk file already does most
of what is needed.
However, for the hardware in this example, the image will
need to boot from sdb instead of
sda, which is what the
directdisk kickstart file uses.
The example begins by making a copy of the
directdisk.wks file in the
scripts/lib/image/canned-wks
directory and then changing the lines that specify the
target disk from which to boot.
$ cp /home/trz/yocto/yocto-image/scripts/lib/image/canned-wks/directdisk.wks /home/trz/yocto/yocto-image/scripts/lib/image/canned-wks/directdisksdb.wks
Next, the example modifies the
directdisksdb.wks file and changes all
instances of "--ondisk sda"
to "--ondisk sdb".
The example changes the following two lines and leaves the
remaining lines untouched:
part /boot --source bootimg --ondisk sdb --fstype=msdos --label boot --active --align 1024
part / --source rootfs --ondisk sdb --fstype=ext3 --label platform --align 1024
Once the lines are changed, the example generates the
directdisksdb image.
The command points the process at the
core-image-minimal artifacts for the
Next Unit of Computing (nuc)
MACHINE
the local.conf.
$ wic create directdisksdb -e core-image-minimal
Checking basic build environment...
Done.
Creating image(s)...
Info: The new image(s) can be found here:
/var/tmp/wic/build/directdisksdb-201310231131-sdb.direct
The following build artifacts were used to create the image(s):
ROOTFS_DIR: /home/trz/yocto/yocto-image/build/tmp/work/nuc-poky-linux/core-image-minimal/1.0-r0/rootfs
BOOTIMG_DIR: /home/trz/yocto/yocto-image/build/tmp/sysroots/nuc/usr/share
KERNEL_DIR: /home/trz/yocto/yocto-image/build/tmp/sysroots/nuc/usr/src/kernel
NATIVE_SYSROOT: /home/trz/yocto/yocto-image/build/tmp/sysroots/x86_64-linux
The image(s) were created using OE kickstart file:
/home/trz/yocto/yocto-image/scripts/lib/image/canned-wks/directdisksdb.wks
Continuing with the example, you can now directly
dd the image to a USB stick, or
whatever media for which you built your image,
and boot the resulting media:
$ sudo dd if=/var/tmp/wic/build/directdisksdb-201310231131-sdb.direct of=/dev/sdb
86018+0 records in
86018+0 records out
44041216 bytes (44 MB) copied, 13.0734 s, 3.4 MB/s
[trz@empanada tmp]$ sudo eject /dev/sdb
This example creates an image based on
core-image-minimal and a
crownbay-noemgd
MACHINE
that works right out of the box.
$ wic create directdisk -e core-image-minimal
Checking basic build environment...
Done.
Creating image(s)...
Info: The new image(s) can be found here:
/var/tmp/wic/build/directdisk-201309252350-sda.direct
The following build artifacts were used to create the image(s):
ROOTFS_DIR: /home/trz/yocto/yocto-image/build/tmp/work/crownbay_noemgd-poky-linux/core-image-minimal/1.0-r0/rootfs
BOOTIMG_DIR: /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/share
KERNEL_DIR: /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/src/kernel
NATIVE_SYSROOT: /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/src/kernel
The image(s) were created using OE kickstart file:
/home/trz/yocto/yocto-image/scripts/lib/image/canned-wks/directdisk.wks
This next example manually specifies each build artifact
(runs in Raw Mode) and uses a modified kickstart file.
The example also uses the -o option
to cause wic to create the output
somewhere other than the default
/var/tmp/wic directory:
$ wic create ~/test.wks -o /home/trz/testwic --rootfs-dir /home/trz/yocto/yocto-image/build/tmp/work/crownbay_noemgd-poky-linux/core-image-minimal/1.0-r0/rootfs --bootimg-dir /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/share --kernel-dir /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/src/kernel --native-sysroot /home/trz/yocto/yocto-image/build/tmp/sysroots/x86_64-linux
Creating image(s)...
Info: The new image(s) can be found here:
/home/trz/testwic/build/test-201309260032-sda.direct
The following build artifacts were used to create the image(s):
ROOTFS_DIR: /home/trz/yocto/yocto-image/build/tmp/work/crownbay_noemgd-poky-linux/core-image-minimal/1.0-r0/rootfs
BOOTIMG_DIR: /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/share
KERNEL_DIR: /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/src/kernel
NATIVE_SYSROOT: /home/trz/yocto/yocto-image/build/tmp/sysroots/crownbay-noemgd/usr/src/kernel
The image(s) were created using OE kickstart file:
/home/trz/test.wks
For this example,
MACHINE
did not have to be specified in the
local.conf file since the artifact is
manually specified.
The current wic implementation supports
only the basic kickstart partitioning commands:
partition (or part
for short) and bootloader.
Following is a listing of the commands, their syntax, and
meanings.
The commands are based on the Fedora kickstart documentation
but with modifications to reflect wic
capabilities.
http://fedoraproject.org/wiki/Anaconda/Kickstart#part_or_partition
http://fedoraproject.org/wiki/Anaconda/Kickstart#bootloader
This command creates a partition on the system and uses the following syntax:
part <mntpoint>
The <mntpoint> is where the
partition will be mounted and must be of one of the
following forms:
/<path>: For example,/,/usr, and/homeswap: The partition will be used as swap space.
Following are the supported options:
--size: The minimum partition size in MBytes. Specify an integer value such as 500. Do not append the number with "MB". You do not need this option if you use--source.--source: This option is a wic-specific option that can currently have one of two values, "bootimg" or "rootfs".If
--source rootfsis used, it tells thewiccommand to create a partition as large as needed to fill with the contents of the root filesystem (specified by the-rwicoption) and to fill it with the contents of/rootfs.If
--source bootimgis used, it tells thewiccommand to create a partition as large as needed to fill with the contents of the boot partition (specified by the-bwicoption). Exactly what those contents are depend on the value of the--fstypeoption for that partition. If--fstype=efiis specified, the boot artifacts contained in HDDDIR are used, and if--fstype=msdosis specified, the boot artifacts found inSTAGING_DATADIRare used.--ondiskor--ondrive: Forces the partition to be created on a particular disk.--fstype: Sets the file system type for the partition. Valid values are:msdosefiext4ext3ext2btrfsswap
--label label: Specifies the label to give to the filesystem to be made on the partition. If the given label is already in use by another filesystem, a new label is created for the partition.--active: Marks the partition as active.--align (in KBytes): This option is specific to the Meego Image Creator (mic) that says to start a partition on an x KBytes boundary.
This command specifies how the boot loader should be and supports the following options:
--timeout: Specifies the number of seconds before the bootloader times out and boots the default option.--append: Specifies kernel parameters. These will be added to the syslinuxAPPENDorgrubkernel command line.The boot type is determined by the fstype of the
/bootmountpoint. If the fstype is "msdos" the boot type is "pcbios", otherwise it is the fstype, which is currently "efi" (more to be added later).If the boot type is "efi", the image will use
gruband has one menuentry: "boot".If the boot type is "pcbios", the image will use syslinux and has one menu label: "boot".
Future updates will implement more options. If you use anything that is not specifically supported, results can be unpredictable.
Configuring the Yocto Project kernel consists of making sure the .config
file has all the right information in it for the image you are building.
You can use the menuconfig tool and configuration fragments to
make sure your .config file is just how you need it.
This section describes how to use menuconfig, create and use
configuration fragments, and how to interactively tweak your .config
file to create the leanest kernel configuration file possible.
For more information on kernel configuration, see the "Changing the Configuration" section in the Yocto Project Linux Kernel Development Manual.
The easiest way to define kernel configurations is to set them through the
menuconfig tool.
This tool provides an interactive method with which
to set kernel configurations.
For general information on menuconfig, see
http://en.wikipedia.org/wiki/Menuconfig.
To use the menuconfig tool in the Yocto Project development
environment, you must launch it using BitBake.
Thus, the environment must be set up using the
oe-init-build-env
or
oe-init-build-env-memres
script found in the
Build Directory.
The following commands run menuconfig assuming the
Source Directory
top-level folder is ~/poky:
$ cd poky
$ source oe-init-build-env
$ bitbake linux-yocto -c menuconfig
Once menuconfig comes up, its standard interface allows you to
interactively examine and configure all the kernel configuration parameters.
After making your changes, simply exit the tool and save your changes to
create an updated version of the .config configuration file.
Consider an example that configures the linux-yocto-3.4
kernel.
The OpenEmbedded build system recognizes this kernel as
linux-yocto.
Thus, the following commands from the shell in which you previously sourced the
environment initialization script cleans the shared state cache and the
WORKDIR
directory and then runs menuconfig:
$ bitbake linux-yocto -c menuconfig
Once menuconfig launches, use the interface
to navigate through the selections to find the configuration settings in
which you are interested.
For example, consider the CONFIG_SMP configuration setting.
You can find it at Processor Type and Features under
the configuration selection Symmetric Multi-processing Support.
After highlighting the selection, use the arrow keys to select or deselect
the setting.
When you are finished with all your selections, exit out and save them.
Saving the selections updates the .config configuration file.
This is the file that the OpenEmbedded build system uses to configure the
kernel during the build.
You can find and examine this file in the Build Directory in
tmp/work/.
The actual .config is located in the area where the
specific kernel is built.
For example, if you were building a Linux Yocto kernel based on the
Linux 3.4 kernel and you were building a QEMU image targeted for
x86 architecture, the
.config file would be located here:
poky/build/tmp/work/qemux86-poky-linux/linux-yocto-3.4.11+git1+84f...
...656ed30-r1/linux-qemux86-standard-build
Note
The previous example directory is artificially split and many of the characters in the actual filename are omitted in order to make it more readable. Also, depending on the kernel you are using, the exact pathname forlinux-yocto-3.4... might differ.
Within the .config file, you can see the kernel settings.
For example, the following entry shows that symmetric multi-processor support
is not set:
# CONFIG_SMP is not set
A good method to isolate changed configurations is to use a combination of the
menuconfig tool and simple shell commands.
Before changing configurations with menuconfig, copy the
existing .config and rename it to something else,
use menuconfig to make
as many changes an you want and save them, then compare the renamed configuration
file against the newly created file.
You can use the resulting differences as your base to create configuration fragments
to permanently save in your kernel layer.
Note
Be sure to make a copy of the.config and don't just
rename it.
The build system needs an existing .config
from which to work.
Configuration fragments are simply kernel options that appear in a file
placed where the OpenEmbedded build system can find and apply them.
Syntactically, the configuration statement is identical to what would appear
in the .config file, which is in the
Build Directory in
tmp/work/<arch>-poky-linux/linux-yocto-<release-specific-string>/linux-<arch>-<build-type>.
It is simple to create a configuration fragment.
For example, issuing the following from the shell creates a configuration fragment
file named my_smp.cfg that enables multi-processor support
within the kernel:
$ echo "CONFIG_SMP=y" >> my_smp.cfg
Note
All configuration files must use the.cfg extension in order
for the OpenEmbedded build system to recognize them as a configuration fragment.
Where do you put your configuration files?
You can place these configuration files in the same area pointed to by
SRC_URI.
The OpenEmbedded build system will pick up the configuration and add it to the
kernel's configuration.
For example, suppose you had a set of configuration options in a file called
myconfig.cfg.
If you put that file inside a directory named linux-yocto
that resides in the same directory as the kernel's append file and then add
a SRC_URI statement such as the following to the kernel's append file,
those configuration options will be picked up and applied when the kernel is built.
SRC_URI += "file://myconfig.cfg"
As mentioned earlier, you can group related configurations into multiple files and
name them all in the SRC_URI statement as well.
For example, you could group separate configurations specifically for Ethernet and graphics
into their own files and add those by using a SRC_URI statement like the
following in your append file:
SRC_URI += "file://myconfig.cfg \
file://eth.cfg \
file://gfx.cfg"
You can make sure the .config file is as lean or efficient as
possible by reading the output of the kernel configuration fragment audit,
noting any issues, making changes to correct the issues, and then repeating.
As part of the kernel build process, the
kernel_configcheck task runs.
This task validates the kernel configuration by checking the final
.config file against the input files.
During the check, the task produces warning messages for the following
issues:
Requested options that did not make the final
.configfile.Configuration items that appear twice in the same configuration fragment.
Configuration items tagged as "required" that were overridden.
A board overrides a non-board specific option.
Listed options not valid for the kernel being processed. In other words, the option does not appear anywhere.
Note
Thekernel_configcheck task can also optionally report
if an option is overridden during processing.
For each output warning, a message points to the file that contains a list of the options and a pointer to the config fragment that defines them. Collectively, the files are the key to streamlining the configuration.
To streamline the configuration, do the following:
Start with a full configuration that you know works - it builds and boots successfully. This configuration file will be your baseline.
Separately run the
configmeandkernel_configchecktasks.Take the resulting list of files from the
kernel_configchecktask warnings and do the following:Drop values that are redefined in the fragment but do not change the final
.configfile.Analyze and potentially drop values from the
.configfile that override required configurations.Analyze and potentially remove non-board specific options.
Remove repeated and invalid options.
After you have worked through the output of the kernel configuration audit, you can re-run the
configmeandkernel_configchecktasks to see the results of your changes. If you have more issues, you can deal with them as described in the previous step.
Iteratively working through steps two through four eventually yields
a minimal, streamlined configuration file.
Once you have the best .config, you can build the Linux
Yocto kernel.
Patching the kernel involves changing or adding configurations to an existing kernel, changing or adding recipes to the kernel that are needed to support specific hardware features, or even altering the source code itself.
Note
You can use theyocto-kernel script
found in the Source Directory
under scripts to manage kernel patches and configuration.
See the "Managing kernel Patches and Config Items with yocto-kernel"
section in the Yocto Project Board Support Packages (BSP) Developer's Guide for
more information.
This example creates a simple patch by adding some QEMU emulator console
output at boot time through printk statements in the kernel's
calibrate.c source code file.
Applying the patch and booting the modified image causes the added
messages to appear on the emulator's console.
The example assumes a clean build exists for the qemux86
machine in a Source Directory named poky.
Furthermore, the Build Directory is
build and is located in poky and
the kernel is based on the Linux 3.4 kernel.
For general information on how to configure the most efficient build, see the
"Building an Image" section
in the Yocto Project Quick Start.
Also, for more information on patching the kernel, see the "Applying Patches" section in the Yocto Project Linux Kernel Development Manual.
The first step is to create a layer so you can isolate your changes:
$ cd ~/poky
$ mkdir meta-mylayer
Creating a directory that follows the Yocto Project layer naming conventions sets up the layer for your changes. The layer is where you place your configuration files, append files, and patch files. To learn more about creating a layer and filling it with the files you need, see the "Understanding and Creating Layers" section.
Each time you build a kernel image, the kernel source code is fetched and unpacked into the following directory:
${S}/linux
See the "Finding the Temporary Source Code"
section and the
S variable
for more information about where source is kept during a build.
For this example, we are going to patch the
init/calibrate.c file
by adding some simple console printk statements that we can
see when we boot the image using QEMU.
Two methods exist by which you can create the patch: Git workflow and Quilt workflow. For kernel patches, the Git workflow is more appropriate. This section assumes the Git workflow and shows the steps specific to this example.
Change the working directory: Change to where the kernel source code is before making your edits to the
calibrate.cfile:$ cd ~/poky/build/tmp/work/qemux86-poky-linux/linux-yocto-${PV}-${PR}/linuxBecause you are working in an established Git repository, you must be in this directory in order to commit your changes and create the patch file.
Edit the source file: Edit the
init/calibrate.cfile to have the following changes:void calibrate_delay(void) { unsigned long lpj; static bool printed; int this_cpu = smp_processor_id(); printk("*************************************\n"); printk("* *\n"); printk("* HELLO YOCTO KERNEL *\n"); printk("* *\n"); printk("*************************************\n"); if (per_cpu(cpu_loops_per_jiffy, this_cpu)) { . . .Stage and commit your changes: These Git commands display the modified file, stage it, and then commit the file:
$ git status $ git add init/calibrate.c $ git commit -m "calibrate: Add printk example"Generate the patch file: This Git command creates the a patch file named
0001-calibrate-Add-printk-example.patchin the current directory.$ git format-patch -1
These steps get your layer set up for the build:
Create additional structure: Create the additional layer structure:
$ cd ~/poky/meta-mylayer $ mkdir conf $ mkdir recipes-kernel $ mkdir recipes-kernel/linux $ mkdir recipes-kernel/linux/linux-yoctoThe
confdirectory holds your configuration files, while therecipes-kerneldirectory holds your append file and your patch file.Create the layer configuration file: Move to the
meta-mylayer/confdirectory and create thelayer.conffile as follows:# We have a conf and classes directory, add to BBPATH BBPATH .= ":${LAYERDIR}" # We have recipes-* directories, add to BBFILES BBFILES += "${LAYERDIR}/recipes-*/*/*.bb \ ${LAYERDIR}/recipes-*/*/*.bbappend" BBFILE_COLLECTIONS += "mylayer" BBFILE_PATTERN_mylayer = "^${LAYERDIR}/" BBFILE_PRIORITY_mylayer = "5"Notice
mylayeras part of the last three statements.Create the kernel recipe append file: Move to the
meta-mylayer/recipes-kernel/linuxdirectory and create thelinux-yocto_3.4.bbappendfile as follows:FILESEXTRAPATHS_prepend := "${THISDIR}/${PN}:" SRC_URI += "file://0001-calibrate-Add-printk-example.patch" PRINC := "${@int(PRINC) + 1}"The
FILESEXTRAPATHSandSRC_URIstatements enable the OpenEmbedded build system to find the patch file. For more information on using append files, see the "Using .bbappend Files" section.Put the patch file in your layer: Move the
0001-calibrate-Add-printk-example.patchfile to themeta-mylayer/recipes-kernel/linux/linux-yoctodirectory.
Do the following to make sure the build parameters are set up for the example. Once you set up these build parameters, they do not have to change unless you change the target architecture of the machine you are building:
Build for the correct target architecture: Your selected
MACHINEdefinition within thelocal.conffile in the Build Directory specifies the target architecture used when building the Linux kernel. By default,MACHINEis set toqemux86, which specifies a 32-bit Intel® Architecture target machine suitable for the QEMU emulator.Identify your
meta-mylayerlayer: TheBBLAYERSvariable in thebblayers.conffile found in thepoky/build/confdirectory needs to have the path to your localmeta-mylayerlayer. By default, theBBLAYERSvariable contains paths tometa,meta-yocto, andmeta-yocto-bspin thepokyGit repository. Add the path to yourmeta-mylayerlocation:BBLAYERS ?= " \ $HOME/poky/meta \ $HOME/poky/meta-yocto \ $HOME/poky/meta-yocto-bsp \ $HOME/poky/meta-mylayer \ " BBLAYERS_NON_REMOVABLE ?= " \ $HOME/poky/meta \ $HOME/poky/meta-yocto \ "
The following steps build your modified kernel image:
Be sure your build environment is initialized: Your environment should be set up since you previously sourced the
oe-init-build-envscript. If it is not, source the script again frompoky.$ cd ~/poky $ source oe-init-build-envClean up: Be sure to clean the shared state out by running the
cleansstateBitBake task as follows from your Build Directory:$ bitbake -c cleansstate linux-yoctoNote
Never remove any files by hand from thetmp/deploydirectory inside the Build Directory. Always use the various BitBake clean tasks to clear out previous build artifacts.Build the image: Next, build the kernel image using this command:
$ bitbake -k linux-yocto
These steps boot the image and allow you to see the changes
Boot the image: Boot the modified image in the QEMU emulator using this command:
$ runqemu qemux86Verify the changes: Log into the machine using
rootwith no password and then use the following shell command to scroll through the console's boot output.# dmesg | lessYou should see the results of your
printkstatements as part of the output.
When you build an image using the Yocto Project and do not alter any distribution Metadata, you are creating a Poky distribution. If you wish to gain more control over package alternative selections, compile-time options, and other low-level configurations, you can create your own distribution.
To create your own distribution, the basic steps consist of creating your own distribution layer, creating your own distribution configuration file, and then adding any needed code and Metadata to the layer. The following steps provide some more detail:
Create a layer for your new distro: Create your distribution layer so that you can keep your Metadata and code for the distribution separate. It is strongly recommended that you create and use your own layer for configuration and code. Using your own layer as compared to just placing configurations in a
local.confconfiguration file makes it easier to reproduce the same build configuration when using multiple build machines. See the "Creating a General Layer Using the yocto-layer Script" section for information on how to quickly set up a layer.Create the distribution configuration file: The distribution configuration file needs to be created in the
conf/distrodirectory of your layer. You need to name it using your distribution name (e.g.mydistro.conf).You can split out parts of your configuration file into include files and then "require" them from within your distribution configuration file. Be sure to place the include files in the
conf/distro/includedirectory of your layer. A common example usage of include files would be to separate out the selection of desired version and revisions for individual recipes.Your configuration file needs to set the following required variables:
DISTRO_NAME[required]DISTRO_VERSION[required]These following variables are optional and you typically set them from the distribution configuration file:
DISTRO_FEATURES[optional]DISTRO_EXTRA_RDEPENDS[optional]DISTRO_EXTRA_RRECOMMENDS[optional]TCLIBC[optional]Tip
If you want to base your distribution configuration file on the very basic configuration from OE-Core, you can useconf/distro/defaultsetup.confas a reference and just include variables that differ as compared todefaultsetup.conf. Alternatively, you can create a distribution configuration file from scratch using thedefaultsetup.conffile or configuration files from other distributions such as Poky or Angstrom as references.Provide miscellaneous variables: Be sure to define any other variables for which you want to create a default or enforce as part of the distribution configuration. You can include nearly any variable from the
local.conffile. The variables you use are not limited to the list in the previous bulleted item.Point to Your distribution configuration file: In your
local.conffile in the Build Directory, set yourDISTROvariable to point to your distribution's configuration file. For example, if your distribution's configuration file is namedmydistro.conf, then you point to it as follows:DISTRO = "mydistro"Add more to the layer if necessary: Use your layer to hold other information needed for the distribution:
Add recipes for installing distro-specific configuration files that are not already installed by another recipe. If you have distro-specific configuration files that are included by an existing recipe, you should add a
.bbappendfor those. For general information and recommendations on how to add recipes to your layer, see the "Creating Your Own Layer" and "Best Practices to Follow When Creating Layers" sections.Add any image recipes that are specific to your distribution.
Add a
psplashappend file for a branded splash screen. For information on append files, see the "Using .bbappend Files" section.Add any other append files to make custom changes that are specific to individual recipes.
Very small distributions have some significant advantages such as requiring less on-die or in-package memory (cheaper), better performance through efficient cache usage, lower power requirements due to less memory, faster boot times, and reduced development overhead. Some real-world examples where a very small distribution gives you distinct advantages are digital cameras, medical devices, and small headless systems.
This section presents information that shows you how you can
trim your distribution to even smaller sizes than the
poky-tiny distribution, which is around
5 Mbytes, that can be built out-of-the-box using the Yocto Project.
The following list presents the overall steps you need to consider and perform to create distributions with smaller root filesystems, achieve faster boot times, maintain your critical functionality, and avoid initial RAM disks:
Determine your goals and guiding principles.
Understand what contributes to your image size.
Reduce the size of the root filesystem.
Reduce the size of the kernel.
Eliminate packaging requirements.
Look for other ways to minimize size.
Iterate on the process.
Before you can reach your destination, you need to know where you are going. Here is an example list that you can use as a guide when creating very small distributions:
Determine how much space you need (e.g. a kernel that is 1 Mbyte or less and a root filesystem that is 3 Mbytes or less).
Find the areas that are currently taking 90% of the space and concentrate on reducing those areas.
Do not create any difficult "hacks" to achieve your goals.
Leverage the device-specific options.
Work in a separate layer so that you keep changes isolated. For information on how to create layers, see the "Understanding and Creating Layers" section.
It is easiest to have something to start with when creating
your own distribution.
You can use the Yocto Project out-of-the-box to create the
poky-tiny distribution.
Ultimately, you will want to make changes in your own
distribution that are likely modeled after
poky-tiny.
Note
To usepoky-tiny in your build,
set the
DISTRO
variable in your
local.conf file to "poky-tiny"
as described in the
"Creating Your Own Distribution"
section.
Understanding some memory concepts will help you reduce the
system size.
Memory consists of static, dynamic, and temporary memory.
Static memory is the TEXT (code), DATA (initialized data
in the code), and BSS (uninitialized data) sections.
Dynamic memory represents memory that is allocated at runtime:
stacks, hash tables, and so forth.
Temporary memory is recovered after the boot process.
This memory consists of memory used for decompressing
the kernel and for the __init__
functions.
To help you see where you currently are with kernel and root
filesystem sizes, you can use two tools found in the
Source Directory in
the scripts/tiny/ directory:
ksize.py: Reports component sizes for the kernel build objects.dirsize.py: Reports component sizes for the root filesystem.
This next tool and command helps you organize configuration fragments and view file dependencies in a human-readable form:
merge_config.sh: Helps you manage configuration files and fragments within the kernel. With this tool, you can merge individual configuration fragments together. The tool allows you to make overrides and warns you of any missing configuration options. The tool is ideal for allowing you to iterate on configurations, create minimal configurations, and create configuration files for different machines without having to duplicate your process.The
merge_config.shscript is part of the Linux Yocto kernel Git repository in thescripts/kconfigdirectory.For more information on configuration fragments, see the "Generating Configuration Files" section of the Yocto Project Linux Kernel Development Manual and the "Creating Configuration Fragments" section, which is in this manual.
bitbake -u depexp -g <bitbake_target>: Using the BitBake command with these options brings up a Dependency Explorer from which you can view file dependencies. Understanding these dependencies allows you to make informed decisions when cutting out various pieces of the kernel and root filesystem.
The root filesystem is made up of packages for booting, libraries, and applications. To change things, you can configure how the packaging happens, which changes the way you build them. You can also tweak the filesystem itself or select a different filesystem.
First, find out what is hogging your root filesystem by running the
dirsize.py script from your root directory:
$ cd <root-directory-of-image>
$ dirsize.py 100000 > dirsize-100k.log
$ cat dirsize-100k.log
You can apply a filter to the script to ignore files under a certain size. The previous example filters out any files below 100 Kbytes. The sizes reported by the tool are uncompressed, and thus will be smaller by a relatively constant factor in a compressed root filesystem. When you examine your log file, you can focus on areas of the root filesystem that take up large amounts of memory.
You need to be sure that what you eliminate does not cripple the functionality you need. One way to see how packages relate to each other is by using the Dependency Explorer UI with the BitBake command:
$ cd <image-directory>
$ bitbake -u depexp -g <image>
Use the interface to select potential packages you wish to eliminate and see their dependency relationships.
When deciding how to reduce the size, get rid of packages that
result in minimal impact on the feature set.
For example, you might not need a VGA display.
Or, you might be able to get by with devtmpfs
and mdev instead of
udev.
Use your local.conf file to make changes.
For example, to eliminate udev and
glib, set the following in the
local configuration file:
VIRTUAL-RUNTIME_dev_manager = ""
Finally, you should consider exactly the type of root
filesystem you need to meet your needs while also reducing
its size.
For example, consider cramfs,
squashfs, ubifs,
ext2, or an initramfs
using initramfs.
Be aware that ext3 requires a 1 Mbyte
journal.
If you are okay with running read-only, you do not need this
journal.
Note
After each round of elimination, you need to rebuild your system and then use the tools to see the effects of your reductions.The kernel is built by including policies for hardware-independent aspects. What subsystems do you enable? For what architecture are you building? Which drivers do you build by default?
Note
You can modify the kernel source if you want to help with boot time.
Run the ksize.py script from the top-level
Linux build directory to get an idea of what is making up
the kernel:
$ cd <top-level-linux-build-directory>
$ ksize.py > ksize.log
$ cat ksize.log
When you examine the log, you will see how much space is
taken up with the built-in .o files for
drivers, networking, core kernel files, filesystem, sound,
and so forth.
The sizes reported by the tool are uncompressed, and thus
will be smaller by a relatively constant factor in a compressed
kernel image.
Look to reduce the areas that are large and taking up around
the "90% rule."
To examine, or drill down, into any particular area, use the
-d option with the script:
$ ksize.py -d > ksize.log
Using this option breaks out the individual file information for each area of the kernel (e.g. drivers, networking, and so forth).
Use your log file to see what you can eliminate from the kernel based on features you can let go. For example, if you are not going to need sound, you do not need any drivers that support sound.
After figuring out what to eliminate, you need to reconfigure
the kernel to reflect those changes during the next build.
You could run menuconfig and make all your
changes at once.
However, that makes it difficult to see the effects of your
individual eliminations and also makes it difficult to replicate
the changes for perhaps another target device.
A better method is to start with no configurations using
allnoconfig, create configuration
fragments for individual changes, and then manage the
fragments into a single configuration file using
merge_config.sh.
The tool makes it easy for you to iterate using the
configuration change and build cycle.
Each time you make configuration changes, you need to rebuild the kernel and check to see what impact your changes had on the overall size.
Packaging requirements add size to the image. One way to reduce the size of the image is to remove all the packaging requirements from the image. This reduction includes both removing the package manager and its unique dependencies as well as removing the package management data itself.
To eliminate all the packaging requirements for an image, follow these steps:
Put the following line in your main recipe for the image to remove package management data files:
ROOTFS_POSTPROCESS_COMMAND += "remove_packaging_data_files ;For example, the recipe for the
core-image-minimalimage contains this line. You can also add the line to thelocal.confconfiguration file.Be sure that "package-management" is not part of your
IMAGE_FEATURESstatement for the image. When you remove this feature, you are removing the package manager as well as its dependencies from the root filesystem.
Depending on your particular circumstances, other areas that you can trim likely exist. The key to finding these areas is through tools and methods described here combined with experimentation and iteration. Here are a couple of areas to experiment with:
eglibc: In general, follow this process:Remove
eglibcfeatures fromDISTRO_FEATURESthat you think you do not need.Build your distribution.
If the build fails due to missing symbols in a package, determine if you can reconfigure the package to not need those features. For example, change the configuration to not support wide character support as is done for
ncurses. Or, if support for those characters is needed, determine whateglibcfeatures provide the support and restore the configuration.Rebuild and repeat the process.
busybox: For BusyBox, use a process similar as described foreglibc. A difference is you will need to boot the resulting system to see if you are able to do everything you expect from the running system. You need to be sure to integrate configuration fragments into Busybox because BusyBox handles its own core features and then allows you to add configuration fragments on top.
If you have not reached your goals on system size, you need to iterate on the process. The process is the same. Use the tools and see just what is taking up 90% of the root filesystem and the kernel. Decide what you can eliminate without limiting your device beyond what you need.
Depending on your system, a good place to look might be Busybox, which provides a stripped down version of Unix tools in a single, executable file. You might be able to drop virtual terminal services or perhaps ipv6.
This section describes a few tasks that involve packages:
Excluding packages from an image
Incrementing a package revision number
Handling a package name alias
Handling optional module packaging
Using Runtime Package Management
Setting up and running package test (ptest)
You might find it necessary to prevent specific packages from being installed into an image. If so, you can use several variables to direct the build system to essentially ignore installing recommended packages or to not install a package at all.
The following list introduces variables you can use to
prevent packages from being installed into your image.
Each of these variables only works with IPK and RPM
package types.
Support for Debian packages does not exist.
Also, you can use these variables from your
local.conf file or attach them to a
specific image recipe by using a recipe name override.
For more detail on the variables, see the descriptions in the
Yocto Project Reference Manual's glossary chapter.
BAD_RECOMMENDATIONS: Use this variable to specify "recommended-only" packages that you do not want installed.NO_RECOMMENDATIONS: Use this variable to prevent all "recommended-only" packages from being installed.PACKAGE_EXCLUDE: Use this variable to prevent specific packages from being installed regardless of whether they are "recommended-only" or not. You need to realize that the build process could fail with an error when you prevent the installation of a package whose presence is required by an installed package.
If a committed change results in changing the package output,
then the value of the
PR
variable needs to be increased (or "bumped").
Increasing PR occurs one of two ways:
Automatically using a Package Revision Service (PR Service).
Manually incrementing the
PRvariable.
Given that one of the challenges any build system and its users face is how to maintain a package feed that is compatible with existing package manager applications such as RPM, APT, and OPKG, using an automated system is much preferred over a manual system. In either system, the main requirement is that version numbering increases in a linear fashion and that a number of version components exist that support that linear progression.
The following two sections provide information on the PR Service
and on manual PR bumping.
As mentioned, attempting to maintain revision numbers in the Metadata is error prone, inaccurate and causes problems for people submitting recipes. Conversely, the PR Service automatically generates increasing numbers, particularly the revision field, which removes the human element.
Note
For additional information on using a PR Service, you can see the PR Service wiki page.
The Yocto Project uses variables in order of
decreasing priority to facilitate revision numbering (i.e.
PE,
PV, and
PR
for epoch, version and revision, respectively).
The values are highly dependent on the policies and
procedures of a given distribution and package feed.
Because the OpenEmbedded build system uses
"signatures",
which are unique to a given build, the build system
knows when to rebuild packages.
All the inputs into a given task are represented by a
signature, which can trigger a rebuild when different.
Thus, the build system itself does not rely on the
PR numbers to trigger a rebuild.
The signatures, however, can be used to generate
PR values.
The PR Service works with both
OEBasic and
OEBasicHash generators.
The value of PR bumps when the
checksum changes and the different generator mechanisms
change signatures under different circumstances.
As implemented, the build system includes values from
the PR Service into the PR field as
an addition using the form ".x" so
r0 becomes r0.1,
r0.2 and so forth.
This scheme allows existing PR values
to be used for whatever reasons, which include manual
PR bumps should it be necessary.
By default, the PR Service is not enabled or running. Thus, the packages generated are just "self consistent". The build system adds and removes packages and there are no guarantees about upgrade paths but images will be consistent and correct with the latest changes.
The simplest form for a PR Service is for it to exist
for a single host development system that builds the
package feed (building system).
For this scenario, you can enable a local PR Service by
setting
PRSERV_HOST
in your local.conf file in the
Build Directory:
PRSERV_HOST = "localhost:0"
Once the service is started, packages will automatically
get increasing PR values and
BitBake will take care of starting and stopping the server.
If you have a more complex setup where multiple host
development systems work against a common, shared package
feed, you have a single PR Service running and it is
connected to each building system.
For this scenario, you need to start the PR Service using
the bitbake-prserv command:
bitbake-prserv ‐‐host <ip> ‐‐port <port> ‐‐start
In addition to hand-starting the service, you need to
update the local.conf file of each
building system as described earlier so each system
points to the server and port.
It is also recommended you use Build History, which adds
some sanity checks to package versions, in conjunction with
the server that is running the PR Service.
To enable build history, add the following to each building
system's local.conf file:
# It is recommended to activate "buildhistory" for testing the PR service
INHERIT += "buildhistory"
BUILDHISTORY_COMMIT = "1"
For information on Build History, see the "Maintaining Build Output Quality" section in the Yocto Project Reference Manual.
Note
The OpenEmbedded build system does not maintain
PR information as part of the
shared state (sstate) packages.
If you maintain an sstate feed, its expected that either
all your building systems that contribute to the sstate
feed use a shared PR Service, or you do not run a PR
Service on any of your building systems.
Having some systems use a PR Service while others do
not leads to obvious problems.
For more information on shared state, see the "Shared State Cache" section in the Yocto Project Reference Manual.
The alternative to setting up a PR Service is to manually
bump the
PR
variable.
If a committed change results in changing the package output,
then the value of the PR variable needs to be increased
(or "bumped") as part of that commit.
For new recipes you should add the PR
variable and set its initial value equal to "r0", which is the default.
Even though the default value is "r0", the practice of adding it to a new recipe makes
it harder to forget to bump the variable when you make changes
to the recipe in future.
If you are sharing a common .inc file with multiple recipes,
you can also use the
INC_PR
variable to ensure that
the recipes sharing the .inc file are rebuilt when the
.inc file itself is changed.
The .inc file must set INC_PR
(initially to "r0"), and all recipes referring to it should set PR
to "$(INC_PR).0" initially, incrementing the last number when the recipe is changed.
If the .inc file is changed then its
INC_PR should be incremented.
When upgrading the version of a package, assuming the
PV
changes, the PR variable should be
reset to "r0" (or "$(INC_PR).0" if you are using
INC_PR).
Usually, version increases occur only to packages.
However, if for some reason PV changes but does not
increase, you can increase the
PE
variable (Package Epoch).
The PE variable defaults to "0".
Version numbering strives to follow the Debian Version Field Policy Guidelines. These guidelines define how versions are compared and what "increasing" a version means.
Sometimes a package name you are using might exist under an alias or as a similarly named
package in a different distribution.
The OpenEmbedded build system implements a distro_check
task that automatically connects to major distributions
and checks for these situations.
If the package exists under a different name in a different distribution, you get a
distro_check mismatch.
You can resolve this problem by defining a per-distro recipe name alias using the
DISTRO_PN_ALIAS
variable.
Following is an example that shows how you specify the DISTRO_PN_ALIAS
variable:
DISTRO_PN_ALIAS_pn-PACKAGENAME = "distro1=package_name_alias1 \
distro2=package_name_alias2 \
distro3=package_name_alias3 \
..."
If you have more than one distribution alias, separate them with a space.
Note that the build system currently automatically checks the
Fedora, OpenSUSE, Debian, Ubuntu,
and Mandriva distributions for source package recipes without having to specify them
using the DISTRO_PN_ALIAS variable.
For example, the following command generates a report that lists the Linux distributions
that include the sources for each of the recipes.
$ bitbake world -f -c distro_check
The results are stored in the build/tmp/log/distro_check-${DATETIME}.results
file found in the
Source Directory.
Many pieces of software split functionality into optional modules (or plug-ins) and the plug-ins that are built might depend on configuration options. To avoid having to duplicate the logic that determines what modules are available in your recipe or to avoid having to package each module by hand, the OpenEmbedded build system provides functionality to handle module packaging dynamically.
To handle optional module packaging, you need to do two things:
Ensure the module packaging is actually done
Ensure that any dependencies on optional modules from other recipes are satisfied by your recipe
To ensure the module packaging actually gets done, you use
the do_split_packages function within
the populate_packages Python function
in your recipe.
The do_split_packages function
searches for a pattern of files or directories under a
specified path and creates a package for each one it finds
by appending to the
PACKAGES
variable and setting the appropriate values for
FILES_packagename,
RDEPENDS_packagename,
DESCRIPTION_packagename, and so forth.
Here is an example from the lighttpd
recipe:
python populate_packages_prepend () {
lighttpd_libdir = d.expand('${libdir}')
do_split_packages(d, lighttpd_libdir, '^mod_(.*)\.so$',
'lighttpd-module-%s', 'Lighttpd module for %s',
extra_depends='')
}
The previous example specifies a number of things in the
call to do_split_packages.
A directory within the files installed by your recipe through
do_installin which to search.A regular expression to match module files in that directory. In the example, note the parentheses () that mark the part of the expression from which the module name should be derived.
A pattern to use for the package names.
A description for each package.
An empty string for
extra_depends, which disables the default dependency on the mainlighttpdpackage. Thus, if a file in${libdir}calledmod_alias.sois found, a package calledlighttpd-module-aliasis created for it and theDESCRIPTIONis set to "Lighttpd module for alias".
Often, packaging modules is as simple as the previous
example.
However, more advanced options exist that you can use
within do_split_packages to modify its
behavior.
And, if you need to, you can add more logic by specifying
a hook function that is called for each package.
It is also perfectly acceptable to call
do_split_packages multiple times if
you have more than one set of modules to package.
For more examples that show how to use
do_split_packages, see the
connman.inc file in the
meta/recipes-connectivity/connman/
directory of the poky
source repository.
You can also find examples in
meta/classes/kernel.bbclass.
Following is a reference that shows
do_split_packages mandatory and
optional arguments:
Mandatory arguments
root
The path in which to search
file_regex
Regular expression to match searched files.
Use parentheses () to mark the part of this
expression that should be used to derive the
module name (to be substituted where %s is
used in other function arguments as noted below)
output_pattern
Pattern to use for the package names. Must
include %s.
description
Description to set for each package. Must
include %s.
Optional arguments
postinst
Postinstall script to use for all packages
(as a string)
recursive
True to perform a recursive search - default
False
hook
A hook function to be called for every match.
The function will be called with the following
arguments (in the order listed):
f
Full path to the file/directory match
pkg
The package name
file_regex
As above
output_pattern
As above
modulename
The module name derived using file_regex
extra_depends
Extra runtime dependencies (RDEPENDS) to be
set for all packages. The default value of None
causes a dependency on the main package
(${PN}) - if you do not want this, pass empty
string '' for this parameter.
aux_files_pattern
Extra item(s) to be added to FILES for each
package. Can be a single string item or a list
of strings for multiple items. Must include %s.
postrm
postrm script to use for all packages (as a
string)
allow_dirs
True to allow directories to be matched -
default False
prepend
If True, prepend created packages to PACKAGES
instead of the default False which appends them
match_path
match file_regex on the whole relative path to
the root rather than just the file name
aux_files_pattern_verbatim
Extra item(s) to be added to FILES for each
package, using the actual derived module name
rather than converting it to something legal
for a package name. Can be a single string item
or a list of strings for multiple items. Must
include %s.
allow_links
True to allow symlinks to be matched - default
False
The second part for handling optional module packaging
is to ensure that any dependencies on optional modules
from other recipes are satisfied by your recipe.
You can be sure these dependencies are satisfied by
using the
PACKAGES_DYNAMIC variable.
Here is an example that continues with the
lighttpd recipe shown earlier:
PACKAGES_DYNAMIC = "lighttpd-module-.*"
The name specified in the regular expression can of
course be anything.
In this example, it is lighttpd-module-
and is specified as the prefix to ensure that any
RDEPENDS
and RRECOMMENDS
on a package name starting with the prefix are satisfied
during build time.
If you are using do_split_packages
as described in the previous section, the value you put in
PACKAGES_DYNAMIC should correspond to
the name pattern specified in the call to
do_split_packages.
During a build, BitBake always transforms a recipe into one or
more packages.
For example, BitBake takes the bash recipe
and currently produces the bash-dbg,
bash-staticdev,
bash-dev, bash-doc,
bash-locale, and
bash packages.
Not all generated packages are included in an image.
In several situations, you might need to update, add, remove, or query the packages on a target device at runtime (i.e. without having to generate a new image). Examples of such situations include:
You want to provide in-the-field updates to deployed devices (e.g. security updates).
You want to have a fast turn-around development cycle for one or more applications that run on your device.
You want to temporarily install the "debug" packages of various applications on your device so that debugging can be greatly improved by allowing access to symbols and source debugging.
You want to deploy a more minimal package selection of your device but allow in-the-field updates to add a larger selection for customization.
In all these situations, you have something similar to a more traditional Linux distribution in that in-field devices are able to receive pre-compiled packages from a server for installation or update. Being able to install these packages on a running, in-field device is what is termed "runtime package management".
In order to use runtime package management, you need a host/server machine that serves up the pre-compiled packages plus the required metadata. You also need package manipulation tools on the target. The build machine is a likely candidate to act as the server. However, that machine does not necessarily have to be the package server. The build machine could push its artifacts to another machine that acts as the server (e.g. Internet-facing).
A simple build that targets just one device produces
more than one package database.
In other words, the packages produced by a build are separated
out into a couple of different package groupings based on
criteria such as the target's CPU architecture, the target
board, or the C library used on the target.
For example, a build targeting the qemuarm
device produces the following three package databases:
all, armv5te, and
qemuarm.
If you wanted your qemuarm device to be
aware of all the packages that were available to it,
you would need to point it to each of these databases
individually.
In a similar way, a traditional Linux distribution usually is
configured to be aware of a number of software repositories
from which it retrieves packages.
Using runtime package management is completely optional and not required for a successful build or deployment in any way. But if you want to make use of runtime package management, you need to do a couple things above and beyond the basics. The remainder of this section describes what you need to do.
This section describes build considerations that you need to be aware of in order to provide support for runtime package management.
When BitBake generates packages it needs to know
what format(s) to use.
In your configuration, you use the
PACKAGE_CLASSES
variable to specify the format.
Note
You can choose to have more than one format but you must provide at least one.
If you would like your image to start off with a basic
package database of the packages in your current build
as well as have the relevant tools available on the
target for runtime package management, you can include
"package-management" in the
IMAGE_FEATURES
variable.
Including "package-management" in this
configuration variable ensures that when the image
is assembled for your target, the image includes
the currently-known package databases as well as
the target-specific tools required for runtime
package management to be performed on the target.
However, this is not strictly necessary.
You could start your image off without any databases
but only include the required on-target package
tool(s).
As an example, you could include "opkg" in your
IMAGE_INSTALL
variable if you are using the IPK package format.
You can then initialize your target's package database(s)
later once your image is up and running.
Whenever you perform any sort of build step that can potentially generate a package or modify an existing package, it is always a good idea to re-generate the package index with:
$ bitbake package-index
Realize that it is not sufficient to simply do the following:
$ bitbake <some-package> package-index
This is because BitBake does not properly schedule the
package-index target fully after any
other target has completed.
Thus, be sure to run the package update step separately.
As described below in the
"Using IPK"
section, if you are using IPK as your package format, you
can make use of the
distro-feed-configs recipe provided
by meta-oe in order to configure your
target to use your IPK databases.
When your build is complete, your packages reside in the
${TMPDIR}/deploy/<package-format>
directory.
For example, if ${TMPDIR}
is tmp and your selected package type
is IPK, then your IPK packages are available in
tmp/deploy/ipk.
Typically, packages are served from a server using HTTP. However, other protocols are possible. If you want to use HTTP, then setup and configure a web server, such as Apache 2 or lighttpd, on the machine serving the packages.
As previously mentioned, the build machine can act as the package server. In the following sections that describe server machine setups, the build machine is assumed to also be the server.
This example assumes you are using the Apache 2 server:
Add the directory to your Apache configuration, which you can find at
/etc/httpd/conf/httpd.conf. Use commands similar to these on the development system. These example commands assume a top-level Source Directory namedpokyin your home directory. The example also assumes an RPM package type. If you are using a different package type, such as IPK, use "ipk" in the pathnames:<VirtualHost *:80> .... Alias /rpm ~/poky/build/tmp/deploy/rpm <Directory "~/poky/build/tmp/deploy/rpm"> Options +Indexes </Directory> </VirtualHost>Reload the Apache configuration as described in this step. For all commands, be sure you have root privileges.
If your development system is using Fedora or CentOS, use the following:
# service httpd reloadFor Ubuntu and Debian, use the following:
# /etc/init.d/apache2 reloadFor OpenSUSE, use the following:
# /etc/init.d/apache2 reloadIf you are using Security-Enhanced Linux (SELinux), you need to label the files as being accessible through Apache. Use the following command from the development host. This example assumes RPM package types:
# chcon -R -h -t httpd_sys_content_t tmp/deploy/rpm
If you are using lighttpd, all you need
to do is to provide a link from your
${TMPDIR}/deploy/<package-format>
directory to lighttpd's document-root.
You can determine the specifics of your lighttpd
installation by looking through its configuration file,
which is usually found at:
/etc/lighttpd/lighttpd.conf.
For example, if you are using IPK, lighttpd's
document-root is set to
/var/www/lighttpd, and you had
packages for a target named "BOARD",
then you might create a link from your build location
to lighttpd's document-root as follows:
# ln -s $(PWD)/tmp/deploy/ipk /var/www/lighttpd/BOARD-dir
At this point, you need to start the lighttpd server. The method used to start the server varies by distribution. However, one basic method that starts it by hand is:
# lighttpd -f /etc/lighttpd/lighttpd.conf
Setting up the target differs depending on the package management system. This section provides information for RPM and IPK.
The application for performing runtime package
management of RPM packages on the target is called
smart.
On the target machine, you need to inform
smart of every package database
you want to use.
As an example, suppose your target device can use the
following three package databases from a server named
server.name:
all, i586,
and qemux86.
Given this example, issue the following commands on the
target:
# smart channel --add all type=rpm-md baseurl=http://server.name/rpm/all
# smart channel --add i585 type=rpm-md baseurl=http://server.name/rpm/i586
# smart channel --add qemux86 type=rpm-md baseurl=http://server.name/rpm/qemux86
Also from the target machine, fetch the repository information using this command:
# smart update
You can now use the smart query
and smart install commands to
find and install packages from the repositories.
The application for performing runtime package
management of IPK packages on the target is called
opkg.
In order to inform opkg of the
package databases you want to use, simply create one
or more *.conf files in the
/etc/opkg directory on the target.
The opkg application uses them
to find its available package databases.
As an example, suppose you configured your HTTP server
on your machine named
www.mysite.com to serve files
from a BOARD-dir directory under
its document-root.
In this case, you might create a configuration
file on the target called
/etc/opkg/base-feeds.conf that
contains:
src/gz all http://www.mysite.com/BOARD-dir/all
src/gz armv7a http://www.mysite.com/BOARD-dir/armv7a
src/gz beagleboard http://www.mysite.com/BOARD-dir/beagleboard
As a way of making it easier to generate and make
these IPK configuration files available on your
target, simply define
FEED_DEPLOYDIR_BASE_URI
to point to your server and the location within the
document-root which contains the databases.
For example: if you are serving your packages over
HTTP, your server's IP address is 192.168.7.1, and
your databases are located in a directory called
BOARD-dir underneath your HTTP
server's document-root, you need to set
FEED_DEPLOYDIR_BASE_URI to
http://192.168.7.1/BOARD-dir and
a set of configuration files will be generated for you
in your target to work with this feed.
On the target machine, fetch (or refresh) the repository information using this command:
# opkg update
You can now use the opkg list and
opkg install commands to find and
install packages from the repositories.
A Package Test (ptest) runs tests against packages built
by the OpenEmbedded build system on the target machine.
A ptest contains at least two items: the actual test, and
a shell script (run-ptest) that starts
the test.
The shell script that starts the test must not contain
the actual test, the script only starts it.
On the other hand, the test can be anything from a simple
shell script that runs a binary and checks the output to
an elaborate system of test binaries and data files.
The test generates output in the format used by Automake:
<result>: <testname>
where the result can be PASS,
FAIL, or SKIP,
and the testname can be any identifying string.
Note
A recipe is "ptest-enabled" if it inherits ptest.
To add package testing to your build, add the
DISTRO_FEATURES
and EXTRA_IMAGE_FEATURES
variables to your local.conf file,
which is found in the
Build Directory:
DISTRO_FEATURES_append = " ptest"
EXTRA_IMAGE_FEATURES += "ptest-pkgs"
Once your build is complete, the ptest files are installed
into the /usr/lib/<package>/ptest
directory within the image, where
<package> is the name of the
package.
The ptest-runner package installs a
shell script that loops through all installed ptest test
suites and runs them in sequence.
Consequently, you might want to add this package to
your image.
In order to enable a recipe to run installed ptests on target hardware, you need to prepare the recipes that build the packages you want to test. Here is what you have to do for each recipe:
Be sure the recipe inherits ptest: Include the following line in each recipe:
inherit ptestCreate
run-ptest: This script starts your test. Locate the script where you will refer to it usingSRC_URI. Here is an example that starts a test fordbus:#!/bin/sh cd test make -k runtest-TESTSEnsure dependencies are met: If the test adds build or runtime dependencies that normally do not exist for the package (such as requiring "make" to run the test suite), use the
DEPENDSandRDEPENDSvariables in your recipe in order for the package to meet the dependencies. Here is an example where the package has a runtime dependency on "make":RDEPENDS_${PN}-ptest += "make"Add a function to build the test suite: Not many packages support cross-compilation of their test suites. Consequently, you usually need to add a cross-compilation function to the package.
Many packages based on Automake compile and run the test suite by using a single command such as
make check. However, the nativemake checkbuilds and runs on the same computer, while cross-compiling requires that the package is built on the host but executed on the target. The built version of Automake that ships with the Yocto Project includes a patch that separates building and execution. Consequently, packages that use the unaltered, patched version ofmake checkautomatically cross-compiles.However, you still must add a
do_compile_ptestfunction to build the test suite. Add a function similar to the following to your recipe:do_compile_ptest() { oe_runmake buildtest-TESTS }Ensure special configurations are set: If the package requires special configurations prior to compiling the test code, you must insert a
do_configure_ptestfunction into the recipe.Install the test suite: The
ptest.bbclassclass automatically copies the filerun-ptestto the target and then runs makeinstall-ptestto run the tests. If this is not enough, you need to create ado_install_ptestfunction and make sure it gets called after the "make install-ptest" completes.
By default, the OpenEmbedded build system uses the Build Directory to build source code. The build process involves fetching the source files, unpacking them, and then patching them if necessary before the build takes place.
Situations exist where you might want to build software from source
files that are external to and thus outside of the
OpenEmbedded build system.
For example, suppose you have a project that includes a new BSP with
a heavily customized kernel.
And, you want to minimize exposing the build system to the
development team so that they can focus on their project and
maintain everyone's workflow as much as possible.
In this case, you want a kernel source directory on the development
machine where the development occurs.
You want the recipe's
SRC_URI
variable to point to the external directory and use it as is, not
copy it.
To build from software that comes from an external source, all you
need to do is inherit
externalsrc.bbclass
and then set the
EXTERNALSRC
variable to point to your external source code.
Here are the statements to put in your
local.conf file:
INHERIT += "externalsrc"
EXTERNALSRC_pn-myrecipe = "/some/path/to/your/source/tree"
By default, externalsrc.bbclass builds
the source code in a directory separate from the external source
directory as specified by
EXTERNALSRC.
If you need to have the source built in the same directory in
which it resides, or some other nominated directory, you can set
EXTERNALSRC_BUILD
to point to that directory:
EXTERNALSRC_BUILD_pn-myrecipe = "/path/to/my/source/tree"
By default, the Yocto Project uses
SysVinit as the initialization manager.
However, support also exists for systemd,
which is a full replacement for init with
parallel starting of services, reduced shell overhead and other
features that are used by many distributions.
If you want to use sysvinit, you do
not have to do anything.
But, if you want to use systemd, you must
take some steps as described in the following sections.
Set the following variables in your distribution configuration file as follows:
DISTRO_FEATURES_append = " systemd"
VIRTUAL-RUNTIME_init_manager = "systemd"
You can also prevent the sysvinit
distribution feature from
being automatically enabled as follows:
DISTRO_FEATURES_BACKFILL_CONSIDERED = "sysvinit"
Doing so removes any redundant sysvinit
scripts.
For information on the backfill variable, see
DISTRO_FEATURES_BACKFILL_CONSIDERED
in the Yocto Project Reference Manual.
Set the following variables in your distribution configuration file as follows:
DISTRO_FEATURES_append = " systemd"
VIRTUAL-RUNTIME_init_manager = "systemd"
Doing so causes your main image to use the
packagegroup-core-boot.bb recipe and
systemd.
The rescue/minimal image cannot use this package group.
However, it can install sysvinit
and the appropriate packages will have support for both
systemd and sysvinit.
You might find that there are groups of recipes or append files
that you want to filter out of the build process.
Usually, this is not necessary.
However, on rare occasions where you might want to use a
layer but exclude parts that are causing problems, such
as introducing a different version of a recipe, you can
use
BBMASK
to exclude the recipe.
It is possible to filter or mask out .bb and
.bbappend files.
You can do this by providing an expression with the
BBMASK variable.
Here is one example:
BBMASK = "/meta-mymachine/recipes-maybe/"
Here, all .bb and
.bbappend files in the directory that match
the expression are ignored during the build process.
Note
The value you provide is passed to Python's regular expression compiler. The expression is compared against the full paths to the files. For complete syntax information, see Python's documentation at http://docs.python.org/release/2.3/lib/re-syntax.html.If you're working on a recipe that pulls from an external Source Code Manager (SCM), it is possible to have the OpenEmbedded build system notice new recipe changes added to the SCM and then build the resulting package that depends on the new recipes by using the latest versions. This only works for SCMs from which it is possible to get a sensible revision number for changes. Currently, you can do this with Apache Subversion (SVN), Git, and Bazaar (BZR) repositories.
To enable this behavior, simply add the following to the local.conf
configuration file found in the
Build Directory:
SRCREV_pn-<PN> = "${AUTOREV}"
where PN
is the name of the recipe for which you want to enable automatic source
revision updating.
In fact, the Yocto Project provides a distribution named
poky-bleeding, whose configuration
file contains the line:
require conf/distro/include/poky-floating-revisions.inc
This line pulls in the listed include file that contains numerous lines of exactly that form:
SRCREV_pn-gconf-dbus ?= "${AUTOREV}"
SRCREV_pn-matchbox-common ?= "${AUTOREV}"
SRCREV_pn-matchbox-config-gtk ?= "${AUTOREV}"
SRCREV_pn-matchbox-desktop ?= "${AUTOREV}"
SRCREV_pn-matchbox-keyboard ?= "${AUTOREV}"
SRCREV_pn-matchbox-panel ?= "${AUTOREV}"
SRCREV_pn-matchbox-panel-2 ?= "${AUTOREV}"
SRCREV_pn-matchbox-themes-extra ?= "${AUTOREV}"
SRCREV_pn-matchbox-terminal ?= "${AUTOREV}"
SRCREV_pn-matchbox-wm ?= "${AUTOREV}"
SRCREV_pn-matchbox-wm-2 ?= "${AUTOREV}"
SRCREV_pn-settings-daemon ?= "${AUTOREV}"
SRCREV_pn-screenshot ?= "${AUTOREV}"
SRCREV_pn-libfakekey ?= "${AUTOREV}"
SRCREV_pn-oprofileui ?= "${AUTOREV}"
.
.
.
These lines allow you to experiment with building a distribution that tracks the latest development source for numerous packages.
Caution
Thepoky-bleeding distribution
is not tested on a regular basis.
Keep this in mind if you use it.
Suppose, for security reasons, you need to disable your target device's root filesystem's write permissions (i.e. you need a read-only root filesystem). Or, perhaps you are running the device's operating system from a read-only storage device. For either case, you can customize your image for that behavior.
Note
Supporting a read-only root filesystem requires that the system and applications do not try to write to the root filesystem. You must configure all parts of the target system to write elsewhere, or to gracefully fail in the event of attempting to write to the root filesystem.
To create the read-only root filesystem, simply add the
read-only-rootfs feature to your image.
Using either of the following statements in your
image recipe or from within the
local.conf file found in the
Build Directory
causes the build system to create a read-only root filesystem:
IMAGE_FEATURES = "read-only-rootfs"
or
EXTRA_IMAGE_FEATURES += "read-only-rootfs"
For more information on how to use these variables, see the
"Customizing Images Using Custom IMAGE_FEATURES and EXTRA_IMAGE_FEATURES"
section.
For information on the variables, see
IMAGE_FEATURES
and EXTRA_IMAGE_FEATURES.
It is very important that you make sure all
post-Installation (pkg_postinst) scripts
for packages that are installed into the image can be run
at the time when the root filesystem is created during the
build on the host system.
These scripts cannot attempt to run during first-boot on the
target device.
With the read-only-rootfs feature enabled,
the build system checks during root filesystem creation to make
sure all post-installation scripts succeed.
If any of these scripts still need to be run after the root
filesystem is created, the build immediately fails.
These checks during build time ensure that the build fails
rather than the target device fails later during its
initial boot operation.
Most of the common post-installation scripts generated by the build system for the out-of-the-box Yocto Project are engineered so that they can run during root filesystem creation (e.g. post-installation scripts for caching fonts). However, if you create and add custom scripts, you need to be sure they can be run during file system creation.
Here are some common problems that prevent post-installation scripts from running during root filesystem creation:
Not using $D in front of absolute paths: The build system defines
$Dat root filesystem creation time, and it is blank when run on the target device. This implies two purposes for$D: ensuring paths are valid in both the host and target environments, and checking to determine which environment is being used as a method for taking appropriate actions.Attempting to run processes that are specific to or dependent on the target architecture: You can work around these attempts by using native tools to accomplish the same tasks, or by alternatively running the processes under QEMU, which has the
qemu_run_binaryfunction. For more information, see themeta/classes/qemu.bbclassclass in the Source Directory.
With the read-only-rootfs feature enabled,
any attempt by the target to write to the root filesystem at
runtime fails.
Consequently, you must make sure that you configure processes
and applications that attempt these types of writes do so
to directories with write access (e.g.
/tmp or /var/run).
The OpenEmbedded build system makes available a series of automated tests for images to verify runtime functionality.
Note
Currently, there is only support for running these tests under QEMU.
These tests are written in Python making use of the
unittest module, and the majority of them
run commands on the target system over
ssh.
This section describes how you set up the environment to use these
tests, run available tests, and write and add your own tests.
In order to run tests, you need to do the following:
Set up to avoid interaction with
sudofor networking: To accomplish this, you must do one of the following:Add
NOPASSWDfor your user in/etc/sudoerseither for ALL commands or just forrunqemu-ifup. You must provide the full path as that can change if you are using multiple clones of the source repository.Note
On some distributions, you also need to comment out "Defaults requiretty" in/etc/sudoers.Manually configure a tap interface for your system.
Run as root the script in
scripts/runqemu-gen-tapdevs, which should generate a list of tap devices. This is the option typically chosen for Autobuilder-type environments.
Set the
DISPLAYvariable: You need to set this variable so that you have an X server available (e.g. startvncserverfor a headless machine).Be sure your host's firewall accepts incoming connections from 192.168.7.0/24: Some of the tests (in particular smart tests) start a HTTP server on a random high number port, which is used to serve files to the target. The smart module serves
${DEPLOY_DIR}/rpmso it can run smart channel commands. That means your host's firewall must accept incoming connections from 192.168.7.0/24, which is the default IP range used for tap devices byrunqemu.
Note
Regardless of how you initiate the tests, if you built your image usingrm_work,
most of the tests will fail with errors because they rely on
${WORKDIR}/installed_pkgs.txt.
You can start the tests automatically or manually:
Automatically Running Tests: To run the tests automatically after the OpenEmbedded build system successfully creates an image, first set the
TEST_IMAGEvariable to "1" in yourlocal.conffile in the Build Directory:TEST_IMAGE = "1"Next, simply build your image. If the image successfully builds, the tests will be run:
bitbake core-image-satoManually Running Tests: To manually run the tests, first globally inherit
testimage.classby editing yourlocal.conffile:INHERIT += "testimage"Next, use BitBake to run the tests:
bitbake -c testimage <image>
Regardless of how you run the tests, once they start, the following happens:
A copy of the root filesystem is written to
${WORKDIR}/testimage.The image is booted under QEMU using the standard
runqemuscript.A default timeout of 500 seconds occurs to allow for the boot process to reach the login prompt. You can change the timeout period by setting
TEST_QEMUBOOT_TIMEOUTin thelocal.conffile.Once the boot process is reached and the login prompt appears, the tests run. The full boot log is written to
${WORKDIR}/testimage/qemu_boot_log.Each test module loads in the order found in
TEST_SUITES. You can find the full output of the commands run oversshin${WORKDIR}/testimgage/ssh_target_log.If no failures occur, the task running the tests ends successfully. You can find the output from the
unittestin the task log at${WORKDIR}/temp/log.do_testimage.
All test files reside in
meta/lib/oeqa/runtime in the
Source Directory.
A test name maps directly to a Python module.
Each test module may contain a number of individual tests.
Tests are usually grouped together by the area
tested (e.g tests for systemd reside in
meta/lib/oeqa/runtime/systemd.py).
You can add tests to any layer provided you place them in the
proper area and you extend
BBPATH
in the local.conf file as normal.
Be sure that tests reside in
<layer>/lib/oeqa/runtime.
Note
Be sure that module names do not collide with module names used in the default set of test modules inmeta/lib/oeqa/runtime.
You can change the set of tests run by appending or overriding
TEST_SUITES
variable in local.conf.
Each name in TEST_SUITES represents a
required test for the image.
Test modules named within TEST_SUITES
cannot be skipped even if a test is not suitable for an image
(e.g. running the rpm tests on an image without
rpm).
Appending "auto" to TEST_SUITES causes the
build system to try to run all tests that are suitable for the
image (i.e. each test module may elect to skip itself).
The order you list tests in TEST_SUITES
is important.
The order influences test dependencies.
Consequently, tests that depend on other tests should be added
after the test on which they depend.
For example, since ssh depends on the
ping test, ssh
needs to come after ping in the list.
The test class provides no re-ordering or dependency handling.
Note
Each module can have multiple classes with multiple test methods. And, Pythonunittest rules apply.
Here are some things to keep in mind when running tests:
The default tests for the image are defined as:
DEFAULT_TEST_SUITES_pn-<image> = "ping ssh df connman syslog xorg scp vnc date rpm smart dmesg"Add your own test to the list of the by using the following:
TEST_SUITES_append = " mytest"Run a specific list of tests as follows:
TEST_SUITES = "test1 test2 test3"Remember, order is important. Be sure to place a test that is dependent on another test later in the order.
As mentioned previously, all new test files need to be in the
proper place for the build system to find them.
New tests for additional functionality outside of the core
should be added to the layer that adds the functionality, in
<layer>/lib/oeqa/runtime (as
long as
BBPATH
is extended in the layer's
layer.conf file as normal).
Just remember that filenames need to map directly to test
(module) names and that you do not use module names that
collide with existing core tests.
To create a new test, start by copying an existing module
(e.g. syslog.py or
gcc.py are good ones to use).
Test modules can use code from
meta/lib/oeqa/utils, which are helper
classes.
Note
Structure shell commands such that you rely on them and they return a single code for success. Be aware that sometimes you will need to parse the output. See thedf.py and
date.py modules for examples.
You will notice that all test classes inherit
oeRuntimeTest, which is found in
meta/lib/oetest.py.
This base class offers some helper attributes, which are
described in the following sections:
Class methods are as follows:
hasPackage(pkg): Returns "True" ifpkgis in the installed package list of the image, which is based on${WORKDIR}/installed_pkgs.txtthat is generated during thedo.rootfstask.hasFeature(feature): Returns "True" if the feature is inIMAGE_FEATURESorDISTRO_FEATURES.restartTarget(params): Restarts the QEMU image optionally passingparamsto therunqemuscript'sqemuparamslist (e.g "-m 1024" for more memory).
Class attributes are as follows:
pscmd: Equals "ps -ef" ifprocpsis installed in the image. Otherwise,pscmdequals "ps" (busybox).tc: The called text context, which gives access to the following attributes:d: The BitBake data store, which allows you to use stuff such asoeRuntimeTest.tc.d.getVar("VIRTUAL-RUNTIME_init_manager").testslistandtestsrequired: Used internally. The tests do not need these.filesdir: The absolute path tometa/lib/oeqa/runtime/files, which contains helper files for tests meant for copying on the target such as small files written in C for compilation.qemu: Provides access to theQemuRunnerobject, which is the class that boots the image. Theqemuattribute provides the following useful attributes:ip: The machine's IP address.host_ip: The host IP address, which is only used by smart tests.
target: TheSSHControlobject, which is used for running the following commands on the image:host: Used internally. The tests do not use this command.timeout: A global timeout for commands run on the target for the instance of a test. The default is 300 seconds.run(cmd, timeout=None): The single, most used method. This command is a wrapper for:ssh root@host "cmd". The command returns a tuple: (status, output), which are what their names imply - the return code of 'cmd' and whatever output it produces. The optional timeout argument represents the number of seconds the test should wait for 'cmd' to return. If the argument is "None", the test uses the default instance's timeout period, which is 300 seconds. If the argument is "0", the test runs until the command returns.copy_to(localpath, remotepath):scp localpath root@ip:remotepath.copy_from(remotepath, localpath):scp root@host:remotepath localpath.
A single instance attribute exists, which is
target.
The target instance attribute is
identical to the class attribute of the same name, which
is described in the previous section.
This attribute exists as both an instance and class
attribute so tests can use
self.target.run(cmd) in instance
methods instead of
oeRuntimeTest.tc.target.run(cmd).
GDB allows you to examine running programs, which in turn helps you to understand and fix problems. It also allows you to perform post-mortem style analysis of program crashes. GDB is available as a package within the Yocto Project and is installed in SDK images by default. See the "Images" chapter in the Yocto Project Reference Manual for a description of these images. You can find information on GDB at http://sourceware.org/gdb/.
Tip
For best results, install-dbg packages for
the applications you are going to debug.
Doing so makes extra debug symbols available that give you more
meaningful output.
Sometimes, due to memory or disk space constraints, it is not possible to use GDB directly on the remote target to debug applications. These constraints arise because GDB needs to load the debugging information and the binaries of the process being debugged. Additionally, GDB needs to perform many computations to locate information such as function names, variable names and values, stack traces and so forth - even before starting the debugging process. These extra computations place more load on the target system and can alter the characteristics of the program being debugged.
To help get past the previously mentioned constraints, you can use Gdbserver. Gdbserver runs on the remote target and does not load any debugging information from the debugged process. Instead, a GDB instance processes the debugging information that is run on a remote computer - the host GDB. The host GDB then sends control commands to Gdbserver to make it stop or start the debugged program, as well as read or write memory regions of that debugged program. All the debugging information loaded and processed as well as all the heavy debugging is done by the host GDB. Offloading these processes gives the Gdbserver running on the target a chance to remain small and fast.
Because the host GDB is responsible for loading the debugging information and for doing the necessary processing to make actual debugging happen, the user has to make sure the host can access the unstripped binaries complete with their debugging information and also be sure the target is compiled with no optimizations. The host GDB must also have local access to all the libraries used by the debugged program. Because Gdbserver does not need any local debugging information, the binaries on the remote target can remain stripped. However, the binaries must also be compiled without optimization so they match the host's binaries.
To remain consistent with GDB documentation and terminology, the binary being debugged on the remote target machine is referred to as the "inferior" binary. For documentation on GDB see the GDB site.
The remainder of this section describes the steps you need to take to debug using the GNU project debugger.
Before you can initiate a remote debugging session, you need to be sure you have set up the cross-development environment, toolchain, and sysroot. The "Preparing for Application Development" chapter of the Yocto Project Application Developer's Guide describes this process. Be sure you have read that chapter and have set up your environment.
Make sure Gdbserver is installed on the target.
If it is not, install the package
gdbserver, which needs the
libthread-db1 package.
Here is an example that when entered from the host
connects to the target and launches Gdbserver in order to
"debug" a binary named helloworld:
$ gdbserver localhost:2345 /usr/bin/helloworld
Gdbserver should now be listening on port 2345 for debugging commands coming from a remote GDB process that is running on the host computer. Communication between Gdbserver and the host GDB are done using TCP. To use other communication protocols, please refer to the Gdbserver documentation.
Running GDB on the host computer takes a number of stages, which this section describes.
A suitable GDB cross-binary is required that runs on your
host computer but also knows about the the ABI of the
remote target.
You can get this binary from the
Cross-Development Toolchain.
Here is an example where the toolchain has been installed
in the default directory
/opt/poky/1.5.2:
/opt/poky/1.4/sysroots/i686-pokysdk-linux/usr/bin/armv7a-vfp-neon-poky-linux-gnueabi/arm-poky-linux-gnueabi-gdb
where arm is the target architecture
and linux-gnueabi is the target ABI.
Alternatively, you can use BitBake to build the
gdb-cross binary.
Here is an example:
$ bitbake gdb-cross
Once the binary is built, you can find it here:
tmp/sysroots/<host-arch>/usr/bin/<target-platform>/<target-abi>-gdb
Aside from the GDB cross-binary, you also need a GDB
initialization file in the same top directory in which
your binary resides.
When you start GDB on your host development system, GDB
finds this initialization file and executes all the
commands within.
For information on the .gdbinit, see
"Debugging with GDB",
which is maintained by
sourceware.org.
You need to add a statement in the
.gdbinit file that points to your
root filesystem.
Here is an example that points to the root filesystem for
an ARM-based target device:
set sysroot /home/jzhang/sysroot_arm
Before launching the host GDB, you need to be sure
you have sourced the cross-debugging environment script,
which if you installed the root filesystem in the default
location is at /opt/poky/1.5.2
and begins with the string "environment-setup".
For more information, see the
"Setting Up the Cross-Development Environment"
section in the Yocto Project Application Developer's
Guide.
Finally, switch to the directory where the binary resides
and run the cross-gdb binary.
Provide the binary file you are going to debug.
For example, the following command continues with the
example used in the previous section by loading
the helloworld binary as well as the
debugging information:
$ arm-poky-linux-gnuabi-gdb helloworld
The commands in your .gdbinit execute
and the GDB prompt appears.
From the target, you need to connect to the remote GDB server that is running on the host. You need to specify the remote host and port. Here is the command continuing with the example:
target remote 192.168.7.2:2345
You can now proceed with debugging as normal - as if you were debugging on the local machine. For example, to instruct GDB to break in the "main" function and then continue with execution of the inferior binary use the following commands from within GDB:
(gdb) break main
(gdb) continue
For more information about using GDB, see the project's online documentation at http://sourceware.org/gdb/download/onlinedocs/.
Toaster is an Application Programming Interface (API) and
web-based interface to the OpenEmbedded build system, which uses
BitBake.
Both interfaces are based on a Representational State Transfer
(REST) API that queries for and returns build information using
GET and JSON.
These types of search operations retrieve sets of objects from
a data store used to collect build information.
The results contain all the data for the objects being returned.
You can order the results of the search by key and the search
parameters are consistent for all object types.
Using the interfaces you can do the following:
See information about the tasks executed and reused during the build.
See what is built (recipes and packages) and what packages were installed into the final image.
See performance-related information such as build time, CPU usage, and disk I/O.
Examine error, warning and trace messages to aid in debugging.
Note
This release of Toaster provides you with information about a BitBake run. The tool does not allow you to configure and launch a build. However, future development includes plans to integrate the configuration and build launching capabilities of Hob.
For more information on using Hob to build an image, see the "Image Development Using Hob" section.
The remainder of this section describes what you need to have in place to use Toaster, how to start it, use it, and stop it. For additional information on installing and running Toaster, see the "Installation and Running" section of the "Toaster" wiki page. For complete information on the API and its search operation URI, parameters, and responses, see the REST API Contracts Wiki page.
Getting set up to use and start Toaster is simple. First, be sure you have met the following requirements:
You have set up your Source Directory by cloning the upstream
pokyrepository. See the Yocto Project Release item for information on how to set up the Source Directory.You have checked out the
dora-toasterbranch:$ cd poky $ git checkout -b dora-toaster origin/dora-toasterBe sure your build machine has Django version 1.4.5 installed.
Make sure that port 8000 and 8200 are free (i.e. they have no servers on them).
Once you have met the requirements, follow these steps to start Toaster running in the background of your shell:
Note
The Toaster must be started and running in order for it to collect data.Set up your build environment: Source a build environment script (i.e.
oe-init-build-envoroe-init-build-env-memres).Prepare your local configuration file: Toaster needs the Toaster class enabled in Bitbake in order to record target image package information. You can enable it by adding the following line to your
conf/local.conffile:INHERIT += "toaster"Toaster also needs Build History enabled in Bitbake in order to record target image package information. You can enable this by adding the following two lines to your
conf/local.conffile:INHERIT += "buildhistory" BUILDHISTORY_COMMIT = "1"Start Toaster: Start the Toaster service using this command from within your build directory:
$ source toaster start
When Toaster starts, it creates some additional files in your Build Directory. Deleting these files will cause you to lose data or interrupt Toaster:
toaster.sqlite: Toaster's database file.toaster_web.log: The log file of the web server.toaster_ui.log: The log file of the user interface component.toastermain.pid: The PID of the web server.toasterui.pid: The PID of the DSI data bridge.bitbake-cookerdaemon.log: The BitBake server's log file.
Once Toaster is running, it logs information for any BitBake run from your Build Directory. This logging is automatic. All you need to do is access and use the information.
You access the information one of two ways:
Open a Browser and type enter in the
http://localhost:8000URL.Use the
xdg-opentool from the shell and pass it the same URL.
Either method opens the home page for the Toaster interface, which is temporary for this release.
The Toaster database is persistent regardless of whether you start or stop the service.
Toaster's interface shows you a list of builds (successful and unsuccessful) for which it has data. You can click on any build to see related information. This information includes configuration details, information about tasks, all recipes and packages built and their dependencies, packages installed in your final image, execution time, CPU usage and disk I/O per task.
OProfile is a statistical profiler well suited for finding performance bottlenecks in both user-space software and in the kernel. This profiler provides answers to questions like "Which functions does my application spend the most time in when doing X?" Because the OpenEmbedded build system is well integrated with OProfile, it makes profiling applications on target hardware straightforward.
Note
For more information on how to set up and run OProfile, see the "OProfile" section in the Yocto Project Profiling and Tracing Manual.
To use OProfile, you need an image that has OProfile installed.
The easiest way to do this is with tools-profile in the
IMAGE_FEATURES variable.
You also need debugging symbols to be available on the system where the analysis
takes place.
You can gain access to the symbols by using dbg-pkgs in the
IMAGE_FEATURES variable or by
installing the appropriate -dbg packages.
For successful call graph analysis, the binaries must preserve the frame
pointer register and should also be compiled with the
-fno-omit-framepointer flag.
You can achieve this by setting the
SELECTED_OPTIMIZATION
variable with the following options:
-fexpensive-optimizations
-fno-omit-framepointer
-frename-registers
-O2
You can also achieve it by setting the
DEBUG_BUILD
variable to "1" in the local.conf configuration file.
If you use the DEBUG_BUILD variable,
you also add extra debugging information that can make the debug
packages large.
Using OProfile you can perform all the profiling work on the target device. A simple OProfile session might look like the following:
# opcontrol --reset
# opcontrol --start --separate=lib --no-vmlinux -c 5
.
.
[do whatever is being profiled]
.
.
# opcontrol --stop
$ opreport -cl
In this example, the reset command clears any previously profiled data.
The next command starts OProfile.
The options used when starting the profiler separate dynamic library data
within applications, disable kernel profiling, and enable callgraphing up to
five levels deep.
Note
To profile the kernel, you would specify the--vmlinux=/path/to/vmlinux option.
The vmlinux file is usually in the source directory in the
/boot/ directory and must match the running kernel.
After you perform your profiling tasks, the next command stops the profiler.
After that, you can view results with the opreport command with options
to see the separate library symbols and callgraph information.
Callgraphing logs information about time spent in functions and about a function's calling function (parent) and called functions (children). The higher the callgraphing depth, the more accurate the results. However, higher depths also increase the logging overhead. Consequently, you should take care when setting the callgraphing depth.
Note
On ARM, binaries need to have the frame pointer enabled for callgraphing to work. To accomplish this use the-fno-omit-framepointer option
with gcc.
For more information on using OProfile, see the OProfile online documentation at http://oprofile.sourceforge.net/docs/.
A graphical user interface for OProfile is also available. You can download and build this interface from the Yocto Project at http://git.yoctoproject.org/cgit.cgi/oprofileui/. If the "tools-profile" image feature is selected, all necessary binaries are installed onto the target device for OProfileUI interaction. For a list of image features that ship with the Yocto Project, see the "Image Features" section in the Yocto Project Reference Manual.
Even though the source directory usually includes all needed patches on the target device, you might find you need other OProfile patches for recent OProfileUI features. If so, see the OProfileUI README for the most recent information.
Using OProfile in online mode assumes a working network connection with the target hardware. With this connection, you just need to run "oprofile-server" on the device. By default, OProfile listens on port 4224.
Note
You can change the port using the--port command-line
option.
The client program is called oprofile-viewer and its UI is relatively
straightforward.
You access key functionality through the buttons on the toolbar, which
are duplicated in the menus.
Here are the buttons:
Connect: Connects to the remote host. You can also supply the IP address or hostname.
Disconnect: Disconnects from the target.
Start: Starts profiling on the device.
Stop: Stops profiling on the device and downloads the data to the local host. Stopping the profiler generates the profile and displays it in the viewer.
Download: Downloads the data from the target and generates the profile, which appears in the viewer.
Reset: Resets the sample data on the device. Resetting the data removes sample information collected from previous sampling runs. Be sure you reset the data if you do not want to include old sample information.
Save: Saves the data downloaded from the target to another directory for later examination.
Open: Loads previously saved data.
The client downloads the complete 'profile archive' from
the target to the host for processing.
This archive is a directory that contains the sample data, the object files,
and the debug information for the object files.
The archive is then converted using the oparchconv script, which is
included in this distribution.
The script uses opimport to convert the archive from
the target to something that can be processed on the host.
Downloaded archives reside in the
Build Directory in
tmp and are cleared up when they are no longer in use.
If you wish to perform kernel profiling, you need to be sure
a vmlinux file that matches the running kernel is available.
In the source directory, that file is usually located in
/boot/vmlinux-KERNELVERSION, where
KERNEL-version is the version of the kernel.
The OpenEmbedded build system generates separate vmlinux
packages for each kernel it builds.
Thus, it should just be a question of making sure a matching package is
installed (e.g. opkg install kernel-vmlinux).
The files are automatically installed into development and profiling images
alongside OProfile.
A configuration option exists within the OProfileUI settings page that you can use to
enter the location of the vmlinux file.
Waiting for debug symbols to transfer from the device can be slow, and it is not always necessary to actually have them on the device for OProfile use. All that is needed is a copy of the filesystem with the debug symbols present on the viewer system. The "Launch GDB on the Host Computer" section covers how to create such a directory with the Source Directory and how to use the OProfileUI Settings Dialog to specify the location. If you specify the directory, it will be used when the file checksums match those on the system you are profiling.
If network access to the target is unavailable, you can generate
an archive for processing in oprofile-viewer as follows:
# opcontrol --reset
# opcontrol --start --separate=lib --no-vmlinux -c 5
.
.
[do whatever is being profiled]
.
.
# opcontrol --stop
# oparchive -o my_archive
In the above example, my_archive is the name of the
archive directory where you would like the profile archive to be kept.
After the directory is created, you can copy it to another host and load it
using oprofile-viewer open functionality.
If necessary, the archive is converted.
One of the concerns for a development organization using open source software is how to maintain compliance with various open source licensing during the lifecycle of the product. While this section does not provide legal advice or comprehensively cover all scenarios, it does present methods that you can use to assist you in meeting the compliance requirements during a software release.
With hundreds of different open source licenses that the Yocto Project tracks, it is difficult to know the requirements of each and every license. However, we can begin to cover the requirements of the major FLOSS licenses, by assuming that there are three main areas of concern:
Source code must be provided.
License text for the software must be provided.
Compilation scripts and modifications to the source code must be provided.
There are other requirements beyond the scope of these three and the methods described in this section (e.g. the mechanism through which source code is distributed).
As different organizations have different methods of complying with open source licensing, this section is not meant to imply that there is only one single way to meet your compliance obligations, but rather to describe one method of achieving compliance. The remainder of this section describes methods supported to meet the previously mentioned three requirements. Once you take steps to meet these requirements, and prior to releasing images, sources, and the build system, you should audit all artifacts to ensure completeness.
Note
The Yocto Project generates a license manifest during image creation that is located in${DEPLOY_DIR}/licenses/<image_name-datestamp>
to assist with any audits.
Compliance activities should begin before you generate the final image. The first thing you should look at is the requirement that tops the list for most compliance groups - providing the source. The Yocto Project has a few ways of meeting this requirement.
One of the easiest ways to meet this requirement is
to provide the entire
DL_DIR
used by the build.
This method, however, has a few issues.
The most obvious is the size of the directory since it includes
all sources used in the build and not just the source used in
the released image.
It will include toolchain source, and other artifacts, which
you would not generally release.
However, the more serious issue for most companies is accidental
release of proprietary software.
The Yocto Project provides an archiver class to help avoid
some of these concerns.
See the
"Archiving Sources - archive*.bbclass"
section in the Yocto Project Reference Manual for information
on this class.
Before you employ DL_DIR or the
archiver class, you need to decide how you choose to
provide source.
The source archiver class can generate tarballs and SRPMs
and can create them with various levels of compliance in mind.
One way of doing this (but certainly not the only way) is to
release just the original source as a tarball.
You can do this by adding the following to the
local.conf file found in the
Build Directory:
ARCHIVER_MODE ?= "original"
ARCHIVER_CLASS = "${@'archive-${ARCHIVER_MODE}-source' if ARCHIVER_MODE != 'none' else ''}"
INHERIT += "${ARCHIVER_CLASS}"
SOURCE_ARCHIVE_PACKAGE_TYPE = "tar"
During the creation of your image, the source from all
recipes that deploy packages to the image is placed within
subdirectories of
DEPLOY_DIR/sources based on the
LICENSE
for each recipe.
Releasing the entire directory enables you to comply with
requirements concerning providing the unmodified source.
It is important to note that the size of the directory can
get large.
A way to help mitigate the size issue is to only release tarballs for licenses that require the release of source. Let's assume you are only concerned with GPL code as identified with the following:
$ cd poky/build/tmp/deploy/sources
$ mkdir ~/gpl_source_release
$ for dir in */*GPL*; do cp -r $dir ~/gpl_source_release; done
At this point, you could create a tarball from the
gpl_source_release directory and
provide that to the end user.
This method would be a step toward achieving compliance
with section 3a of GPLv2 and with section 6 of GPLv3.
One requirement that is often overlooked is inclusion
of license text.
This requirement also needs to be dealt with prior to
generating the final image.
Some licenses require the license text to accompany
the binary.
You can achieve this by adding the following to your
local.conf file:
COPY_LIC_MANIFEST = "1"
COPY_LIC_DIRS = "1"
Adding these statements to the configuration file ensures that the licenses collected during package generation are included on your image. As the source archiver has already archived the original unmodified source that contains the license files, you would have already met the requirements for inclusion of the license information with source as defined by the GPL and other open source licenses.
At this point, we have addressed all we need to address prior to generating the image. The next two requirements are addressed during the final packaging of the release.
By releasing the version of the OpenEmbedded build system and the layers used during the build, you will be providing both compilation scripts and the source code modifications in one step.
If the deployment team has a BSP layer and a distro layer, and those those layers are used to patch, compile, package, or modify (in any way) any open source software included in your released images, you may be required to to release those layers under section 3 of GPLv2 or section 1 of GPLv3. One way of doing that is with a clean checkout of the version of the Yocto Project and layers used during your build. Here is an example:
# We built using the dora branch of the poky repo
$ git clone -b dora git://git.yoctoproject.org/poky
$ cd poky
# We built using the release_branch for our layers
$ git clone -b release_branch git://git.mycompany.com/meta-my-bsp-layer
$ git clone -b release_branch git://git.mycompany.com/meta-my-software-layer
# clean up the .git repos
$ find . -name ".git" -type d -exec rm -rf {} \;
One thing a development organization might want to consider
for end-user convenience is to modify
meta-yocto/conf/bblayers.conf.sample to
ensure that when the end user utilizes the released build
system to build an image, the development organization's
layers are included in the bblayers.conf
file automatically:
# LAYER_CONF_VERSION is increased each time build/conf/bblayers.conf
# changes incompatibly
LCONF_VERSION = "6"
BBPATH = "${TOPDIR}"
BBFILES ?= ""
BBLAYERS ?= " \
##OEROOT##/meta \
##OEROOT##/meta-yocto \
##OEROOT##/meta-yocto-bsp \
##OEROOT##/meta-mylayer \
"
BBLAYERS_NON_REMOVABLE ?= " \
##OEROOT##/meta \
##OEROOT##/meta-yocto \
"
Creating and providing an archive of the Metadata layers (recipes, configuration files, and so forth) enables you to meet your requirements to include the scripts to control compilation as well as any modifications to the original source.
 |
Copyright © 2010-2014 Linux Foundation
Permission is granted to copy, distribute and/or modify this document under the terms of the Creative Commons Attribution-Share Alike 2.0 UK: England & Wales as published by Creative Commons.
Note
For the latest version of this manual associated with this Yocto Project release, see the Yocto Project Application Developer's Guide from the Yocto Project website.| Revision History | |
|---|---|
| Revision 1.0 | 6 April 2011 |
| Released with the Yocto Project 1.0 Release. | |
| Revision 1.0.1 | 23 May 2011 |
| Released with the Yocto Project 1.0.1 Release. | |
| Revision 1.1 | 6 October 2011 |
| Released with the Yocto Project 1.1 Release. | |
| Revision 1.2 | April 2012 |
| Released with the Yocto Project 1.2 Release. | |
| Revision 1.3 | October 2012 |
| Released with the Yocto Project 1.3 Release. | |
| Revision 1.4 | April 2013 |
| Released with the Yocto Project 1.4 Release. | |
| Revision 1.5 | October 2013 |
| Released with the Yocto Project 1.5 Release. | |
| Revision 1.5.1 | January 2014 |
| Released with the Yocto Project 1.5.1 Release. | |
| Revision 1.5.2 | May 2014 |
| Released with the Yocto Project 1.5.2 Release. | |
Welcome to the Yocto Project Application Developer's Guide. This manual provides information that lets you begin developing applications using the Yocto Project.
The Yocto Project provides an application development environment based on an Application Development Toolkit (ADT) and the availability of stand-alone cross-development toolchains and other tools. This manual describes the ADT and how you can configure and install it, how to access and use the cross-development toolchains, how to customize the development packages installation, how to use command line development for both Autotools-based and Makefile-based projects, and an introduction to the Eclipse™ IDE Yocto Plug-in.
Note
The ADT is distribution-neutral and does not require the Yocto Project reference distribution, which is called Poky. This manual, however, uses examples that use the Poky distribution.
Part of the Yocto Project development solution is an Application Development Toolkit (ADT). The ADT provides you with a custom-built, cross-development platform suited for developing a user-targeted product application.
Fundamentally, the ADT consists of the following:
An architecture-specific cross-toolchain and matching sysroot both built by the OpenEmbedded build system. The toolchain and sysroot are based on a Metadata configuration and extensions, which allows you to cross-develop on the host machine for the target hardware.
The Eclipse IDE Yocto Plug-in.
The Quick EMUlator (QEMU), which lets you simulate target hardware.
Various user-space tools that greatly enhance your application development experience.
The Cross-Development Toolchain consists of a cross-compiler, cross-linker, and cross-debugger that are used to develop user-space applications for targeted hardware. This toolchain is created either by running the ADT Installer script, a toolchain installer script, or through a Build Directory that is based on your Metadata configuration or extension for your targeted device. The cross-toolchain works with a matching target sysroot.
The matching target sysroot contains needed headers and libraries for generating binaries that run on the target architecture. The sysroot is based on the target root filesystem image that is built by the OpenEmbedded build system and uses the same Metadata configuration used to build the cross-toolchain.
The Eclipse IDE is a popular development environment and it fully supports development using the Yocto Project. When you install and configure the Eclipse Yocto Project Plug-in into the Eclipse IDE, you maximize your Yocto Project experience. Installing and configuring the Plug-in results in an environment that has extensions specifically designed to let you more easily develop software. These extensions allow for cross-compilation, deployment, and execution of your output into a QEMU emulation session. You can also perform cross-debugging and profiling. The environment also supports a suite of tools that allows you to perform remote profiling, tracing, collection of power data, collection of latency data, and collection of performance data.
For information about the application development workflow that uses the Eclipse IDE and for a detailed example of how to install and configure the Eclipse Yocto Project Plug-in, see the "Working Within Eclipse" section of the Yocto Project Development Manual.
The QEMU emulator allows you to simulate your hardware while running your application or image. QEMU is made available a number of ways:
If you use the ADT Installer script to install ADT, you can specify whether or not to install QEMU.
If you have downloaded a Yocto Project release and unpacked it to create a Source Directory and you have sourced the environment setup script, QEMU is installed and automatically available.
If you have installed the cross-toolchain tarball and you have sourced the toolchain's setup environment script, QEMU is also installed and automatically available.
User-space tools are included as part of the distribution. You will find these tools helpful during development. The tools include LatencyTOP, PowerTOP, OProfile, Perf, SystemTap, and Lttng-ust. These tools are common development tools for the Linux platform.
LatencyTOP: LatencyTOP focuses on latency that causes skips in audio, stutters in your desktop experience, or situations that overload your server even when you have plenty of CPU power left.
PowerTOP: Helps you determine what software is using the most power. You can find out more about PowerTOP at https://01.org/powertop/.
OProfile: A system-wide profiler for Linux systems that is capable of profiling all running code at low overhead. You can find out more about OProfile at http://oprofile.sourceforge.net/about/. For examples on how to setup and use this tool, see the "OProfile" section in the Yocto Project Profiling and Tracing Manual.
Perf: Performance counters for Linux used to keep track of certain types of hardware and software events. For more information on these types of counters see https://perf.wiki.kernel.org/ and click on “Perf tools.” For examples on how to setup and use this tool, see the "perf" section in the Yocto Project Profiling and Tracing Manual.
SystemTap: A free software infrastructure that simplifies information gathering about a running Linux system. This information helps you diagnose performance or functional problems. SystemTap is not available as a user-space tool through the Eclipse IDE Yocto Plug-in. See http://sourceware.org/systemtap for more information on SystemTap. For examples on how to setup and use this tool, see the "SystemTap" section in the Yocto Project Profiling and Tracing Manual.
Lttng-ust: A User-space Tracer designed to provide detailed information on user-space activity. See http://lttng.org/ust for more information on Lttng-ust.
In order to develop applications, you need set up your host development system. Several ways exist that allow you to install cross-development tools, QEMU, the Eclipse Yocto Plug-in, and other tools. This chapter describes how to prepare for application development.
The following list describes installation methods that set up varying degrees of tool
availability on your system.
Regardless of the installation method you choose,
you must source the cross-toolchain
environment setup script before you use a toolchain.
See the "Setting Up the
Cross-Development Environment" section for more information.
Note
Avoid mixing installation methods when installing toolchains for different architectures. For example, avoid using the ADT Installer to install some toolchains and then hand-installing cross-development toolchains by running the toolchain installer for different architectures. Mixing installation methods can result in situations where the ADT Installer becomes unreliable and might not install the toolchain.
If you must mix installation methods, you might avoid problems by deleting
/var/lib/opkg, thus purging the opkg package
metadata
Use the ADT installer script: This method is the recommended way to install the ADT because it automates much of the process for you. For example, you can configure the installation to install the QEMU emulator and the user-space NFS, specify which root filesystem profiles to download, and define the target sysroot location.
Use an existing toolchain: Using this method, you select and download an architecture-specific toolchain installer and then run the script to hand-install the toolchain. If you use this method, you just get the cross-toolchain and QEMU - you do not get any of the other mentioned benefits had you run the ADT Installer script.
Use the toolchain from within the Build Directory: If you already have a Build Directory, you can build the cross-toolchain within the directory. However, like the previous method mentioned, you only get the cross-toolchain and QEMU - you do not get any of the other benefits without taking separate steps.
To run the ADT Installer, you need to get the ADT Installer tarball, be sure you have the necessary host development packages that support the ADT Installer, and then run the ADT Installer Script.
For a list of the host packages needed to support ADT installation and use, see the "ADT Installer Extras" lists in the "Required Packages for the Host Development System" section of the Yocto Project Reference Manual.
The ADT Installer is contained in the ADT Installer tarball. You can get the tarball using either of these methods:
Download the Tarball: You can download the tarball from http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/adt-installer into any directory.
Build the Tarball: You can use BitBake to generate the tarball inside an existing Build Directory.
If you use BitBake to generate the ADT Installer tarball, you must
sourcethe environment setup script (oe-init-build-envoroe-init-build-env-memres) located in the Source Directory before running the BitBake command that creates the tarball.The following example commands establish the Source Directory, check out the current release branch, set up the build environment while also creating the default Build Directory, and run the BitBake command that results in the tarball
poky/build/tmp/deploy/sdk/adt_installer.tar.bz2:Note
Before using BitBake to build the ADT tarball, be sure to make sure yourlocal.conffile is properly configured.$ cd ~ $ git clone git://git.yoctoproject.org/poky $ cd poky $ git checkout -b dora origin/dora $ source oe-init-build-env $ bitbake adt-installer
Before running the ADT Installer script, you need to unpack the tarball.
You can unpack the tarball in any directory you wish.
For example, this command copies the ADT Installer tarball from where
it was built into the home directory and then unpacks the tarball into
a top-level directory named adt-installer:
$ cd ~
$ cp poky/build/tmp/deploy/sdk/adt_installer.tar.bz2 $HOME
$ tar -xjf adt_installer.tar.bz2
Unpacking it creates the directory adt-installer,
which contains the ADT Installer script (adt_installer)
and its configuration file (adt_installer.conf).
Before you run the script, however, you should examine the ADT Installer configuration file and be sure you are going to get what you want. Your configurations determine which kernel and filesystem image are downloaded.
The following list describes the configurations you can define for the ADT Installer.
For configuration values and restrictions, see the comments in
the adt-installer.conf file:
YOCTOADT_REPO: This area includes the IPKG-based packages and the root filesystem upon which the installation is based. If you want to set up your own IPKG repository pointed to byYOCTOADT_REPO, you need to be sure that the directory structure follows the same layout as the reference directory set up at http://adtrepo.yoctoproject.org. Also, your repository needs to be accessible through HTTP.YOCTOADT_TARGETS: The machine target architectures for which you want to set up cross-development environments.YOCTOADT_QEMU: Indicates whether or not to install the emulator QEMU.YOCTOADT_NFS_UTIL: Indicates whether or not to install user-mode NFS. If you plan to use the Eclipse IDE Yocto plug-in against QEMU, you should install NFS.Note
To boot QEMU images using our userspace NFS server, you need to be runningportmaporrpcbind. If you are runningrpcbind, you will also need to add the-ioption whenrpcbindstarts up. Please make sure you understand the security implications of doing this. You might also have to modify your firewall settings to allow NFS booting to work.YOCTOADT_ROOTFS_<arch>: The root filesystem images you want to download from theYOCTOADT_IPKG_REPOrepository.YOCTOADT_TARGET_SYSROOT_IMAGE_<arch>: The particular root filesystem used to extract and create the target sysroot. The value of this variable must have been specified withYOCTOADT_ROOTFS_<arch>. For example, if you downloaded bothminimalandsato-sdkimages by settingYOCTOADT_ROOTFS_<arch>to "minimal sato-sdk", thenYOCTOADT_ROOTFS_<arch>must be set to eitherminimalorsato-sdk.YOCTOADT_TARGET_SYSROOT_LOC_<arch>: The location on the development host where the target sysroot is created.
After you have configured the adt_installer.conf file,
run the installer using the following command:
$ cd adt-installer
$ ./adt_installer
Once the installer begins to run, you are asked to enter the
location for cross-toolchain installation.
The default location is
/opt/poky/<release>.
After either accepting the default location or selecting your
own location, you are prompted to run the installation script
interactively or in silent mode.
If you want to closely monitor the installation,
choose “I” for interactive mode rather than “S” for silent mode.
Follow the prompts from the script to complete the installation.
Once the installation completes, the ADT, which includes the
cross-toolchain, is installed in the selected installation
directory.
You will notice environment setup files for the cross-toolchain
in the installation directory, and image tarballs in the
adt-installer directory according to your
installer configurations, and the target sysroot located
according to the
YOCTOADT_TARGET_SYSROOT_LOC_<arch>
variable also in your configuration file.
If you want to simply install a cross-toolchain by hand, you can
do so by running the toolchain installer.
The installer includes the pre-built cross-toolchain, the
runqemu script, and support files.
If you use this method to install the cross-toolchain, you
might still need to install the target sysroot by installing and
extracting it separately.
For information on how to install the sysroot, see the
"Extracting the Root Filesystem" section.
Follow these steps:
Get your toolchain installer using one of the following methods:
Go to http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/toolchain/ and find the folder that matches your host development system (i.e.
i686for 32-bit machines orx86_64for 64-bit machines).Go into that folder and download the toolchain installer whose name includes the appropriate target architecture. The toolchains provided by the Yocto Project are based off of the
core-image-satoimage and contain libraries appropriate for developing against that image. For example, if your host development system is a 64-bit x86 system and you are going to use your cross-toolchain for a 32-bit x86 target, go into thex86_64folder and download the following installer:poky-eglibc-x86_64-core-image-sato-i586-toolchain-1.5.2.shBuild your own toolchain installer. For cases where you cannot use an installer from the download area, you can build your own as described in the "Optionally Building a Toolchain Installer" section.
Once you have the installer, run it to install the toolchain.
Note
You must change the permissions on the toolchain installer script so that it is executable.The following command shows how to run the installer given a toolchain tarball for a 64-bit x86 development host system and a 32-bit x86 target architecture. The example assumes the toolchain installer is located in
~/Downloads/.$ ~/Downloads/poky-eglibc-x86_64-core-image-sato-i586-toolchain-1.5.2.shThe first thing the installer prompts you for is the directory into which you want to install the toolchain. The default directory used is
/opt/poky/1.5.2. If you do not have write permissions for the directory into which you are installing the toolchain, the toolchain installer notifies you and exits. Be sure you have write permissions in the directory and run the installer again.When the script finishes, the cross-toolchain is installed. You will notice environment setup files for the cross-toolchain in the installation directory.
A final way of making the cross-toolchain available is to use BitBake
to generate the toolchain within an existing
Build Directory.
This method does not install the toolchain into the default
/opt directory.
As with the previous method, if you need to install the target sysroot, you must
do that separately as well.
Follow these steps to generate the toolchain into the Build Directory:
Set up the Build Environment: Source the OpenEmbedded build environment setup script (i.e.
oe-init-build-envoroe-init-build-env-memres) located in the Source Directory.Check your Local Configuration File: At this point, you should be sure that the
MACHINEvariable in thelocal.conffile found in theconfdirectory of the Build Directory is set for the target architecture. Comments within thelocal.conffile list the values you can use for theMACHINEvariable.Note
You can populate the Build Directory with the cross-toolchains for more than a single architecture. You just need to edit theMACHINEvariable in thelocal.conffile and re-run the BitBake command.Generate the Cross-Toolchain: Run
bitbake meta-ide-supportto complete the cross-toolchain generation. Once the BitBake command finishes, the cross-toolchain is generated and populated within the Build Directory. You will notice environment setup files for the cross-toolchain that contain the string "environment-setup" in the Build Directory'stmpfolder.Be aware that when you use this method to install the toolchain, you still need to separately extract and install the sysroot filesystem. For information on how to do this, see the "Extracting the Root Filesystem" section.
Before you can develop using the cross-toolchain, you need to set up the
cross-development environment by sourcing the toolchain's environment setup script.
If you used the ADT Installer or hand-installed cross-toolchain,
then you can find this script in the directory you chose for installation.
The default installation directory is the /opt/poky/1.5.2
directory.
If you installed the toolchain in the
Build Directory,
you can find the environment setup
script for the toolchain in the Build Directory's tmp directory.
Be sure to run the environment setup script that matches the
architecture for which you are developing.
Environment setup scripts begin with the string
"environment-setup" and include as part of their
name the architecture.
For example, the toolchain environment setup script for a 64-bit
IA-based architecture installed in the default installation directory
would be the following:
/opt/poky/1.5.2/environment-setup-x86_64-poky-linux
You will need to have a kernel and filesystem image to boot using your hardware or the QEMU emulator. Furthermore, if you plan on booting your image using NFS or you want to use the root filesystem as the target sysroot, you need to extract the root filesystem.
To get the kernel and filesystem images, you either have to build them or download pre-built versions. You can find examples for both these situations in the "A Quick Test Run" section of the Yocto Project Quick Start.
The Yocto Project ships basic kernel and filesystem images for several
architectures (x86, x86-64,
mips, powerpc, and arm)
that you can use unaltered in the QEMU emulator.
These kernel images reside in the release
area - http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/machines
and are ideal for experimentation using Yocto Project.
For information on the image types you can build using the OpenEmbedded build system,
see the
"Images" chapter in
the Yocto Project Reference Manual.
If you are planning on developing against your image and you are not
building or using one of the Yocto Project development images
(e.g. core-image-*-dev), you must be sure to
include the development packages as part of your image recipe.
Furthermore, if you plan on remotely deploying and debugging your
application from within the
Eclipse IDE, you must have an image that contains the Yocto Target Communication
Framework (TCF) agent (tcf-agent).
By default, the Yocto Project provides only one type of pre-built
image that contains the tcf-agent.
And, those images are SDK (e.g.core-image-sato-sdk).
If you want to use a different image type that contains the tcf-agent,
you can do so one of two ways:
Modify the
conf/local.confconfiguration in the Build Directory and then rebuild the image. With this method, you need to modify theEXTRA_IMAGE_FEATURESvariable to have the value of "tools-debug" before rebuilding the image. Once the image is rebuilt, thetcf-agentwill be included in the image and is launched automatically after the boot.Manually build the
tcf-agent. To build the agent, follow these steps:Be sure the ADT is installed as described in the "Installing the ADT and Toolchains" section.
Set up the cross-development environment as described in the "Setting Up the Cross-Development Environment" section.
Get the
tcf-agentsource code using the following commands:$ git clone http://git.eclipse.org/gitroot/tcf/org.eclipse.tcf.agent.git $ cd org.eclipse.tcf.agent/agentLocate the
Makefile.incfile inside theagentfolder and modify it for the cross-compilation environment by setting theOPSYSandMACHINEvariables according to your target.Use the cross-development tools to build the
tcf-agent. Before you "Make" the file, be sure your cross-tools are set up first. See the "Makefile-Based Projects" section for information on how to make sure the cross-tools are set up correctly.If the build is successful, the
tcf-agentoutput will beobj/$(OPSYS)/$(MACHINE)/Debug/agent.Deploy the agent into the image's root filesystem.
If you install your toolchain by hand or build it using BitBake and you need a root filesystem, you need to extract it separately. If you use the ADT Installer to install the ADT, the root filesystem is automatically extracted and installed.
Here are some cases where you need to extract the root filesystem:
You want to boot the image using NFS.
You want to use the root filesystem as the target sysroot. For example, the Eclipse IDE environment with the Eclipse Yocto Plug-in installed allows you to use QEMU to boot under NFS.
You want to develop your target application using the root filesystem as the target sysroot.
To extract the root filesystem, first source
the cross-development environment setup script.
If you built the toolchain in the Build Directory, you will find
the toolchain environment script in the
tmp directory.
If you installed the toolchain by hand, the environment setup
script is located in /opt/poky/1.5.2.
After sourcing the environment script, use the
runqemu-extract-sdk command and provide the
filesystem image.
Following is an example.
The second command sets up the environment.
In this case, the setup script is located in the
/opt/poky/1.5.2 directory.
The third command extracts the root filesystem from a previously
built filesystem that is located in the
~/Downloads directory.
Furthermore, this command extracts the root filesystem into the
qemux86-sato directory:
$ cd ~
$ source /opt/poky/1.5.2/environment-setup-i586-poky-linux
$ runqemu-extract-sdk \
~/Downloads/core-image-sato-sdk-qemux86-2011091411831.rootfs.tar.bz2 \
$HOME/qemux86-sato
You could now point to the target sysroot at
qemux86-sato.
As an alternative to locating and downloading a toolchain installer, you can build the toolchain installer one of two ways if you have a Build Directory:
Use
bitbake meta-toolchain. This method requires you to still install the target sysroot by installing and extracting it separately. For information on how to install the sysroot, see the "Extracting the Root Filesystem" section.Use
bitbake image -c populate_sdk. This method has significant advantages over the previous method because it results in a toolchain installer that contains the sysroot that matches your target root filesystem.
Remember, before using any BitBake command, you
must source the build environment setup script
(i.e.
oe-init-build-env
or
oe-init-build-env-memres)
located in the Source Directory and you must make sure your
conf/local.conf variables are correct.
In particular, you need to be sure the
MACHINE
variable matches the architecture for which you are building and that
the
SDKMACHINE
variable is correctly set if you are building a toolchain designed to
run on an architecture that differs from your current development host
machine (i.e. the build machine).
When the BitBake command completes, the toolchain installer will be in
tmp/deploy/sdk in the Build Directory.
Note
By default, this toolchain does not build static binaries. If you want to use the toolchain to build these types of libraries, you need to be sure your image has the appropriate static development libraries. Use theIMAGE_INSTALL
variable inside your local.conf file to
install the appropriate library packages.
Following is an example using eglibc static
development libraries:
IMAGE_INSTALL_append = " eglibc-staticdev"
Because the Yocto Project is suited for embedded Linux development, it is likely that you will need to customize your development packages installation. For example, if you are developing a minimal image, then you might not need certain packages (e.g. graphics support packages). Thus, you would like to be able to remove those packages from your target sysroot.
The OpenEmbedded build system supports the generation of sysroot files using three different Package Management Systems (PMS):
OPKG: A less well known PMS whose use originated in the OpenEmbedded and OpenWrt embedded Linux projects. This PMS works with files packaged in an
.ipkformat. See http://en.wikipedia.org/wiki/Opkg for more information about OPKG.RPM: A more widely known PMS intended for GNU/Linux distributions. This PMS works with files packaged in an
.rmsformat. The build system currently installs through this PMS by default. See http://en.wikipedia.org/wiki/RPM_Package_Manager for more information about RPM.Debian: The PMS for Debian-based systems is built on many PMS tools. The lower-level PMS tool
dpkgforms the base of the Debian PMS. For information on dpkg see http://en.wikipedia.org/wiki/Dpkg.
Whichever PMS you are using, you need to be sure that the
PACKAGE_CLASSES
variable in the conf/local.conf
file is set to reflect that system.
The first value you choose for the variable specifies the package file format for the root
filesystem at sysroot.
Additional values specify additional formats for convenience or testing.
See the configuration file for details.
Note
For build performance information related to the PMS, see the "Packaging -package*.bbclass"
section in the Yocto Project Reference Manual.
As an example, consider a scenario where you are using OPKG and you want to add
the libglade package to the target sysroot.
First, you should generate the ipk file for the
libglade package and add it
into a working opkg repository.
Use these commands:
$ bitbake libglade
$ bitbake package-index
Next, source the environment setup script found in the
Source Directory.
Follow that by setting up the installation destination to point to your
sysroot as <sysroot_dir>.
Finally, have an OPKG configuration file <conf_file>
that corresponds to the opkg repository you have just created.
The following command forms should now work:
$ opkg-cl –f <conf_file> -o <sysroot_dir> update
$ opkg-cl –f <cconf_file> -o <sysroot_dir> \
--force-overwrite install libglade
$ opkg-cl –f <cconf_file> -o <sysroot_dir> \
--force-overwrite install libglade-dbg
$ opkg-cl –f <conf_file> -o <sysroot_dir> \
--force-overwrite install libglade-dev
Recall that earlier the manual discussed how to use an existing toolchain
tarball that had been installed into the default installation
directory, /opt/poky/1.5.2, which is outside of the
Build Directory
(see the section "Using a Cross-Toolchain Tarball)".
And, that sourcing your architecture-specific environment setup script
initializes a suitable cross-toolchain development environment.
During this setup, locations for the compiler, QEMU scripts, QEMU binary,
a special version of pkgconfig and other useful
utilities are added to the PATH variable.
Also, variables to assist
pkgconfig and autotools
are also defined so that, for example, configure.sh
can find pre-generated test results for tests that need target hardware
on which to run.
Collectively, these conditions allow you to easily use the toolchain outside of the OpenEmbedded build environment on both autotools-based projects and Makefile-based projects. This chapter provides information for both these types of projects.
Once you have a suitable cross-toolchain installed, it is very easy to develop a project outside of the OpenEmbedded build system. This section presents a simple "Helloworld" example that shows how to set up, compile, and run the project.
Follow these steps to create a simple autotools-based project:
Create your directory: Create a clean directory for your project and then make that directory your working location:
$ mkdir $HOME/helloworld $ cd $HOME/helloworldPopulate the directory: Create
hello.c,Makefile.am, andconfigure.infiles as follows:For
hello.c, include these lines:#include <stdio.h> main() { printf("Hello World!\n"); }For
Makefile.am, include these lines:bin_PROGRAMS = hello hello_SOURCES = hello.cFor
configure.in, include these lines:AC_INIT(hello.c) AM_INIT_AUTOMAKE(hello,0.1) AC_PROG_CC AC_PROG_INSTALL AC_OUTPUT(Makefile)
Source the cross-toolchain environment setup file: Installation of the cross-toolchain creates a cross-toolchain environment setup script in the directory that the ADT was installed. Before you can use the tools to develop your project, you must source this setup script. The script begins with the string "environment-setup" and contains the machine architecture, which is followed by the string "poky-linux". Here is an example that sources a script from the default ADT installation directory that uses the 32-bit Intel x86 Architecture and using the dora Yocto Project release:
$ source /opt/poky/1.5.2/environment-setup-i586-poky-linuxGenerate the local aclocal.m4 files and create the configure script: The following GNU Autotools generate the local
aclocal.m4files and create the configure script:$ aclocal $ autoconfGenerate files needed by GNU coding standards: GNU coding standards require certain files in order for the project to be compliant. This command creates those files:
$ touch NEWS README AUTHORS ChangeLogGenerate the configure file: This command generates the
configure:$ automake -aCross-compile the project: This command compiles the project using the cross-compiler:
$ ./configure ${CONFIGURE_FLAGS}Make and install the project: These two commands generate and install the project into the destination directory:
$ make $ make install DESTDIR=./tmpVerify the installation: This command is a simple way to verify the installation of your project. Running the command prints the architecture on which the binary file can run. This architecture should be the same architecture that the installed cross-toolchain supports.
$ file ./tmp/usr/local/bin/helloExecute your project: To execute the project in the shell, simply enter the name. You could also copy the binary to the actual target hardware and run the project there as well:
$ ./helloAs expected, the project displays the "Hello World!" message.
For an Autotools-based project, you can use the cross-toolchain by just
passing the appropriate host option to configure.sh.
The host option you use is derived from the name of the environment setup
script found in the directory in which you installed the cross-toolchain.
For example, the host option for an ARM-based target that uses the GNU EABI
is armv5te-poky-linux-gnueabi.
You will notice that the name of the script is
environment-setup-armv5te-poky-linux-gnueabi.
Thus, the following command works:
$ ./configure --host=armv5te-poky-linux-gnueabi \
--with-libtool-sysroot=<sysroot-dir>
This single command updates your project and rebuilds it using the appropriate cross-toolchain tools.
Note
Ifconfigure script results in problems recognizing the
--with-libtool-sysroot=<sysroot-dir> option,
regenerate the script to enable the support by doing the following and then
run the script again:
$ libtoolize --automake
$ aclocal -I ${OECORE_NATIVE_SYSROOT}/usr/share/aclocal \
[-I <dir_containing_your_project-specific_m4_macros>]
$ autoconf
$ autoheader
$ automake -a
 |
Copyright © 2010-2014 Linux Foundation
Permission is granted to copy, distribute and/or modify this document under the terms of the Creative Commons Attribution-Non-Commercial-Share Alike 2.0 UK: England & Wales as published by Creative Commons.
Note
For the latest version of this manual associated with this Yocto Project release, see the Yocto Project Board Support Package (BSP) Developer's Guide from the Yocto Project website.| Revision History | |
|---|---|
| Revision 0.9 | 24 November 2010 |
| The initial document draft released with the Yocto Project 0.9 Release. | |
| Revision 1.0 | 6 April 2011 |
| Released with the Yocto Project 1.0 Release. | |
| Revision 1.0.1 | 23 May 2011 |
| Released with the Yocto Project 1.0.1 Release. | |
| Revision 1.1 | 6 October 2011 |
| Released with the Yocto Project 1.1 Release. | |
| Revision 1.2 | April 2012 |
| Released with the Yocto Project 1.2 Release. | |
| Revision 1.3 | October 2012 |
| Released with the Yocto Project 1.3 Release. | |
| Revision 1.4 | April 2013 |
| Released with the Yocto Project 1.4 Release. | |
| Revision 1.5 | October 2013 |
| Released with the Yocto Project 1.5 Release. | |
| Revision 1.5.1 | January 2014 |
| Released with the Yocto Project 1.5.1 Release. | |
| Revision 1.5.2 | May 2014 |
| Released with the Yocto Project 1.5.2 Release. | |
A Board Support Package (BSP) is a collection of information that defines how to support a particular hardware device, set of devices, or hardware platform. The BSP includes information about the hardware features present on the device and kernel configuration information along with any additional hardware drivers required. The BSP also lists any additional software components required in addition to a generic Linux software stack for both essential and optional platform features.
This guide presents information about BSP Layers, defines a structure for components so that BSPs follow a commonly understood layout, discusses how to customize a recipe for a BSP, addresses BSP licensing, and provides information that shows you how to create and manage a BSP Layer using two Yocto Project BSP Tools.
The BSP consists of a file structure inside a base directory. Collectively, you can think of the base directory and the file structure as a BSP Layer. Although not a strict requirement, layers in the Yocto Project use the following well established naming convention:
meta-<bsp_name>
The string "meta-" is prepended to the machine or platform name, which is "bsp_name" in the above form.
The layer's base directory (meta-<bsp_name>) is the root
of the BSP Layer.
This root is what you add to the
BBLAYERS
variable in the conf/bblayers.conf file found in the
Build Directory.
Adding the root allows the OpenEmbedded build system to recognize the BSP
definition and from it build an image.
Here is an example:
BBLAYERS ?= " \
/usr/local/src/yocto/meta \
/usr/local/src/yocto/meta-yocto \
/usr/local/src/yocto/meta-yocto-bsp \
/usr/local/src/yocto/meta-mylayer \
"
BBLAYERS_NON_REMOVABLE ?= " \
/usr/local/src/yocto/meta \
/usr/local/src/yocto/meta-yocto \
"
Some BSPs require additional layers on
top of the BSP's root layer in order to be functional.
For these cases, you also need to add those layers to the
BBLAYERS variable in order to build the BSP.
You must also specify in the "Dependencies" section of the BSP's
README file any requirements for additional
layers and, preferably, any
build instructions that might be contained elsewhere
in the README file.
Some layers function as a layer to hold other BSP layers.
An example of this type of layer is the meta-intel layer.
The meta-intel layer contains over 10 individual BSP layers.
For more detailed information on layers, see the "Understanding and Creating Layers" section of the Yocto Project Development Manual.
Providing a common form allows end-users to understand and become familiar with the layout. A common format also encourages standardization of software support of hardware.
The proposed form does have elements that are specific to the OpenEmbedded build system. It is intended that this information can be used by other build systems besides the OpenEmbedded build system and that it will be simple to extract information and convert it to other formats if required. The OpenEmbedded build system, through its standard layers mechanism, can directly accept the format described as a layer. The BSP captures all the hardware-specific details in one place in a standard format, which is useful for any person wishing to use the hardware platform regardless of the build system they are using.
The BSP specification does not include a build system or other tools - it is concerned with the hardware-specific components only. At the end-distribution point, you can ship the BSP combined with a build system and other tools. However, it is important to maintain the distinction that these are separate components that happen to be combined in certain end products.
Before looking at the common form for the file structure inside a BSP Layer, you should be aware that some requirements do exist in order for a BSP to be considered compliant with the Yocto Project. For that list of requirements, see the "Released BSP Requirements" section.
Below is the common form for the file structure inside a BSP Layer. While you can use this basic form for the standard, realize that the actual structures for specific BSPs could differ.
meta-<bsp_name>/
meta-<bsp_name>/<bsp_license_file>
meta-<bsp_name>/README
meta-<bsp_name>/README.sources
meta-<bsp_name>/binary/<bootable_images>
meta-<bsp_name>/conf/layer.conf
meta-<bsp_name>/conf/machine/*.conf
meta-<bsp_name>/recipes-bsp/*
meta-<bsp_name>/recipes-core/*
meta-<bsp_name>/recipes-graphics/*
meta-<bsp_name>/recipes-kernel/linux/linux-yocto_<kernel_rev>.bbappend
Below is an example of the Crown Bay BSP:
meta-crownbay/COPYING.MIT
meta-crownbay/README
meta-crownbay/README.sources
meta-crownbay/binary/
meta-crownbay/conf/
meta-crownbay/conf/layer.conf
meta-crownbay/conf/machine/
meta-crownbay/conf/machine/crownbay.conf
meta-crownbay/conf/machine/crownbay-noemgd.conf
meta-crownbay/recipes-bsp/
meta-crownbay/recipes-bsp/formfactor/
meta-crownbay/recipes-bsp/formfactor/formfactor_0.0.bbappend
meta-crownbay/recipes-bsp/formfactor/formfactor/
meta-crownbay/recipes-bsp/formfactor/formfactor/crownbay/
meta-crownbay/recipes-bsp/formfactor/formfactor/crownbay/machconfig
meta-crownbay/recipes-bsp/formfactor/formfactor/crownbay-noemgd/
meta-crownbay/recipes-bsp/formfactor/formfactor/crownbay-noemgd/machconfig
meta-crownbay/recipes-graphics/
meta-crownbay/recipes-graphics/xorg-xserver/
meta-crownbay/recipes-graphics/xorg-xserver/xserver-xf86-config_0.1.bbappend
meta-crownbay/recipes-graphics/xorg-xserver/xserver-xf86-config/
meta-crownbay/recipes-graphics/xorg-xserver/xserver-xf86-config/crownbay/
meta-crownbay/recipes-graphics/xorg-xserver/xserver-xf86-config/crownbay/xorg.conf
meta-crownbay/recipes-kernel/
meta-crownbay/recipes-kernel/linux/
meta-crownbay/recipes-kernel/linux/linux-yocto_3.4.bbappend
meta-crownbay/recipes-kernel/linux/linux-yocto_3.8.bbappend
meta-crownbay/recipes-kernel/linux/linux-yocto_3.10.bbappend
meta-crownbay/recipes-kernel/linux/linux-yocto-dev.bbappend
meta-crownbay/recipes-kernel/linux/linux-yocto-rt_3.4.bbappend
meta-crownbay/recipes-kernel/linux/linux-yocto-rt_3.8.bbappend
meta-crownbay/recipes-kernel/linux/linux-yocto-rt_3.10.bbappend
The following sections describe each part of the proposed BSP format.
You can find these files in the BSP Layer at:
meta-<bsp_name>/<bsp_license_file>
These optional files satisfy licensing requirements for the BSP.
The type or types of files here can vary depending on the licensing requirements.
For example, in the Crown Bay BSP all licensing requirements are handled with the
COPYING.MIT file.
Licensing files can be MIT, BSD, GPLv*, and so forth. These files are recommended for the BSP but are optional and totally up to the BSP developer.
You can find this file in the BSP Layer at:
meta-<bsp_name>/README
This file provides information on how to boot the live images that are optionally
included in the binary/ directory.
The README file also provides special information needed for
building the image.
At a minimum, the README file must
contain a list of dependencies, such as the names of
any other layers on which the BSP depends and the name of
the BSP maintainer with his or her contact information.
You can find this file in the BSP Layer at:
meta-<bsp_name>/README.sources
This file provides information on where to locate the BSP source files. For example, information provides where to find the sources that comprise the images shipped with the BSP. Information is also included to help you find the Metadata used to generate the images that ship with the BSP.
You can find these files in the BSP Layer at:
meta-<bsp_name>/binary/<bootable_images>
This optional area contains useful pre-built kernels and user-space filesystem images appropriate to the target system. This directory typically contains graphical (e.g. Sato) and minimal live images when the BSP tarball has been created and made available in the Yocto Project website. You can use these kernels and images to get a system running and quickly get started on development tasks.
The exact types of binaries present are highly hardware-dependent. However, a README file should be present in the BSP Layer that explains how to use the kernels and images with the target hardware. If pre-built binaries are present, source code to meet licensing requirements must also exist in some form.
You can find this file in the BSP Layer at:
meta-<bsp_name>/conf/layer.conf
The conf/layer.conf file identifies the file structure as a
layer, identifies the
contents of the layer, and contains information about how the build
system should use it.
Generally, a standard boilerplate file such as the following works.
In the following example, you would replace "bsp" and
"_bsp" with the actual name
of the BSP (i.e. <bsp_name> from the example template).
# We have a conf and classes directory, add to BBPATH
BBPATH .= ":${LAYERDIR}"
# We have a recipes directory, add to BBFILES
BBFILES += "${LAYERDIR}/recipes-*/*/*.bb \
${LAYERDIR}/recipes-*/*/*.bbappend"
BBFILE_COLLECTIONS += "bsp"
BBFILE_PATTERN_bsp = "^${LAYERDIR}/"
BBFILE_PRIORITY_bsp = "6"
To illustrate the string substitutions, here are the corresponding statements
from the Crown Bay conf/layer.conf file:
BBFILE_COLLECTIONS += "crownbay"
BBFILE_PATTERN_crownbay = "^${LAYERDIR}/"
BBFILE_PRIORITY_crownbay = "6"
This file simply makes BitBake aware of the recipes and configuration directories. The file must exist so that the OpenEmbedded build system can recognize the BSP.
You can find these files in the BSP Layer at:
meta-<bsp_name>/conf/machine/*.conf
The machine files bind together all the information contained elsewhere
in the BSP into a format that the build system can understand.
If the BSP supports multiple machines, multiple machine configuration files
can be present.
These filenames correspond to the values to which users have set the
MACHINE variable.
These files define things such as the kernel package to use
(PREFERRED_PROVIDER
of virtual/kernel), the hardware drivers to
include in different types of images, any special software components
that are needed, any bootloader information, and also any special image
format requirements.
Each BSP Layer requires at least one machine file. However, you can supply more than one file.
This crownbay.conf file could also include
a hardware "tuning" file that is commonly used to
define the package architecture and specify
optimization flags, which are carefully chosen to give best
performance on a given processor.
Tuning files are found in the meta/conf/machine/include
directory within the
Source Directory.
For example, the ia32-base.inc file resides in the
meta/conf/machine/include directory.
To use an include file, you simply include them in the machine configuration file.
For example, the Crown Bay BSP crownbay.conf contains the
following statements:
require conf/machine/include/tune-atom.inc
require conf/machine/include/ia32-base.inc
require conf/machine/include/meta-intel.inc
require conf/machine/include/meta-intel-emgd.inc
You can find these files in the BSP Layer at:
meta-<bsp_name>/recipes-bsp/*
This optional directory contains miscellaneous recipe files for the BSP.
Most notably would be the formfactor files.
For example, in the Crown Bay BSP there is the
formfactor_0.0.bbappend file, which is an
append file used to augment the recipe that starts the build.
Furthermore, there are machine-specific settings used during the
build that are defined by the machconfig file.
In the Crown Bay example, two machconfig files
exist: one that supports the Intel® Embedded Media and Graphics
Driver (Intel® EMGD) and one that does not:
meta-crownbay/recipes-bsp/formfactor/formfactor/crownbay/machconfig
meta-crownbay/recipes-bsp/formfactor/formfactor/crownbay-noemgd/machconfig
meta-crownbay/recipes-bsp/formfactor/formfactor_0.0.bbappend
Note
If a BSP does not have a formfactor entry, defaults are established according to
the formfactor configuration file that is installed by the main
formfactor recipe
meta/recipes-bsp/formfactor/formfactor_0.0.bb,
which is found in the
Source Directory.
You can find these files in the BSP Layer at:
meta-<bsp_name>/recipes-graphics/*
This optional directory contains recipes for the BSP if it has
special requirements for graphics support.
All files that are needed for the BSP to support a display are kept here.
For example, the Crown Bay BSP's xorg.conf file
detects the graphics support needed (i.e. the Intel® Embedded Media
Graphics Driver (EMGD) or the Video Electronics Standards Association
(VESA) graphics):
meta-crownbay/recipes-graphics/xorg-xserver/xserver-xf86-config_0.1.bbappend
meta-crownbay/recipes-graphics/xorg-xserver/xserver-xf86-config/crownbay/xorg.conf
You can find these files in the BSP Layer at:
meta-<bsp_name>/recipes-kernel/linux/linux-yocto_*.bbappend
These files append your specific changes to the main kernel recipe you are using.
For your BSP, you typically want to use an existing Yocto Project kernel recipe found in the
Source Directory
at meta/recipes-kernel/linux.
You can append your specific changes to the kernel recipe by using a
similarly named append file, which is located in the BSP Layer (e.g.
the meta-<bsp_name>/recipes-kernel/linux directory).
Suppose you are using the linux-yocto_3.10.bb recipe to build
the kernel.
In other words, you have selected the kernel in your
<bsp_name>.conf file by adding these types
of statements:
PREFERRED_PROVIDER_virtual/kernel ?= "linux-yocto"
PREFERRED_VERSION_linux-yocto ?= "3.10%"
Note
When the preferred provider is assumed by default, thePREFERRED_PROVIDER statement does not appear in the
<bsp_name>.conf file.
You would use the linux-yocto_3.10.bbappend file to append
specific BSP settings to the kernel, thus configuring the kernel for your particular BSP.
As an example, look at the existing Crown Bay BSP. The append file used is:
meta-crownbay/recipes-kernel/linux/linux-yocto_3.10.bbappend
The following listing shows the file.
Be aware that the actual commit ID strings in this example listing might be different
than the actual strings in the file from the meta-intel
Git source repository.
FILESEXTRAPATHS_prepend := "${THISDIR}/${PN}:"
COMPATIBLE_MACHINE_crownbay-noemgd = "crownbay-noemgd"
KMACHINE_crownbay-noemgd = "crownbay"
KBRANCH_crownbay-noemgd = "standard/crownbay"
KERNEL_FEATURES_append_crownbay-noemgd = " cfg/vesafb"
LINUX_VERSION = "3.10.11"
SRCREV_meta_crownbay-noemgd = "285f93bf942e8f6fa678ffc6cc53696ed5400718"
SRCREV_machine_crownbay-noemgd = "702040ac7c7ec66a29b4d147665ccdd0ff015577"
This append file contains statements used to support the Crown Bay BSP.
The file defines crownbay as the
COMPATIBLE_MACHINE
and uses the
KMACHINE variable to
ensure the machine name used by the OpenEmbedded build system maps to the
machine name used by the Linux Yocto kernel.
The file also uses the optional
KBRANCH variable
to ensure the build process uses the standard/crownbay
kernel branch.
The
KERNEL_FEATURES
variable enables features specific to the kernel.
Finally, the append file points to specific commits in the
Source Directory Git
repository and the meta Git repository branches to identify the
exact kernel needed to build the Crown Bay BSP.
One thing missing in this particular BSP, which you will typically need when
developing a BSP, is the kernel configuration file (.config) for your BSP.
When developing a BSP, you probably have a kernel configuration file or a set of kernel
configuration files that, when taken together, define the kernel configuration for your BSP.
You can accomplish this definition by putting the configurations in a file or a set of files
inside a directory located at the same level as your kernel's append file and having the same
name as the kernel's main recipe file.
With all these conditions met, simply reference those files in a
SRC_URI statement in the append file.
For example, suppose you had some configuration options in a file called
network_configs.cfg.
You can place that file inside a directory named linux-yocto and then add
a SRC_URI statement such as the following to the append file.
When the OpenEmbedded build system builds the kernel, the configuration options are
picked up and applied.
SRC_URI += "file://network_configs.cfg"
To group related configurations into multiple files, you perform a similar procedure.
Here is an example that groups separate configurations specifically for Ethernet and graphics
into their own files and adds the configurations
by using a SRC_URI statement like the following in your append file:
SRC_URI += "file://myconfig.cfg \
file://eth.cfg \
file://gfx.cfg"
The FILESEXTRAPATHS
variable is in boilerplate form in the
previous example in order to make it easy to do that.
This variable must be in your layer or BitBake will not find the patches or
configurations even if you have them in your SRC_URI.
The FILESEXTRAPATHS variable enables the build process to
find those configuration files.
Note
Other methods exist to accomplish grouping and defining configuration options.
For example, if you are working with a local clone of the kernel repository,
you could checkout the kernel's meta branch, make your changes,
and then push the changes to the local bare clone of the kernel.
The result is that you directly add configuration options to the
meta branch for your BSP.
The configuration options will likely end up in that location anyway if the BSP gets
added to the Yocto Project.
In general, however, the Yocto Project maintainers take care of moving the
SRC_URI-specified
configuration options to the kernel's meta branch.
Not only is it easier for BSP developers to not have to worry about putting those
configurations in the branch, but having the maintainers do it allows them to apply
'global' knowledge about the kinds of common configuration options multiple BSPs in
the tree are typically using.
This allows for promotion of common configurations into common features.
Certain requirements exist for a released BSP to be considered compliant with the Yocto Project. Additionally, recommendations also exist. This section describes the requirements and recommendations for released BSPs.
Before looking at BSP requirements, you should consider the following:
The requirements here assume the BSP layer is a well-formed, "legal" layer that can be added to the Yocto Project. For guidelines on creating a layer that meets these base requirements, see the "BSP Layers" and the "Understanding and Creating Layers" in the Yocto Project Development Manual.
The requirements in this section apply regardless of how you ultimately package a BSP. You should consult the packaging and distribution guidelines for your specific release process. For an example of packaging and distribution requirements, see the "Third Party BSP Release Process" wiki page.
The requirements for the BSP as it is made available to a developer are completely independent of the released form of the BSP. For example, the BSP Metadata can be contained within a Git repository and could have a directory structure completely different from what appears in the officially released BSP layer.
It is not required that specific packages or package modifications exist in the BSP layer, beyond the requirements for general compliance with the Yocto Project. For example, no requirement exists dictating that a specific kernel or kernel version be used in a given BSP.
Following are the requirements for a released BSP that conforms to the Yocto Project:
Layer Name: The BSP must have a layer name that follows the Yocto Project standards. For information on BSP layer names, see the "BSP Layers" section.
File System Layout: When possible, use the same directory names in your BSP layer as listed in the
recipes.txtfile. In particular, you should place recipes (.bbfiles) and recipe modifications (.bbappendfiles) intorecipes-*subdirectories by functional area as outlined inrecipes.txt. If you cannot find a category inrecipes.txtto fit a particular recipe, you can make up your ownrecipes-*subdirectory. You can findrecipes.txtin themetadirectory of the Source Directory, or in the OpenEmbedded Core Layer (openembedded-core) found at http://git.openembedded.org/openembedded-core/tree/meta.Within any particular
recipes-*category, the layout should match what is found in the OpenEmbedded Core Git repository (openembedded-core) or the Source Directory (poky). In other words, make sure you place related files in appropriately relatedrecipes-*subdirectories specific to the recipe's function, or within a subdirectory containing a set of closely-related recipes. The recipes themselves should follow the general guidelines for recipes used in the Yocto Project found in the "Yocto Recipe and Patch Style Guide".License File: You must include a license file in the
meta-<bsp_name>directory. This license covers the BSP Metadata as a whole. You must specify which license to use since there is no default license if one is not specified. See theCOPYING.MITfile for the Fish River Island 2 BSP in themeta-fri2BSP layer as an example.README File: You must include a
READMEfile in themeta-<bsp_name>directory. See theREADMEfile for the Fish River Island 2 BSP in themeta-fri2BSP layer as an example.At a minimum, the
READMEfile should contain the following:A brief description about the hardware the BSP targets.
A list of all the dependencies on which a BSP layer depends. These dependencies are typically a list of required layers needed to build the BSP. However, the dependencies should also contain information regarding any other dependencies the BSP might have.
Any required special licensing information. For example, this information includes information on special variables needed to satisfy a EULA, or instructions on information needed to build or distribute binaries built from the BSP Metadata.
The name and contact information for the BSP layer maintainer. This is the person to whom patches and questions should be sent. For information on how to find the right person, see the "How to Submit a Change" section in the Yocto Project Development Manual.
Instructions on how to build the BSP using the BSP layer.
Instructions on how to boot the BSP build from the BSP layer.
Instructions on how to boot the binary images contained in the
binarydirectory, if present.Information on any known bugs or issues that users should know about when either building or booting the BSP binaries.
README.sources File: You must include a
README.sourcesin themeta-<bsp_name>directory. This file specifies exactly where you can find the sources used to generate the binary images contained in thebinarydirectory, if present. See theREADME.sourcesfile for the Fish River Island 2 BSP in themeta-fri2BSP layer as an example.Layer Configuration File: You must include a
conf/layer.confin themeta-<bsp_name>directory. This file identifies themeta-<bsp_name>BSP layer as a layer to the build system.Machine Configuration File: You must include one or more
conf/machine/<bsp_name>.conffiles in themeta-<bsp_name>directory. These configuration files define machine targets that can be built using the BSP layer. Multiple machine configuration files define variations of machine configurations that are supported by the BSP. If a BSP supports multiple machine variations, you need to adequately describe each variation in the BSPREADMEfile. Do not use multiple machine configuration files to describe disparate hardware. If you do have very different targets, you should create separate BSP layers for each target.Note
It is completely possible for a developer to structure the working repository as a conglomeration of unrelated BSP files, and to possibly generate BSPs targeted for release from that directory using scripts or some other mechanism (e.g.meta-yocto-bsplayer). Such considerations are outside the scope of this document.
Following are recommendations for a released BSP that conforms to the Yocto Project:
Bootable Images: BSP releases can contain one or more bootable images. Including bootable images allows users to easily try out the BSP on their own hardware.
In some cases, it might not be convenient to include a bootable image. In this case, you might want to make two versions of the BSP available: one that contains binary images, and one that does not. The version that does not contain bootable images avoids unnecessary download times for users not interested in the images.
If you need to distribute a BSP and include bootable images or build kernel and filesystems meant to allow users to boot the BSP for evaluation purposes, you should put the images and artifacts within a
binary/subdirectory located in themeta-<bsp_name>directory.Note
If you do include a bootable image as part of the BSP and the image was built by software covered by the GPL or other open source licenses, it is your responsibility to understand and meet all licensing requirements, which could include distribution of source files.Use a Yocto Linux Kernel: Kernel recipes in the BSP should be based on a Yocto Linux kernel. Basing your recipes on these kernels reduces the costs for maintaining the BSP and increases its scalability. See the
Yocto Linux Kernelcategory in the Source Repositories for these kernels.
If you plan on customizing a recipe for a particular BSP, you need to do the following:
Create a
.bbappendfile for the modified recipe. For information on using append files, see the "Using .bbappend Files" section in the Yocto Project Development Manual.Ensure your directory structure in the BSP layer that supports your machine is such that it can be found by the build system. See the example later in this section for more information.
Put the append file in a directory whose name matches the machine's name and is located in an appropriate sub-directory inside the BSP layer (i.e.
recipes-bsp,recipes-graphics,recipes-core, and so forth).Place the BSP-specific files in the directory named for your machine inside the BSP layer.
Following is a specific example to help you better understand the process.
Consider an example that customizes a recipe by adding
a BSP-specific configuration file named interfaces to the
init-ifupdown_1.0.bb recipe for machine "xyz".
Do the following:
Edit the
init-ifupdown_1.0.bbappendfile so that it contains the following:FILESEXTRAPATHS_prepend := "${THISDIR}/files:" PRINC := "${@int(PRINC) + 2}"The append file needs to be in the
meta-xyz/recipes-core/init-ifupdowndirectory.Create and place the new
interfacesconfiguration file in the BSP's layer here:meta-xyz/recipes-core/init-ifupdown/files/xyz/interfacesThe
FILESEXTRAPATHSvariable in the append files extends the search path the build system uses to find files during the build. Consequently, for this example you need to have thefilesdirectory in the same location as your append file.
In some cases, a BSP contains separately licensed Intellectual Property (IP) for a component or components. For these cases, you are required to accept the terms of a commercial or other type of license that requires some kind of explicit End User License Agreement (EULA). Once the license is accepted, the OpenEmbedded build system can then build and include the corresponding component in the final BSP image. If the BSP is available as a pre-built image, you can download the image after agreeing to the license or EULA.
You could find that some separately licensed components that are essential for normal operation of the system might not have an unencumbered (or free) substitute. Without these essential components, the system would be non-functional. Then again, you might find that other licensed components that are simply 'good-to-have' or purely elective do have an unencumbered, free replacement component that you can use rather than agreeing to the separately licensed component. Even for components essential to the system, you might find an unencumbered component that is not identical but will work as a less-capable version of the licensed version in the BSP recipe.
For cases where you can substitute a free component and still maintain the system's functionality, the "Downloads" page from the Yocto Project website's makes available de-featured BSPs that are completely free of any IP encumbrances. For these cases, you can use the substitution directly and without any further licensing requirements. If present, these fully de-featured BSPs are named appropriately different as compared to the names of the respective encumbered BSPs. If available, these substitutions are your simplest and most preferred options. Use of these substitutions of course assumes the resulting functionality meets system requirements.
If however, a non-encumbered version is unavailable or it provides unsuitable functionality or quality, you can use an encumbered version.
A couple different methods exist within the OpenEmbedded build system to satisfy the licensing requirements for an encumbered BSP. The following list describes them in order of preference:
Use the
LICENSE_FLAGSvariable to define the recipes that have commercial or other types of specially-licensed packages: For each of those recipes, you can specify a matching license string in alocal.confvariable namedLICENSE_FLAGS_WHITELIST. Specifying the matching license string signifies that you agree to the license. Thus, the build system can build the corresponding recipe and include the component in the image. See the "Enabling Commercially Licensed Recipes" section in the Yocto Project Reference Manual for details on how to use these variables.If you build as you normally would, without specifying any recipes in the
LICENSE_FLAGS_WHITELIST, the build stops and provides you with the list of recipes that you have tried to include in the image that need entries in theLICENSE_FLAGS_WHITELIST. Once you enter the appropriate license flags into the whitelist, restart the build to continue where it left off. During the build, the prompt will not appear again since you have satisfied the requirement.Once the appropriate license flags are on the white list in the
LICENSE_FLAGS_WHITELISTvariable, you can build the encumbered image with no change at all to the normal build process.Get a pre-built version of the BSP: You can get this type of BSP by visiting the "Downloads" page of the Yocto Project website. You can download BSP tarballs that contain proprietary components after agreeing to the licensing requirements of each of the individually encumbered packages as part of the download process. Obtaining the BSP this way allows you to access an encumbered image immediately after agreeing to the click-through license agreements presented by the website. Note that if you want to build the image yourself using the recipes contained within the BSP tarball, you will still need to create an appropriate
LICENSE_FLAGS_WHITELISTto match the encumbered recipes in the BSP.
Note
Pre-compiled images are bundled with a time-limited kernel that runs for a predetermined amount of time (10 days) before it forces the system to reboot. This limitation is meant to discourage direct redistribution of the image. You must eventually rebuild the image if you want to remove this restriction.
The Yocto Project includes a couple of tools that enable
you to create a BSP layer
from scratch and do basic configuration and maintenance
of the kernel without ever looking at a Metadata file.
These tools are yocto-bsp and yocto-kernel,
respectively.
The following sections describe the common location and help features as well
as provide details for the
yocto-bsp and yocto-kernel tools.
Designed to have a command interface somewhat like
Git, each
tool is structured as a set of sub-commands under a
top-level command.
The top-level command (yocto-bsp
or yocto-kernel) itself does
nothing but invoke or provide help on the sub-commands
it supports.
Both tools reside in the scripts/ subdirectory
of the Source Directory.
Consequently, to use the scripts, you must source the
environment just as you would when invoking a build:
$ source oe-init-build-env [build_dir]
The most immediately useful function is to get help on both tools.
The built-in help system makes it easy to drill down at
any time and view the syntax required for any specific command.
Simply enter the name of the command with the help
switch:
$ yocto-bsp help
Usage:
Create a customized Yocto BSP layer.
usage: yocto-bsp [--version] [--help] COMMAND [ARGS]
Current 'yocto-bsp' commands are:
create Create a new Yocto BSP
list List available values for options and BSP properties
See 'yocto-bsp help COMMAND' for more information on a specific command.
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-D, --debug output debug information
Similarly, entering just the name of a sub-command shows the detailed usage for that sub-command:
$ yocto-bsp create
Usage:
Create a new Yocto BSP
usage: yocto-bsp create <bsp-name> <karch> [-o <DIRNAME> | --outdir <DIRNAME>]
[-i <JSON PROPERTY FILE> | --infile <JSON PROPERTY_FILE>]
This command creates a Yocto BSP based on the specified parameters.
The new BSP will be a new Yocto BSP layer contained by default within
the top-level directory specified as 'meta-bsp-name'. The -o option
can be used to place the BSP layer in a directory with a different
name and location.
...
For any sub-command, you can use the word "help" option just before the sub-command to get more extensive documentation:
$ yocto-bsp help create
NAME
yocto-bsp create - Create a new Yocto BSP
SYNOPSIS
yocto-bsp create <bsp-name> <karch> [-o <DIRNAME> | --outdir <DIRNAME>]
[-i <JSON PROPERTY FILE> | --infile <JSON PROPERTY_FILE>]
DESCRIPTION
This command creates a Yocto BSP based on the specified
parameters. The new BSP will be a new Yocto BSP layer contained
by default within the top-level directory specified as
'meta-bsp-name'. The -o option can be used to place the BSP layer
in a directory with a different name and location.
The value of the 'karch' parameter determines the set of files
that will be generated for the BSP, along with the specific set of
'properties' that will be used to fill out the BSP-specific
portions of the BSP. The possible values for the 'karch' parameter
can be listed via 'yocto-bsp list karch'.
...
Now that you know where these two commands reside and how to access information on them, you should find it relatively straightforward to discover the commands necessary to create a BSP and perform basic kernel maintenance on that BSP using the tools.
Note
You can also use theyocto-layer tool to create
a "generic" layer.
For information on this tool, see the
"Creating a General Layer Using the yocto-layer Script"
section in the Yocto Project Development Guide.
The next sections provide a concrete starting point to expand on a few points that might not be immediately obvious or that could use further explanation.
The yocto-bsp script creates a new
BSP layer for any architecture supported
by the Yocto Project, as well as QEMU versions of the same.
The default mode of the script's operation is to prompt you for information needed
to generate the BSP layer.
For the current set of BSPs, the script prompts you for various important parameters such as:
The kernel to use
The branch of that kernel to use (or re-use)
Whether or not to use X, and if so, which drivers to use
Whether to turn on SMP
Whether the BSP has a keyboard
Whether the BSP has a touchscreen
Remaining configurable items associated with the BSP
You use the yocto-bsp create sub-command to create
a new BSP layer.
This command requires you to specify a particular kernel architecture
(karch) on which to base the BSP.
Assuming you have sourced the environment, you can use the
yocto-bsp list karch sub-command to list the
architectures available for BSP creation as follows:
$ yocto-bsp list karch
Architectures available:
powerpc
i386
x86_64
arm
qemu
mips
The remainder of this section presents an example that uses
myarm as the machine name and qemu
as the machine architecture.
Of the available architectures, qemu is the only architecture
that causes the script to prompt you further for an actual architecture.
In every other way, this architecture is representative of how creating a BSP for
an actual machine would work.
The reason the example uses this architecture is because it is an emulated architecture
and can easily be followed without requiring actual hardware.
As the yocto-bsp create command runs, default values for
the prompts appear in brackets.
Pressing enter without supplying anything on the command line or pressing enter
with an invalid response causes the script to accept the default value.
Once the script completes, the new meta-myarm BSP layer
is created in the current working directory.
This example assumes you have sourced the
oe-init-build-env
and are currently in the top-level folder of the
Source Directory.
Following is the complete example:
$ yocto-bsp create myarm qemu
Checking basic git connectivity...
Done.
Which qemu architecture would you like to use? [default: i386]
1) i386 (32-bit)
2) x86_64 (64-bit)
3) ARM (32-bit)
4) PowerPC (32-bit)
5) MIPS (32-bit)
3
Would you like to use the default (3.10) kernel? (y/n) [default: y] y
Do you need a new machine branch for this BSP (the alternative is to re-use an existing branch)? [y/n] [default: y]
Getting branches from remote repo git://git.yoctoproject.org/linux-yocto-3.10.git...
Please choose a machine branch to base your new BSP branch on: [default: standard/base]
1) standard/arm-versatile-926ejs
2) standard/base
3) standard/beagleboard
4) standard/ck
5) standard/crownbay
6) standard/edf
7) standard/emenlow
8) standard/fri2
9) standard/fsl-mpc8315e-rdb
10) standard/minnow
11) standard/mti-malta32
12) standard/mti-malta64
13) standard/qemuppc
14) standard/routerstationpro
15) standard/sys940x
1
Would you like SMP support? (y/n) [default: y]
Does your BSP have a touchscreen? (y/n) [default: n]
Does your BSP have a keyboard? (y/n) [default: y]
New qemu BSP created in meta-myarm
Let's take a closer look at the example now:
For the QEMU architecture, the script first prompts you for which emulated architecture to use. In the example, we use the ARM architecture.
The script then prompts you for the kernel. The default 3.10 kernel is acceptable. So, the example accepts the default. If you enter 'n', the script prompts you to further enter the kernel you do want to use (e.g. 3.2, 3.2_preempt-rt, and so forth.).
Next, the script asks whether you would like to have a new branch created especially for your BSP in the local Linux Yocto Kernel Git repository . If not, then the script re-uses an existing branch.
In this example, the default (or "yes") is accepted. Thus, a new branch is created for the BSP rather than using a common, shared branch. The new branch is the branch committed to for any patches you might later add. The reason a new branch is the default is that typically new BSPs do require BSP-specific patches. The tool thus assumes that most of time a new branch is required.
Regardless of which choice you make in the previous step, you are now given the opportunity to select a particular machine branch on which to base your new BSP-specific machine branch (or to re-use if you had elected to not create a new branch). Because this example is generating an ARM-based BSP, the example uses
#1at the prompt, which selects the ARM-versatile branch.The remainder of the prompts are routine. Defaults are accepted for each.
By default, the script creates the new BSP Layer in the current working directory of the Source Directory, which is
pokyin this case.
Once the BSP Layer is created, you must add it to your
bblayers.conf file.
Here is an example:
BBLAYERS = ? " \
/usr/local/src/yocto/meta \
/usr/local/src/yocto/meta-yocto \
/usr/local/src/yocto/meta-yocto-bsp \
/usr/local/src/yocto/meta-myarm \
"
BBLAYERS_NON_REMOVABLE ?= " \
/usr/local/src/yocto/meta \
/usr/local/src/yocto/meta-yocto \
"
Adding the layer to this file allows the build system to build the BSP and
the yocto-kernel tool to be able to find the layer and
other Metadata it needs on which to operate.
Assuming you have created a BSP Layer using
yocto-bsp and you added it to your
BBLAYERS
variable in the bblayers.conf file, you can now use
the yocto-kernel script to add patches and configuration
items to the BSP's kernel.
The yocto-kernel script allows you to add, remove, and list patches
and kernel config settings to a BSP's kernel
.bbappend file.
All you need to do is use the appropriate sub-command.
Recall that the easiest way to see exactly what sub-commands are available
is to use the yocto-kernel built-in help as follows:
$ yocto-kernel
Usage:
Modify and list Yocto BSP kernel config items and patches.
usage: yocto-kernel [--version] [--help] COMMAND [ARGS]
Current 'yocto-kernel' commands are:
config list List the modifiable set of bare kernel config options for a BSP
config add Add or modify bare kernel config options for a BSP
config rm Remove bare kernel config options from a BSP
patch list List the patches associated with a BSP
patch add Patch the Yocto kernel for a BSP
patch rm Remove patches from a BSP
feature list List the features used by a BSP
feature add Have a BSP use a feature
feature rm Have a BSP stop using a feature
features list List the features available to BSPs
feature describe Describe a particular feature
feature create Create a new BSP-local feature
feature destroy Remove a BSP-local feature
See 'yocto-kernel help COMMAND' for more information on a specific command.
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-D, --debug output debug information
The yocto-kernel patch add sub-command allows you to add a
patch to a BSP.
The following example adds two patches to the myarm BSP:
$ yocto-kernel patch add myarm ~/test.patch
Added patches:
test.patch
$ yocto-kernel patch add myarm ~/yocto-testmod.patch
Added patches:
yocto-testmod.patch
Note
Although the previous example adds patches one at a time, it is possible to add multiple patches at the same time.
You can verify patches have been added by using the
yocto-kernel patch list sub-command.
Here is an example:
$ yocto-kernel patch list myarm
The current set of machine-specific patches for myarm is:
1) test.patch
2) yocto-testmod.patch
You can also use the yocto-kernel script to
remove a patch using the yocto-kernel patch rm sub-command.
Here is an example:
$ yocto-kernel patch rm myarm
Specify the patches to remove:
1) test.patch
2) yocto-testmod.patch
1
Removed patches:
test.patch
Again, using the yocto-kernel patch list sub-command,
you can verify that the patch was in fact removed:
$ yocto-kernel patch list myarm
The current set of machine-specific patches for myarm is:
1) yocto-testmod.patch
In a completely similar way, you can use the yocto-kernel config add
sub-command to add one or more kernel config item settings to a BSP.
The following commands add a couple of config items to the
myarm BSP:
$ yocto-kernel config add myarm CONFIG_MISC_DEVICES=y
Added items:
CONFIG_MISC_DEVICES=y
$ yocto-kernel config add myarm CONFIG_YOCTO_TESTMOD=y
Added items:
CONFIG_YOCTO_TESTMOD=y
Note
Although the previous example adds config items one at a time, it is possible to add multiple config items at the same time.
You can list the config items now associated with the BSP. Doing so shows you the config items you added as well as others associated with the BSP:
$ yocto-kernel config list myarm
The current set of machine-specific kernel config items for myarm is:
1) CONFIG_MISC_DEVICES=y
2) CONFIG_YOCTO_TESTMOD=y
Finally, you can remove one or more config items using the
yocto-kernel config rm sub-command in a manner
completely analogous to yocto-kernel patch rm.
 |
Copyright © 2010-2014 Linux Foundation
Permission is granted to copy, distribute and/or modify this document under the terms of the Creative Commons Attribution-Share Alike 2.0 UK: England & Wales as published by Creative Commons.
Note
For the latest version of this manual associated with this Yocto Project release, see the Yocto Project Linux Kernel Development Manual from the Yocto Project website.| Revision History | |
|---|---|
| Revision 1.4 | April 2013 |
| Released with the Yocto Project 1.4 Release. | |
| Revision 1.5 | October 2013 |
| Released with the Yocto Project 1.5 Release. | |
| Revision 1.5.1 | January 2014 |
| Released with the Yocto Project 1.5.1 Release. | |
| Revision 1.5.2 | May 2014 |
| Released with the Yocto Project 1.5.2 Release. | |
Regardless of how you intend to make use of the Yocto Project, chances are you will work with the Linux kernel. This manual provides background information on the Yocto Linux kernel Metadata, describes common tasks you can perform using the kernel tools, and shows you how to use the kernel Metadata needed to work with the kernel inside the Yocto Project.
Each Yocto Project release has a set of linux-yocto recipes, whose
Git repositories you can view in the Yocto
Source Repositories under
the "Yocto Linux Kernel" heading.
New recipes for the release track the latest upstream developments
and introduce newly supported platforms.
Previous recipes in the release are refreshed and supported for at
least one additional release.
As they align, these previous releases are updated to include the
latest from the Long Term Support Initiative (LTSI) project.
Also included is a linux-yocto development recipe
(linux-yocto-dev.bb) should you want to work
with the very latest in upstream Linux kernel development and
kernel Metadata development.
The Yocto Project also provides a powerful set of kernel tools for managing Linux kernel sources and configuration data. You can use these tools to make a single configuration change, apply multiple patches, or work with your own kernel sources.
In particular, the kernel tools allow you to generate configuration
fragments that specify only what you must, and nothing more.
Configuration fragments only need to contain the highest level
visible CONFIG options as presented by the Linux
kernel menuconfig system.
Contrast this against a complete Linux kernel
.config, which includes all the automatically
selected CONFIG options.
This efficiency reduces your maintenance effort and allows you
to further separate your configuration in ways that make sense for
your project.
A common split separates policy and hardware.
For example, all your kernels might support
the proc and sys filesystems,
but only specific boards require sound, USB, or specific drivers.
Specifying these configurations individually allows you to aggregate
them together as needed, but maintains them in only one place.
Similar logic applies to separating source changes.
If you do not maintain your own kernel sources and need to make only minimal changes to the sources, the released recipes provide a vetted base upon which to layer your changes. Doing so allows you to benefit from the continual kernel integration and testing performed during development of the Yocto Project.
If, instead, you have a very specific Linux kernel source tree and are unable to align with one of the official linux-yocto recipes, an alternative exists by which you can use the Yocto Project Linux kernel tools with your own kernel sources.
The sections that follow provide instructions for completing specific Linux kernel development tasks. These instructions assume you are comfortable working with BitBake recipes and basic open-source development tools. Understanding these concepts will facilitate the process of working with the kernel recipes. If you find you need some additional background, please be sure to review and understand the following documentation:
Yocto Project Quick Start
The "Modifying Temporary Source Code" section in the Yocto Project Development Manual
The "Understanding and Creating Layers" section in the Yocto Project Development Manual
The "Modifying the Kernel" section in the Yocto Project Development Manual.
Finally, while this document focuses on the manual creation of recipes, patches, and configuration files, the Yocto Project Board Support Package (BSP) tools are available to automate this process with existing content and work well to create the initial framework and boilerplate code. For details on these tools, see the "Using the Yocto Project's BSP Tools" section in the Yocto Project Board Support Package (BSP) Developer's Guide.
This chapter presents several common tasks you perform when you work with the Yocto Project Linux kernel. These tasks include preparing a layer, modifying an existing recipe, iterative development, working with your own sources, and incorporating out-of-tree modules.
Note
The examples presented in this chapter work with the Yocto Project 1.2.2 Release and forward.
If you are going to be modifying kernel recipes, it is recommended
that you create and prepare your own layer in which to do your
work.
Your layer contains its own BitBake append files
(.bbappend) and provides a convenient
mechanism to create your own recipe files
(.bb).
For details on how to create and work with layers, see the following
sections in the Yocto Project Development Manual:
"Understanding and Creating Layers" for general information on layers and how to create layers.
"Set Up Your Layer for the Build" for specific instructions on setting up a layer for kernel development.
In many cases, you can customize an existing linux-yocto recipe to
meet the needs of your project.
Each release of the Yocto Project provides a few Linux
kernel recipes from which you can choose.
These are located in the
Source Directory
in meta/recipes-kernel/linux.
Modifying an existing recipe can consist of the following:
Creating the append file
Applying patches
Changing the configuration
Before modifying an existing recipe, be sure that you have created a minimal, custom layer from which you can work. See the "Creating and Preparing a Layer" section for some general resources. You can also see the "Set Up Your Layer for the Build" section of the Yocto Project Development Manual for a detailed example.
You create this file in your custom layer.
You also name it accordingly based on the linux-yocto recipe
you are using.
For example, if you are modifying the
meta/recipes-kernel/linux/linux-yocto_3.4.bb
recipe, the append file will typical be located as follows
within your custom layer:
<your-layer>/recipes-kernel/linux/linux-yocto_3.4.bbappend
The append file should initially extend the
FILESPATH
search path by prepending the directory that contains your
files to the
FILESEXTRAPATHS
variable as follows:
FILESEXTRAPATHS_prepend := "${THISDIR}/${PN}:"
The path ${THISDIR}/${PN}
expands to "linux-yocto" in the current directory for this
example.
If you add any new files that modify the kernel recipe and you
have extended FILESPATH as
described above, you must place the files in your layer in the
following area:
<your-layer>/recipes-kernel/linux/linux-yocto/
Note
If you are working on a new machine Board Support Package (BSP), be sure to refer to the Yocto Project Board Support Package (BSP) Developer's Guide.
If you have a single patch or a small series of patches
that you want to apply to the Linux kernel source, you
can do so just as you would with any other recipe.
You first copy the patches to the path added to
FILESEXTRAPATHS
in your .bbappend file as described in
the previous section, and then reference them in
SRC_URI
statements.
For example, you can apply a three-patch series by adding the
following lines to your linux-yocto .bbappend
file in your layer:
SRC_URI += "file://0001-first-change.patch"
SRC_URI += "file://0002-first-change.patch"
SRC_URI += "file://0003-first-change.patch"
The next time you run BitBake to build the Linux kernel, BitBake detects the change in the recipe and fetches and applies the patches before building the kernel.
For a detailed example showing how to patch the kernel, see the "Patching the Kernel" section in the Yocto Project Development Manual.
You can make wholesale or incremental changes to the Linux
kernel .config file by including a
defconfig and by specifying
configuration fragments in the
SRC_URI.
If you have a final Linux kernel .config
file you want to use, copy it to a directory named
files, which must be in
your layer's recipes-kernel/linux
directory, and name the file "defconfig".
Then, add the following lines to your linux-yocto
.bbappend file in your layer:
FILESEXTRAPATHS_prepend := "${THISDIR}/files:"
SRC_URI += "file://defconfig"
The SRC_URI tells the build system how to
search for the file, while the
FILESEXTRAPATHS
extends the
FILESPATH
variable (search directories) to include the
files directory you created for the
configuration changes.
Note
The build system applies the configurations from the.config file before applying any
subsequent configuration fragments.
The final kernel configuration is a combination of the
configurations in the .config file and
any configuration fragments you provide.
You need to realize that if you have any configuration
fragments, the build system applies these on top of and
after applying the existing .config
file configurations.
Generally speaking, the preferred approach is to determine the
incremental change you want to make and add that as a
configuration fragment.
For example, if you want to add support for a basic serial
console, create a file named 8250.cfg in
the files directory with the following
content (without indentation):
CONFIG_SERIAL_8250=y
CONFIG_SERIAL_8250_CONSOLE=y
CONFIG_SERIAL_8250_PCI=y
CONFIG_SERIAL_8250_NR_UARTS=4
CONFIG_SERIAL_8250_RUNTIME_UARTS=4
CONFIG_SERIAL_CORE=y
CONFIG_SERIAL_CORE_CONSOLE=y
Next, include this configuration fragment and extend the
FILESPATH variable in your
.bbappend file:
FILESEXTRAPATHS_prepend := "${THISDIR}/files:"
SRC_URI += "file://8250.cfg"
The next time you run BitBake to build the Linux kernel, BitBake detects the change in the recipe and fetches and applies the new configuration before building the kernel.
For a detailed example showing how to configure the kernel, see the "Configuring the Kernel" section in the Yocto Project Development Manual.
If you do not have existing patches or configuration files, you can iteratively generate them from within the BitBake build environment as described within this section. During an iterative workflow, running a previously completed BitBake task causes BitBake to invalidate the tasks that follow the completed task in the build sequence. Invalidated tasks rebuild the next time you run the build using BitBake.
As you read this section, be sure to substitute the name of your Linux kernel recipe for the term "linux-yocto".
If kernel images are being built with "-dirty" on the end of the version string, this simply means that modifications in the source directory have not been committed.
$ git status
You can use the above Git command to report modified, removed, or added files. You should commit those changes to the tree regardless of whether they will be saved, exported, or used. Once you commit the changes, you need to rebuild the kernel.
To force a pickup and commit of all such pending changes, enter the following:
$ git add .
$ git commit -s -a -m "getting rid of -dirty"
Next, rebuild the kernel.
You can manipulate the .config file
used to build a linux-yocto recipe with the
menuconfig command as follows:
$ bitbake linux-yocto -c menuconfig
This command starts the Linux kernel configuration tool,
which allows you to prepare a new
.config file for the build.
When you exit the tool, be sure to save your changes
at the prompt.
The resulting .config file is
located in
${WORKDIR} under the
linux-${MACHINE}-${ directory.
You can use the entire KTYPE}-build.config file as the
defconfig file as described in the
"Changing the Configuration" section.
A better method is to create a configuration fragment using the
differences between two configuration files: one previously
created and saved, and one freshly created using the
menuconfig tool.
To create a configuration fragment using this method, follow these steps:
Complete a build at least through the kernel configuration task as follows:
$ bitbake linux-yocto -c kernel_configme -fCopy and rename the resulting
.configfile (e.g.config.orig).Run the
menuconfigcommand:$ bitbake linux-yocto -c menuconfigPrepare a configuration fragment based on the differences between the two files.
Ultimately, the configuration fragment file needs to be a
list of Linux kernel CONFIG_ assignments.
It cannot be in diff format.
Here is an example of a command that creates your
configuration fragment file.
Regardless of the exact command you use, plan on reviewing
the output as you can usually remove some of the defaults:
$ diff -Nurp config.orig .config | sed -n "s/^\+//p" > frag.cfg
See the "Changing the Configuration" section for information on how to use the output as a configuration fragment.
Note
You can also use this method to create configuration fragments for a BSP. See the "BSP Descriptions" section for more information.
The kernel tools also provide configuration validation.
You can use these tools to produce warnings for when a
requested configuration does not appear in the final
.config file or when you override a
policy configuration in a hardware configuration fragment.
Here is an example with some sample output of the command
that runs these tools:
$ bitbake linux-yocto -c kernel_configcheck -f
...
NOTE: validating kernel configuration
This BSP sets 3 invalid/obsolete kernel options.
These config options are not offered anywhere within this kernel.
The full list can be found in your kernel src dir at:
meta/cfg/standard/mybsp/invalid.cfg
This BSP sets 21 kernel options that are possibly non-hardware related.
The full list can be found in your kernel src dir at:
meta/cfg/standard/mybsp/specified_non_hdw.cfg
WARNING: There were 2 hardware options requested that do not
have a corresponding value present in the final ".config" file.
This probably means you are not't getting the config you wanted.
The full list can be found in your kernel src dir at:
meta/cfg/standard/mybsp/mismatch.cfg
The output describes the various problems that you can
encounter along with where to find the offending configuration
items.
You can use the information in the logs to adjust your
configuration files and then repeat the
kernel_configme and
kernel_configcheck commands until
they produce no warnings.
For more information on how to use the
menuconfig tool, see the
"Using menuconfig"
section in the Yocto Project Development Manual.
You can experiment with source code changes and create a simple patch without leaving the BitBake environment. To get started, be sure to complete a build at least through the kernel configuration task:
$ bitbake linux-yocto -c kernel_configme -f
Taking this step ensures you have the sources prepared
and the configuration completed.
You can find the sources in the
${WORKDIR}/linux directory.
You can edit the sources as you would any other Linux source
tree.
However, keep in mind that you will lose changes if you
trigger the fetch task for the recipe.
You can avoid triggering this task by not issuing BitBake's
cleanall, cleansstate,
or forced fetch commands.
Also, do not modify the recipe itself while working
with temporary changes or BitBake might run the
fetch command depending on the
changes to the recipe.
To test your temporary changes, instruct BitBake to run the
compile again.
The -f option forces the command to run
even though BitBake might think it has already done so:
$ bitbake linux-yocto -c compile -f
If the compile fails, you can update the sources and repeat
the compile.
Once compilation is successful, you can inspect and test
the resulting build (i.e. kernel, modules, and so forth) from
the Build Directory:
${WORKDIR}/linux-${MACHINE}-${KTYPE}-build
Alternatively, you can run the deploy
command to place the kernel image in the
tmp/deploy/images directory:
$ bitbake linux-yocto -c deploy
And, of course, you can perform the remaining installation and packaging steps by issuing:
$ bitbake linux-yocto
For rapid iterative development, the edit-compile-repeat loop described in this section is preferable to rebuilding the entire recipe because the installation and packaging tasks are very time consuming.
Once you are satisfied with your source code modifications,
you can make them permanent by generating patches and
applying them to the
SRC_URI
statement as described in section
"Applying Patches" section.
If you are not familiar with generating patches, refer to the
"Creating the Patch"
section in the Yocto Project Development Manual.
If you cannot work with one of the Linux kernel versions supported by existing linux-yocto recipes, you can still make use of the Yocto Project Linux kernel tooling by working with your own sources. When you use your own sources, you will not be able to leverage the existing kernel Metadata and stabilization work of the linux-yocto sources. However, you will be able to manage your own Metadata in the same format as the linux-yocto sources. Maintaining format compatibility facilitates converging with linux-yocto on a future, mutually-supported kernel version.
To help you use your own sources, the Yocto Project provides a
linux-yocto custom recipe
(linux-yocto-custom.bb) that uses
kernel.org sources
and the Yocto Project Linux kernel tools for managing
kernel Metadata.
You can find this recipe in the
poky Git repository of the
Yocto Project Source Repository
at:
poky/meta-skeleton/recipes-kernel/linux/linux-yocto-custom.bb
Here are some basic steps you can use to work with your own sources:
Copy the
linux-yocto-custom.bbrecipe to your layer and give it a meaningful name. The name should include the version of the Linux kernel you are using (e.g.linux-yocto-myproject_3.5.bb, where "3.5" is the base version of the Linux kernel with which you would be working).In the same directory inside your layer, create a matching directory to store your patches and configuration files (e.g.
linux-yocto-myproject).Edit the following variables in your recipe as appropriate for your project:
SRC_URI: TheSRC_URIshould be a Git repository that uses one of the supported Git fetcher protocols (i.e.file,git,http, and so forth). The skeleton recipe provides an exampleSRC_URIas a syntax reference.LINUX_VERSION: The Linux kernel version you are using (e.g. "3.4").LINUX_VERSION_EXTENSION: The Linux kernelCONFIG_LOCALVERSIONthat is compiled into the resulting kernel and visible through theunamecommand.SRCREV: The commit ID from which you want to build.PR: Treat this variable the same as you would in any other recipe. Increment the variable to indicate to the OpenEmbedded build system that the recipe has changed.PV: The defaultPVassignment is typically adequate. It combines theLINUX_VERSIONwith the Source Control Manager (SCM) revision as derived from theSRCPVvariable. The combined results are a string with the following form:3.4.11+git1+68a635bf8dfb64b02263c1ac80c948647cc76d5f_1+218bd8d2022b9852c60d32f0d770931e3cf343e2While lengthy, the extra verbosity in
PVhelps ensure you are using the exact sources from which you intend to build.COMPATIBLE_MACHINE: A list of the machines supported by your new recipe. This variable in the example recipe is set by default to a regular expression that matches only the empty string, "(^$)". This default setting triggers an explicit build failure. You must change it to match a list of the machines that your new recipe supports. For example, to support theqemux86andqemux86-64machines, use the following form:COMPATIBLE_MACHINE = "qemux86|qemux86-64"
Provide further customizations to your recipe as needed just as you would customize an existing linux-yocto recipe. See the "Modifying an Existing Recipe" section for information.
While it is always preferable to work with sources integrated
into the Linux kernel sources, if you need an external kernel
module, the hello-mod.bb recipe is available
as a template from which you can create your own out-of-tree
Linux kernel module recipe.
This template recipe is located in the
poky Git repository of the
Yocto Project Source Repository
at:
poky/meta-skeleton/recipes-kernel/hello-mod/hello-mod_0.1.bb
To get started, copy this recipe to your layer and give it a
meaningful name (e.g. mymodule_1.0.bb).
In the same directory, create a directory named
files where you can store any source files,
patches, or other files necessary for building
the module that do not come with the sources.
Finally, update the recipe as appropriate for the module.
Typically you will need to set the following variables:
Depending on the build system used by the module sources, you might
need to make some adjustments.
For example, a typical module Makefile looks
much like the one provided with the hello-mod
template:
obj-m := hello.o
SRC := $(shell pwd)
all:
$(MAKE) -C $(KERNEL_SRC) M=$(SRC)
modules_install:
$(MAKE) -C $(KERNEL_SRC) M=$(SRC) modules_install
...
The important point to note here is the
KERNEL_SRC
variable.
The class module.bbclass sets this variable,
as well as the
KERNEL_PATH
variable to
${
with the necessary Linux kernel build information to build modules.
If your module STAGING_KERNEL_DIR}Makefile uses a different
variable, you might want to override the
do_compile() step, or create a patch to
the Makefile to work with the more typical
KERNEL_SRC or KERNEL_PATH
variables.
After you have prepared your recipe, you will likely want to include the module in your images. To do this, see the documentation for the following variables in the Yocto Project Reference Manual and set one of them as appropriate in your machine configuration file:
modules are often not required for boot and can be excluded from certain build configurations. The following allows for the most flexibility:
MACHINE_EXTRA_RRECOMMENDS += "kernel-module-mymodule"
Where the value is derived by appending the module filename without
the .ko extension to the string
"kernel-module-".
Because the variable is
RRECOMMENDS
and not a
RDEPENDS
variable, the build will not fail if this module is not available
to include in the image.
A common question when working with a kernel is: "What changes have been applied to this tree?" Rather than using "grep" across directories to see what has changed, you can use Git to inspect or search the kernel tree. Using Git is an efficient way to see what has changed in the tree.
Following are a few examples that show how to use Git commands to examine changes. These examples are by no means the only way to see changes.
Note
In the following examples, unless you provide a commit range,kernel.org history is blended
with Yocto Project kernel changes.
You can form ranges by using branch names from the
kernel tree as the upper and lower commit markers with
the Git commands.
You can see the branch names through the web interface
to the Yocto Project source repositories at
http://git.yoctoproject.org/cgit.cgi.
To see a full range of the changes, use the
git whatchanged command and specify a
commit range for the branch
(<commit>..<commit>).
Here is an example that looks at what has changed in the
emenlow branch of the
linux-yocto-3.4 kernel.
The lower commit range is the commit associated with the
standard/base branch, while
the upper commit range is the commit associated with the
standard/emenlow branch.
$ git whatchanged origin/standard/base..origin/standard/emenlow
To see short, one line summaries of changes use the
git log command:
$ git log --oneline origin/standard/base..origin/standard/emenlow
Use this command to see code differences for the changes:
$ git diff origin/standard/base..origin/standard/emenlow
Use this command to see the commit log messages and the text differences:
$ git show origin/standard/base..origin/standard/emenlow
Use this command to create individual patches for
each change.
Here is an example that that creates patch files for each
commit and places them in your Documents
directory:
$ git format-patch -o $HOME/Documents origin/standard/base..origin/standard/emenlow
Tags in the Yocto Project kernel tree divide changes for
significant features or branches.
The git show <tag> command shows
changes based on a tag.
Here is an example that shows systemtap
changes:
$ git show systemtap
You can use the
git branch --contains <tag> command
to show the branches that contain a particular feature.
This command shows the branches that contain the
systemtap feature:
$ git branch --contains systemtap
In addition to supporting configuration fragments and patches, the
Yocto Project kernel tools also support rich
Metadata that you can
use to define complex policies and Board Support Package (BSP) support.
The purpose of the Metadata and the tools that manage it, known as
the kern-tools (kern-tools-native_git.bb), is
to help you manage the complexity of the configuration and sources
used to support multiple BSPs and Linux kernel types.
The kernel sources in the Yocto Project contain kernel Metadata, which is
located in the meta branches of the kernel source
Git repositories.
This Metadata defines Board Support Packages (BSPs) that
correspond to definitions in linux-yocto recipes for the same BSPs.
A BSP consists of an aggregation of kernel policy and hardware-specific
feature enablements.
The BSP can be influenced from within the linux-yocto recipe.
Note
Linux kernel source that contains kernel Metadata is said to be "linux-yocto style" kernel source. A Linux kernel recipe that inherits from thelinux-yocto.inc include file is said to be a
"linux-yocto style" recipe.
Every linux-yocto style recipe must define the
KMACHINE
variable.
This variable is typically set to the same value as the
MACHINE
variable, which is used by BitBake (e.g. "routerstationpro" or "fri2").
Multiple BSPs can reuse the same KMACHINE
name if they are built using the same BSP description.
The "fri2" and "fri2-noemgd" BSP combination
in the meta-intel
layer is a good example of two BSPs using the same
KMACHINE value (i.e. "fri2").
See the BSP Descriptions section
for more information.
The linux-yocto style recipes can optionally define the following variables:
KBRANCH
KERNEL_FEATURES
KBRANCH_DEFAULT
LINUX_KERNEL_TYPE
KBRANCH_DEFAULT defines the Linux kernel source
repository's default branch to use to build the Linux kernel.
The value is used as the default for KBRANCH, which
can define an alternate branch typically with a machine override as
follows:
KBRANCH_fri2 = "standard/fri2"
Unless you specify otherwise, KBRANCH_DEFAULT
initializes to "master".
LINUX_KERNEL_TYPE defines the kernel type to be
used in assembling the configuration.
If you do not specify a LINUX_KERNEL_TYPE,
it defaults to "standard".
Together with
KMACHINE,
LINUX_KERNEL_TYPE defines the search
arguments used by the kernel tools to find the
appropriate description within the kernel Metadata with which to
build out the sources and configuration.
The linux-yocto recipes define "standard", "tiny", and "preempt-rt"
kernel types.
See the Kernel Types section
for more information on kernel types.
During the build, the kern-tools search for the BSP description
file that most closely matches the KMACHINE
and LINUX_KERNEL_TYPE variables passed in from the
recipe.
The tools use the first BSP description it finds that match
both variables.
If the tools cannot find a match, they issue a warning such as
the following:
WARNING: Can't find any BSP hardware or required configuration fragments.
WARNING: Looked at meta/cfg/broken/fri2-broken/hdw_frags.txt and
meta/cfg/broken/fri2-broken/required_frags.txt in directory:
meta/cfg/broken/fri2-broken
In this example, KMACHINE was set to "fri2-broken"
and LINUX_KERNEL_TYPE was set to "broken".
The tools first search for the KMACHINE and
then for the LINUX_KERNEL_TYPE.
If the tools cannot find a partial match, they will use the
sources from the KBRANCH and any configuration
specified in the
SRC_URI.
You can use the KERNEL_FEATURES variable
to include features (configuration fragments, patches, or both) that
are not already included by the KMACHINE and
LINUX_KERNEL_TYPE variable combination.
For example, to include a feature specified as "features/netfilter.scc",
specify:
KERNEL_FEATURES += "features/netfilter.scc"
To include a feature called "cfg/sound.scc" just for the
qemux86 machine, specify:
KERNEL_FEATURES_append_qemux86 = "cfg/sound.scc"
The value of the entries in KERNEL_FEATURES
are dependent on their location within the kernel Metadata itself.
The examples here are taken from the
linux-yocto-3.4 repository where "features"
and "cfg" are subdirectories within the
meta/cfg/kernel-cache directory.
For more information, see the
"Kernel Metadata Syntax" section.
Note
The processing of the these variables has evolved some between the 0.9 and 1.3 releases of the Yocto Project and associated kern-tools sources. The descriptions in this section are accurate for 1.3 and later releases of the Yocto Project.
Kernel Metadata can be defined in either the kernel recipe (recipe-space) or in the kernel tree (in-tree). Where you choose to define the Metadata depends on what you want to do and how you intend to work. Regardless of where you define the kernel Metadata, the syntax used applies equally.
If you are unfamiliar with the Linux kernel and only wish to apply a configuration and possibly a couple of patches provided to you by others, the recipe-space method is recommended. This method is also a good approach if you are working with Linux kernel sources you do not control or if you just do not want to maintain a Linux kernel Git repository on your own. For partial information on how you can define kernel Metadata in the recipe-space, see the "Modifying an Existing Recipe" section.
Conversely, if you are actively developing a kernel and are already maintaining a Linux kernel Git repository of your own, you might find it more convenient to work with the kernel Metadata in the same repository as the Linux kernel sources. This method can make iterative development of the Linux kernel more efficient outside of the BitBake environment.
When stored in recipe-space, the kernel Metadata files reside in a
directory hierarchy below
FILESEXTRAPATHS.
For a linux-yocto recipe or for a Linux kernel recipe derived
by copying and modifying
oe-core/meta-skeleton/recipes-kernel/linux/linux-yocto-custom.bb
to a recipe in your layer, FILESEXTRAPATHS
is typically set to
${THISDIR}/${PN}.
See the "Modifying an Existing Recipe"
section for more information.
Here is an example that shows a trivial tree of kernel Metadata stored in recipe-space within a BSP layer:
meta-my_bsp_layer/
`-- recipes-kernel
`-- linux
`-- linux-yocto
|-- bsp-standard.scc
|-- bsp.cfg
`-- standard.cfg
When the Metadata is stored in recipe-space, you must take
steps to ensure BitBake has the necessary information to decide
what files to fetch and when they need to be fetched again.
It is only necessary to specify the .scc
files on the
SRC_URI.
BitBake parses them and fetches any files referenced in the
.scc files by the include,
patch, or kconf commands.
Because of this, it is necessary to bump the recipe
PR
value when changing the content of files not explicitly listed
in the SRC_URI.
When stored in-tree, the kernel Metadata files reside in the
meta directory of the Linux kernel sources.
The meta directory can be present in the
same repository branch as the sources,
such as "master", or meta can be its own
orphan branch.
Note
An orphan branch in Git is a branch with unique history and content to the other branches in the repository. Orphan branches are useful to track Metadata changes independently from the sources of the Linux kernel, while still keeping them together in the same repository.
For the purposes of this document, we will discuss all
in-tree Metadata as residing below the
meta/cfg/kernel-cache directory.
Following is an example that shows how a trivial tree of Metadata is stored in a custom Linux kernel Git repository:
meta/
`-- cfg
`-- kernel-cache
|-- bsp-standard.scc
|-- bsp.cfg
`-- standard.cfg
To use a branch different from where the sources reside,
specify the branch in the KMETA variable
in your Linux kernel recipe.
Here is an example:
KMETA = "meta"
To use the same branch as the sources, set
KMETA to an empty string:
KMETA = ""
If you are working with your own sources and want to create an
orphan meta branch, use these commands
from within your Linux kernel Git repository:
$ git checkout --orphan meta
$ git rm -rf .
$ git commit --allow-empty -m "Create orphan meta branch"
If you modify the Metadata in the linux-yocto
meta branch, you must not forget to update
the
SRCREV
statements in the kernel's recipe.
In particular, you need to update the
SRCREV_meta variable to match the commit in
the KMETA branch you wish to use.
Changing the data in these branches and not updating the
SRCREV statements to match will cause the
build to fetch an older commit.
The kernel Metadata consists of three primary types of files:
scc
[2]
description files, configuration fragments, and patches.
The scc files define variables and include or
otherwise reference any of the three file types.
The description files are used to aggregate all types of kernel
Metadata into
what ultimately describes the sources and the configuration required
to build a Linux kernel tailored to a specific machine.
The scc description files are used to define two
fundamental types of kernel Metadata:
Features
Board Support Packages (BSPs)
Features aggregate sources in the form of patches and configuration fragments into a modular reusable unit. You can use features to implement conceptually separate kernel Metadata descriptions such as pure configuration fragments, simple patches, complex features, and kernel types. Kernel types define general kernel features and policy to be reused in the BSPs.
BSPs define hardware-specific features and aggregate them with kernel types to form the final description of what will be assembled and built.
While the kernel Metadata syntax does not enforce any logical separation of configuration fragments, patches, features or kernel types, best practices dictate a logical separation of these types of Metadata. The following Metadata file hierarchy is recommended:
<base>/
bsp/
cfg/
features/
ktypes/
patches/
The bsp directory contains the
BSP descriptions.
The remaining directories all contain "features".
Separating bsp from the rest of the structure
aids conceptualizing intended usage.
Use these guidelines to help place your scc
description files within the structure:
If your file contains only configuration fragments, place the file in the
cfgdirectory.If your file contains only source-code fixes, place the file in the
patchesdirectory.If your file encapsulates a major feature, often combining sources and configurations, place the file in
featuresdirectory.If your file aggregates non-hardware configuration and patches in order to define a base kernel policy or major kernel type to be reused across multiple BSPs, place the file in
ktypesdirectory.
These distinctions can easily become blurred - especially as
out-of-tree features slowly merge upstream over time.
Also, remember that how the description files are placed is
a purely logical organization and has no impact on the functionality
of the kernel Metadata.
There is no impact because all of cfg,
features, patches, and
ktypes, contain "features" as far as the kernel
tools are concerned.
Paths used in kernel Metadata files are relative to
<base>, which is either
FILESEXTRAPATHS
if you are creating Metadata in
recipe-space,
or meta/cfg/kernel-cache/ if you are creating
Metadata in-tree.
The simplest unit of kernel Metadata is the configuration-only
feature.
This feature consists of one or more Linux kernel configuration
parameters in a configuration fragment file
(.cfg) and an .scc file
that describes the fragment.
The Symmetric Multi-Processing (SMP) fragment included in the
linux-yocto-3.4 Git repository
consists of the following two files:
cfg/smp.scc:
define KFEATURE_DESCRIPTION "Enable SMP"
kconf hardware smp.cfg
cfg/smp.cfg:
CONFIG_SMP=y
CONFIG_SCHED_SMT=y
You can find information on configuration fragment files in the "Creating Configuration Fragments" section of the Yocto Project Development Manual and in the "Generating Configuration Files" section earlier in this manual.
KFEATURE_DESCRIPTION
provides a short description of the fragment.
Higher level kernel tools use this description.
The kconf command is used to include the
actual configuration fragment in an .scc
file, and the "hardware" keyword identifies the fragment as
being hardware enabling, as opposed to general policy,
which would use the "non-hardware" keyword.
The distinction is made for the benefit of the configuration
validation tools, which warn you if a hardware fragment
overrides a policy set by a non-hardware fragment.
Note
The description file can include multiplekconf statements, one per fragment.
As described in the "Generating Configuration Files" section, you can use the following BitBake command to audit your configuration:
$ bitbake linux-yocto -c kernel_configcheck -f
Patch descriptions are very similar to configuration fragment
descriptions, which are described in the previous section.
However, instead of a .cfg file, these
descriptions work with source patches.
A typical patch includes a description file and the patch itself:
patches/mypatch.scc:
patch mypatch.patch
patches/mypatch.patch:
<typical-patch>
You can create the typical .patch
file using diff -Nurp or
git format-patch.
The description file can include multiple patch statements, one per patch.
Features are complex kernel Metadata types that consist
of configuration fragments (kconf), patches
(patch), and possibly other feature
description files (include).
Here is an example that shows a feature description file:
features/myfeature.scc
define KFEATURE_DESCRIPTION "Enable myfeature"
patch 0001-myfeature-core.patch
patch 0002-myfeature-interface.patch
include cfg/myfeature_dependency.scc
kconf non-hardware myfeature.cfg
This example shows how the patch and
kconf commands are used as well as
how an additional feature description file is included.
Typically, features are less granular than configuration
fragments and are more likely than configuration fragments
and patches to be the types of things you want to specify
in the KERNEL_FEATURES variable of the
Linux kernel recipe.
See the "Using Kernel Metadata in a Recipe"
section earlier in the manual.
A kernel type defines a high-level kernel policy by
aggregating non-hardware configuration fragments with
patches you want to use when building a Linux kernels of a
specific type.
Syntactically, kernel types are no different than features
as described in the "Features"
section.
The LINUX_KERNEL_TYPE variable in the kernel
recipe selects the kernel type.
See the "Using Kernel Metadata in a Recipe"
section for more information.
As an example, the linux-yocto-3.4
tree defines three kernel types: "standard",
"tiny", and "preempt-rt":
"standard": Includes the generic Linux kernel policy of the Yocto Project linux-yocto kernel recipes. This policy includes, among other things, which file systems, networking options, core kernel features, and debugging and tracing options are supported.
"preempt-rt": Applies the
PREEMPT_RTpatches and the configuration options required to build a real-time Linux kernel. This kernel type inherits from the "standard" kernel type."tiny": Defines a bare minimum configuration meant to serve as a base for very small Linux kernels. The "tiny" kernel type is independent from the "standard" configuration. Although the "tiny" kernel type does not currently include any source changes, it might in the future.
The "standard" kernel type is defined by
standard.scc:
# Include this kernel type fragment to get the standard features and
# configuration values.
# Include all standard features
include standard-nocfg.scc
kconf non-hardware standard.cfg
# individual cfg block section
include cfg/fs/devtmpfs.scc
include cfg/fs/debugfs.scc
include cfg/fs/btrfs.scc
include cfg/fs/ext2.scc
include cfg/fs/ext3.scc
include cfg/fs/ext4.scc
include cfg/net/ipv6.scc
include cfg/net/ip_nf.scc
include cfg/net/ip6_nf.scc
include cfg/net/bridge.scc
As with any .scc file, a
kernel type definition can aggregate other
.scc files with
include commands.
These definitions can also directly pull in
configuration fragments and patches with the
kconf and patch
commands, respectively.
Note
It is not strictly necessary to create a kernel type.scc file.
The Board Support Package (BSP) file can implicitly define
the kernel type using a define
KTYPE myktype
line.
See the "BSP Descriptions"
section for more information.
BSP descriptions combine kernel types with hardware-specific features. The hardware-specific portion is typically defined independently, and then aggregated with each supported kernel type. Consider this simple BSP description that supports the "mybsp" machine:
mybsp.scc:
define KMACHINE mybsp
define KTYPE standard
define KARCH i386
kconf mybsp.cfg
Every BSP description should define the
KMACHINE,
KTYPE,
and KARCH
variables.
These variables allow the OpenEmbedded build system to identify
the description as meeting the criteria set by the recipe being
built.
This simple example supports the "mybsp" machine for the "standard"
kernel and the "i386" architecture.
Be aware that a hard link between the
KTYPE variable and a kernel type
description file does not exist.
Thus, if you do not have kernel types defined in your kernel
Metadata, you only need to ensure that the kernel recipe's
LINUX_KERNEL_TYPE
variable and the KTYPE variable in the
BSP description file match.
Note
Future versions of the tooling make the specification ofKTYPE in the BSP optional.
If you did want to separate your kernel policy from your hardware configuration, you could do so by specifying a kernel type, such as "standard" and including that description file in the BSP description file. See the "Kernel Types" section for more information.
You might also have multiple hardware configurations that you
aggregate into a single hardware description file that you
could include in the BSP description file, rather than referencing
a single .cfg file.
Consider the following:
mybsp.scc:
define KMACHINE mybsp
define KTYPE standard
define KARCH i386
include standard.scc
include mybsp-hw.scc
In the above example, standard.scc
aggregates all the configuration fragments, patches, and
features that make up your standard kernel policy whereas
mybsp-hw.scc aggregates all those necessary
to support the hardware available on the "mybsp" machine.
For information on how to break a complete
.config file into the various
configuration fragments, see the
"Generating Configuration Files"
section.
Many real-world examples are more complex.
Like any other .scc file, BSP
descriptions can aggregate features.
Consider the Fish River Island 2 (fri2)
BSP definition from the linux-yocto-3.4
Git repository:
fri2.scc:
kconf hardware fri2.cfg
include cfg/x86.scc
include features/eg20t/eg20t.scc
include cfg/dmaengine.scc
include features/ericsson-3g/f5521gw.scc
include features/power/intel.scc
include cfg/efi.scc
include features/usb/ehci-hcd.scc
include features/usb/ohci-hcd.scc
include features/iwlwifi/iwlwifi.scc
The fri2.scc description file includes
a hardware configuration fragment
(fri2.cfg) specific to the Fish River
Island 2 BSP as well as several more general configuration
fragments and features enabling hardware found on the
machine.
This description file is then included in each of the three
"fri2" description files for the supported kernel types
(i.e. "standard", "preempt-rt", and "tiny").
Consider the "fri2" description for the "standard" kernel
type:
fri2-standard.scc:
define KMACHINE fri2
define KTYPE standard
define KARCH i386
include ktypes/standard/standard.scc
branch fri2
git merge emgd-1.14
include fri2.scc
# Extra fri2 configs above the minimal defined in fri2.scc
include cfg/efi-ext.scc
include features/drm-emgd/drm-emgd.scc
include cfg/vesafb.scc
# default policy for standard kernels
include cfg/usb-mass-storage.scc
The include command midway through the file
includes the fri2.scc description that
defines all hardware enablements for the BSP that is common to all
kernel types.
Using this command significantly reduces duplication.
This "fri2" standard description introduces a few more variables
and commands that are worth further discussion.
Notice the branch fri2 command, which creates
a machine-specific branch into which source changes are applied.
With this branch set up, the git merge command
uses Git to merge in a feature branch named "emgd-1.14".
You could also handle this with the patch
command.
However, for commonly used features such as this, feature branches
are a convenient mechanism.
See the "Feature Branches"
section for more information.
Now consider the "fri2" description for the "tiny" kernel type:
fri2-tiny.scc:
define KMACHINE fri2
define KTYPE tiny
define KARCH i386
include ktypes/tiny/tiny.scc
branch fri2
include fri2.scc
As you might expect, the "tiny" description includes quite a bit less. In fact, it includes only the minimal policy defined by the "tiny" kernel type and the hardware-specific configuration required for booting the machine along with the most basic functionality of the system as defined in the base "fri2" description file.
Notice again the three critical variables:
KMACHINE, KTYPE,
and KARCH.
Of these variables, only the KTYPE has changed.
It is now set to "tiny".
Many recipes based on the linux-yocto-custom.bb
recipe use Linux kernel sources that have only a single
branch - "master".
This type of repository structure is fine for linear development
supporting a single machine and architecture.
However, if you work with multiple boards and architectures,
a kernel source repository with multiple branches is more
efficient.
For example, suppose you need a series of patches for one board to boot.
Sometimes, these patches are works-in-progress or fundamentally wrong,
yet they are still necessary for specific boards.
In these situations, you most likely do not want to include these
patches in every kernel you build (i.e. have the patches as part of
the lone "master" branch).
It is situations like these that give rise to multiple branches used
within a Linux kernel sources Git repository.
Repository organization strategies exist that maximize source reuse, remove redundancy, and logically order your changes. This section presents strategies for the following cases:
Encapsulating patches in a feature description and only including the patches in the BSP descriptions of the applicable boards.
Creating a machine branch in your kernel source repository and applying the patches on that branch only.
Creating a feature branch in your kernel source repository and merging that branch into your BSP when needed.
The approach you take is entirely up to you and depends on what works best for your development model.
if you are reusing patches from an external tree and are not working on the patches, you might find the encapsulated feature to be appropriate. Given this scenario, you do not need to create any branches in the source repository. Rather, you just take the static patches you need and encapsulate them within a feature description. Once you have the feature description, you simply include that into the BSP description as described in the "BSP Descriptions" section.
You can find information on how to create patches and BSP descriptions in the "Patches" and "BSP Descriptions" sections.
When you have multiple machines and architectures to support, or you are actively working on board support, it is more efficient to create branches in the repository based on individual machines. Having machine branches allows common source to remain in the "master" branch with any features specific to a machine stored in the appropriate machine branch. This organization method frees you from continually reintegrating your patches into a feature.
Once you have a new branch, you can set up your kernel Metadata
to use the branch a couple different ways.
In the recipe, you can specify the new branch as the
KBRANCH to use for the board as
follows:
KBRANCH = "mynewbranch"
Another method is to use the branch command
in the BSP description:
mybsp.scc:
define KMACHINE mybsp
define KTYPE standard
define KARCH i386
include standard.scc
branch mynewbranch
include mybsp-hw.scc
If you find yourself with numerous branches, you might consider using a hierarchical branching system similar to what the linux-yocto Linux kernel repositories use:
<common>/<kernel_type>/<machine>
If you had two kernel types, "standard" and "small" for instance, and three machines, the branches in your Git repository might look like this:
common/base
common/standard/base
common/standard/machine_a
common/standard/machine_b
common/standard/machine_c
common/small/base
common/small/machine_a
This organization can help clarify the branch relationships.
In this case, common/standard/machine_a
includes everything in common/base and
common/standard/base.
The "standard" and "small" branches add sources specific to those
kernel types that for whatever reason are not appropriate for the
other branches.
Note
The "base" branches are an artifact of the way Git manages its data internally on the filesystem: Git will not allow you to usecommon/standard and
common/standard/machine_a because it
would have to create a file and a directory named "standard".
When you are actively developing new features, it can be more
efficient to work with that feature as a branch, rather than
as a set of patches that have to be regularly updated.
The Yocto Project Linux kernel tools provide for this with
the git merge command.
To merge a feature branch into a BSP, insert the
git merge command after any
branch commands:
mybsp.scc:
define KMACHINE mybsp
define KTYPE standard
define KARCH i386
include standard.scc
branch mynewbranch
git merge myfeature
include mybsp-hw.scc
This section provides a brief reference for the commands you can use
within an SCC description file (.scc):
branch [ref]: Creates a new branch relative to the current branch (typically${KTYPE}) using the currently checked-out branch, or "ref" if specified.define: Defines variables, such asKMACHINE,KTYPE,KARCH, andKFEATURE_DESCRIPTION.include SCC_FILE: Includes an SCC file in the current file. The file is parsed as if you had inserted it inline.kconf [hardware|non-hardware] CFG_FILE: Queues a configuration fragment for merging into the final Linux.configfile.git merge GIT_BRANCH: Merges the feature branch into the current branch.patch PATCH_FILE: Applies the patch to the current Git branch.
[2]
scc stands for Series Configuration
Control, but the naming has less significance in the
current implementation of the tooling than it had in the
past.
Consider scc files to be description files.
Kernels available through the Yocto Project, like other kernels, are based off the Linux
kernel releases from http://www.kernel.org.
At the beginning of a major development cycle, the Yocto Project team
chooses its kernel based on factors such as release timing, the anticipated release
timing of final upstream kernel.org versions, and Yocto Project
feature requirements.
Typically, the kernel chosen is in the
final stages of development by the community.
In other words, the kernel is in the release
candidate or "rc" phase and not yet a final release.
But, by being in the final stages of external development, the team knows that the
kernel.org final release will clearly be within the early stages of
the Yocto Project development window.
This balance allows the team to deliver the most up-to-date kernel possible, while still ensuring that the team has a stable official release for the baseline Linux kernel version.
The ultimate source for kernels available through the Yocto Project are released kernels
from kernel.org.
In addition to a foundational kernel from kernel.org, the
kernels available contain a mix of important new mainline
developments, non-mainline developments (when there is no alternative),
Board Support Package (BSP) developments,
and custom features.
These additions result in a commercially released Yocto Project Linux kernel that caters
to specific embedded designer needs for targeted hardware.
Once a kernel is officially released, the Yocto Project team goes into their next development cycle, or upward revision (uprev) cycle, while still continuing maintenance on the released kernel. It is important to note that the most sustainable and stable way to include feature development upstream is through a kernel uprev process. Back-porting hundreds of individual fixes and minor features from various kernel versions is not sustainable and can easily compromise quality.
During the uprev cycle, the Yocto Project team uses an ongoing analysis of
kernel development, BSP support, and release timing to select the best
possible kernel.org version.
The team continually monitors community kernel
development to look for significant features of interest.
The team does consider back-porting large features if they have a significant advantage.
User or community demand can also trigger a back-port or creation of new
functionality in the Yocto Project baseline kernel during the uprev cycle.
Generally speaking, every new kernel both adds features and introduces new bugs. These consequences are the basic properties of upstream kernel development and are managed by the Yocto Project team's kernel strategy. It is the Yocto Project team's policy to not back-port minor features to the released kernel. They only consider back-porting significant technological jumps - and, that is done after a complete gap analysis. The reason for this policy is that back-porting any small to medium sized change from an evolving kernel can easily create mismatches, incompatibilities and very subtle errors.
These policies result in both a stable and a cutting edge kernel that mixes forward ports of existing features and significant and critical new functionality. Forward porting functionality in the kernels available through the Yocto Project kernel can be thought of as a "micro uprev." The many “micro uprevs” produce a kernel version with a mix of important new mainline, non-mainline, BSP developments and feature integrations. This kernel gives insight into new features and allows focused amounts of testing to be done on the kernel, which prevents surprises when selecting the next major uprev. The quality of these cutting edge kernels is evolving and the kernels are used in leading edge feature and BSP development.
This section describes the architecture of the kernels available through the Yocto Project and provides information on the mechanisms used to achieve that architecture.
As mentioned earlier, a key goal of the Yocto Project is to present the
developer with
a kernel that has a clear and continuous history that is visible to the user.
The architecture and mechanisms used achieve that goal in a manner similar to the
upstream kernel.org.
You can think of a Yocto Project kernel as consisting of a baseline Linux kernel with added features logically structured on top of the baseline. The features are tagged and organized by way of a branching strategy implemented by the source code manager (SCM) Git. For information on Git as applied to the Yocto Project, see the "Git" section in the Yocto Project Development Manual.
The result is that the user has the ability to see the added features and the commits that make up those features. In addition to being able to see added features, the user can also view the history of what made up the baseline kernel.
The following illustration shows the conceptual Yocto Project kernel.
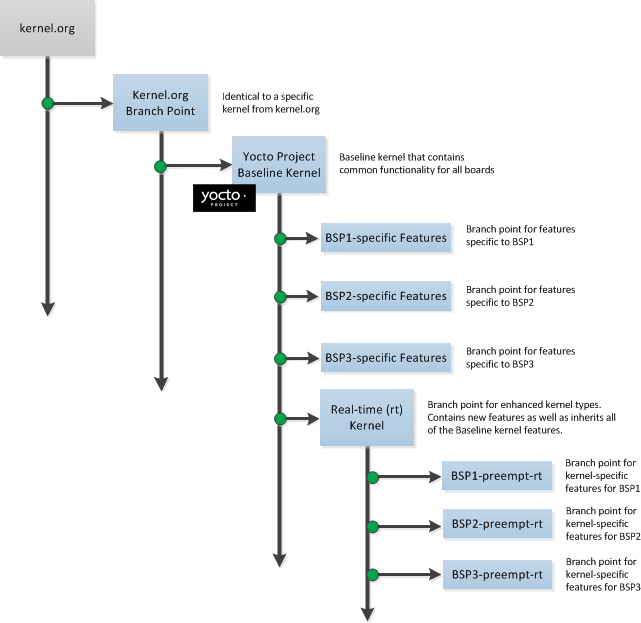 |
In the illustration, the "Kernel.org Branch Point" marks the specific spot (or release) from which the Yocto Project kernel is created. From this point "up" in the tree, features and differences are organized and tagged.
The "Yocto Project Baseline Kernel" contains functionality that is common to every kernel type and BSP that is organized further up the tree. Placing these common features in the tree this way means features do not have to be duplicated along individual branches of the structure.
From the Yocto Project Baseline Kernel, branch points represent specific functionality for individual BSPs as well as real-time kernels. The illustration represents this through three BSP-specific branches and a real-time kernel branch. Each branch represents some unique functionality for the BSP or a real-time kernel.
In this example structure, the real-time kernel branch has common features for all real-time kernels and contains more branches for individual BSP-specific real-time kernels. The illustration shows three branches as an example. Each branch points the way to specific, unique features for a respective real-time kernel as they apply to a given BSP.
The resulting tree structure presents a clear path of markers (or branches) to the developer that, for all practical purposes, is the kernel needed for any given set of requirements.
The Yocto Project team creates kernel branches at points where functionality is no longer shared and thus, needs to be isolated. For example, board-specific incompatibilities would require different functionality and would require a branch to separate the features. Likewise, for specific kernel features, the same branching strategy is used.
This branching strategy results in a tree that has features organized to be specific for particular functionality, single kernel types, or a subset of kernel types. This strategy also results in not having to store the same feature twice internally in the tree. Rather, the kernel team stores the unique differences required to apply the feature onto the kernel type in question.
Note
The Yocto Project team strives to place features in the tree such that they can be shared by all boards and kernel types where possible. However, during development cycles or when large features are merged, the team cannot always follow this practice. In those cases, the team uses isolated branches to merge features.
BSP-specific code additions are handled in a similar manner to kernel-specific additions. Some BSPs only make sense given certain kernel types. So, for these types, the team creates branches off the end of that kernel type for all of the BSPs that are supported on that kernel type. From the perspective of the tools that create the BSP branch, the BSP is really no different than a feature. Consequently, the same branching strategy applies to BSPs as it does to features. So again, rather than store the BSP twice, the team only stores the unique differences for the BSP across the supported multiple kernels.
While this strategy can result in a tree with a significant number of branches, it is
important to realize that from the developer's point of view, there is a linear
path that travels from the baseline kernel.org, through a select
group of features and ends with their BSP-specific commits.
In other words, the divisions of the kernel are transparent and are not relevant
to the developer on a day-to-day basis.
From the developer's perspective, this path is the "master" branch.
The developer does not need to be aware of the existence of any other branches at all.
Of course, there is value in the existence of these branches
in the tree, should a person decide to explore them.
For example, a comparison between two BSPs at either the commit level or at the line-by-line
code diff level is now a trivial operation.
Working with the kernel as a structured tree follows recognized community best practices. In particular, the kernel as shipped with the product, should be considered an "upstream source" and viewed as a series of historical and documented modifications (commits). These modifications represent the development and stabilization done by the Yocto Project kernel development team.
Because commits only change at significant release points in the product life cycle, developers can work on a branch created from the last relevant commit in the shipped Yocto Project kernel. As mentioned previously, the structure is transparent to the developer because the kernel tree is left in this state after cloning and building the kernel.
The Source Code Manager (SCM) is Git.
This SCM is the obvious mechanism for meeting the previously mentioned goals.
Not only is it the SCM for kernel.org but,
Git continues to grow in popularity and supports many different work flows,
front-ends and management techniques.
You can find documentation on Git at http://git-scm.com/documentation. You can also get an introduction to Git as it applies to the Yocto Project in the "Git" section in the Yocto Project Development Manual. These referenced sections overview Git and describe a minimal set of commands that allows you to be functional using Git.
Note
You can use as much, or as little, of what Git has to offer to accomplish what you need for your project. You do not have to be a "Git Master" in order to use it with the Yocto Project.
This section describes construction of the Yocto Project kernel source repositories as accomplished by the Yocto Project team to create kernel repositories. These kernel repositories are found under the heading "Yocto Linux Kernel" at http://git.yoctoproject.org/cgit.cgi and can be shipped as part of a Yocto Project release. The team creates these repositories by compiling and executing the set of feature descriptions for every BSP and feature in the product. Those feature descriptions list all necessary patches, configuration, branching, tagging and feature divisions found in a kernel. Thus, the Yocto Project kernel repository (or tree) is built.
The existence of this tree allows you to access and clone a particular Yocto Project kernel repository and use it to build images based on their configurations and features.
You can find the files used to describe all the valid features and BSPs
in the Yocto Project kernel in any clone of the Yocto Project kernel source repository
Git tree.
For example, the following command clones the Yocto Project baseline kernel that
branched off of linux.org version 3.4:
$ git clone git://git.yoctoproject.org/linux-yocto-3.4
For another example of how to set up a local Git repository of the Yocto Project kernel files, see the "Yocto Project Kernel" bulleted item in the Yocto Project Development Manual.
Once you have cloned the kernel Git repository on your local machine, you can
switch to the meta branch within the repository.
Here is an example that assumes the local Git repository for the kernel is in
a top-level directory named linux-yocto-3.4:
$ cd linux-yocto-3.4
$ git checkout -b meta origin/meta
Once you have checked out and switched to the meta branch,
you can see a snapshot of all the kernel configuration and feature descriptions that are
used to build that particular kernel repository.
These descriptions are in the form of .scc files.
You should realize, however, that browsing your local kernel repository for feature descriptions and patches is not an effective way to determine what is in a particular kernel branch. Instead, you should use Git directly to discover the changes in a branch. Using Git is an efficient and flexible way to inspect changes to the kernel.
Note
Ground up reconstruction of the complete kernel tree is an action only taken by the Yocto Project team during an active development cycle. When you create a clone of the kernel Git repository, you are simply making it efficiently available for building and development.
The following steps describe what happens when the Yocto Project Team constructs the Yocto Project kernel source Git repository (or tree) found at http://git.yoctoproject.org/cgit.cgi given the introduction of a new top-level kernel feature or BSP. These are the actions that effectively create the tree that includes the new feature, patch or BSP:
A top-level kernel feature is passed to the kernel build subsystem. Normally, this feature is a BSP for a particular kernel type.
The file that describes the top-level feature is located by searching these system directories:
The in-tree kernel-cache directories, which are located in
meta/cfg/kernel-cacheAreas pointed to by
SRC_URIstatements found in recipes
For a typical build, the target of the search is a feature description in an
.sccfile whose name follows this format:<bsp_name>-<kernel_type>.sccOnce located, the feature description is either compiled into a simple script of actions, or into an existing equivalent script that is already part of the shipped kernel.
Extra features are appended to the top-level feature description. These features can come from the
KERNEL_FEATURESvariable in recipes.Each extra feature is located, compiled and appended to the script as described in step three.
The script is executed to produce a series of
meta-*directories. These directories are descriptions of all the branches, tags, patches and configurations that need to be applied to the base Git repository to completely create the source (build) branch for the new BSP or feature.The base repository is cloned, and the actions listed in the
meta-*directories are applied to the tree.The Git repository is left with the desired branch checked out and any required branching, patching and tagging has been performed.
The kernel tree is now ready for developer consumption to be locally cloned, configured, and built into a Yocto Project kernel specific to some target hardware.
Note
The generated meta-* directories add to the kernel
as shipped with the Yocto Project release.
Any add-ons and configuration data are applied to the end of an existing branch.
The full repository generation that is found in the
official Yocto Project kernel repositories at
http://git.yoctoproject.org/cgit.cgi
is the combination of all supported boards and configurations.
The technique the Yocto Project team uses is flexible and allows for seamless blending of an immutable history with additional patches specific to a deployment. Any additions to the kernel become an integrated part of the branches.
Once a local Git repository of the Yocto Project kernel exists on a development system, you can consider the compilation phase of kernel development - building a kernel image. Some prerequisites exist that are validated by the build process before compilation starts:
The
SRC_URIpoints to the kernel Git repository.A BSP build branch exists. This branch has the following form:
<kernel_type>/<bsp_name>
The OpenEmbedded build system makes sure these conditions exist before attempting compilation. Other means, however, do exist, such as as bootstrapping a BSP.
Before building a kernel, the build process verifies the tree
and configures the kernel by processing all of the
configuration "fragments" specified by feature descriptions in the .scc
files.
As the features are compiled, associated kernel configuration fragments are noted
and recorded in the meta-* series of directories in their compilation order.
The fragments are migrated, pre-processed and passed to the Linux Kernel
Configuration subsystem (lkc) as raw input in the form
of a .config file.
The lkc uses its own internal dependency constraints to do the final
processing of that information and generates the final .config file
that is used during compilation.
Using the board's architecture and other relevant values from the board's template, kernel compilation is started and a kernel image is produced.
The other thing that you notice once you configure a kernel is that
the build process generates a build tree that is separate from your kernel's local Git
source repository tree.
This build tree has a name that uses the following form, where
${MACHINE} is the metadata name of the machine (BSP) and "kernel_type" is one
of the Yocto Project supported kernel types (e.g. "standard"):
linux-${MACHINE}-<kernel_type>-build
The existing support in the kernel.org tree achieves this
default functionality.
This behavior means that all the generated files for a particular machine or BSP are now in
the build tree directory.
The files include the final .config file, all the .o
files, the .a files, and so forth.
Since each machine or BSP has its own separate
Build Directory
in its own separate branch
of the Git repository, you can easily switch between different builds.
C.1. |
How do I use my own Linux kernel |
Refer to the "Changing the Configuration" section for information. | |
C.2. | How do I create configuration fragments? |
Refer to the "Generating Configuration Files" section for information. | |
C.3. | How do I use my own Linux kernel sources? |
Refer to the "Working With Your Own Sources" section for information. | |
C.4. | How do I install/not-install the kernel image on the rootfs? |
The kernel image (e.g. See the "Using .bbappend Files" section in the Yocto Project Development Manual for information on how to use an append file to override metadata. | |
C.5. | How do I install a specific kernel module? |
Linux kernel modules are packaged individually.
To ensure a specific kernel module is included in an image,
include it in the appropriate machine
These other variables are useful for installing specific modules:
For example, set the following in the
MACHINE_EXTRA_RRECOMMENDS += "kernel-module-ab123"
For more information, see the "Incorporating Out-of-Tree Modules" section. | |
C.6. | How do I change the Linux kernel command line? |
The Linux kernel command line is typically specified in
the machine config using the
APPEND += "printk.time=y initcall_debug debug"
|
 |
Copyright © 2010-2014 Linux Foundation
Permission is granted to copy, distribute and/or modify this document under the terms of the Creative Commons Attribution-Share Alike 2.0 UK: England & Wales as published by Creative Commons.
Note
For the latest version of this manual associated with this Yocto Project release, see the Yocto Project Profiling and Tracing Manual from the Yocto Project website.| Revision History | |
|---|---|
| Revision 1.4 | April 2013 |
| Released with the Yocto Project 1.4 Release. | |
| Revision 1.5 | October 2013 |
| Released with the Yocto Project 1.5 Release. | |
| Revision 1.5.1 | January 2014 |
| Released with the Yocto Project 1.5.1 Release. | |
| Revision 1.5.2 | May 2014 |
| Released with the Yocto Project 1.5.2 Release. | |
Yocto bundles a number of tracing and profiling tools - this 'HOWTO' describes their basic usage and shows by example how to make use of them to examine application and system behavior.
The tools presented are for the most part completely open-ended and have quite good and/or extensive documentation of their own which can be used to solve just about any problem you might come across in Linux. Each section that describes a particular tool has links to that tool's documentation and website.
The purpose of this 'HOWTO' is to present a set of common and generally useful tracing and profiling idioms along with their application (as appropriate) to each tool, in the context of a general-purpose 'drill-down' methodology that can be applied to solving a large number (90%?) of problems. For help with more advanced usages and problems, please see the documentation and/or websites listed for each tool.
The final section of this 'HOWTO' is a collection of real-world examples which we'll be continually adding to as we solve more problems using the tools - feel free to add your own examples to the list!
Most of the tools are available only in 'sdk' images or in images built after adding 'tools-profile' to your local.conf. So, in order to be able to access all of the tools described here, please first build and boot an 'sdk' image e.g.
$ bitbake core-image-sato-sdk
or alternatively by adding 'tools-profile' to the EXTRA_IMAGE_FEATURES line in your local.conf:
EXTRA_IMAGE_FEATURES = "debug-tweaks tools-profile"
If you use the 'tools-profile' method, you don't need to build an sdk image - the tracing and profiling tools will be included in non-sdk images as well e.g.:
$ bitbake core-image-sato
Note
By default, the Yocto build system strips symbols from the binaries it packages, which makes it difficult to use some of the tools.
You can prevent that by putting the following in your local.conf when you build the image:
INHIBIT_PACKAGE_STRIP = "1"
The above setting will noticeably increase the size of your image.
If you've already built a stripped image, you can generate debug packages (xxx-dbg) which you can manually install as needed.
To generate debug info for packages, you can add dbg-pkgs to EXTRA_IMAGE_FEATURES in local.conf. For example:
EXTRA_IMAGE_FEATURES = "debug-tweaks tools-profile dbg-pkgs"
Additionally, in order to generate the right type of debuginfo, we also need to add the following to local.conf:
PACKAGE_DEBUG_SPLIT_STYLE = 'debug-file-directory'
It may seem surprising to see a section covering an 'overall architecture' for what seems to be a random collection of tracing tools that together make up the Linux tracing and profiling space. The fact is, however, that in recent years this seemingly disparate set of tools has started to converge on a 'core' set of underlying mechanisms:
- static tracepoints
- dynamic tracepoints
- kprobes
- uprobes
- the perf_events subsystem
- debugfs
This chapter presents basic usage examples for each of the tracing tools.
The 'perf' tool is the profiling and tracing tool that comes bundled with the Linux kernel.
Don't let the fact that it's part of the kernel fool you into thinking that it's only for tracing and profiling the kernel - you can indeed use it to trace and profile just the kernel, but you can also use it to profile specific applications separately (with or without kernel context), and you can also use it to trace and profile the kernel and all applications on the system simultaneously to gain a system-wide view of what's going on.
In many ways, perf aims to be a superset of all the tracing and profiling tools available in Linux today, including all the other tools covered in this HOWTO. The past couple of years have seen perf subsume a lot of the functionality of those other tools and, at the same time, those other tools have removed large portions of their previous functionality and replaced it with calls to the equivalent functionality now implemented by the perf subsystem. Extrapolation suggests that at some point those other tools will simply become completely redundant and go away; until then, we'll cover those other tools in these pages and in many cases show how the same things can be accomplished in perf and the other tools when it seems useful to do so.
The coverage below details some of the most common ways you'll likely want to apply the tool; full documentation can be found either within the tool itself or in the man pages at perf(1).
For this section, we'll assume you've already performed the basic setup outlined in the General Setup section.
In particular, you'll get the most mileage out of perf if you profile an image built with INHIBIT_PACKAGE_STRIP = "1" in your local.conf.
perf runs on the target system for the most part. You can archive profile data and copy it to the host for analysis, but for the rest of this document we assume you've ssh'ed to the host and will be running the perf commands on the target.
The perf tool is pretty much self-documenting. To remind yourself of the available commands, simply type 'perf', which will show you basic usage along with the available perf subcommands:
root@crownbay:~# perf
usage: perf [--version] [--help] COMMAND [ARGS]
The most commonly used perf commands are:
annotate Read perf.data (created by perf record) and display annotated code
archive Create archive with object files with build-ids found in perf.data file
bench General framework for benchmark suites
buildid-cache Manage build-id cache.
buildid-list List the buildids in a perf.data file
diff Read two perf.data files and display the differential profile
evlist List the event names in a perf.data file
inject Filter to augment the events stream with additional information
kmem Tool to trace/measure kernel memory(slab) properties
kvm Tool to trace/measure kvm guest os
list List all symbolic event types
lock Analyze lock events
probe Define new dynamic tracepoints
record Run a command and record its profile into perf.data
report Read perf.data (created by perf record) and display the profile
sched Tool to trace/measure scheduler properties (latencies)
script Read perf.data (created by perf record) and display trace output
stat Run a command and gather performance counter statistics
test Runs sanity tests.
timechart Tool to visualize total system behavior during a workload
top System profiling tool.
See 'perf help COMMAND' for more information on a specific command.
As a simple test case, we'll profile the 'wget' of a fairly large file, which is a minimally interesting case because it has both file and network I/O aspects, and at least in the case of standard Yocto images, it's implemented as part of busybox, so the methods we use to analyze it can be used in a very similar way to the whole host of supported busybox applets in Yocto.
root@crownbay:~# rm linux-2.6.19.2.tar.bz2; \
wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
The quickest and easiest way to get some basic overall data about what's going on for a particular workload is to profile it using 'perf stat'. 'perf stat' basically profiles using a few default counters and displays the summed counts at the end of the run:
root@crownbay:~# perf stat wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |***************************************************| 41727k 0:00:00 ETA
Performance counter stats for 'wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2':
4597.223902 task-clock # 0.077 CPUs utilized
23568 context-switches # 0.005 M/sec
68 CPU-migrations # 0.015 K/sec
241 page-faults # 0.052 K/sec
3045817293 cycles # 0.663 GHz
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
858909167 instructions # 0.28 insns per cycle
165441165 branches # 35.987 M/sec
19550329 branch-misses # 11.82% of all branches
59.836627620 seconds time elapsed
Many times such a simple-minded test doesn't yield much of interest, but sometimes it does (see Real-world Yocto bug (slow loop-mounted write speed)).
Also, note that 'perf stat' isn't restricted to a fixed set of counters - basically any event listed in the output of 'perf list' can be tallied by 'perf stat'. For example, suppose we wanted to see a summary of all the events related to kernel memory allocation/freeing along with cache hits and misses:
root@crownbay:~# perf stat -e kmem:* -e cache-references -e cache-misses wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |***************************************************| 41727k 0:00:00 ETA
Performance counter stats for 'wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2':
5566 kmem:kmalloc
125517 kmem:kmem_cache_alloc
0 kmem:kmalloc_node
0 kmem:kmem_cache_alloc_node
34401 kmem:kfree
69920 kmem:kmem_cache_free
133 kmem:mm_page_free
41 kmem:mm_page_free_batched
11502 kmem:mm_page_alloc
11375 kmem:mm_page_alloc_zone_locked
0 kmem:mm_page_pcpu_drain
0 kmem:mm_page_alloc_extfrag
66848602 cache-references
2917740 cache-misses # 4.365 % of all cache refs
44.831023415 seconds time elapsed
So 'perf stat' gives us a nice easy way to get a quick overview of what might be happening for a set of events, but normally we'd need a little more detail in order to understand what's going on in a way that we can act on in a useful way.
To dive down into a next level of detail, we can use 'perf record'/'perf report' which will collect profiling data and present it to use using an interactive text-based UI (or simply as text if we specify --stdio to 'perf report').
As our first attempt at profiling this workload, we'll simply run 'perf record', handing it the workload we want to profile (everything after 'perf record' and any perf options we hand it - here none - will be executed in a new shell). perf collects samples until the process exits and records them in a file named 'perf.data' in the current working directory.
root@crownbay:~# perf record wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |************************************************| 41727k 0:00:00 ETA
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.176 MB perf.data (~7700 samples) ]
To see the results in a 'text-based UI' (tui), simply run 'perf report', which will read the perf.data file in the current working directory and display the results in an interactive UI:
root@crownbay:~# perf report
 |
The above screenshot displays a 'flat' profile, one entry for each 'bucket' corresponding to the functions that were profiled during the profiling run, ordered from the most popular to the least (perf has options to sort in various orders and keys as well as display entries only above a certain threshold and so on - see the perf documentation for details). Note that this includes both userspace functions (entries containing a [.]) and kernel functions accounted to the process (entries containing a [k]). (perf has command-line modifiers that can be used to restrict the profiling to kernel or userspace, among others).
Notice also that the above report shows an entry for 'busybox', which is the executable that implements 'wget' in Yocto, but that instead of a useful function name in that entry, it displays a not-so-friendly hex value instead. The steps below will show how to fix that problem.
Before we do that, however, let's try running a different profile, one which shows something a little more interesting. The only difference between the new profile and the previous one is that we'll add the -g option, which will record not just the address of a sampled function, but the entire callchain to the sampled function as well:
root@crownbay:~# perf record -g wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |************************************************| 41727k 0:00:00 ETA
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0.652 MB perf.data (~28476 samples) ]
root@crownbay:~# perf report
 |
Using the callgraph view, we can actually see not only which functions took the most time, but we can also see a summary of how those functions were called and learn something about how the program interacts with the kernel in the process.
Notice that each entry in the above screenshot now contains a '+' on the left-hand side. This means that we can expand the entry and drill down into the callchains that feed into that entry. Pressing 'enter' on any one of them will expand the callchain (you can also press 'E' to expand them all at the same time or 'C' to collapse them all).
In the screenshot above, we've toggled the __copy_to_user_ll() entry and several subnodes all the way down. This lets us see which callchains contributed to the profiled __copy_to_user_ll() function which contributed 1.77% to the total profile.
As a bit of background explanation for these callchains, think about what happens at a high level when you run wget to get a file out on the network. Basically what happens is that the data comes into the kernel via the network connection (socket) and is passed to the userspace program 'wget' (which is actually a part of busybox, but that's not important for now), which takes the buffers the kernel passes to it and writes it to a disk file to save it.
The part of this process that we're looking at in the above call stacks is the part where the kernel passes the data it's read from the socket down to wget i.e. a copy-to-user.
Notice also that here there's also a case where the hex value is displayed in the callstack, here in the expanded sys_clock_gettime() function. Later we'll see it resolve to a userspace function call in busybox.
 |
The above screenshot shows the other half of the journey for the data - from the wget program's userspace buffers to disk. To get the buffers to disk, the wget program issues a write(2), which does a copy-from-user to the kernel, which then takes care via some circuitous path (probably also present somewhere in the profile data), to get it safely to disk.
Now that we've seen the basic layout of the profile data and the basics of how to extract useful information out of it, let's get back to the task at hand and see if we can get some basic idea about where the time is spent in the program we're profiling, wget. Remember that wget is actually implemented as an applet in busybox, so while the process name is 'wget', the executable we're actually interested in is busybox. So let's expand the first entry containing busybox:
 |
Again, before we expanded we saw that the function was labeled with a hex value instead of a symbol as with most of the kernel entries. Expanding the busybox entry doesn't make it any better.
The problem is that perf can't find the symbol information for the busybox binary, which is actually stripped out by the Yocto build system.
One way around that is to put the following in your local.conf when you build the image:
INHIBIT_PACKAGE_STRIP = "1"
However, we already have an image with the binaries stripped, so what can we do to get perf to resolve the symbols? Basically we need to install the debuginfo for the busybox package.
To generate the debug info for the packages in the image, we can add dbg-pkgs to EXTRA_IMAGE_FEATURES in local.conf. For example:
EXTRA_IMAGE_FEATURES = "debug-tweaks tools-profile dbg-pkgs"
Additionally, in order to generate the type of debuginfo that perf understands, we also need to add the following to local.conf:
PACKAGE_DEBUG_SPLIT_STYLE = 'debug-file-directory'
Once we've done that, we can install the debuginfo for busybox. The debug packages once built can be found in build/tmp/deploy/rpm/* on the host system. Find the busybox-dbg-...rpm file and copy it to the target. For example:
[trz@empanada core2]$ scp /home/trz/yocto/crownbay-tracing-dbg/build/tmp/deploy/rpm/core2/busybox-dbg-1.20.2-r2.core2.rpm root@192.168.1.31:
root@192.168.1.31's password:
busybox-dbg-1.20.2-r2.core2.rpm 100% 1826KB 1.8MB/s 00:01
Now install the debug rpm on the target:
root@crownbay:~# rpm -i busybox-dbg-1.20.2-r2.core2.rpm
Now that the debuginfo is installed, we see that the busybox entries now display their functions symbolically:
 |
If we expand one of the entries and press 'enter' on a leaf node, we're presented with a menu of actions we can take to get more information related to that entry:
 |
One of these actions allows us to show a view that displays a busybox-centric view of the profiled functions (in this case we've also expanded all the nodes using the 'E' key):
 |
Finally, we can see that now that the busybox debuginfo is installed, the previously unresolved symbol in the sys_clock_gettime() entry mentioned previously is now resolved, and shows that the sys_clock_gettime system call that was the source of 6.75% of the copy-to-user overhead was initiated by the handle_input() busybox function:
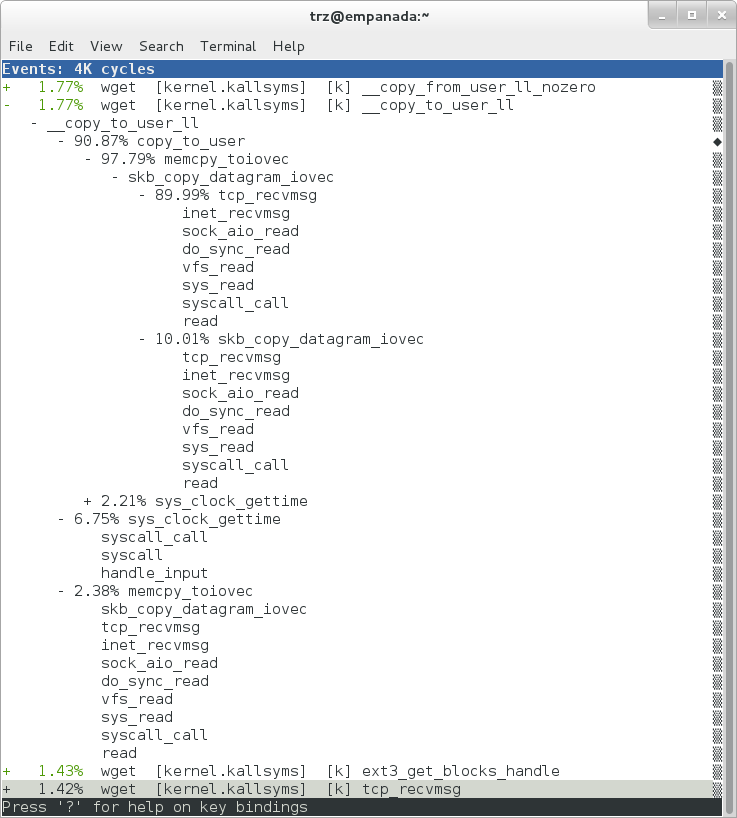 |
At the lowest level of detail, we can dive down to the assembly level and see which instructions caused the most overhead in a function. Pressing 'enter' on the 'udhcpc_main' function, we're again presented with a menu:
 |
Selecting 'Annotate udhcpc_main', we get a detailed listing of percentages by instruction for the udhcpc_main function. From the display, we can see that over 50% of the time spent in this function is taken up by a couple tests and the move of a constant (1) to a register:
 |
As a segue into tracing, let's try another profile using a different counter, something other than the default 'cycles'.
The tracing and profiling infrastructure in Linux has become unified in a way that allows us to use the same tool with a completely different set of counters, not just the standard hardware counters that traditional tools have had to restrict themselves to (of course the traditional tools can also make use of the expanded possibilities now available to them, and in some cases have, as mentioned previously).
We can get a list of the available events that can be used to profile a workload via 'perf list':
root@crownbay:~# perf list
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
stalled-cycles-frontend OR idle-cycles-frontend [Hardware event]
stalled-cycles-backend OR idle-cycles-backend [Hardware event]
instructions [Hardware event]
cache-references [Hardware event]
cache-misses [Hardware event]
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
ref-cycles [Hardware event]
cpu-clock [Software event]
task-clock [Software event]
page-faults OR faults [Software event]
minor-faults [Software event]
major-faults [Software event]
context-switches OR cs [Software event]
cpu-migrations OR migrations [Software event]
alignment-faults [Software event]
emulation-faults [Software event]
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-icache-loads [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
.
.
.
rNNN [Raw hardware event descriptor]
cpu/t1=v1[,t2=v2,t3 ...]/modifier [Raw hardware event descriptor]
(see 'perf list --help' on how to encode it)
mem:<addr>[:access] [Hardware breakpoint]
sunrpc:rpc_call_status [Tracepoint event]
sunrpc:rpc_bind_status [Tracepoint event]
sunrpc:rpc_connect_status [Tracepoint event]
sunrpc:rpc_task_begin [Tracepoint event]
skb:kfree_skb [Tracepoint event]
skb:consume_skb [Tracepoint event]
skb:skb_copy_datagram_iovec [Tracepoint event]
net:net_dev_xmit [Tracepoint event]
net:net_dev_queue [Tracepoint event]
net:netif_receive_skb [Tracepoint event]
net:netif_rx [Tracepoint event]
napi:napi_poll [Tracepoint event]
sock:sock_rcvqueue_full [Tracepoint event]
sock:sock_exceed_buf_limit [Tracepoint event]
udp:udp_fail_queue_rcv_skb [Tracepoint event]
hda:hda_send_cmd [Tracepoint event]
hda:hda_get_response [Tracepoint event]
hda:hda_bus_reset [Tracepoint event]
scsi:scsi_dispatch_cmd_start [Tracepoint event]
scsi:scsi_dispatch_cmd_error [Tracepoint event]
scsi:scsi_eh_wakeup [Tracepoint event]
drm:drm_vblank_event [Tracepoint event]
drm:drm_vblank_event_queued [Tracepoint event]
drm:drm_vblank_event_delivered [Tracepoint event]
random:mix_pool_bytes [Tracepoint event]
random:mix_pool_bytes_nolock [Tracepoint event]
random:credit_entropy_bits [Tracepoint event]
gpio:gpio_direction [Tracepoint event]
gpio:gpio_value [Tracepoint event]
block:block_rq_abort [Tracepoint event]
block:block_rq_requeue [Tracepoint event]
block:block_rq_issue [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_backmerge [Tracepoint event]
.
.
writeback:writeback_wake_thread [Tracepoint event]
writeback:writeback_wake_forker_thread [Tracepoint event]
writeback:writeback_bdi_register [Tracepoint event]
.
.
writeback:writeback_single_inode_requeue [Tracepoint event]
writeback:writeback_single_inode [Tracepoint event]
kmem:kmalloc [Tracepoint event]
kmem:kmem_cache_alloc [Tracepoint event]
kmem:mm_page_alloc [Tracepoint event]
kmem:mm_page_alloc_zone_locked [Tracepoint event]
kmem:mm_page_pcpu_drain [Tracepoint event]
kmem:mm_page_alloc_extfrag [Tracepoint event]
vmscan:mm_vmscan_kswapd_sleep [Tracepoint event]
vmscan:mm_vmscan_kswapd_wake [Tracepoint event]
vmscan:mm_vmscan_wakeup_kswapd [Tracepoint event]
vmscan:mm_vmscan_direct_reclaim_begin [Tracepoint event]
.
.
module:module_get [Tracepoint event]
module:module_put [Tracepoint event]
module:module_request [Tracepoint event]
sched:sched_kthread_stop [Tracepoint event]
sched:sched_wakeup [Tracepoint event]
sched:sched_wakeup_new [Tracepoint event]
sched:sched_process_fork [Tracepoint event]
sched:sched_process_exec [Tracepoint event]
sched:sched_stat_runtime [Tracepoint event]
rcu:rcu_utilization [Tracepoint event]
workqueue:workqueue_queue_work [Tracepoint event]
workqueue:workqueue_execute_end [Tracepoint event]
signal:signal_generate [Tracepoint event]
signal:signal_deliver [Tracepoint event]
timer:timer_init [Tracepoint event]
timer:timer_start [Tracepoint event]
timer:hrtimer_cancel [Tracepoint event]
timer:itimer_state [Tracepoint event]
timer:itimer_expire [Tracepoint event]
irq:irq_handler_entry [Tracepoint event]
irq:irq_handler_exit [Tracepoint event]
irq:softirq_entry [Tracepoint event]
irq:softirq_exit [Tracepoint event]
irq:softirq_raise [Tracepoint event]
printk:console [Tracepoint event]
task:task_newtask [Tracepoint event]
task:task_rename [Tracepoint event]
syscalls:sys_enter_socketcall [Tracepoint event]
syscalls:sys_exit_socketcall [Tracepoint event]
.
.
.
syscalls:sys_enter_unshare [Tracepoint event]
syscalls:sys_exit_unshare [Tracepoint event]
raw_syscalls:sys_enter [Tracepoint event]
raw_syscalls:sys_exit [Tracepoint event]
Only a subset of these would be of interest to us when looking at this workload, so let's choose the most likely subsystems (identified by the string before the colon in the Tracepoint events) and do a 'perf stat' run using only those wildcarded subsystems:
root@crownbay:~# perf stat -e skb:* -e net:* -e napi:* -e sched:* -e workqueue:* -e irq:* -e syscalls:* wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
Performance counter stats for 'wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2':
23323 skb:kfree_skb
0 skb:consume_skb
49897 skb:skb_copy_datagram_iovec
6217 net:net_dev_xmit
6217 net:net_dev_queue
7962 net:netif_receive_skb
2 net:netif_rx
8340 napi:napi_poll
0 sched:sched_kthread_stop
0 sched:sched_kthread_stop_ret
3749 sched:sched_wakeup
0 sched:sched_wakeup_new
0 sched:sched_switch
29 sched:sched_migrate_task
0 sched:sched_process_free
1 sched:sched_process_exit
0 sched:sched_wait_task
0 sched:sched_process_wait
0 sched:sched_process_fork
1 sched:sched_process_exec
0 sched:sched_stat_wait
2106519415641 sched:sched_stat_sleep
0 sched:sched_stat_iowait
147453613 sched:sched_stat_blocked
12903026955 sched:sched_stat_runtime
0 sched:sched_pi_setprio
3574 workqueue:workqueue_queue_work
3574 workqueue:workqueue_activate_work
0 workqueue:workqueue_execute_start
0 workqueue:workqueue_execute_end
16631 irq:irq_handler_entry
16631 irq:irq_handler_exit
28521 irq:softirq_entry
28521 irq:softirq_exit
28728 irq:softirq_raise
1 syscalls:sys_enter_sendmmsg
1 syscalls:sys_exit_sendmmsg
0 syscalls:sys_enter_recvmmsg
0 syscalls:sys_exit_recvmmsg
14 syscalls:sys_enter_socketcall
14 syscalls:sys_exit_socketcall
.
.
.
16965 syscalls:sys_enter_read
16965 syscalls:sys_exit_read
12854 syscalls:sys_enter_write
12854 syscalls:sys_exit_write
.
.
.
58.029710972 seconds time elapsed
Let's pick one of these tracepoints and tell perf to do a profile using it as the sampling event:
root@crownbay:~# perf record -g -e sched:sched_wakeup wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
 |
The screenshot above shows the results of running a profile using sched:sched_switch tracepoint, which shows the relative costs of various paths to sched_wakeup (note that sched_wakeup is the name of the tracepoint - it's actually defined just inside ttwu_do_wakeup(), which accounts for the function name actually displayed in the profile:
/*
* Mark the task runnable and perform wakeup-preemption.
*/
static void
ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
trace_sched_wakeup(p, true);
.
.
.
}
A couple of the more interesting callchains are expanded and displayed above, basically some network receive paths that presumably end up waking up wget (busybox) when network data is ready.
Note that because tracepoints are normally used for tracing, the default sampling period for tracepoints is 1 i.e. for tracepoints perf will sample on every event occurrence (this can be changed using the -c option). This is in contrast to hardware counters such as for example the default 'cycles' hardware counter used for normal profiling, where sampling periods are much higher (in the thousands) because profiling should have as low an overhead as possible and sampling on every cycle would be prohibitively expensive.
Profiling is a great tool for solving many problems or for getting a high-level view of what's going on with a workload or across the system. It is however by definition an approximation, as suggested by the most prominent word associated with it, 'sampling'. On the one hand, it allows a representative picture of what's going on in the system to be cheaply taken, but on the other hand, that cheapness limits its utility when that data suggests a need to 'dive down' more deeply to discover what's really going on. In such cases, the only way to see what's really going on is to be able to look at (or summarize more intelligently) the individual steps that go into the higher-level behavior exposed by the coarse-grained profiling data.
As a concrete example, we can trace all the events we think might be applicable to our workload:
root@crownbay:~# perf record -g -e skb:* -e net:* -e napi:* -e sched:sched_switch -e sched:sched_wakeup -e irq:*
-e syscalls:sys_enter_read -e syscalls:sys_exit_read -e syscalls:sys_enter_write -e syscalls:sys_exit_write
wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
We can look at the raw trace output using 'perf script' with no arguments:
root@crownbay:~# perf script
perf 1262 [000] 11624.857082: sys_exit_read: 0x0
perf 1262 [000] 11624.857193: sched_wakeup: comm=migration/0 pid=6 prio=0 success=1 target_cpu=000
wget 1262 [001] 11624.858021: softirq_raise: vec=1 [action=TIMER]
wget 1262 [001] 11624.858074: softirq_entry: vec=1 [action=TIMER]
wget 1262 [001] 11624.858081: softirq_exit: vec=1 [action=TIMER]
wget 1262 [001] 11624.858166: sys_enter_read: fd: 0x0003, buf: 0xbf82c940, count: 0x0200
wget 1262 [001] 11624.858177: sys_exit_read: 0x200
wget 1262 [001] 11624.858878: kfree_skb: skbaddr=0xeb248d80 protocol=0 location=0xc15a5308
wget 1262 [001] 11624.858945: kfree_skb: skbaddr=0xeb248000 protocol=0 location=0xc15a5308
wget 1262 [001] 11624.859020: softirq_raise: vec=1 [action=TIMER]
wget 1262 [001] 11624.859076: softirq_entry: vec=1 [action=TIMER]
wget 1262 [001] 11624.859083: softirq_exit: vec=1 [action=TIMER]
wget 1262 [001] 11624.859167: sys_enter_read: fd: 0x0003, buf: 0xb7720000, count: 0x0400
wget 1262 [001] 11624.859192: sys_exit_read: 0x1d7
wget 1262 [001] 11624.859228: sys_enter_read: fd: 0x0003, buf: 0xb7720000, count: 0x0400
wget 1262 [001] 11624.859233: sys_exit_read: 0x0
wget 1262 [001] 11624.859573: sys_enter_read: fd: 0x0003, buf: 0xbf82c580, count: 0x0200
wget 1262 [001] 11624.859584: sys_exit_read: 0x200
wget 1262 [001] 11624.859864: sys_enter_read: fd: 0x0003, buf: 0xb7720000, count: 0x0400
wget 1262 [001] 11624.859888: sys_exit_read: 0x400
wget 1262 [001] 11624.859935: sys_enter_read: fd: 0x0003, buf: 0xb7720000, count: 0x0400
wget 1262 [001] 11624.859944: sys_exit_read: 0x400
This gives us a detailed timestamped sequence of events that occurred within the workload with respect to those events.
In many ways, profiling can be viewed as a subset of tracing - theoretically, if you have a set of trace events that's sufficient to capture all the important aspects of a workload, you can derive any of the results or views that a profiling run can.
Another aspect of traditional profiling is that while powerful in many ways, it's limited by the granularity of the underlying data. Profiling tools offer various ways of sorting and presenting the sample data, which make it much more useful and amenable to user experimentation, but in the end it can't be used in an open-ended way to extract data that just isn't present as a consequence of the fact that conceptually, most of it has been thrown away.
Full-blown detailed tracing data does however offer the opportunity to manipulate and present the information collected during a tracing run in an infinite variety of ways.
Another way to look at it is that there are only so many ways that the 'primitive' counters can be used on their own to generate interesting output; to get anything more complicated than simple counts requires some amount of additional logic, which is typically very specific to the problem at hand. For example, if we wanted to make use of a 'counter' that maps to the value of the time difference between when a process was scheduled to run on a processor and the time it actually ran, we wouldn't expect such a counter to exist on its own, but we could derive one called say 'wakeup_latency' and use it to extract a useful view of that metric from trace data. Likewise, we really can't figure out from standard profiling tools how much data every process on the system reads and writes, along with how many of those reads and writes fail completely. If we have sufficient trace data, however, we could with the right tools easily extract and present that information, but we'd need something other than pre-canned profiling tools to do that.
Luckily, there is a general-purpose way to handle such needs, called 'programming languages'. Making programming languages easily available to apply to such problems given the specific format of data is called a 'programming language binding' for that data and language. Perf supports two programming language bindings, one for Python and one for Perl.
Now that we have the trace data in perf.data, we can use 'perf script -g' to generate a skeleton script with handlers for the read/write entry/exit events we recorded:
root@crownbay:~# perf script -g python
generated Python script: perf-script.py
The skeleton script simply creates a python function for each event type in the perf.data file. The body of each function simply prints the event name along with its parameters. For example:
def net__netif_rx(event_name, context, common_cpu,
common_secs, common_nsecs, common_pid, common_comm,
skbaddr, len, name):
print_header(event_name, common_cpu, common_secs, common_nsecs,
common_pid, common_comm)
print "skbaddr=%u, len=%u, name=%s\n" % (skbaddr, len, name),
We can run that script directly to print all of the events contained in the perf.data file:
root@crownbay:~# perf script -s perf-script.py
in trace_begin
syscalls__sys_exit_read 0 11624.857082795 1262 perf nr=3, ret=0
sched__sched_wakeup 0 11624.857193498 1262 perf comm=migration/0, pid=6, prio=0, success=1, target_cpu=0
irq__softirq_raise 1 11624.858021635 1262 wget vec=TIMER
irq__softirq_entry 1 11624.858074075 1262 wget vec=TIMER
irq__softirq_exit 1 11624.858081389 1262 wget vec=TIMER
syscalls__sys_enter_read 1 11624.858166434 1262 wget nr=3, fd=3, buf=3213019456, count=512
syscalls__sys_exit_read 1 11624.858177924 1262 wget nr=3, ret=512
skb__kfree_skb 1 11624.858878188 1262 wget skbaddr=3945041280, location=3243922184, protocol=0
skb__kfree_skb 1 11624.858945608 1262 wget skbaddr=3945037824, location=3243922184, protocol=0
irq__softirq_raise 1 11624.859020942 1262 wget vec=TIMER
irq__softirq_entry 1 11624.859076935 1262 wget vec=TIMER
irq__softirq_exit 1 11624.859083469 1262 wget vec=TIMER
syscalls__sys_enter_read 1 11624.859167565 1262 wget nr=3, fd=3, buf=3077701632, count=1024
syscalls__sys_exit_read 1 11624.859192533 1262 wget nr=3, ret=471
syscalls__sys_enter_read 1 11624.859228072 1262 wget nr=3, fd=3, buf=3077701632, count=1024
syscalls__sys_exit_read 1 11624.859233707 1262 wget nr=3, ret=0
syscalls__sys_enter_read 1 11624.859573008 1262 wget nr=3, fd=3, buf=3213018496, count=512
syscalls__sys_exit_read 1 11624.859584818 1262 wget nr=3, ret=512
syscalls__sys_enter_read 1 11624.859864562 1262 wget nr=3, fd=3, buf=3077701632, count=1024
syscalls__sys_exit_read 1 11624.859888770 1262 wget nr=3, ret=1024
syscalls__sys_enter_read 1 11624.859935140 1262 wget nr=3, fd=3, buf=3077701632, count=1024
syscalls__sys_exit_read 1 11624.859944032 1262 wget nr=3, ret=1024
That in itself isn't very useful; after all, we can accomplish pretty much the same thing by simply running 'perf script' without arguments in the same directory as the perf.data file.
We can however replace the print statements in the generated function bodies with whatever we want, and thereby make it infinitely more useful.
As a simple example, let's just replace the print statements in the function bodies with a simple function that does nothing but increment a per-event count. When the program is run against a perf.data file, each time a particular event is encountered, a tally is incremented for that event. For example:
def net__netif_rx(event_name, context, common_cpu,
common_secs, common_nsecs, common_pid, common_comm,
skbaddr, len, name):
inc_counts(event_name)
Each event handler function in the generated code is modified to do this. For convenience, we define a common function called inc_counts() that each handler calls; inc_counts() simply tallies a count for each event using the 'counts' hash, which is a specialized hash function that does Perl-like autovivification, a capability that's extremely useful for kinds of multi-level aggregation commonly used in processing traces (see perf's documentation on the Python language binding for details):
counts = autodict()
def inc_counts(event_name):
try:
counts[event_name] += 1
except TypeError:
counts[event_name] = 1
Finally, at the end of the trace processing run, we want to print the result of all the per-event tallies. For that, we use the special 'trace_end()' function:
def trace_end():
for event_name, count in counts.iteritems():
print "%-40s %10s\n" % (event_name, count)
The end result is a summary of all the events recorded in the trace:
skb__skb_copy_datagram_iovec 13148
irq__softirq_entry 4796
irq__irq_handler_exit 3805
irq__softirq_exit 4795
syscalls__sys_enter_write 8990
net__net_dev_xmit 652
skb__kfree_skb 4047
sched__sched_wakeup 1155
irq__irq_handler_entry 3804
irq__softirq_raise 4799
net__net_dev_queue 652
syscalls__sys_enter_read 17599
net__netif_receive_skb 1743
syscalls__sys_exit_read 17598
net__netif_rx 2
napi__napi_poll 1877
syscalls__sys_exit_write 8990
Note that this is pretty much exactly the same information we get from 'perf stat', which goes a little way to support the idea mentioned previously that given the right kind of trace data, higher-level profiling-type summaries can be derived from it.
Documentation on using the 'perf script' python binding.
The examples so far have focused on tracing a particular program or workload - in other words, every profiling run has specified the program to profile in the command-line e.g. 'perf record wget ...'.
It's also possible, and more interesting in many cases, to run a system-wide profile or trace while running the workload in a separate shell.
To do system-wide profiling or tracing, you typically use the -a flag to 'perf record'.
To demonstrate this, open up one window and start the profile using the -a flag (press Ctrl-C to stop tracing):
root@crownbay:~# perf record -g -a
^C[ perf record: Woken up 6 times to write data ]
[ perf record: Captured and wrote 1.400 MB perf.data (~61172 samples) ]
In another window, run the wget test:
root@crownbay:~# wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |*******************************| 41727k 0:00:00 ETA
Here we see entries not only for our wget load, but for other processes running on the system as well:
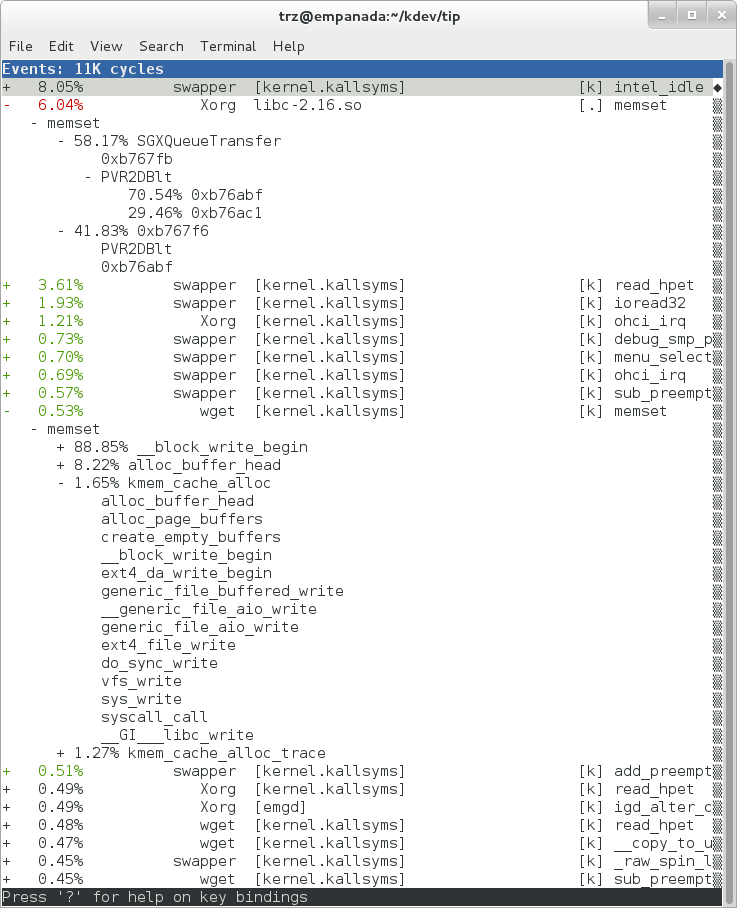 |
In the snapshot above, we can see callchains that originate in libc, and a callchain from Xorg that demonstrates that we're using a proprietary X driver in userspace (notice the presence of 'PVR' and some other unresolvable symbols in the expanded Xorg callchain).
Note also that we have both kernel and userspace entries in the above snapshot. We can also tell perf to focus on userspace but providing a modifier, in this case 'u', to the 'cycles' hardware counter when we record a profile:
root@crownbay:~# perf record -g -a -e cycles:u
^C[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0.376 MB perf.data (~16443 samples) ]
 |
Notice in the screenshot above, we see only userspace entries ([.])
Finally, we can press 'enter' on a leaf node and select the 'Zoom into DSO' menu item to show only entries associated with a specific DSO. In the screenshot below, we've zoomed into the 'libc' DSO which shows all the entries associated with the libc-xxx.so DSO.
 |
We can also use the system-wide -a switch to do system-wide tracing. Here we'll trace a couple of scheduler events:
root@crownbay:~# perf record -a -e sched:sched_switch -e sched:sched_wakeup
^C[ perf record: Woken up 38 times to write data ]
[ perf record: Captured and wrote 9.780 MB perf.data (~427299 samples) ]
We can look at the raw output using 'perf script' with no arguments:
root@crownbay:~# perf script
perf 1383 [001] 6171.460045: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
perf 1383 [001] 6171.460066: sched_switch: prev_comm=perf prev_pid=1383 prev_prio=120 prev_state=R+ ==> next_comm=kworker/1:1 next_pid=21 next_prio=120
kworker/1:1 21 [001] 6171.460093: sched_switch: prev_comm=kworker/1:1 prev_pid=21 prev_prio=120 prev_state=S ==> next_comm=perf next_pid=1383 next_prio=120
swapper 0 [000] 6171.468063: sched_wakeup: comm=kworker/0:3 pid=1209 prio=120 success=1 target_cpu=000
swapper 0 [000] 6171.468107: sched_switch: prev_comm=swapper/0 prev_pid=0 prev_prio=120 prev_state=R ==> next_comm=kworker/0:3 next_pid=1209 next_prio=120
kworker/0:3 1209 [000] 6171.468143: sched_switch: prev_comm=kworker/0:3 prev_pid=1209 prev_prio=120 prev_state=S ==> next_comm=swapper/0 next_pid=0 next_prio=120
perf 1383 [001] 6171.470039: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
perf 1383 [001] 6171.470058: sched_switch: prev_comm=perf prev_pid=1383 prev_prio=120 prev_state=R+ ==> next_comm=kworker/1:1 next_pid=21 next_prio=120
kworker/1:1 21 [001] 6171.470082: sched_switch: prev_comm=kworker/1:1 prev_pid=21 prev_prio=120 prev_state=S ==> next_comm=perf next_pid=1383 next_prio=120
perf 1383 [001] 6171.480035: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
Notice that there are a lot of events that don't really have anything to do with what we're interested in, namely events that schedule 'perf' itself in and out or that wake perf up. We can get rid of those by using the '--filter' option - for each event we specify using -e, we can add a --filter after that to filter out trace events that contain fields with specific values:
root@crownbay:~# perf record -a -e sched:sched_switch --filter 'next_comm != perf && prev_comm != perf' -e sched:sched_wakeup --filter 'comm != perf'
^C[ perf record: Woken up 38 times to write data ]
[ perf record: Captured and wrote 9.688 MB perf.data (~423279 samples) ]
root@crownbay:~# perf script
swapper 0 [000] 7932.162180: sched_switch: prev_comm=swapper/0 prev_pid=0 prev_prio=120 prev_state=R ==> next_comm=kworker/0:3 next_pid=1209 next_prio=120
kworker/0:3 1209 [000] 7932.162236: sched_switch: prev_comm=kworker/0:3 prev_pid=1209 prev_prio=120 prev_state=S ==> next_comm=swapper/0 next_pid=0 next_prio=120
perf 1407 [001] 7932.170048: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
perf 1407 [001] 7932.180044: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
perf 1407 [001] 7932.190038: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
perf 1407 [001] 7932.200044: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
perf 1407 [001] 7932.210044: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
perf 1407 [001] 7932.220044: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
swapper 0 [001] 7932.230111: sched_wakeup: comm=kworker/1:1 pid=21 prio=120 success=1 target_cpu=001
swapper 0 [001] 7932.230146: sched_switch: prev_comm=swapper/1 prev_pid=0 prev_prio=120 prev_state=R ==> next_comm=kworker/1:1 next_pid=21 next_prio=120
kworker/1:1 21 [001] 7932.230205: sched_switch: prev_comm=kworker/1:1 prev_pid=21 prev_prio=120 prev_state=S ==> next_comm=swapper/1 next_pid=0 next_prio=120
swapper 0 [000] 7932.326109: sched_wakeup: comm=kworker/0:3 pid=1209 prio=120 success=1 target_cpu=000
swapper 0 [000] 7932.326171: sched_switch: prev_comm=swapper/0 prev_pid=0 prev_prio=120 prev_state=R ==> next_comm=kworker/0:3 next_pid=1209 next_prio=120
kworker/0:3 1209 [000] 7932.326214: sched_switch: prev_comm=kworker/0:3 prev_pid=1209 prev_prio=120 prev_state=S ==> next_comm=swapper/0 next_pid=0 next_prio=120
In this case, we've filtered out all events that have 'perf' in their 'comm' or 'comm_prev' or 'comm_next' fields. Notice that there are still events recorded for perf, but notice that those events don't have values of 'perf' for the filtered fields. To completely filter out anything from perf will require a bit more work, but for the purpose of demonstrating how to use filters, it's close enough.
perf isn't restricted to the fixed set of static tracepoints listed by 'perf list'. Users can also add their own 'dynamic' tracepoints anywhere in the kernel. For instance, suppose we want to define our own tracepoint on do_fork(). We can do that using the 'perf probe' perf subcommand:
root@crownbay:~# perf probe do_fork
Added new event:
probe:do_fork (on do_fork)
You can now use it in all perf tools, such as:
perf record -e probe:do_fork -aR sleep 1
Adding a new tracepoint via 'perf probe' results in an event with all the expected files and format in /sys/kernel/debug/tracing/events, just the same as for static tracepoints (as discussed in more detail in the trace events subsystem section:
root@crownbay:/sys/kernel/debug/tracing/events/probe/do_fork# ls -al
drwxr-xr-x 2 root root 0 Oct 28 11:42 .
drwxr-xr-x 3 root root 0 Oct 28 11:42 ..
-rw-r--r-- 1 root root 0 Oct 28 11:42 enable
-rw-r--r-- 1 root root 0 Oct 28 11:42 filter
-r--r--r-- 1 root root 0 Oct 28 11:42 format
-r--r--r-- 1 root root 0 Oct 28 11:42 id
root@crownbay:/sys/kernel/debug/tracing/events/probe/do_fork# cat format
name: do_fork
ID: 944
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int common_padding; offset:8; size:4; signed:1;
field:unsigned long __probe_ip; offset:12; size:4; signed:0;
print fmt: "(%lx)", REC->__probe_ip
We can list all dynamic tracepoints currently in existence:
root@crownbay:~# perf probe -l
probe:do_fork (on do_fork)
probe:schedule (on schedule)
Let's record system-wide ('sleep 30' is a trick for recording system-wide but basically do nothing and then wake up after 30 seconds):
root@crownbay:~# perf record -g -a -e probe:do_fork sleep 30
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.087 MB perf.data (~3812 samples) ]
Using 'perf script' we can see each do_fork event that fired:
root@crownbay:~# perf script
# ========
# captured on: Sun Oct 28 11:55:18 2012
# hostname : crownbay
# os release : 3.4.11-yocto-standard
# perf version : 3.4.11
# arch : i686
# nrcpus online : 2
# nrcpus avail : 2
# cpudesc : Intel(R) Atom(TM) CPU E660 @ 1.30GHz
# cpuid : GenuineIntel,6,38,1
# total memory : 1017184 kB
# cmdline : /usr/bin/perf record -g -a -e probe:do_fork sleep 30
# event : name = probe:do_fork, type = 2, config = 0x3b0, config1 = 0x0, config2 = 0x0, excl_usr = 0, excl_kern
= 0, id = { 5, 6 }
# HEADER_CPU_TOPOLOGY info available, use -I to display
# ========
#
matchbox-deskto 1197 [001] 34211.378318: do_fork: (c1028460)
matchbox-deskto 1295 [001] 34211.380388: do_fork: (c1028460)
pcmanfm 1296 [000] 34211.632350: do_fork: (c1028460)
pcmanfm 1296 [000] 34211.639917: do_fork: (c1028460)
matchbox-deskto 1197 [001] 34217.541603: do_fork: (c1028460)
matchbox-deskto 1299 [001] 34217.543584: do_fork: (c1028460)
gthumb 1300 [001] 34217.697451: do_fork: (c1028460)
gthumb 1300 [001] 34219.085734: do_fork: (c1028460)
gthumb 1300 [000] 34219.121351: do_fork: (c1028460)
gthumb 1300 [001] 34219.264551: do_fork: (c1028460)
pcmanfm 1296 [000] 34219.590380: do_fork: (c1028460)
matchbox-deskto 1197 [001] 34224.955965: do_fork: (c1028460)
matchbox-deskto 1306 [001] 34224.957972: do_fork: (c1028460)
matchbox-termin 1307 [000] 34225.038214: do_fork: (c1028460)
matchbox-termin 1307 [001] 34225.044218: do_fork: (c1028460)
matchbox-termin 1307 [000] 34225.046442: do_fork: (c1028460)
matchbox-deskto 1197 [001] 34237.112138: do_fork: (c1028460)
matchbox-deskto 1311 [001] 34237.114106: do_fork: (c1028460)
gaku 1312 [000] 34237.202388: do_fork: (c1028460)
And using 'perf report' on the same file, we can see the callgraphs from starting a few programs during those 30 seconds:
 |
Online versions of the man pages for the commands discussed in this section can be found here:
The 'perf stat' manpage.
The 'perf probe' manpage.
Documentation on using the 'perf script' python binding.
The top-level perf(1) manpage.
Normally, you should be able to invoke the man pages via perf itself e.g. 'perf help' or 'perf help record'.
However, by default Yocto doesn't install man pages, but perf invokes the man pages for most help functionality. This is a bug and is being addressed by a Yocto bug: Bug 3388 - perf: enable man pages for basic 'help' functionality.
The man pages in text form, along with some other files, such as a set of examples, can be found in the 'perf' directory of the kernel tree:
tools/perf/Documentation
There's also a nice perf tutorial on the perf wiki that goes into more detail than we do here in certain areas: Perf Tutorial
'ftrace' literally refers to the 'ftrace function tracer' but in reality this encompasses a number of related tracers along with the infrastructure that they all make use of.
For this section, we'll assume you've already performed the basic setup outlined in the General Setup section.
ftrace, trace-cmd, and kernelshark run on the target system, and are ready to go out-of-the-box - no additional setup is necessary. For the rest of this section we assume you've ssh'ed to the host and will be running ftrace on the target. kernelshark is a GUI application and if you use the '-X' option to ssh you can have the kernelshark GUI run on the target but display remotely on the host if you want.
'ftrace' essentially refers to everything included in the /tracing directory of the mounted debugfs filesystem (Yocto follows the standard convention and mounts it at /sys/kernel/debug). Here's a listing of all the files found in /sys/kernel/debug/tracing on a Yocto system:
root@sugarbay:/sys/kernel/debug/tracing# ls
README kprobe_events trace
available_events kprobe_profile trace_clock
available_filter_functions options trace_marker
available_tracers per_cpu trace_options
buffer_size_kb printk_formats trace_pipe
buffer_total_size_kb saved_cmdlines tracing_cpumask
current_tracer set_event tracing_enabled
dyn_ftrace_total_info set_ftrace_filter tracing_on
enabled_functions set_ftrace_notrace tracing_thresh
events set_ftrace_pid
free_buffer set_graph_function
The files listed above are used for various purposes - some relate directly to the tracers themselves, others are used to set tracing options, and yet others actually contain the tracing output when a tracer is in effect. Some of the functions can be guessed from their names, others need explanation; in any case, we'll cover some of the files we see here below but for an explanation of the others, please see the ftrace documentation.
We'll start by looking at some of the available built-in tracers.
cat'ing the 'available_tracers' file lists the set of available tracers:
root@sugarbay:/sys/kernel/debug/tracing# cat available_tracers
blk function_graph function nop
The 'current_tracer' file contains the tracer currently in effect:
root@sugarbay:/sys/kernel/debug/tracing# cat current_tracer
nop
The above listing of current_tracer shows that the 'nop' tracer is in effect, which is just another way of saying that there's actually no tracer currently in effect.
echo'ing one of the available_tracers into current_tracer makes the specified tracer the current tracer:
root@sugarbay:/sys/kernel/debug/tracing# echo function > current_tracer
root@sugarbay:/sys/kernel/debug/tracing# cat current_tracer
function
The above sets the current tracer to be the 'function tracer'. This tracer traces every function call in the kernel and makes it available as the contents of the 'trace' file. Reading the 'trace' file lists the currently buffered function calls that have been traced by the function tracer:
root@sugarbay:/sys/kernel/debug/tracing# cat trace | less
# tracer: function
#
# entries-in-buffer/entries-written: 310629/766471 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
<idle>-0 [004] d..1 470.867169: ktime_get_real <-intel_idle
<idle>-0 [004] d..1 470.867170: getnstimeofday <-ktime_get_real
<idle>-0 [004] d..1 470.867171: ns_to_timeval <-intel_idle
<idle>-0 [004] d..1 470.867171: ns_to_timespec <-ns_to_timeval
<idle>-0 [004] d..1 470.867172: smp_apic_timer_interrupt <-apic_timer_interrupt
<idle>-0 [004] d..1 470.867172: native_apic_mem_write <-smp_apic_timer_interrupt
<idle>-0 [004] d..1 470.867172: irq_enter <-smp_apic_timer_interrupt
<idle>-0 [004] d..1 470.867172: rcu_irq_enter <-irq_enter
<idle>-0 [004] d..1 470.867173: rcu_idle_exit_common.isra.33 <-rcu_irq_enter
<idle>-0 [004] d..1 470.867173: local_bh_disable <-irq_enter
<idle>-0 [004] d..1 470.867173: add_preempt_count <-local_bh_disable
<idle>-0 [004] d.s1 470.867174: tick_check_idle <-irq_enter
<idle>-0 [004] d.s1 470.867174: tick_check_oneshot_broadcast <-tick_check_idle
<idle>-0 [004] d.s1 470.867174: ktime_get <-tick_check_idle
<idle>-0 [004] d.s1 470.867174: tick_nohz_stop_idle <-tick_check_idle
<idle>-0 [004] d.s1 470.867175: update_ts_time_stats <-tick_nohz_stop_idle
<idle>-0 [004] d.s1 470.867175: nr_iowait_cpu <-update_ts_time_stats
<idle>-0 [004] d.s1 470.867175: tick_do_update_jiffies64 <-tick_check_idle
<idle>-0 [004] d.s1 470.867175: _raw_spin_lock <-tick_do_update_jiffies64
<idle>-0 [004] d.s1 470.867176: add_preempt_count <-_raw_spin_lock
<idle>-0 [004] d.s2 470.867176: do_timer <-tick_do_update_jiffies64
<idle>-0 [004] d.s2 470.867176: _raw_spin_lock <-do_timer
<idle>-0 [004] d.s2 470.867176: add_preempt_count <-_raw_spin_lock
<idle>-0 [004] d.s3 470.867177: ntp_tick_length <-do_timer
<idle>-0 [004] d.s3 470.867177: _raw_spin_lock_irqsave <-ntp_tick_length
.
.
.
Each line in the trace above shows what was happening in the kernel on a given cpu, to the level of detail of function calls. Each entry shows the function called, followed by its caller (after the arrow).
The function tracer gives you an extremely detailed idea of what the kernel was doing at the point in time the trace was taken, and is a great way to learn about how the kernel code works in a dynamic sense.
It is a little more difficult to follow the call chains than it needs to be - luckily there's a variant of the function tracer that displays the callchains explicitly, called the 'function_graph' tracer:
root@sugarbay:/sys/kernel/debug/tracing# echo function_graph > current_tracer
root@sugarbay:/sys/kernel/debug/tracing# cat trace | less
tracer: function_graph
CPU DURATION FUNCTION CALLS
| | | | | | |
7) 0.046 us | pick_next_task_fair();
7) 0.043 us | pick_next_task_stop();
7) 0.042 us | pick_next_task_rt();
7) 0.032 us | pick_next_task_fair();
7) 0.030 us | pick_next_task_idle();
7) | _raw_spin_unlock_irq() {
7) 0.033 us | sub_preempt_count();
7) 0.258 us | }
7) 0.032 us | sub_preempt_count();
7) + 13.341 us | } /* __schedule */
7) 0.095 us | } /* sub_preempt_count */
7) | schedule() {
7) | __schedule() {
7) 0.060 us | add_preempt_count();
7) 0.044 us | rcu_note_context_switch();
7) | _raw_spin_lock_irq() {
7) 0.033 us | add_preempt_count();
7) 0.247 us | }
7) | idle_balance() {
7) | _raw_spin_unlock() {
7) 0.031 us | sub_preempt_count();
7) 0.246 us | }
7) | update_shares() {
7) 0.030 us | __rcu_read_lock();
7) 0.029 us | __rcu_read_unlock();
7) 0.484 us | }
7) 0.030 us | __rcu_read_lock();
7) | load_balance() {
7) | find_busiest_group() {
7) 0.031 us | idle_cpu();
7) 0.029 us | idle_cpu();
7) 0.035 us | idle_cpu();
7) 0.906 us | }
7) 1.141 us | }
7) 0.022 us | msecs_to_jiffies();
7) | load_balance() {
7) | find_busiest_group() {
7) 0.031 us | idle_cpu();
.
.
.
4) 0.062 us | msecs_to_jiffies();
4) 0.062 us | __rcu_read_unlock();
4) | _raw_spin_lock() {
4) 0.073 us | add_preempt_count();
4) 0.562 us | }
4) + 17.452 us | }
4) 0.108 us | put_prev_task_fair();
4) 0.102 us | pick_next_task_fair();
4) 0.084 us | pick_next_task_stop();
4) 0.075 us | pick_next_task_rt();
4) 0.062 us | pick_next_task_fair();
4) 0.066 us | pick_next_task_idle();
------------------------------------------
4) kworker-74 => <idle>-0
------------------------------------------
4) | finish_task_switch() {
4) | _raw_spin_unlock_irq() {
4) 0.100 us | sub_preempt_count();
4) 0.582 us | }
4) 1.105 us | }
4) 0.088 us | sub_preempt_count();
4) ! 100.066 us | }
.
.
.
3) | sys_ioctl() {
3) 0.083 us | fget_light();
3) | security_file_ioctl() {
3) 0.066 us | cap_file_ioctl();
3) 0.562 us | }
3) | do_vfs_ioctl() {
3) | drm_ioctl() {
3) 0.075 us | drm_ut_debug_printk();
3) | i915_gem_pwrite_ioctl() {
3) | i915_mutex_lock_interruptible() {
3) 0.070 us | mutex_lock_interruptible();
3) 0.570 us | }
3) | drm_gem_object_lookup() {
3) | _raw_spin_lock() {
3) 0.080 us | add_preempt_count();
3) 0.620 us | }
3) | _raw_spin_unlock() {
3) 0.085 us | sub_preempt_count();
3) 0.562 us | }
3) 2.149 us | }
3) 0.133 us | i915_gem_object_pin();
3) | i915_gem_object_set_to_gtt_domain() {
3) 0.065 us | i915_gem_object_flush_gpu_write_domain();
3) 0.065 us | i915_gem_object_wait_rendering();
3) 0.062 us | i915_gem_object_flush_cpu_write_domain();
3) 1.612 us | }
3) | i915_gem_object_put_fence() {
3) 0.097 us | i915_gem_object_flush_fence.constprop.36();
3) 0.645 us | }
3) 0.070 us | add_preempt_count();
3) 0.070 us | sub_preempt_count();
3) 0.073 us | i915_gem_object_unpin();
3) 0.068 us | mutex_unlock();
3) 9.924 us | }
3) + 11.236 us | }
3) + 11.770 us | }
3) + 13.784 us | }
3) | sys_ioctl() {
As you can see, the function_graph display is much easier to follow. Also note that in addition to the function calls and associated braces, other events such as scheduler events are displayed in context. In fact, you can freely include any tracepoint available in the trace events subsystem described in the next section by simply enabling those events, and they'll appear in context in the function graph display. Quite a powerful tool for understanding kernel dynamics.
Also notice that there are various annotations on the left hand side of the display. For example if the total time it took for a given function to execute is above a certain threshold, an exclamation point or plus sign appears on the left hand side. Please see the ftrace documentation for details on all these fields.
One especially important directory contained within the /sys/kernel/debug/tracing directory is the 'events' subdirectory, which contains representations of every tracepoint in the system. Listing out the contents of the 'events' subdirectory, we see mainly another set of subdirectories:
root@sugarbay:/sys/kernel/debug/tracing# cd events
root@sugarbay:/sys/kernel/debug/tracing/events# ls -al
drwxr-xr-x 38 root root 0 Nov 14 23:19 .
drwxr-xr-x 5 root root 0 Nov 14 23:19 ..
drwxr-xr-x 19 root root 0 Nov 14 23:19 block
drwxr-xr-x 32 root root 0 Nov 14 23:19 btrfs
drwxr-xr-x 5 root root 0 Nov 14 23:19 drm
-rw-r--r-- 1 root root 0 Nov 14 23:19 enable
drwxr-xr-x 40 root root 0 Nov 14 23:19 ext3
drwxr-xr-x 79 root root 0 Nov 14 23:19 ext4
drwxr-xr-x 14 root root 0 Nov 14 23:19 ftrace
drwxr-xr-x 8 root root 0 Nov 14 23:19 hda
-r--r--r-- 1 root root 0 Nov 14 23:19 header_event
-r--r--r-- 1 root root 0 Nov 14 23:19 header_page
drwxr-xr-x 25 root root 0 Nov 14 23:19 i915
drwxr-xr-x 7 root root 0 Nov 14 23:19 irq
drwxr-xr-x 12 root root 0 Nov 14 23:19 jbd
drwxr-xr-x 14 root root 0 Nov 14 23:19 jbd2
drwxr-xr-x 14 root root 0 Nov 14 23:19 kmem
drwxr-xr-x 7 root root 0 Nov 14 23:19 module
drwxr-xr-x 3 root root 0 Nov 14 23:19 napi
drwxr-xr-x 6 root root 0 Nov 14 23:19 net
drwxr-xr-x 3 root root 0 Nov 14 23:19 oom
drwxr-xr-x 12 root root 0 Nov 14 23:19 power
drwxr-xr-x 3 root root 0 Nov 14 23:19 printk
drwxr-xr-x 8 root root 0 Nov 14 23:19 random
drwxr-xr-x 4 root root 0 Nov 14 23:19 raw_syscalls
drwxr-xr-x 3 root root 0 Nov 14 23:19 rcu
drwxr-xr-x 6 root root 0 Nov 14 23:19 rpm
drwxr-xr-x 20 root root 0 Nov 14 23:19 sched
drwxr-xr-x 7 root root 0 Nov 14 23:19 scsi
drwxr-xr-x 4 root root 0 Nov 14 23:19 signal
drwxr-xr-x 5 root root 0 Nov 14 23:19 skb
drwxr-xr-x 4 root root 0 Nov 14 23:19 sock
drwxr-xr-x 10 root root 0 Nov 14 23:19 sunrpc
drwxr-xr-x 538 root root 0 Nov 14 23:19 syscalls
drwxr-xr-x 4 root root 0 Nov 14 23:19 task
drwxr-xr-x 14 root root 0 Nov 14 23:19 timer
drwxr-xr-x 3 root root 0 Nov 14 23:19 udp
drwxr-xr-x 21 root root 0 Nov 14 23:19 vmscan
drwxr-xr-x 3 root root 0 Nov 14 23:19 vsyscall
drwxr-xr-x 6 root root 0 Nov 14 23:19 workqueue
drwxr-xr-x 26 root root 0 Nov 14 23:19 writeback
Each one of these subdirectories corresponds to a 'subsystem' and contains yet again more subdirectories, each one of those finally corresponding to a tracepoint. For example, here are the contents of the 'kmem' subsystem:
root@sugarbay:/sys/kernel/debug/tracing/events# cd kmem
root@sugarbay:/sys/kernel/debug/tracing/events/kmem# ls -al
drwxr-xr-x 14 root root 0 Nov 14 23:19 .
drwxr-xr-x 38 root root 0 Nov 14 23:19 ..
-rw-r--r-- 1 root root 0 Nov 14 23:19 enable
-rw-r--r-- 1 root root 0 Nov 14 23:19 filter
drwxr-xr-x 2 root root 0 Nov 14 23:19 kfree
drwxr-xr-x 2 root root 0 Nov 14 23:19 kmalloc
drwxr-xr-x 2 root root 0 Nov 14 23:19 kmalloc_node
drwxr-xr-x 2 root root 0 Nov 14 23:19 kmem_cache_alloc
drwxr-xr-x 2 root root 0 Nov 14 23:19 kmem_cache_alloc_node
drwxr-xr-x 2 root root 0 Nov 14 23:19 kmem_cache_free
drwxr-xr-x 2 root root 0 Nov 14 23:19 mm_page_alloc
drwxr-xr-x 2 root root 0 Nov 14 23:19 mm_page_alloc_extfrag
drwxr-xr-x 2 root root 0 Nov 14 23:19 mm_page_alloc_zone_locked
drwxr-xr-x 2 root root 0 Nov 14 23:19 mm_page_free
drwxr-xr-x 2 root root 0 Nov 14 23:19 mm_page_free_batched
drwxr-xr-x 2 root root 0 Nov 14 23:19 mm_page_pcpu_drain
Let's see what's inside the subdirectory for a specific tracepoint, in this case the one for kmalloc:
root@sugarbay:/sys/kernel/debug/tracing/events/kmem# cd kmalloc
root@sugarbay:/sys/kernel/debug/tracing/events/kmem/kmalloc# ls -al
drwxr-xr-x 2 root root 0 Nov 14 23:19 .
drwxr-xr-x 14 root root 0 Nov 14 23:19 ..
-rw-r--r-- 1 root root 0 Nov 14 23:19 enable
-rw-r--r-- 1 root root 0 Nov 14 23:19 filter
-r--r--r-- 1 root root 0 Nov 14 23:19 format
-r--r--r-- 1 root root 0 Nov 14 23:19 id
The 'format' file for the tracepoint describes the event in memory, which is used by the various tracing tools that now make use of these tracepoint to parse the event and make sense of it, along with a 'print fmt' field that allows tools like ftrace to display the event as text. Here's what the format of the kmalloc event looks like:
root@sugarbay:/sys/kernel/debug/tracing/events/kmem/kmalloc# cat format
name: kmalloc
ID: 313
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int common_padding; offset:8; size:4; signed:1;
field:unsigned long call_site; offset:16; size:8; signed:0;
field:const void * ptr; offset:24; size:8; signed:0;
field:size_t bytes_req; offset:32; size:8; signed:0;
field:size_t bytes_alloc; offset:40; size:8; signed:0;
field:gfp_t gfp_flags; offset:48; size:4; signed:0;
print fmt: "call_site=%lx ptr=%p bytes_req=%zu bytes_alloc=%zu gfp_flags=%s", REC->call_site, REC->ptr, REC->bytes_req, REC->bytes_alloc,
(REC->gfp_flags) ? __print_flags(REC->gfp_flags, "|", {(unsigned long)(((( gfp_t)0x10u) | (( gfp_t)0x40u) | (( gfp_t)0x80u) | ((
gfp_t)0x20000u) | (( gfp_t)0x02u) | (( gfp_t)0x08u)) | (( gfp_t)0x4000u) | (( gfp_t)0x10000u) | (( gfp_t)0x1000u) | (( gfp_t)0x200u) | ((
gfp_t)0x400000u)), "GFP_TRANSHUGE"}, {(unsigned long)((( gfp_t)0x10u) | (( gfp_t)0x40u) | (( gfp_t)0x80u) | (( gfp_t)0x20000u) | ((
gfp_t)0x02u) | (( gfp_t)0x08u)), "GFP_HIGHUSER_MOVABLE"}, {(unsigned long)((( gfp_t)0x10u) | (( gfp_t)0x40u) | (( gfp_t)0x80u) | ((
gfp_t)0x20000u) | (( gfp_t)0x02u)), "GFP_HIGHUSER"}, {(unsigned long)((( gfp_t)0x10u) | (( gfp_t)0x40u) | (( gfp_t)0x80u) | ((
gfp_t)0x20000u)), "GFP_USER"}, {(unsigned long)((( gfp_t)0x10u) | (( gfp_t)0x40u) | (( gfp_t)0x80u) | (( gfp_t)0x80000u)), GFP_TEMPORARY"},
{(unsigned long)((( gfp_t)0x10u) | (( gfp_t)0x40u) | (( gfp_t)0x80u)), "GFP_KERNEL"}, {(unsigned long)((( gfp_t)0x10u) | (( gfp_t)0x40u)),
"GFP_NOFS"}, {(unsigned long)((( gfp_t)0x20u)), "GFP_ATOMIC"}, {(unsigned long)((( gfp_t)0x10u)), "GFP_NOIO"}, {(unsigned long)((
gfp_t)0x20u), "GFP_HIGH"}, {(unsigned long)(( gfp_t)0x10u), "GFP_WAIT"}, {(unsigned long)(( gfp_t)0x40u), "GFP_IO"}, {(unsigned long)((
gfp_t)0x100u), "GFP_COLD"}, {(unsigned long)(( gfp_t)0x200u), "GFP_NOWARN"}, {(unsigned long)(( gfp_t)0x400u), "GFP_REPEAT"}, {(unsigned
long)(( gfp_t)0x800u), "GFP_NOFAIL"}, {(unsigned long)(( gfp_t)0x1000u), "GFP_NORETRY"}, {(unsigned long)(( gfp_t)0x4000u), "GFP_COMP"},
{(unsigned long)(( gfp_t)0x8000u), "GFP_ZERO"}, {(unsigned long)(( gfp_t)0x10000u), "GFP_NOMEMALLOC"}, {(unsigned long)(( gfp_t)0x20000u),
"GFP_HARDWALL"}, {(unsigned long)(( gfp_t)0x40000u), "GFP_THISNODE"}, {(unsigned long)(( gfp_t)0x80000u), "GFP_RECLAIMABLE"}, {(unsigned
long)(( gfp_t)0x08u), "GFP_MOVABLE"}, {(unsigned long)(( gfp_t)0), "GFP_NOTRACK"}, {(unsigned long)(( gfp_t)0x400000u), "GFP_NO_KSWAPD"},
{(unsigned long)(( gfp_t)0x800000u), "GFP_OTHER_NODE"} ) : "GFP_NOWAIT"
The 'enable' file in the tracepoint directory is what allows the user (or tools such as trace-cmd) to actually turn the tracepoint on and off. When enabled, the corresponding tracepoint will start appearing in the ftrace 'trace' file described previously. For example, this turns on the kmalloc tracepoint:
root@sugarbay:/sys/kernel/debug/tracing/events/kmem/kmalloc# echo 1 > enable
At the moment, we're not interested in the function tracer or some other tracer that might be in effect, so we first turn it off, but if we do that, we still need to turn tracing on in order to see the events in the output buffer:
root@sugarbay:/sys/kernel/debug/tracing# echo nop > current_tracer
root@sugarbay:/sys/kernel/debug/tracing# echo 1 > tracing_on
Now, if we look at the the 'trace' file, we see nothing but the kmalloc events we just turned on:
root@sugarbay:/sys/kernel/debug/tracing# cat trace | less
# tracer: nop
#
# entries-in-buffer/entries-written: 1897/1897 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
dropbear-1465 [000] ...1 18154.620753: kmalloc: call_site=ffffffff816650d4 ptr=ffff8800729c3000 bytes_req=2048 bytes_alloc=2048 gfp_flags=GFP_KERNEL
<idle>-0 [000] ..s3 18154.621640: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d555800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
<idle>-0 [000] ..s3 18154.621656: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d555800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
matchbox-termin-1361 [001] ...1 18154.755472: kmalloc: call_site=ffffffff81614050 ptr=ffff88006d5f0e00 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_KERNEL|GFP_REPEAT
Xorg-1264 [002] ...1 18154.755581: kmalloc: call_site=ffffffff8141abe8 ptr=ffff8800734f4cc0 bytes_req=168 bytes_alloc=192 gfp_flags=GFP_KERNEL|GFP_NOWARN|GFP_NORETRY
Xorg-1264 [002] ...1 18154.755583: kmalloc: call_site=ffffffff814192a3 ptr=ffff88001f822520 bytes_req=24 bytes_alloc=32 gfp_flags=GFP_KERNEL|GFP_ZERO
Xorg-1264 [002] ...1 18154.755589: kmalloc: call_site=ffffffff81419edb ptr=ffff8800721a2f00 bytes_req=64 bytes_alloc=64 gfp_flags=GFP_KERNEL|GFP_ZERO
matchbox-termin-1361 [001] ...1 18155.354594: kmalloc: call_site=ffffffff81614050 ptr=ffff88006db35400 bytes_req=576 bytes_alloc=1024 gfp_flags=GFP_KERNEL|GFP_REPEAT
Xorg-1264 [002] ...1 18155.354703: kmalloc: call_site=ffffffff8141abe8 ptr=ffff8800734f4cc0 bytes_req=168 bytes_alloc=192 gfp_flags=GFP_KERNEL|GFP_NOWARN|GFP_NORETRY
Xorg-1264 [002] ...1 18155.354705: kmalloc: call_site=ffffffff814192a3 ptr=ffff88001f822520 bytes_req=24 bytes_alloc=32 gfp_flags=GFP_KERNEL|GFP_ZERO
Xorg-1264 [002] ...1 18155.354711: kmalloc: call_site=ffffffff81419edb ptr=ffff8800721a2f00 bytes_req=64 bytes_alloc=64 gfp_flags=GFP_KERNEL|GFP_ZERO
<idle>-0 [000] ..s3 18155.673319: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d555800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
dropbear-1465 [000] ...1 18155.673525: kmalloc: call_site=ffffffff816650d4 ptr=ffff8800729c3000 bytes_req=2048 bytes_alloc=2048 gfp_flags=GFP_KERNEL
<idle>-0 [000] ..s3 18155.674821: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d554800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
<idle>-0 [000] ..s3 18155.793014: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d554800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
dropbear-1465 [000] ...1 18155.793219: kmalloc: call_site=ffffffff816650d4 ptr=ffff8800729c3000 bytes_req=2048 bytes_alloc=2048 gfp_flags=GFP_KERNEL
<idle>-0 [000] ..s3 18155.794147: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d555800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
<idle>-0 [000] ..s3 18155.936705: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d555800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
dropbear-1465 [000] ...1 18155.936910: kmalloc: call_site=ffffffff816650d4 ptr=ffff8800729c3000 bytes_req=2048 bytes_alloc=2048 gfp_flags=GFP_KERNEL
<idle>-0 [000] ..s3 18155.937869: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d554800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
matchbox-termin-1361 [001] ...1 18155.953667: kmalloc: call_site=ffffffff81614050 ptr=ffff88006d5f2000 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_KERNEL|GFP_REPEAT
Xorg-1264 [002] ...1 18155.953775: kmalloc: call_site=ffffffff8141abe8 ptr=ffff8800734f4cc0 bytes_req=168 bytes_alloc=192 gfp_flags=GFP_KERNEL|GFP_NOWARN|GFP_NORETRY
Xorg-1264 [002] ...1 18155.953777: kmalloc: call_site=ffffffff814192a3 ptr=ffff88001f822520 bytes_req=24 bytes_alloc=32 gfp_flags=GFP_KERNEL|GFP_ZERO
Xorg-1264 [002] ...1 18155.953783: kmalloc: call_site=ffffffff81419edb ptr=ffff8800721a2f00 bytes_req=64 bytes_alloc=64 gfp_flags=GFP_KERNEL|GFP_ZERO
<idle>-0 [000] ..s3 18156.176053: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d554800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
dropbear-1465 [000] ...1 18156.176257: kmalloc: call_site=ffffffff816650d4 ptr=ffff8800729c3000 bytes_req=2048 bytes_alloc=2048 gfp_flags=GFP_KERNEL
<idle>-0 [000] ..s3 18156.177717: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d555800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
<idle>-0 [000] ..s3 18156.399229: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d555800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
dropbear-1465 [000] ...1 18156.399434: kmalloc: call_site=ffffffff816650d4 ptr=ffff8800729c3000 bytes_http://rostedt.homelinux.com/kernelshark/req=2048 bytes_alloc=2048 gfp_flags=GFP_KERNEL
<idle>-0 [000] ..s3 18156.400660: kmalloc: call_site=ffffffff81619b36 ptr=ffff88006d554800 bytes_req=512 bytes_alloc=512 gfp_flags=GFP_ATOMIC
matchbox-termin-1361 [001] ...1 18156.552800: kmalloc: call_site=ffffffff81614050 ptr=ffff88006db34800 bytes_req=576 bytes_alloc=1024 gfp_flags=GFP_KERNEL|GFP_REPEAT
To again disable the kmalloc event, we need to send 0 to the enable file:
root@sugarbay:/sys/kernel/debug/tracing/events/kmem/kmalloc# echo 0 > enable
You can enable any number of events or complete subsystems (by using the 'enable' file in the subsystem directory) and get an arbitrarily fine-grained idea of what's going on in the system by enabling as many of the appropriate tracepoints as applicable.
A number of the tools described in this HOWTO do just that, including trace-cmd and kernelshark in the next section.
trace-cmd is essentially an extensive command-line 'wrapper' interface that hides the details of all the individual files in /sys/kernel/debug/tracing, allowing users to specify specific particular events within the /sys/kernel/debug/tracing/events/ subdirectory and to collect traces and avoid having to deal with those details directly.
As yet another layer on top of that, kernelshark provides a GUI that allows users to start and stop traces and specify sets of events using an intuitive interface, and view the output as both trace events and as a per-CPU graphical display. It directly uses 'trace-cmd' as the plumbing that accomplishes all that underneath the covers (and actually displays the trace-cmd command it uses, as we'll see).
To start a trace using kernelshark, first start kernelshark:
root@sugarbay:~# kernelshark
Then bring up the 'Capture' dialog by choosing from the kernelshark menu:
Capture | Record
That will display the following dialog, which allows you to choose one or more events (or even one or more complete subsystems) to trace:
 |
Note that these are exactly the same sets of events described in the previous trace events subsystem section, and in fact is where trace-cmd gets them for kernelshark.
In the above screenshot, we've decided to explore the graphics subsystem a bit and so have chosen to trace all the tracepoints contained within the 'i915' and 'drm' subsystems.
After doing that, we can start and stop the trace using the 'Run' and 'Stop' button on the lower right corner of the dialog (the same button will turn into the 'Stop' button after the trace has started):
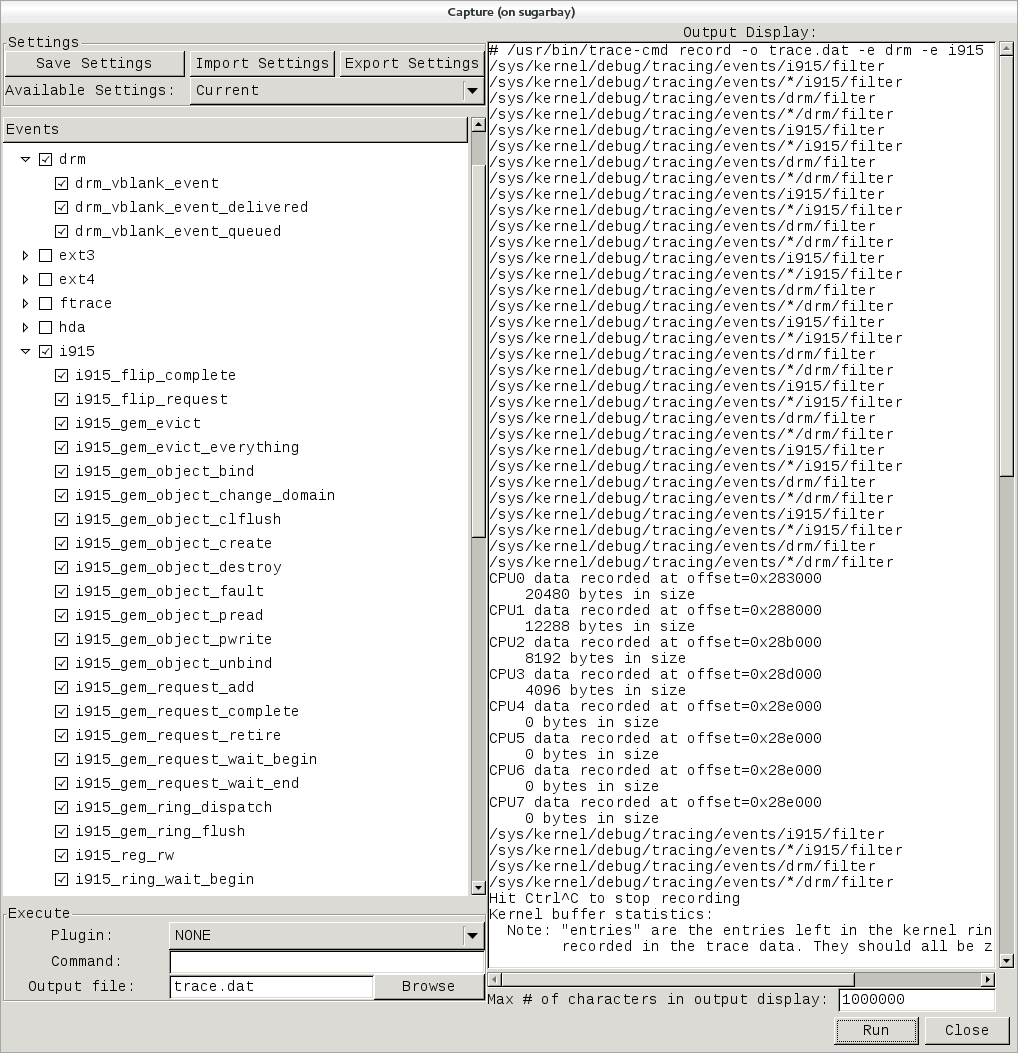 |
Notice that the right-hand pane shows the exact trace-cmd command-line that's used to run the trace, along with the results of the trace-cmd run.
Once the 'Stop' button is pressed, the graphical view magically fills up with a colorful per-cpu display of the trace data, along with the detailed event listing below that:
 |
Here's another example, this time a display resulting from tracing 'all events':
 |
The tool is pretty self-explanatory, but for more detailed information on navigating through the data, see the kernelshark website.
The documentation for ftrace can be found in the kernel Documentation directory:
Documentation/trace/ftrace.txt
The documentation for the trace event subsystem can also be found in the kernel Documentation directory:
Documentation/trace/events.txt
There is a nice series of articles on using ftrace and trace-cmd at LWN:
There's more detailed documentation kernelshark usage here: KernelShark
An amusing yet useful README (a tracing mini-HOWTO) can be found in /sys/kernel/debug/tracing/README.
SystemTap is a system-wide script-based tracing and profiling tool.
SystemTap scripts are C-like programs that are executed in the kernel to gather/print/aggregate data extracted from the context they end up being invoked under.
For example, this probe from the SystemTap tutorial simply prints a line every time any process on the system open()s a file. For each line, it prints the executable name of the program that opened the file, along with its PID, and the name of the file it opened (or tried to open), which it extracts from the open syscall's argstr.
probe syscall.open
{
printf ("%s(%d) open (%s)\n", execname(), pid(), argstr)
}
probe timer.ms(4000) # after 4 seconds
{
exit ()
}
Normally, to execute this probe, you'd simply install systemtap on the system you want to probe, and directly run the probe on that system e.g. assuming the name of the file containing the above text is trace_open.stp:
# stap trace_open.stp
What systemtap does under the covers to run this probe is 1) parse and convert the probe to an equivalent 'C' form, 2) compile the 'C' form into a kernel module, 3) insert the module into the kernel, which arms it, and 4) collect the data generated by the probe and display it to the user.
In order to accomplish steps 1 and 2, the 'stap' program needs access to the kernel build system that produced the kernel that the probed system is running. In the case of a typical embedded system (the 'target'), the kernel build system unfortunately isn't typically part of the image running on the target. It is normally available on the 'host' system that produced the target image however; in such cases, steps 1 and 2 are executed on the host system, and steps 3 and 4 are executed on the target system, using only the systemtap 'runtime'.
The systemtap support in Yocto assumes that only steps 3 and 4 are run on the target; it is possible to do everything on the target, but this section assumes only the typical embedded use-case.
So basically what you need to do in order to run a systemtap script on the target is to 1) on the host system, compile the probe into a kernel module that makes sense to the target, 2) copy the module onto the target system and 3) insert the module into the target kernel, which arms it, and 4) collect the data generated by the probe and display it to the user.
Those are a lot of steps and a lot of details, but fortunately Yocto includes a script called 'crosstap' that will take care of those details, allowing you to simply execute a systemtap script on the remote target, with arguments if necessary.
In order to do this from a remote host, however, you need to have access to the build for the image you booted. The 'crosstap' script provides details on how to do this if you run the script on the host without having done a build:
Note
SystemTap, which uses 'crosstap', assumes you can establish an ssh connection to the remote target. Please refer to the crosstap wiki page for details on verifying ssh connections at https://wiki.yoctoproject.org/wiki/Tracing_and_Profiling#systemtap. Also, the ability to ssh into the target system is not enabled by default in *-minimal images.
$ crosstap root@192.168.1.88 trace_open.stp
Error: No target kernel build found.
Did you forget to create a local build of your image?
'crosstap' requires a local sdk build of the target system
(or a build that includes 'tools-profile') in order to build
kernel modules that can probe the target system.
Practically speaking, that means you need to do the following:
- If you're running a pre-built image, download the release
and/or BSP tarballs used to build the image.
- If you're working from git sources, just clone the metadata
and BSP layers needed to build the image you'll be booting.
- Make sure you're properly set up to build a new image (see
the BSP README and/or the widely available basic documentation
that discusses how to build images).
- Build an -sdk version of the image e.g.:
$ bitbake core-image-sato-sdk
OR
- Build a non-sdk image but include the profiling tools:
[ edit local.conf and add 'tools-profile' to the end of
the EXTRA_IMAGE_FEATURES variable ]
$ bitbake core-image-sato
Once you've build the image on the host system, you're ready to
boot it (or the equivalent pre-built image) and use 'crosstap'
to probe it (you need to source the environment as usual first):
$ source oe-init-build-env
$ cd ~/my/systemtap/scripts
$ crosstap root@192.168.1.xxx myscript.stp
So essentially what you need to do is build an SDK image or image with 'tools-profile' as detailed in the "General Setup" section of this manual, and boot the resulting target image.
Note
If you have a build directory containing multiple machines, you need to have the MACHINE you're connecting to selected in local.conf, and the kernel in that machine's build directory must match the kernel on the booted system exactly, or you'll get the above 'crosstap' message when you try to invoke a script.Once you've done that, you should be able to run a systemtap script on the target:
$ cd /path/to/yocto
$ source oe-init-build-env
### Shell environment set up for builds. ###
You can now run 'bitbake <target>'
Common targets are:
core-image-minimal
core-image-sato
meta-toolchain
meta-toolchain-sdk
adt-installer
meta-ide-support
You can also run generated qemu images with a command like 'runqemu qemux86'
Once you've done that, you can cd to whatever directory contains your scripts and use 'crosstap' to run the script:
$ cd /path/to/my/systemap/script
$ crosstap root@192.168.7.2 trace_open.stp
If you get an error connecting to the target e.g.:
$ crosstap root@192.168.7.2 trace_open.stp
error establishing ssh connection on remote 'root@192.168.7.2'
Try ssh'ing to the target and see what happens:
$ ssh root@192.168.7.2
A lot of the time, connection problems are due specifying a wrong IP address or having a 'host key verification error'.
If everything worked as planned, you should see something like this (enter the password when prompted, or press enter if it's set up to use no password):
$ crosstap root@192.168.7.2 trace_open.stp
root@192.168.7.2's password:
matchbox-termin(1036) open ("/tmp/vte3FS2LW", O_RDWR|O_CREAT|O_EXCL|O_LARGEFILE, 0600)
matchbox-termin(1036) open ("/tmp/vteJMC7LW", O_RDWR|O_CREAT|O_EXCL|O_LARGEFILE, 0600)
The SystemTap language reference can be found here: SystemTap Language Reference
Links to other SystemTap documents, tutorials, and examples can be found here: SystemTap documentation page
oprofile itself is a command-line application that runs on the target system.
For this section, we'll assume you've already performed the basic setup outlined in the "General Setup" section.
For the section that deals with running oprofile from the command-line, we assume you've ssh'ed to the host and will be running oprofile on the target.
oprofileui (oprofile-viewer) is a GUI-based program that runs on the host and interacts remotely with the target. See the oprofileui section for the exact steps needed to install oprofileui on the host.
Oprofile as configured in Yocto is a system-wide profiler (i.e. the version in Yocto doesn't yet make use of the perf_events interface which would allow it to profile specific processes and workloads). It relies on hardware counter support in the hardware (but can fall back to a timer-based mode), which means that it doesn't take advantage of tracepoints or other event sources for example.
It consists of a kernel module that collects samples and a userspace daemon that writes the sample data to disk.
The 'opcontrol' shell script is used for transparently managing these components and starting and stopping profiles, and the 'opreport' command is used to display the results.
The oprofile daemon should already be running, but before you start profiling, you may need to change some settings and some of these settings may require the daemon to not be running. One of these settings is the path to the vmlinux file, which you'll want to set using the --vmlinux option if you want the kernel profiled:
root@crownbay:~# opcontrol --vmlinux=/boot/vmlinux-`uname -r`
The profiling daemon is currently active, so changes to the configuration
will be used the next time you restart oprofile after a --shutdown or --deinit.
You can check if vmlinux file: is set using opcontrol --status:
root@crownbay:~# opcontrol --status
Daemon paused: pid 1334
Separate options: library
vmlinux file: none
Image filter: none
Call-graph depth: 6
If it's not, you need to shutdown the daemon, add the setting and restart the daemon:
root@crownbay:~# opcontrol --shutdown
Killing daemon.
root@crownbay:~# opcontrol --vmlinux=/boot/vmlinux-`uname -r`
root@crownbay:~# opcontrol --start-daemon
Using default event: CPU_CLK_UNHALTED:100000:0:1:1
Using 2.6+ OProfile kernel interface.
Reading module info.
Using log file /var/lib/oprofile/samples/oprofiled.log
Daemon started.
If we check the status again we now see our updated settings:
root@crownbay:~# opcontrol --status
Daemon paused: pid 1649
Separate options: library
vmlinux file: /boot/vmlinux-3.4.11-yocto-standard
Image filter: none
Call-graph depth: 6
We're now in a position to run a profile. For that we use 'opcontrol --start':
root@crownbay:~# opcontrol --start
Profiler running.
In another window, run our wget workload:
root@crownbay:~# rm linux-2.6.19.2.tar.bz2; wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2; sync
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |*******************************| 41727k 0:00:00 ETA
To stop the profile we use 'opcontrol --shutdown', which not only stops the profile but shuts down the daemon as well:
root@crownbay:~# opcontrol --shutdown
Stopping profiling.
Killing daemon.
Oprofile writes sample data to /var/lib/oprofile/samples, which you can look at if you're interested in seeing how the samples are structured. This is also interesting because it's related to how you dive down to get further details about specific executables in OProfile.
To see the default display output for a profile, simply type 'opreport', which will show the results using the data in /var/lib/oprofile/samples:
root@crownbay:~# opreport
WARNING! The OProfile kernel driver reports sample buffer overflows.
Such overflows can result in incorrect sample attribution, invalid sample
files and other symptoms. See the oprofiled.log for details.
You should adjust your sampling frequency to eliminate (or at least minimize)
these overflows.
CPU: Intel Architectural Perfmon, speed 1.3e+06 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000
CPU_CLK_UNHALT...|
samples| %|
------------------
464365 79.8156 vmlinux-3.4.11-yocto-standard
65108 11.1908 oprofiled
CPU_CLK_UNHALT...|
samples| %|
------------------
64416 98.9372 oprofiled
692 1.0628 libc-2.16.so
36959 6.3526 no-vmlinux
4378 0.7525 busybox
CPU_CLK_UNHALT...|
samples| %|
------------------
2844 64.9612 libc-2.16.so
1337 30.5391 busybox
193 4.4084 ld-2.16.so
2 0.0457 libnss_compat-2.16.so
1 0.0228 libnsl-2.16.so
1 0.0228 libnss_files-2.16.so
4344 0.7467 bash
CPU_CLK_UNHALT...|
samples| %|
------------------
2657 61.1648 bash
1665 38.3287 libc-2.16.so
18 0.4144 ld-2.16.so
3 0.0691 libtinfo.so.5.9
1 0.0230 libdl-2.16.so
3118 0.5359 nf_conntrack
686 0.1179 matchbox-terminal
CPU_CLK_UNHALT...|
samples| %|
------------------
214 31.1953 libglib-2.0.so.0.3200.4
114 16.6181 libc-2.16.so
79 11.5160 libcairo.so.2.11200.2
78 11.3703 libgdk-x11-2.0.so.0.2400.8
51 7.4344 libpthread-2.16.so
45 6.5598 libgobject-2.0.so.0.3200.4
29 4.2274 libvte.so.9.2800.2
25 3.6443 libX11.so.6.3.0
19 2.7697 libxcb.so.1.1.0
17 2.4781 libgtk-x11-2.0.so.0.2400.8
12 1.7493 librt-2.16.so
3 0.4373 libXrender.so.1.3.0
671 0.1153 emgd
411 0.0706 nf_conntrack_ipv4
391 0.0672 iptable_nat
378 0.0650 nf_nat
263 0.0452 Xorg
CPU_CLK_UNHALT...|
samples| %|
------------------
106 40.3042 Xorg
53 20.1521 libc-2.16.so
31 11.7871 libpixman-1.so.0.27.2
26 9.8859 emgd_drv.so
16 6.0837 libemgdsrv_um.so.1.5.15.3226
11 4.1825 libEMGD2d.so.1.5.15.3226
9 3.4221 libfb.so
7 2.6616 libpthread-2.16.so
1 0.3802 libudev.so.0.9.3
1 0.3802 libdrm.so.2.4.0
1 0.3802 libextmod.so
1 0.3802 mouse_drv.so
.
.
.
9 0.0015 connmand
CPU_CLK_UNHALT...|
samples| %|
------------------
4 44.4444 libglib-2.0.so.0.3200.4
2 22.2222 libpthread-2.16.so
1 11.1111 connmand
1 11.1111 libc-2.16.so
1 11.1111 librt-2.16.so
6 0.0010 oprofile-server
CPU_CLK_UNHALT...|
samples| %|
------------------
3 50.0000 libc-2.16.so
1 16.6667 oprofile-server
1 16.6667 libpthread-2.16.so
1 16.6667 libglib-2.0.so.0.3200.4
5 8.6e-04 gconfd-2
CPU_CLK_UNHALT...|
samples| %|
------------------
2 40.0000 libdbus-1.so.3.7.2
2 40.0000 libglib-2.0.so.0.3200.4
1 20.0000 libc-2.16.so
The output above shows the breakdown or samples by both number of samples and percentage for each executable. Within an executable, the sample counts are broken down further into executable and shared libraries (DSOs) used by the executable.
To get even more detailed breakdowns by function, we need to have the full paths to the DSOs, which we can get by using -f with opreport:
root@crownbay:~# opreport -f
CPU: Intel Architectural Perfmon, speed 1.3e+06 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000
CPU_CLK_UNHALT...|
samples| %|
464365 79.8156 /boot/vmlinux-3.4.11-yocto-standard
65108 11.1908 /usr/bin/oprofiled
CPU_CLK_UNHALT...|
samples| %|
------------------
64416 98.9372 /usr/bin/oprofiled
692 1.0628 /lib/libc-2.16.so
36959 6.3526 /no-vmlinux
4378 0.7525 /bin/busybox
CPU_CLK_UNHALT...|
samples| %|
------------------
2844 64.9612 /lib/libc-2.16.so
1337 30.5391 /bin/busybox
193 4.4084 /lib/ld-2.16.so
2 0.0457 /lib/libnss_compat-2.16.so
1 0.0228 /lib/libnsl-2.16.so
1 0.0228 /lib/libnss_files-2.16.so
4344 0.7467 /bin/bash
CPU_CLK_UNHALT...|
samples| %|
------------------
2657 61.1648 /bin/bash
1665 38.3287 /lib/libc-2.16.so
18 0.4144 /lib/ld-2.16.so
3 0.0691 /lib/libtinfo.so.5.9
1 0.0230 /lib/libdl-2.16.so
.
.
.
Using the paths shown in the above output and the -l option to opreport, we can see all the functions that have hits in the profile and their sample counts and percentages. Here's a portion of what we get for the kernel:
root@crownbay:~# opreport -l /boot/vmlinux-3.4.11-yocto-standard
CPU: Intel Architectural Perfmon, speed 1.3e+06 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000
samples % symbol name
233981 50.3873 intel_idle
15437 3.3243 rb_get_reader_page
14503 3.1232 ring_buffer_consume
14092 3.0347 mutex_spin_on_owner
13024 2.8047 read_hpet
8039 1.7312 sub_preempt_count
7096 1.5281 ioread32
6997 1.5068 add_preempt_count
3985 0.8582 rb_advance_reader
3488 0.7511 add_event_entry
3303 0.7113 get_parent_ip
3104 0.6684 rb_buffer_peek
2960 0.6374 op_cpu_buffer_read_entry
2614 0.5629 sync_buffer
2545 0.5481 debug_smp_processor_id
2456 0.5289 ohci_irq
2397 0.5162 memset
2349 0.5059 __copy_to_user_ll
2185 0.4705 ring_buffer_event_length
1918 0.4130 in_lock_functions
1850 0.3984 __schedule
1767 0.3805 __copy_from_user_ll_nozero
1575 0.3392 rb_event_data_length
1256 0.2705 memcpy
1233 0.2655 system_call
1213 0.2612 menu_select
Notice that above we see an entry for the __copy_to_user_ll() function that we've looked at with other profilers as well.
Here's what we get when we do the same thing for the busybox executable:
CPU: Intel Architectural Perfmon, speed 1.3e+06 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000
samples % image name symbol name
349 8.4198 busybox retrieve_file_data
308 7.4306 libc-2.16.so _IO_file_xsgetn
283 6.8275 libc-2.16.so __read_nocancel
235 5.6695 libc-2.16.so syscall
233 5.6212 libc-2.16.so clearerr
215 5.1870 libc-2.16.so fread
181 4.3667 libc-2.16.so __write_nocancel
158 3.8118 libc-2.16.so __underflow
151 3.6429 libc-2.16.so _dl_addr
150 3.6188 busybox progress_meter
150 3.6188 libc-2.16.so __poll_nocancel
148 3.5706 libc-2.16.so _IO_file_underflow@@GLIBC_2.1
137 3.3052 busybox safe_poll
125 3.0157 busybox bb_progress_update
122 2.9433 libc-2.16.so __x86.get_pc_thunk.bx
95 2.2919 busybox full_write
81 1.9542 busybox safe_write
77 1.8577 busybox xwrite
72 1.7370 libc-2.16.so _IO_file_read
71 1.7129 libc-2.16.so _IO_sgetn
67 1.6164 libc-2.16.so poll
52 1.2545 libc-2.16.so _IO_switch_to_get_mode
45 1.0856 libc-2.16.so read
34 0.8203 libc-2.16.so write
32 0.7720 busybox monotonic_sec
25 0.6031 libc-2.16.so vfprintf
22 0.5308 busybox get_mono
14 0.3378 ld-2.16.so strcmp
14 0.3378 libc-2.16.so __x86.get_pc_thunk.cx
.
.
.
Since we recorded the profile with a callchain depth of 6, we should be able to see our __copy_to_user_ll() callchains in the output, and indeed we can if we search around a bit in the 'opreport --callgraph' output:
root@crownbay:~# opreport --callgraph /boot/vmlinux-3.4.11-yocto-standard
392 6.9639 vmlinux-3.4.11-yocto-standard sock_aio_read
736 13.0751 vmlinux-3.4.11-yocto-standard __generic_file_aio_write
3255 57.8255 vmlinux-3.4.11-yocto-standard inet_recvmsg
785 0.1690 vmlinux-3.4.11-yocto-standard tcp_recvmsg
1790 31.7940 vmlinux-3.4.11-yocto-standard local_bh_enable
1238 21.9893 vmlinux-3.4.11-yocto-standard __kfree_skb
992 17.6199 vmlinux-3.4.11-yocto-standard lock_sock_nested
785 13.9432 vmlinux-3.4.11-yocto-standard tcp_recvmsg [self]
525 9.3250 vmlinux-3.4.11-yocto-standard release_sock
112 1.9893 vmlinux-3.4.11-yocto-standard tcp_cleanup_rbuf
72 1.2789 vmlinux-3.4.11-yocto-standard skb_copy_datagram_iovec
170 0.0366 vmlinux-3.4.11-yocto-standard skb_copy_datagram_iovec
1491 73.3038 vmlinux-3.4.11-yocto-standard memcpy_toiovec
327 16.0767 vmlinux-3.4.11-yocto-standard skb_copy_datagram_iovec
170 8.3579 vmlinux-3.4.11-yocto-standard skb_copy_datagram_iovec [self]
20 0.9833 vmlinux-3.4.11-yocto-standard copy_to_user
2588 98.2909 vmlinux-3.4.11-yocto-standard copy_to_user
2349 0.5059 vmlinux-3.4.11-yocto-standard __copy_to_user_ll
2349 89.2138 vmlinux-3.4.11-yocto-standard __copy_to_user_ll [self]
166 6.3046 vmlinux-3.4.11-yocto-standard do_page_fault
Remember that by default OProfile sessions are cumulative i.e. if you start and stop a profiling session, then start a new one, the new one will not erase the previous run(s) but will build on it. If you want to restart a profile from scratch, you need to reset:
root@crownbay:~# opcontrol --reset
Yocto also supports a graphical UI for controlling and viewing OProfile traces, called OProfileUI. To use it, you first need to clone the oprofileui git repo, then configure, build, and install it:
[trz@empanada tmp]$ git clone git://git.yoctoproject.org/oprofileui
[trz@empanada tmp]$ cd oprofileui
[trz@empanada oprofileui]$ ./autogen.sh
[trz@empanada oprofileui]$ sudo make install
OprofileUI replaces the 'opreport' functionality with a GUI, and normally doesn't require the user to use 'opcontrol' either. If you want to profile the kernel, however, you need to either use the UI to specify a vmlinux or use 'opcontrol' to specify it on the target:
First, on the target, check if vmlinux file: is set:
root@crownbay:~# opcontrol --status
If not:
root@crownbay:~# opcontrol --shutdown
root@crownbay:~# opcontrol --vmlinux=/boot/vmlinux-`uname -r`
root@crownbay:~# opcontrol --start-daemon
Now, start the oprofile UI on the host system:
[trz@empanada oprofileui]$ oprofile-viewer
To run a profile on the remote system, first connect to the remote system by pressing the 'Connect' button and supplying the IP address and port of the remote system (the default port is 4224).
The oprofile server should automatically be started already. If not, the connection will fail and you either typed in the wrong IP address and port (see below), or you need to start the server yourself:
root@crownbay:~# oprofile-server
Or, to specify a specific port:
root@crownbay:~# oprofile-server --port 8888
Once connected, press the 'Start' button and then run the wget workload on the remote system:
root@crownbay:~# rm linux-2.6.19.2.tar.bz2; wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2; sync
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |*******************************| 41727k 0:00:00 ETA
Once the workload completes, press the 'Stop' button. At that point the OProfile viewer will download the profile files it's collected (this may take some time, especially if the kernel was profiled). While it downloads the files, you should see something like the following:
 |
Once the profile files have been retrieved, you should see a list of the processes that were profiled:
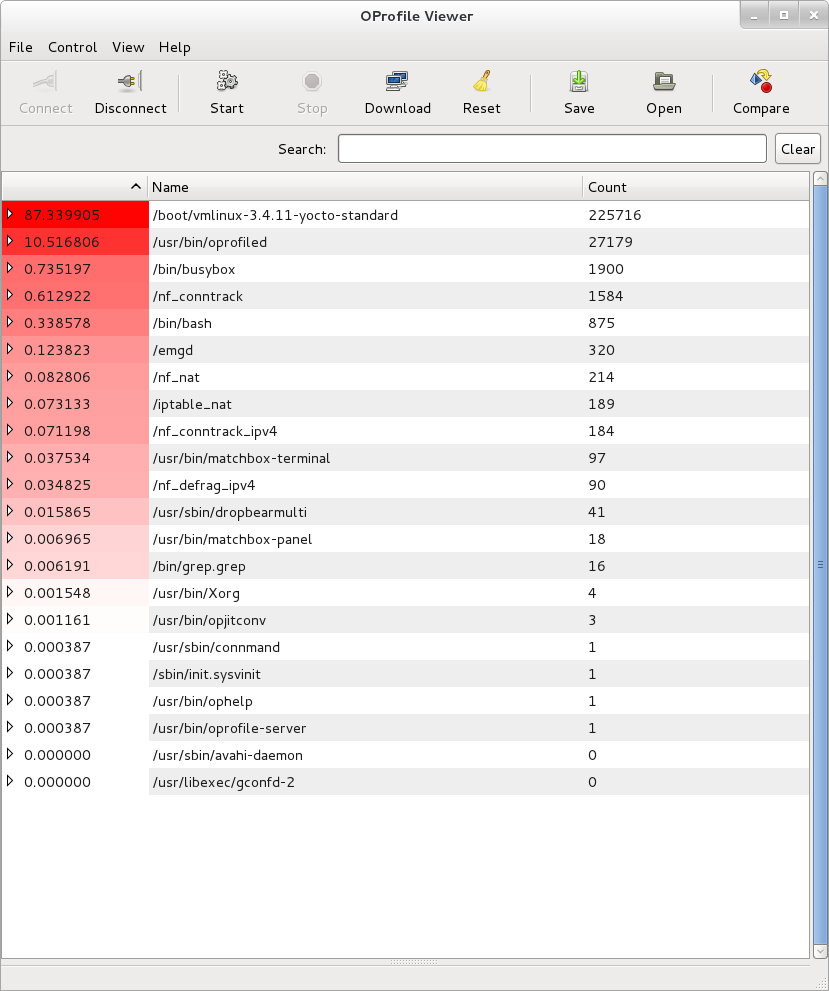 |
If you select one of them, you should see all the symbols that were hit during the profile. Selecting one of them will show a list of callers and callees of the chosen function in two panes below the top pane. For example, here's what we see when we select __copy_to_user_ll():
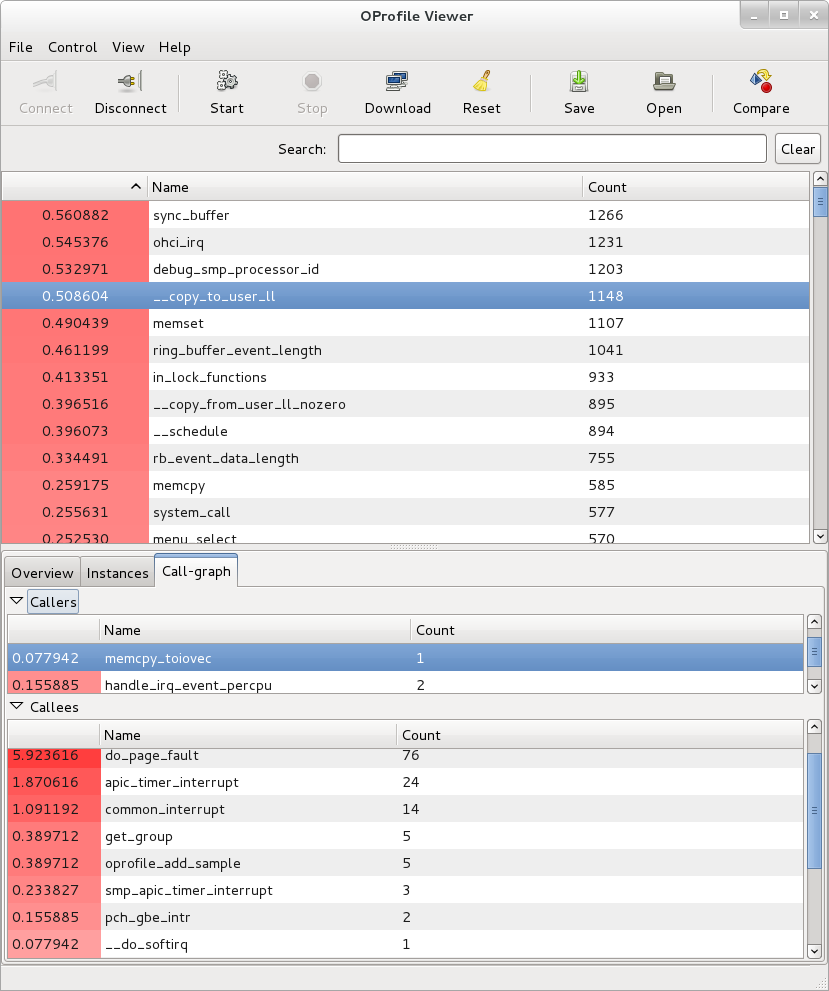 |
As another example, we can look at the busybox process and see that the progress meter made a system call:
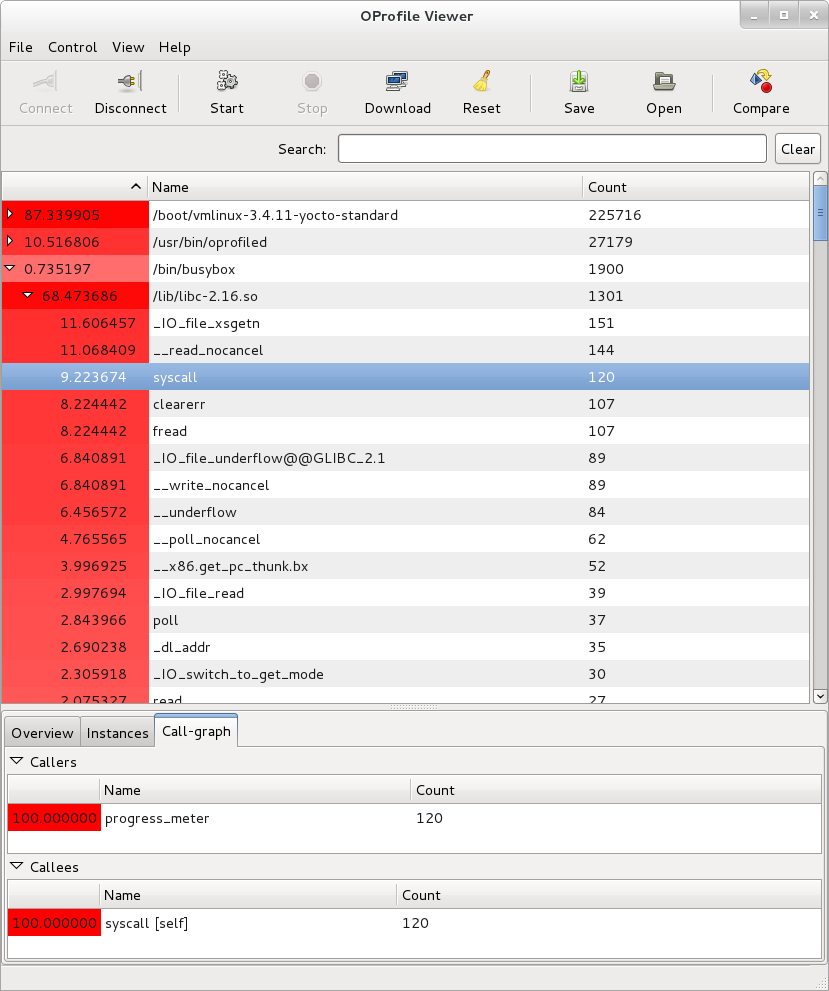 |
Yocto already has some information on setting up and using OProfile and oprofileui. As this document doesn't cover everything in detail, it may be worth taking a look at the "Profiling with OProfile" section in the Yocto Project Development Manual
The OProfile manual can be found here: OProfile manual
The OProfile website contains links to the above manual and bunch of other items including an extensive set of examples: About OProfile
Sysprof is a very easy to use system-wide profiler that consists of a single window with three panes and a few buttons which allow you to start, stop, and view the profile from one place.
For this section, we'll assume you've already performed the basic setup outlined in the General Setup section.
Sysprof is a GUI-based application that runs on the target system. For the rest of this document we assume you've ssh'ed to the host and will be running Sysprof on the target (you can use the '-X' option to ssh and have the Sysprof GUI run on the target but display remotely on the host if you want).
To start profiling the system, you simply press the 'Start' button. To stop profiling and to start viewing the profile data in one easy step, press the 'Profile' button.
Once you've pressed the profile button, the three panes will fill up with profiling data:
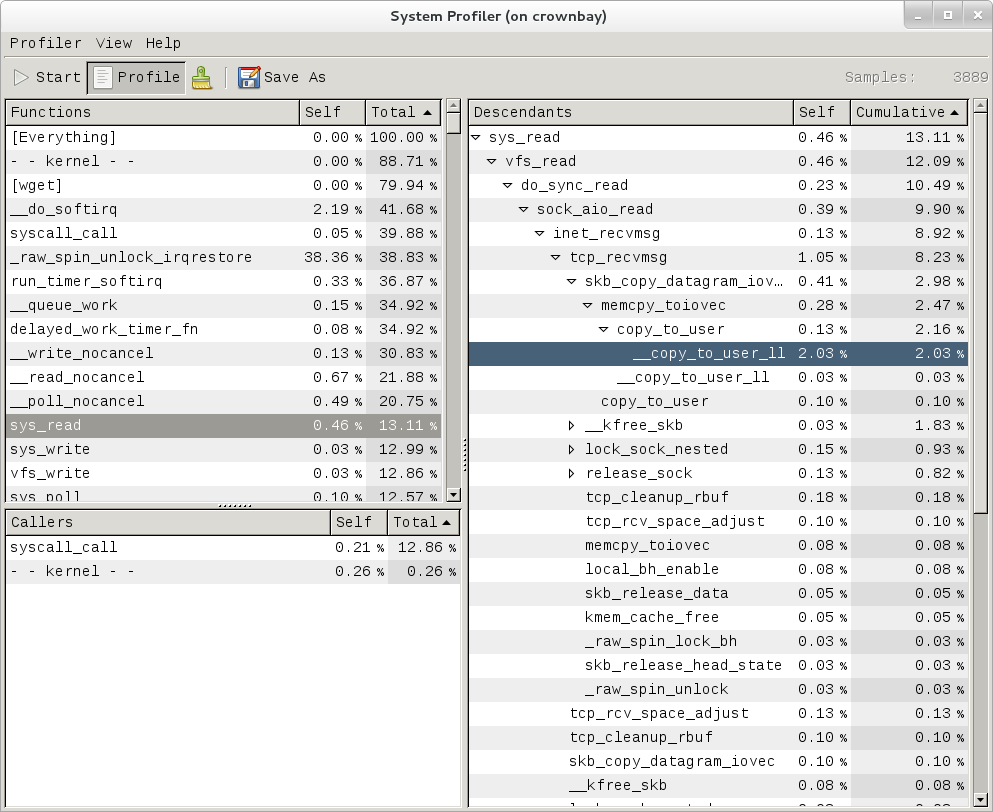 |
The left pane shows a list of functions and processes. Selecting one of those expands that function in the right pane, showing all its callees. Note that this caller-oriented display is essentially the inverse of perf's default callee-oriented callchain display.
In the screenshot above, we're focusing on __copy_to_user_ll() and looking up the callchain we can see that one of the callers of __copy_to_user_ll is sys_read() and the complete callpath between them. Notice that this is essentially a portion of the same information we saw in the perf display shown in the perf section of this page.
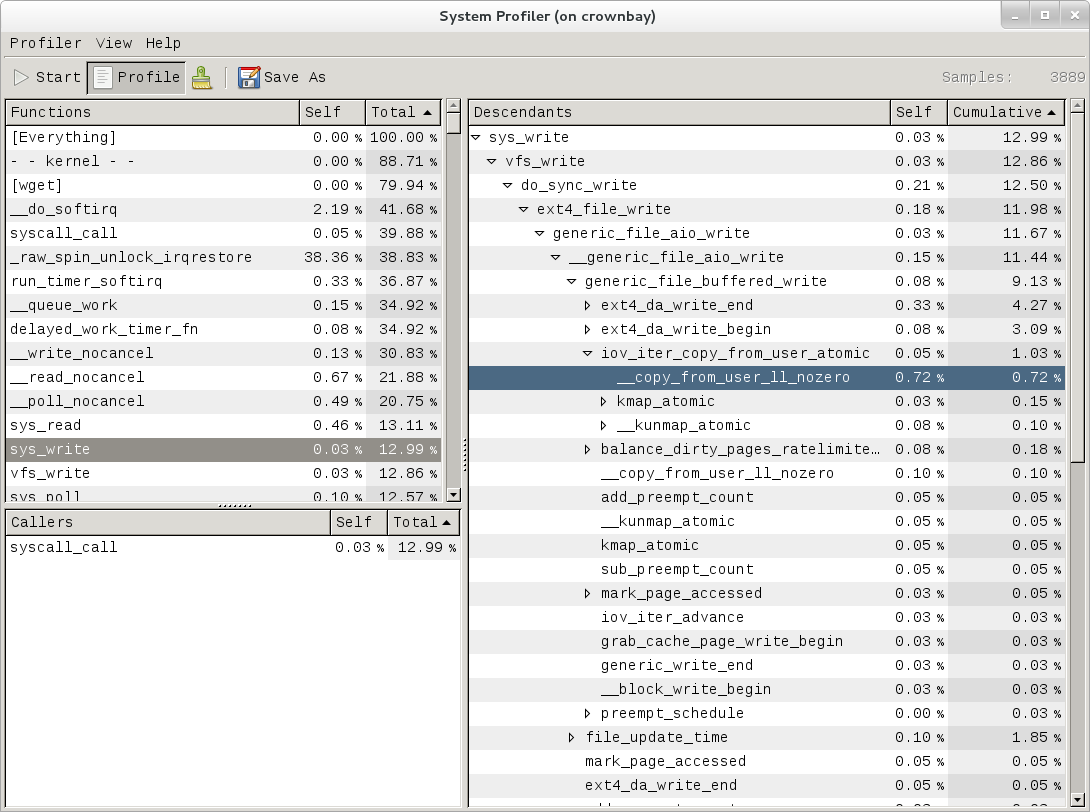 |
Similarly, the above is a snapshot of the Sysprof display of a copy-from-user callchain.
Finally, looking at the third Sysprof pane in the lower left, we can see a list of all the callers of a particular function selected in the top left pane. In this case, the lower pane is showing all the callers of __mark_inode_dirty:
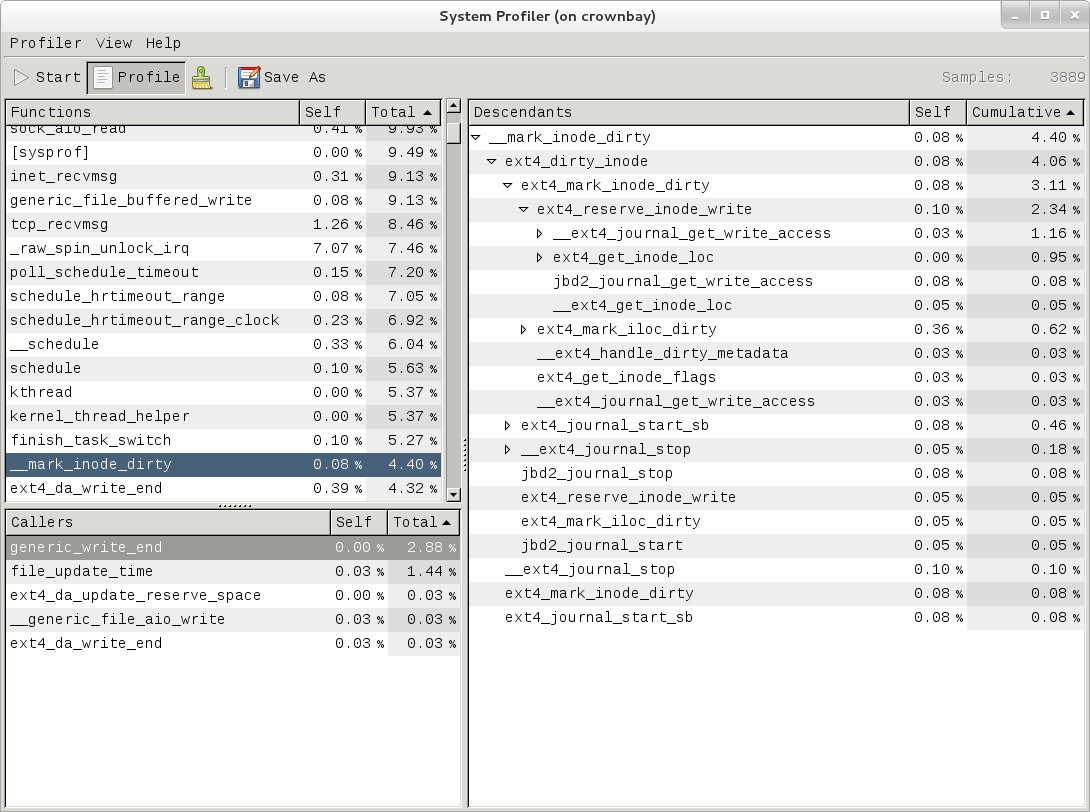 |
Double-clicking on one of those functions will in turn change the focus to the selected function, and so on.
There doesn't seem to be any documentation for Sysprof, but maybe that's because it's pretty self-explanatory. The Sysprof website, however, is here: Sysprof, System-wide Performance Profiler for Linux
For this section, we'll assume you've already performed the basic setup outlined in the General Setup section.
LTTng is run on the target system by ssh'ing to it. However, if you want to see the traces graphically, install Eclipse as described in section "Manually copying a trace to the host and viewing it in Eclipse (i.e. using Eclipse without network support)" and follow the directions to manually copy traces to the host and view them in Eclipse (i.e. using Eclipse without network support).
Note
Be sure to download and install/run the 'SR1' or later Juno release of eclipse e.g.: http://www.eclipse.org/downloads/download.php?file=/technology/epp/downloads/release/juno/SR1/eclipse-cpp-juno-SR1-linux-gtk-x86_64.tar.gzOnce you've applied the above commits and built and booted your image (you need to build the core-image-sato-sdk image or use one of the other methods described in the General Setup section), you're ready to start tracing.
First, from the host, ssh to the target:
$ ssh -l root 192.168.1.47
The authenticity of host '192.168.1.47 (192.168.1.47)' can't be established.
RSA key fingerprint is 23:bd:c8:b1:a8:71:52:00:ee:00:4f:64:9e:10:b9:7e.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.1.47' (RSA) to the list of known hosts.
root@192.168.1.47's password:
Once on the target, use these steps to create a trace:
root@crownbay:~# lttng create
Spawning a session daemon
Session auto-20121015-232120 created.
Traces will be written in /home/root/lttng-traces/auto-20121015-232120
Enable the events you want to trace (in this case all kernel events):
root@crownbay:~# lttng enable-event --kernel --all
All kernel events are enabled in channel channel0
Start the trace:
root@crownbay:~# lttng start
Tracing started for session auto-20121015-232120
And then stop the trace after awhile or after running a particular workload that you want to trace:
root@crownbay:~# lttng stop
Tracing stopped for session auto-20121015-232120
You can now view the trace in text form on the target:
root@crownbay:~# lttng view
[23:21:56.989270399] (+?.?????????) sys_geteuid: { 1 }, { }
[23:21:56.989278081] (+0.000007682) exit_syscall: { 1 }, { ret = 0 }
[23:21:56.989286043] (+0.000007962) sys_pipe: { 1 }, { fildes = 0xB77B9E8C }
[23:21:56.989321802] (+0.000035759) exit_syscall: { 1 }, { ret = 0 }
[23:21:56.989329345] (+0.000007543) sys_mmap_pgoff: { 1 }, { addr = 0x0, len = 10485760, prot = 3, flags = 131362, fd = 4294967295, pgoff = 0 }
[23:21:56.989351694] (+0.000022349) exit_syscall: { 1 }, { ret = -1247805440 }
[23:21:56.989432989] (+0.000081295) sys_clone: { 1 }, { clone_flags = 0x411, newsp = 0xB5EFFFE4, parent_tid = 0xFFFFFFFF, child_tid = 0x0 }
[23:21:56.989477129] (+0.000044140) sched_stat_runtime: { 1 }, { comm = "lttng-consumerd", tid = 1193, runtime = 681660, vruntime = 43367983388 }
[23:21:56.989486697] (+0.000009568) sched_migrate_task: { 1 }, { comm = "lttng-consumerd", tid = 1193, prio = 20, orig_cpu = 1, dest_cpu = 1 }
[23:21:56.989508418] (+0.000021721) hrtimer_init: { 1 }, { hrtimer = 3970832076, clockid = 1, mode = 1 }
[23:21:56.989770462] (+0.000262044) hrtimer_cancel: { 1 }, { hrtimer = 3993865440 }
[23:21:56.989771580] (+0.000001118) hrtimer_cancel: { 0 }, { hrtimer = 3993812192 }
[23:21:56.989776957] (+0.000005377) hrtimer_expire_entry: { 1 }, { hrtimer = 3993865440, now = 79815980007057, function = 3238465232 }
[23:21:56.989778145] (+0.000001188) hrtimer_expire_entry: { 0 }, { hrtimer = 3993812192, now = 79815980008174, function = 3238465232 }
[23:21:56.989791695] (+0.000013550) softirq_raise: { 1 }, { vec = 1 }
[23:21:56.989795396] (+0.000003701) softirq_raise: { 0 }, { vec = 1 }
[23:21:56.989800635] (+0.000005239) softirq_raise: { 0 }, { vec = 9 }
[23:21:56.989807130] (+0.000006495) sched_stat_runtime: { 1 }, { comm = "lttng-consumerd", tid = 1193, runtime = 330710, vruntime = 43368314098 }
[23:21:56.989809993] (+0.000002863) sched_stat_runtime: { 0 }, { comm = "lttng-sessiond", tid = 1181, runtime = 1015313, vruntime = 36976733240 }
[23:21:56.989818514] (+0.000008521) hrtimer_expire_exit: { 0 }, { hrtimer = 3993812192 }
[23:21:56.989819631] (+0.000001117) hrtimer_expire_exit: { 1 }, { hrtimer = 3993865440 }
[23:21:56.989821866] (+0.000002235) hrtimer_start: { 0 }, { hrtimer = 3993812192, function = 3238465232, expires = 79815981000000, softexpires = 79815981000000 }
[23:21:56.989822984] (+0.000001118) hrtimer_start: { 1 }, { hrtimer = 3993865440, function = 3238465232, expires = 79815981000000, softexpires = 79815981000000 }
[23:21:56.989832762] (+0.000009778) softirq_entry: { 1 }, { vec = 1 }
[23:21:56.989833879] (+0.000001117) softirq_entry: { 0 }, { vec = 1 }
[23:21:56.989838069] (+0.000004190) timer_cancel: { 1 }, { timer = 3993871956 }
[23:21:56.989839187] (+0.000001118) timer_cancel: { 0 }, { timer = 3993818708 }
[23:21:56.989841492] (+0.000002305) timer_expire_entry: { 1 }, { timer = 3993871956, now = 79515980, function = 3238277552 }
[23:21:56.989842819] (+0.000001327) timer_expire_entry: { 0 }, { timer = 3993818708, now = 79515980, function = 3238277552 }
[23:21:56.989854831] (+0.000012012) sched_stat_runtime: { 1 }, { comm = "lttng-consumerd", tid = 1193, runtime = 49237, vruntime = 43368363335 }
[23:21:56.989855949] (+0.000001118) sched_stat_runtime: { 0 }, { comm = "lttng-sessiond", tid = 1181, runtime = 45121, vruntime = 36976778361 }
[23:21:56.989861257] (+0.000005308) sched_stat_sleep: { 1 }, { comm = "kworker/1:1", tid = 21, delay = 9451318 }
[23:21:56.989862374] (+0.000001117) sched_stat_sleep: { 0 }, { comm = "kworker/0:0", tid = 4, delay = 9958820 }
[23:21:56.989868241] (+0.000005867) sched_wakeup: { 0 }, { comm = "kworker/0:0", tid = 4, prio = 120, success = 1, target_cpu = 0 }
[23:21:56.989869358] (+0.000001117) sched_wakeup: { 1 }, { comm = "kworker/1:1", tid = 21, prio = 120, success = 1, target_cpu = 1 }
[23:21:56.989877460] (+0.000008102) timer_expire_exit: { 1 }, { timer = 3993871956 }
[23:21:56.989878577] (+0.000001117) timer_expire_exit: { 0 }, { timer = 3993818708 }
.
.
.
You can now safely destroy the trace session (note that this doesn't delete the trace - it's still there in ~/lttng-traces):
root@crownbay:~# lttng destroy
Session auto-20121015-232120 destroyed at /home/root
Note that the trace is saved in a directory of the same name as returned by 'lttng create', under the ~/lttng-traces directory (note that you can change this by supplying your own name to 'lttng create'):
root@crownbay:~# ls -al ~/lttng-traces
drwxrwx--- 3 root root 1024 Oct 15 23:21 .
drwxr-xr-x 5 root root 1024 Oct 15 23:57 ..
drwxrwx--- 3 root root 1024 Oct 15 23:21 auto-20121015-232120
For LTTng userspace tracing, you need to have a properly instrumented userspace program. For this example, we'll use the 'hello' test program generated by the lttng-ust build.
The 'hello' test program isn't installed on the rootfs by the lttng-ust build, so we need to copy it over manually. First cd into the build directory that contains the hello executable:
$ cd build/tmp/work/core2-poky-linux/lttng-ust/2.0.5-r0/git/tests/hello/.libs
Copy that over to the target machine:
$ scp hello root@192.168.1.20:
You now have the instrumented lttng 'hello world' test program on the target, ready to test.
First, from the host, ssh to the target:
$ ssh -l root 192.168.1.47
The authenticity of host '192.168.1.47 (192.168.1.47)' can't be established.
RSA key fingerprint is 23:bd:c8:b1:a8:71:52:00:ee:00:4f:64:9e:10:b9:7e.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.1.47' (RSA) to the list of known hosts.
root@192.168.1.47's password:
Once on the target, use these steps to create a trace:
root@crownbay:~# lttng create
Session auto-20190303-021943 created.
Traces will be written in /home/root/lttng-traces/auto-20190303-021943
Enable the events you want to trace (in this case all userspace events):
root@crownbay:~# lttng enable-event --userspace --all
All UST events are enabled in channel channel0
Start the trace:
root@crownbay:~# lttng start
Tracing started for session auto-20190303-021943
Run the instrumented hello world program:
root@crownbay:~# ./hello
Hello, World!
Tracing... done.
And then stop the trace after awhile or after running a particular workload that you want to trace:
root@crownbay:~# lttng stop
Tracing stopped for session auto-20190303-021943
You can now view the trace in text form on the target:
root@crownbay:~# lttng view
[02:31:14.906146544] (+?.?????????) hello:1424 ust_tests_hello:tptest: { cpu_id = 1 }, { intfield = 0, intfield2 = 0x0, longfield = 0, netintfield = 0, netintfieldhex = 0x0, arrfield1 = [ [0] = 1, [1] = 2, [2] = 3 ], arrfield2 = "test", _seqfield1_length = 4, seqfield1 = [ [0] = 116, [1] = 101, [2] = 115, [3] = 116 ], _seqfield2_length = 4, seqfield2 = "test", stringfield = "test", floatfield = 2222, doublefield = 2, boolfield = 1 }
[02:31:14.906170360] (+0.000023816) hello:1424 ust_tests_hello:tptest: { cpu_id = 1 }, { intfield = 1, intfield2 = 0x1, longfield = 1, netintfield = 1, netintfieldhex = 0x1, arrfield1 = [ [0] = 1, [1] = 2, [2] = 3 ], arrfield2 = "test", _seqfield1_length = 4, seqfield1 = [ [0] = 116, [1] = 101, [2] = 115, [3] = 116 ], _seqfield2_length = 4, seqfield2 = "test", stringfield = "test", floatfield = 2222, doublefield = 2, boolfield = 1 }
[02:31:14.906183140] (+0.000012780) hello:1424 ust_tests_hello:tptest: { cpu_id = 1 }, { intfield = 2, intfield2 = 0x2, longfield = 2, netintfield = 2, netintfieldhex = 0x2, arrfield1 = [ [0] = 1, [1] = 2, [2] = 3 ], arrfield2 = "test", _seqfield1_length = 4, seqfield1 = [ [0] = 116, [1] = 101, [2] = 115, [3] = 116 ], _seqfield2_length = 4, seqfield2 = "test", stringfield = "test", floatfield = 2222, doublefield = 2, boolfield = 1 }
[02:31:14.906194385] (+0.000011245) hello:1424 ust_tests_hello:tptest: { cpu_id = 1 }, { intfield = 3, intfield2 = 0x3, longfield = 3, netintfield = 3, netintfieldhex = 0x3, arrfield1 = [ [0] = 1, [1] = 2, [2] = 3 ], arrfield2 = "test", _seqfield1_length = 4, seqfield1 = [ [0] = 116, [1] = 101, [2] = 115, [3] = 116 ], _seqfield2_length = 4, seqfield2 = "test", stringfield = "test", floatfield = 2222, doublefield = 2, boolfield = 1 }
.
.
.
You can now safely destroy the trace session (note that this doesn't delete the trace - it's still there in ~/lttng-traces):
root@crownbay:~# lttng destroy
Session auto-20190303-021943 destroyed at /home/root
If you already have an LTTng trace on a remote target and would like to view it in Eclipse on the host, you can easily copy it from the target to the host and import it into Eclipse to view it using the LTTng Eclipse plug-in already bundled in the Eclipse (Juno SR1 or greater).
Using the trace we created in the previous section, archive it and copy it to your host system:
root@crownbay:~/lttng-traces# tar zcvf auto-20121015-232120.tar.gz auto-20121015-232120
auto-20121015-232120/
auto-20121015-232120/kernel/
auto-20121015-232120/kernel/metadata
auto-20121015-232120/kernel/channel0_1
auto-20121015-232120/kernel/channel0_0
$ scp root@192.168.1.47:lttng-traces/auto-20121015-232120.tar.gz .
root@192.168.1.47's password:
auto-20121015-232120.tar.gz 100% 1566KB 1.5MB/s 00:01
Unarchive it on the host:
$ gunzip -c auto-20121015-232120.tar.gz | tar xvf -
auto-20121015-232120/
auto-20121015-232120/kernel/
auto-20121015-232120/kernel/metadata
auto-20121015-232120/kernel/channel0_1
auto-20121015-232120/kernel/channel0_0
We can now import the trace into Eclipse and view it:
First, start eclipse and open the 'LTTng Kernel' perspective by selecting the following menu item:
Window | Open Perspective | Other...In the dialog box that opens, select 'LTTng Kernel' from the list.
Back at the main menu, select the following menu item:
File | New | Project...In the dialog box that opens, select the 'Tracing | Tracing Project' wizard and press 'Next>'.
Give the project a name and press 'Finish'.
In the 'Project Explorer' pane under the project you created, right click on the 'Traces' item.
Select 'Import..." and in the dialog that's displayed:
Browse the filesystem and find the select the 'kernel' directory containing the trace you copied from the target e.g. auto-20121015-232120/kernel
'Checkmark' the directory in the tree that's displayed for the trace
Below that, select 'Common Trace Format: Kernel Trace' for the 'Trace Type'
Press 'Finish' to close the dialog
Back in the 'Project Explorer' pane, double-click on the 'kernel' item for the trace you just imported under 'Traces'
You should now see your trace data displayed graphically in several different views in Eclipse:
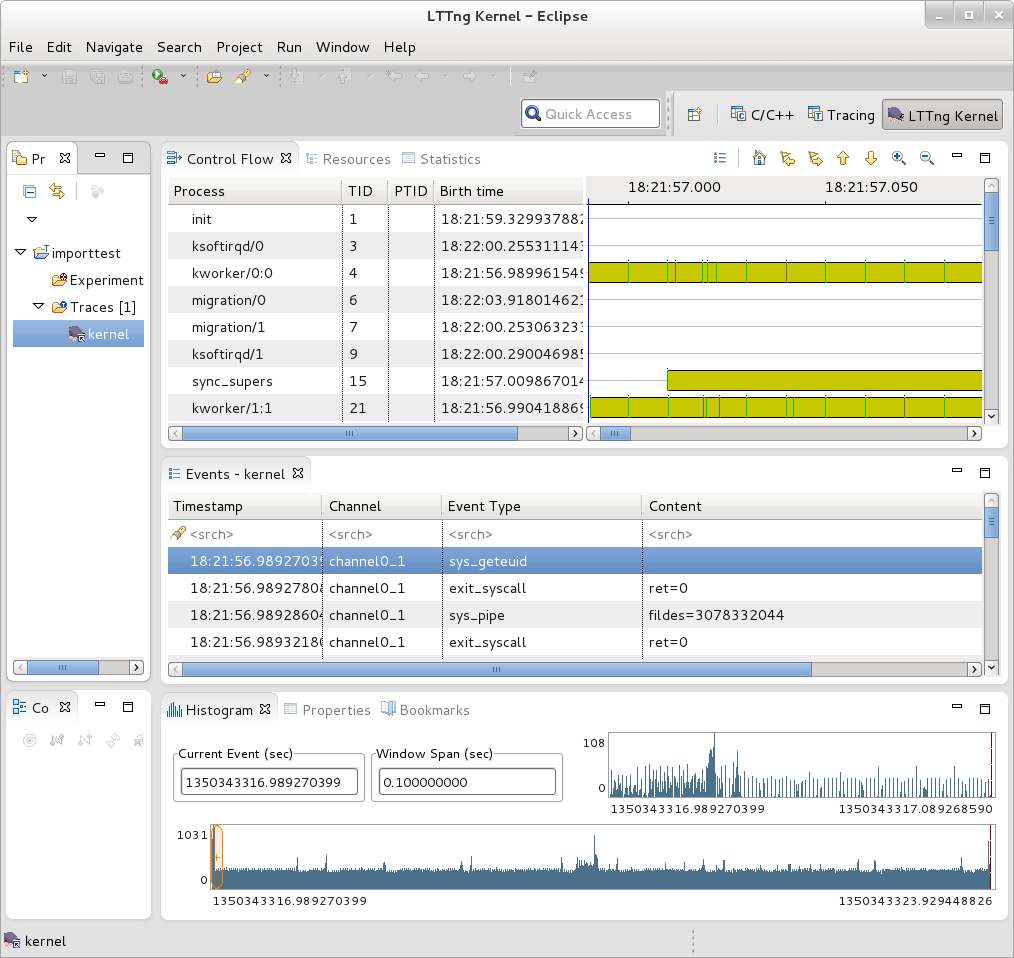 |
You can access extensive help information on how to use the LTTng plug-in to search and analyze captured traces via the Eclipse help system:
Help | Help Contents | LTTng Plug-in User Guide
Note
This section on collecting traces remotely doesn't currently work because of Eclipse 'RSE' connectivity problems. Manually tracing on the target, copying the trace files to the host, and viewing the trace in Eclipse on the host as outlined in previous steps does work however - please use the manual steps outlined above to view traces in Eclipse.In order to trace a remote target, you also need to add a 'tracing' group on the target and connect as a user who's part of that group e.g:
# adduser tomz
# groupadd -r tracing
# usermod -a -G tracing tomz
First, start eclipse and open the 'LTTng Kernel' perspective by selecting the following menu item:
Window | Open Perspective | Other...In the dialog box that opens, select 'LTTng Kernel' from the list.
Back at the main menu, select the following menu item:
File | New | Project...In the dialog box that opens, select the 'Tracing | Tracing Project' wizard and press 'Next>'.
Give the project a name and press 'Finish'. That should result in an entry in the 'Project' subwindow.
In the 'Control' subwindow just below it, press 'New Connection'.
Add a new connection, giving it the hostname or IP address of the target system.
Provide the username and password of a qualified user (a member of the 'tracing' group) or root account on the target system.
Provide appropriate answers to whatever else is asked for e.g. 'secure storage password' can be anything you want. If you get an 'RSE Error' it may be due to proxies. It may be possible to get around the problem by changing the following setting:
Window | Preferences | Network ConnectionsSwitch 'Active Provider' to 'Direct'
There doesn't seem to be any current documentation covering LTTng 2.0, but maybe that's because the project is in transition. The LTTng 2.0 website, however, is here: LTTng Project
You can access extensive help information on how to use the LTTng plug-in to search and analyze captured traces via the Eclipse help system:
Help | Help Contents | LTTng Plug-in User Guide
blktrace is a tool for tracing and reporting low-level disk I/O. blktrace provides the tracing half of the equation; its output can be piped into the blkparse program, which renders the data in a human-readable form and does some basic analysis:
For this section, we'll assume you've already performed the basic setup outlined in the "General Setup" section.
blktrace is an application that runs on the target system. You can run the entire blktrace and blkparse pipeline on the target, or you can run blktrace in 'listen' mode on the target and have blktrace and blkparse collect and analyze the data on the host (see the "Using blktrace Remotely" section below). For the rest of this section we assume you've ssh'ed to the host and will be running blkrace on the target.
To record a trace, simply run the 'blktrace' command, giving it the name of the block device you want to trace activity on:
root@crownbay:~# blktrace /dev/sdc
In another shell, execute a workload you want to trace.
root@crownbay:/media/sdc# rm linux-2.6.19.2.tar.bz2; wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2; sync
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |*******************************| 41727k 0:00:00 ETA
Press Ctrl-C in the blktrace shell to stop the trace. It will display how many events were logged, along with the per-cpu file sizes (blktrace records traces in per-cpu kernel buffers and simply dumps them to userspace for blkparse to merge and sort later).
^C=== sdc ===
CPU 0: 7082 events, 332 KiB data
CPU 1: 1578 events, 74 KiB data
Total: 8660 events (dropped 0), 406 KiB data
If you examine the files saved to disk, you see multiple files, one per CPU and with the device name as the first part of the filename:
root@crownbay:~# ls -al
drwxr-xr-x 6 root root 1024 Oct 27 22:39 .
drwxr-sr-x 4 root root 1024 Oct 26 18:24 ..
-rw-r--r-- 1 root root 339938 Oct 27 22:40 sdc.blktrace.0
-rw-r--r-- 1 root root 75753 Oct 27 22:40 sdc.blktrace.1
To view the trace events, simply invoke 'blkparse' in the directory containing the trace files, giving it the device name that forms the first part of the filenames:
root@crownbay:~# blkparse sdc
8,32 1 1 0.000000000 1225 Q WS 3417048 + 8 [jbd2/sdc-8]
8,32 1 2 0.000025213 1225 G WS 3417048 + 8 [jbd2/sdc-8]
8,32 1 3 0.000033384 1225 P N [jbd2/sdc-8]
8,32 1 4 0.000043301 1225 I WS 3417048 + 8 [jbd2/sdc-8]
8,32 1 0 0.000057270 0 m N cfq1225 insert_request
8,32 1 0 0.000064813 0 m N cfq1225 add_to_rr
8,32 1 5 0.000076336 1225 U N [jbd2/sdc-8] 1
8,32 1 0 0.000088559 0 m N cfq workload slice:150
8,32 1 0 0.000097359 0 m N cfq1225 set_active wl_prio:0 wl_type:1
8,32 1 0 0.000104063 0 m N cfq1225 Not idling. st->count:1
8,32 1 0 0.000112584 0 m N cfq1225 fifo= (null)
8,32 1 0 0.000118730 0 m N cfq1225 dispatch_insert
8,32 1 0 0.000127390 0 m N cfq1225 dispatched a request
8,32 1 0 0.000133536 0 m N cfq1225 activate rq, drv=1
8,32 1 6 0.000136889 1225 D WS 3417048 + 8 [jbd2/sdc-8]
8,32 1 7 0.000360381 1225 Q WS 3417056 + 8 [jbd2/sdc-8]
8,32 1 8 0.000377422 1225 G WS 3417056 + 8 [jbd2/sdc-8]
8,32 1 9 0.000388876 1225 P N [jbd2/sdc-8]
8,32 1 10 0.000397886 1225 Q WS 3417064 + 8 [jbd2/sdc-8]
8,32 1 11 0.000404800 1225 M WS 3417064 + 8 [jbd2/sdc-8]
8,32 1 12 0.000412343 1225 Q WS 3417072 + 8 [jbd2/sdc-8]
8,32 1 13 0.000416533 1225 M WS 3417072 + 8 [jbd2/sdc-8]
8,32 1 14 0.000422121 1225 Q WS 3417080 + 8 [jbd2/sdc-8]
8,32 1 15 0.000425194 1225 M WS 3417080 + 8 [jbd2/sdc-8]
8,32 1 16 0.000431968 1225 Q WS 3417088 + 8 [jbd2/sdc-8]
8,32 1 17 0.000435251 1225 M WS 3417088 + 8 [jbd2/sdc-8]
8,32 1 18 0.000440279 1225 Q WS 3417096 + 8 [jbd2/sdc-8]
8,32 1 19 0.000443911 1225 M WS 3417096 + 8 [jbd2/sdc-8]
8,32 1 20 0.000450336 1225 Q WS 3417104 + 8 [jbd2/sdc-8]
8,32 1 21 0.000454038 1225 M WS 3417104 + 8 [jbd2/sdc-8]
8,32 1 22 0.000462070 1225 Q WS 3417112 + 8 [jbd2/sdc-8]
8,32 1 23 0.000465422 1225 M WS 3417112 + 8 [jbd2/sdc-8]
8,32 1 24 0.000474222 1225 I WS 3417056 + 64 [jbd2/sdc-8]
8,32 1 0 0.000483022 0 m N cfq1225 insert_request
8,32 1 25 0.000489727 1225 U N [jbd2/sdc-8] 1
8,32 1 0 0.000498457 0 m N cfq1225 Not idling. st->count:1
8,32 1 0 0.000503765 0 m N cfq1225 dispatch_insert
8,32 1 0 0.000512914 0 m N cfq1225 dispatched a request
8,32 1 0 0.000518851 0 m N cfq1225 activate rq, drv=2
.
.
.
8,32 0 0 58.515006138 0 m N cfq3551 complete rqnoidle 1
8,32 0 2024 58.516603269 3 C WS 3156992 + 16 [0]
8,32 0 0 58.516626736 0 m N cfq3551 complete rqnoidle 1
8,32 0 0 58.516634558 0 m N cfq3551 arm_idle: 8 group_idle: 0
8,32 0 0 58.516636933 0 m N cfq schedule dispatch
8,32 1 0 58.516971613 0 m N cfq3551 slice expired t=0
8,32 1 0 58.516982089 0 m N cfq3551 sl_used=13 disp=6 charge=13 iops=0 sect=80
8,32 1 0 58.516985511 0 m N cfq3551 del_from_rr
8,32 1 0 58.516990819 0 m N cfq3551 put_queue
CPU0 (sdc):
Reads Queued: 0, 0KiB Writes Queued: 331, 26,284KiB
Read Dispatches: 0, 0KiB Write Dispatches: 485, 40,484KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 0, 0KiB Writes Completed: 511, 41,000KiB
Read Merges: 0, 0KiB Write Merges: 13, 160KiB
Read depth: 0 Write depth: 2
IO unplugs: 23 Timer unplugs: 0
CPU1 (sdc):
Reads Queued: 0, 0KiB Writes Queued: 249, 15,800KiB
Read Dispatches: 0, 0KiB Write Dispatches: 42, 1,600KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 0, 0KiB Writes Completed: 16, 1,084KiB
Read Merges: 0, 0KiB Write Merges: 40, 276KiB
Read depth: 0 Write depth: 2
IO unplugs: 30 Timer unplugs: 1
Total (sdc):
Reads Queued: 0, 0KiB Writes Queued: 580, 42,084KiB
Read Dispatches: 0, 0KiB Write Dispatches: 527, 42,084KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 0, 0KiB Writes Completed: 527, 42,084KiB
Read Merges: 0, 0KiB Write Merges: 53, 436KiB
IO unplugs: 53 Timer unplugs: 1
Throughput (R/W): 0KiB/s / 719KiB/s
Events (sdc): 6,592 entries
Skips: 0 forward (0 - 0.0%)
Input file sdc.blktrace.0 added
Input file sdc.blktrace.1 added
The report shows each event that was found in the blktrace data, along with a summary of the overall block I/O traffic during the run. You can look at the blkparse manpage to learn the meaning of each field displayed in the trace listing.
blktrace and blkparse are designed from the ground up to be able to operate together in a 'pipe mode' where the stdout of blktrace can be fed directly into the stdin of blkparse:
root@crownbay:~# blktrace /dev/sdc -o - | blkparse -i -
This enables long-lived tracing sessions to run without writing anything to disk, and allows the user to look for certain conditions in the trace data in 'real-time' by viewing the trace output as it scrolls by on the screen or by passing it along to yet another program in the pipeline such as grep which can be used to identify and capture conditions of interest.
There's actually another blktrace command that implements the above pipeline as a single command, so the user doesn't have to bother typing in the above command sequence:
root@crownbay:~# btrace /dev/sdc
Because blktrace traces block I/O and at the same time normally writes its trace data to a block device, and in general because it's not really a great idea to make the device being traced the same as the device the tracer writes to, blktrace provides a way to trace without perturbing the traced device at all by providing native support for sending all trace data over the network.
To have blktrace operate in this mode, start blktrace on the target system being traced with the -l option, along with the device to trace:
root@crownbay:~# blktrace -l /dev/sdc
server: waiting for connections...
On the host system, use the -h option to connect to the target system, also passing it the device to trace:
$ blktrace -d /dev/sdc -h 192.168.1.43
blktrace: connecting to 192.168.1.43
blktrace: connected!
On the target system, you should see this:
server: connection from 192.168.1.43
In another shell, execute a workload you want to trace.
root@crownbay:/media/sdc# rm linux-2.6.19.2.tar.bz2; wget http://downloads.yoctoproject.org/mirror/sources/linux-2.6.19.2.tar.bz2; sync
Connecting to downloads.yoctoproject.org (140.211.169.59:80)
linux-2.6.19.2.tar.b 100% |*******************************| 41727k 0:00:00 ETA
When it's done, do a Ctrl-C on the host system to stop the trace:
^C=== sdc ===
CPU 0: 7691 events, 361 KiB data
CPU 1: 4109 events, 193 KiB data
Total: 11800 events (dropped 0), 554 KiB data
On the target system, you should also see a trace summary for the trace just ended:
server: end of run for 192.168.1.43:sdc
=== sdc ===
CPU 0: 7691 events, 361 KiB data
CPU 1: 4109 events, 193 KiB data
Total: 11800 events (dropped 0), 554 KiB data
The blktrace instance on the host will save the target output inside a hostname-timestamp directory:
$ ls -al
drwxr-xr-x 10 root root 1024 Oct 28 02:40 .
drwxr-sr-x 4 root root 1024 Oct 26 18:24 ..
drwxr-xr-x 2 root root 1024 Oct 28 02:40 192.168.1.43-2012-10-28-02:40:56
cd into that directory to see the output files:
$ ls -l
-rw-r--r-- 1 root root 369193 Oct 28 02:44 sdc.blktrace.0
-rw-r--r-- 1 root root 197278 Oct 28 02:44 sdc.blktrace.1
And run blkparse on the host system using the device name:
$ blkparse sdc
8,32 1 1 0.000000000 1263 Q RM 6016 + 8 [ls]
8,32 1 0 0.000036038 0 m N cfq1263 alloced
8,32 1 2 0.000039390 1263 G RM 6016 + 8 [ls]
8,32 1 3 0.000049168 1263 I RM 6016 + 8 [ls]
8,32 1 0 0.000056152 0 m N cfq1263 insert_request
8,32 1 0 0.000061600 0 m N cfq1263 add_to_rr
8,32 1 0 0.000075498 0 m N cfq workload slice:300
.
.
.
8,32 0 0 177.266385696 0 m N cfq1267 arm_idle: 8 group_idle: 0
8,32 0 0 177.266388140 0 m N cfq schedule dispatch
8,32 1 0 177.266679239 0 m N cfq1267 slice expired t=0
8,32 1 0 177.266689297 0 m N cfq1267 sl_used=9 disp=6 charge=9 iops=0 sect=56
8,32 1 0 177.266692649 0 m N cfq1267 del_from_rr
8,32 1 0 177.266696560 0 m N cfq1267 put_queue
CPU0 (sdc):
Reads Queued: 0, 0KiB Writes Queued: 270, 21,708KiB
Read Dispatches: 59, 2,628KiB Write Dispatches: 495, 39,964KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 90, 2,752KiB Writes Completed: 543, 41,596KiB
Read Merges: 0, 0KiB Write Merges: 9, 344KiB
Read depth: 2 Write depth: 2
IO unplugs: 20 Timer unplugs: 1
CPU1 (sdc):
Reads Queued: 688, 2,752KiB Writes Queued: 381, 20,652KiB
Read Dispatches: 31, 124KiB Write Dispatches: 59, 2,396KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 0, 0KiB Writes Completed: 11, 764KiB
Read Merges: 598, 2,392KiB Write Merges: 88, 448KiB
Read depth: 2 Write depth: 2
IO unplugs: 52 Timer unplugs: 0
Total (sdc):
Reads Queued: 688, 2,752KiB Writes Queued: 651, 42,360KiB
Read Dispatches: 90, 2,752KiB Write Dispatches: 554, 42,360KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 90, 2,752KiB Writes Completed: 554, 42,360KiB
Read Merges: 598, 2,392KiB Write Merges: 97, 792KiB
IO unplugs: 72 Timer unplugs: 1
Throughput (R/W): 15KiB/s / 238KiB/s
Events (sdc): 9,301 entries
Skips: 0 forward (0 - 0.0%)
You should see the trace events and summary just as you would have if you'd run the same command on the target.
It's also possible to trace block I/O using only trace events subsystem, which can be useful for casual tracing if you don't want to bother dealing with the userspace tools.
To enable tracing for a given device, use /sys/block/xxx/trace/enable, where xxx is the device name. This for example enables tracing for /dev/sdc:
root@crownbay:/sys/kernel/debug/tracing# echo 1 > /sys/block/sdc/trace/enable
Once you've selected the device(s) you want to trace, selecting the 'blk' tracer will turn the blk tracer on:
root@crownbay:/sys/kernel/debug/tracing# cat available_tracers
blk function_graph function nop
root@crownbay:/sys/kernel/debug/tracing# echo blk > current_tracer
Execute the workload you're interested in:
root@crownbay:/sys/kernel/debug/tracing# cat /media/sdc/testfile.txt
And look at the output (note here that we're using 'trace_pipe' instead of trace to capture this trace - this allows us to wait around on the pipe for data to appear):
root@crownbay:/sys/kernel/debug/tracing# cat trace_pipe
cat-3587 [001] d..1 3023.276361: 8,32 Q R 1699848 + 8 [cat]
cat-3587 [001] d..1 3023.276410: 8,32 m N cfq3587 alloced
cat-3587 [001] d..1 3023.276415: 8,32 G R 1699848 + 8 [cat]
cat-3587 [001] d..1 3023.276424: 8,32 P N [cat]
cat-3587 [001] d..2 3023.276432: 8,32 I R 1699848 + 8 [cat]
cat-3587 [001] d..1 3023.276439: 8,32 m N cfq3587 insert_request
cat-3587 [001] d..1 3023.276445: 8,32 m N cfq3587 add_to_rr
cat-3587 [001] d..2 3023.276454: 8,32 U N [cat] 1
cat-3587 [001] d..1 3023.276464: 8,32 m N cfq workload slice:150
cat-3587 [001] d..1 3023.276471: 8,32 m N cfq3587 set_active wl_prio:0 wl_type:2
cat-3587 [001] d..1 3023.276478: 8,32 m N cfq3587 fifo= (null)
cat-3587 [001] d..1 3023.276483: 8,32 m N cfq3587 dispatch_insert
cat-3587 [001] d..1 3023.276490: 8,32 m N cfq3587 dispatched a request
cat-3587 [001] d..1 3023.276497: 8,32 m N cfq3587 activate rq, drv=1
cat-3587 [001] d..2 3023.276500: 8,32 D R 1699848 + 8 [cat]
And this turns off tracing for the specified device:
root@crownbay:/sys/kernel/debug/tracing# echo 0 > /sys/block/sdc/trace/enable
Online versions of the man pages for the commands discussed in this section can be found here:
The above manpages, along with manpages for the other blktrace utilities (btt, blkiomon, etc) can be found in the /doc directory of the blktrace tools git repo:
$ git clone git://git.kernel.dk/blktrace.git
This chapter contains real-world examples.
In one of our previous releases (denzil), users noticed that booting off of a live image and writing to disk was noticeably slower. This included the boot itself, especially the first one, since first boots tend to do a significant amount of writing due to certain post-install scripts.
The problem (and solution) was discovered by using the Yocto tracing tools, in this case 'perf stat', 'perf script', 'perf record' and 'perf report'.
See all the unvarnished details of how this bug was diagnosed and solved here: Yocto Bug #3049
 |
Copyright © 2010-2014 Linux Foundation
Permission is granted to copy, distribute and/or modify this document under the terms of the Creative Commons Attribution-Share Alike 2.0 UK: England & Wales as published by Creative Commons.
Note
For the latest version of this manual associated with this Yocto Project release, see the Yocto Project Reference Manual from the Yocto Project website.| Revision History | |
|---|---|
| Revision 4.0+git | 24 November 2010 |
| Released with the Yocto Project 0.9 Release | |
| Revision 1.0 | 6 April 2011 |
| Released with the Yocto Project 1.0 Release. | |
| Revision 1.0.1 | 23 May 2011 |
| Released with the Yocto Project 1.0.1 Release. | |
| Revision 1.1 | 6 October 2011 |
| Released with the Yocto Project 1.1 Release. | |
| Revision 1.2 | April 2012 |
| Released with the Yocto Project 1.2 Release. | |
| Revision 1.3 | October 2012 |
| Released with the Yocto Project 1.3 Release. | |
| Revision 1.4 | April 2013 |
| Released with the Yocto Project 1.4 Release. | |
| Revision 1.5 | October 2013 |
| Released with the Yocto Project 1.5 Release. | |
| Revision 1.5.1 | January 2014 |
| Released with the Yocto Project 1.5.1 Release. | |
| Revision 1.5.2 | May 2014 |
| Released with the Yocto Project 1.5.2 Release. | |
This manual provides reference information for the current release of the Yocto Project. The Yocto Project is an open-source collaboration project focused on embedded Linux developers. Amongst other things, the Yocto Project uses the OpenEmbedded build system, which is based on the Poky project, to construct complete Linux images. You can find complete introductory and getting started information on the Yocto Project by reading the Yocto Project Quick Start. For task-based information using the Yocto Project, see the Yocto Project Development Manual and the Yocto Project Linux Kernel Development Manual. For Board Support Package (BSP) structure information, see the Yocto Project Board Support Package (BSP) Developer's Guide. You can also find lots of Yocto Project information on the Yocto Project website.
This reference manual consists of the following:
Using the Yocto Project: Provides an overview of the components that make up the Yocto Project followed by information about debugging images created in the Yocto Project.
Technical Details: Describes fundamental Yocto Project components as well as an explanation behind how the Yocto Project uses shared state (sstate) cache to speed build time.
Directory Structure: Describes the Source Directory created either by unpacking a released Yocto Project tarball on your host development system, or by cloning the upstream Poky Git repository.
BitBake: Provides an overview of the BitBake tool and its role within the Yocto Project.
Classes: Describes the classes used in the Yocto Project.
Images: Describes the standard images that the Yocto Project supports.
Features: Describes mechanisms for creating distribution, machine, and image features during the build process using the OpenEmbedded build system.
Variables Glossary: Presents most variables used by the OpenEmbedded build system, which uses BitBake. Entries describe the function of the variable and how to apply them.
Variable Context: Provides variable locality or context.
FAQ: Provides answers for commonly asked questions in the Yocto Project development environment.
Contributing to the Yocto Project: Provides guidance on how you can contribute back to the Yocto Project.
For general Yocto Project system requirements, see the "What You Need and How You Get It" section in the Yocto Project Quick Start. The remainder of this section provides details on system requirements not covered in the Yocto Project Quick Start.
Currently, the Yocto Project is supported on the following distributions:
Note
Yocto Project releases are tested against the stable Linux distributions in the following list. The Yocto Project should work on other distributions but validation is not performed against them.
In particular, the Yocto Project does not support and currently has no plans to support rolling-releases or development distributions due to their constantly changing nature. We welcome patches and bug reports, but keep in mind that our priority is on the supported platforms listed below.
If you encounter problems, please go to Yocto Project Bugzilla and submit a bug. We are interested in hearing about your experience.
Ubuntu 12.04 (LTS)
Ubuntu 12.10
Ubuntu 13.04
Fedora release 18 (Spherical Cow)
Fedora release 19 (Schrödinger's Cat)
CentOS release 6.4
Debian GNU/Linux 6.0.7 (Squeeze)
Debian GNU/Linux 7.0 (Wheezy)
Debian GNU/Linux 7.1 (Wheezy)
openSUSE 12.2
openSUSE 12.3
Note
While the Yocto Project Team attempts to ensure all Yocto Project releases are one hundred percent compatible with each officially supported Linux distribution, instances might exist where you encounter a problem while using the Yocto Project on a specific distribution. For example, the CentOS 6.4 distribution does not include the Gtk+ 2.20.0 and PyGtk 2.21.0 (or higher) packages, which are required to run Hob.The list of packages you need on the host development system can be large when covering all build scenarios using the Yocto Project. This section provides required packages according to Linux distribution and function.
The following list shows the required packages by function given a supported Ubuntu or Debian Linux distribution:
Essentials: Packages needed to build an image on a headless system:
$ sudo apt-get install gawk wget git-core diffstat unzip texinfo gcc-multilib \ build-essential chrpathGraphical Extras: Packages recommended if the host system has graphics support:
$ sudo apt-get install libsdl1.2-dev xtermDocumentation: Packages needed if you are going to build out the Yocto Project documentation manuals:
$ sudo apt-get install make xsltproc docbook-utils fop dblatex xmltoADT Installer Extras: Packages needed if you are going to be using the Application Development Toolkit (ADT) Installer:
$ sudo apt-get install autoconf automake libtool libglib2.0-dev
The following list shows the required packages by function given a supported Fedora Linux distribution:
Essentials: Packages needed to build an image for a headless system:
$ sudo yum install gawk make wget tar bzip2 gzip python unzip perl patch \ diffutils diffstat git cpp gcc gcc-c++ glibc-devel texinfo chrpath \ ccache perl-Data-Dumper perl-Text-ParseWordsGraphical Extras: Packages recommended if the host system has graphics support:
$ sudo yum install SDL-devel xtermDocumentation: Packages needed if you are going to build out the Yocto Project documentation manuals:
$ sudo yum install make docbook-style-dsssl docbook-style-xsl \ docbook-dtds docbook-utils fop libxslt dblatex xmltoADT Installer Extras: Packages needed if you are going to be using the Application Development Toolkit (ADT) Installer:
$ sudo yum install autoconf automake libtool glib2-devel
The following list shows the required packages by function given a supported openSUSE Linux distribution:
Essentials: Packages needed to build an image for a headless system:
$ sudo zypper install python gcc gcc-c++ git chrpath make wget python-xml \ diffstat texinfo python-curses patchGraphical Extras: Packages recommended if the host system has graphics support:
$ sudo zypper install libSDL-devel xtermDocumentation: Packages needed if you are going to build out the Yocto Project documentation manuals:
$ sudo zypper install make fop xsltproc dblatex xmltoADT Installer Extras: Packages needed if you are going to be using the Application Development Toolkit (ADT) Installer:
$ sudo zypper install autoconf automake libtool glib2-devel
The following list shows the required packages by function given a supported CentOS Linux distribution:
Note
Depending on the CentOS version you are using, other requirements and dependencies might exist. For details, you should look at the CentOS sections on the Poky/GettingStarted/Dependencies wiki page.
Essentials: Packages needed to build an image for a headless system:
$ sudo yum install gawk make wget tar bzip2 gzip python unzip perl patch \ diffutils diffstat git cpp gcc gcc-c++ glibc-devel texinfo chrpathGraphical Extras: Packages recommended if the host system has graphics support:
$ sudo yum install SDL-devel xtermDocumentation: Packages needed if you are going to build out the Yocto Project documentation manuals:
$ sudo yum install make docbook-style-dsssl docbook-style-xsl \ docbook-dtds docbook-utils fop libxslt dblatex xmltoADT Installer Extras: Packages needed if you are going to be using the Application Development Toolkit (ADT) Installer:
$ sudo yum install autoconf automake libtool glib2-devel
In order to use the build system, your host development system must meet the following version requirements for Git, tar, and Python:
Git 1.7.5 or greater
tar 1.24 or greater
Python 2.7.3 or greater not including Python 3.x, which is not supported.
If your host development system does not meet all these requirements,
you can resolve this by either downloading a pre-built tarball
containing these tools, or building such a tarball on another
system.
Regardless of the method, once you have the tarball, you simply
install it somewhere on your system, such as a directory in your
home directory, and then source the environment script provided,
which adds the tools into PATH and sets
any other environment variables required to run the tools.
Doing so gives you working versions of Git, tar, Python and
chrpath.
If downloading a pre-built tarball, locate the
*.sh at
http://downloads.yoctoproject.org/releases/yocto/yocto-1.5.2/buildtools/.
If building your own tarball, do so using this command:
$ bitbake buildtools-tarball
Note
TheSDKMACHINE
variable determines whether you build tools for a 32-bit
or 64-bit system.
Once the build completes, you can find the file that installs
the tools in the tmp/deploy/sdk subdirectory
of the
Build Directory.
The file used to install the tarball has the string "buildtools"
in the name.
After you have either built the tarball or downloaded it, you need
to install it.
Install the tools by executing the *.sh file.
During execution, a prompt appears that allows you to choose the
installation directory.
For example, you could choose the following:
/home/your-username/sdk
The final step before you can actually use the tools is to source the tools environment with a command like the following:
$ source /home/your-username/sdk/environment-setup-i586-poky-linux
Of course, you need to supply your installation directory and be sure to use the right file (i.e. i585 or x86-64).
The Yocto Project development team makes the Yocto Project available through a number of methods:
Releases: Stable, tested releases are available through http://downloads.yoctoproject.org/releases/yocto/.
Nightly Builds: These releases are available at http://autobuilder.yoctoproject.org/nightly. These builds include Yocto Project releases, meta-toolchain tarball installation scripts, and experimental builds.
Yocto Project Website: You can find releases of the Yocto Project and supported BSPs at the Yocto Project website. Along with these downloads, you can find lots of other information at this site.
Development using the Yocto Project requires a local Source Directory. You can set up the Source Directory by downloading a Yocto Project release tarball and unpacking it, or by cloning a copy of the upstream Poky Git repository. For information on both these methods, see the "Getting Set Up" section in the Yocto Project Development Manual.
This chapter describes common usage for the Yocto Project. The information is introductory in nature as other manuals in the Yocto Project documentation set provide more details on how to use the Yocto Project.
This section provides a summary of the build process and provides information for less obvious aspects of the build process. For general information on how to build an image using the OpenEmbedded build system, see the "Building an Image" section of the Yocto Project Quick Start.
The first thing you need to do is set up the OpenEmbedded build
environment by sourcing an environment setup script
(i.e.
oe-init-build-env
or
oe-init-build-env-memres).
Here is an example:
$ source oe-init-build-env [<build_dir>]
The build_dir argument is optional and specifies the directory the
OpenEmbedded build system uses for the build -
the Build Directory.
If you do not specify a Build Directory, it defaults to a directory
named build in your current working directory.
A common practice is to use a different Build Directory for different targets.
For example, ~/build/x86 for a qemux86
target, and ~/build/arm for a qemuarm target.
See the "oe-init-build-env"
section for more information on this script.
Once the build environment is set up, you can build a target using:
$ bitbake <target>
The target is the name of the recipe you want to build.
Common targets are the images in meta/recipes-core/images,
meta/recipes-sato/images, etc. all found in the
Source Directory.
Or, the target can be the name of a recipe for a specific piece of software such as
BusyBox.
For more details about the images the OpenEmbedded build system supports, see the
"Images" chapter.
Note
Building an image without GNU General Public License Version 3 (GPLv3) components is supported for only minimal and base images. See the "Images" chapter for more information.When building an image using GPL components, you need to maintain your original settings and not switch back and forth applying different versions of the GNU General Public License. If you rebuild using different versions of GPL, dependency errors might occur due to some components not being rebuilt.
Once an image has been built, it often needs to be installed.
The images and kernels built by the OpenEmbedded build system are placed in the
Build Directory in
tmp/deploy/images.
For information on how to run pre-built images such as qemux86
and qemuarm, see the
"Using Pre-Built Binaries and QEMU"
section in the Yocto Project Quick Start.
For information about how to install these images, see the documentation for your
particular board or machine.
The exact method for debugging build failures depends on the nature of the problem and on the system's area from which the bug originates. Standard debugging practices such as comparison against the last known working version with examination of the changes and the re-application of steps to identify the one causing the problem are valid for the Yocto Project just as they are for any other system. Even though it is impossible to detail every possible potential failure, this section provides some general tips to aid in debugging.
For discussions on debugging, see the "Debugging With the GNU Project Debugger (GDB) Remotely" and "Working within Eclipse" sections in the Yocto Project Development Manual.
The log file for shell tasks is available in
${WORKDIR}/temp/log.do_taskname.pid.
For example, the compile task for the QEMU minimal image for the x86
machine (qemux86) might be
tmp/work/qemux86-poky-linux/core-image-minimal/1.0-r0/temp/log.do_compile.20830.
To see what BitBake runs to generate that log, look at the corresponding
run.do_taskname.pid file located in the same directory.
Presently, the output from Python tasks is sent directly to the console.
Any given package consists of a set of tasks.
The standard BitBake behavior in most cases is: fetch,
unpack,
patch, configure,
compile, install, package,
package_write, and build.
The default task is build and any tasks on which it depends
build first.
Some tasks, such as devshell, are not part of the
default build chain.
If you wish to run a task that is not part of the default build chain, you can use the
-c option in BitBake.
Here is an example:
$ bitbake matchbox-desktop -c devshell
If you wish to rerun a task, use the -f force
option.
For example, the following sequence forces recompilation after
changing files in the work directory.
$ bitbake matchbox-desktop
.
.
[make some changes to the source code in the work directory]
.
.
$ bitbake matchbox-desktop -c compile -f
$ bitbake matchbox-desktop
This sequence first builds and then recompiles
matchbox-desktop.
The last command reruns all tasks (basically the packaging tasks) after the compile.
BitBake recognizes that the compile task was rerun and therefore
understands that the other tasks also need to be run again.
You can view a list of tasks in a given package by running the
listtasks task as follows:
$ bitbake matchbox-desktop -c listtasks
The results are in the file ${WORKDIR}/temp/log.do_listtasks.
Sometimes it can be hard to see why BitBake wants to build
other packages before building a given package you have specified.
The bitbake -g <targetname> command
creates the pn-buildlist,
pn-depends.dot,
package-depends.dot, and
task-depends.dot files in the current
directory.
These files show what will be built and the package and task
dependencies, which are useful for debugging problems.
You can use the
bitbake -g -u depexp <targetname>
command to display the results in a more human-readable form.
You can see debug output from BitBake by using the -D option.
The debug output gives more information about what BitBake
is doing and the reason behind it.
Each -D option you use increases the logging level.
The most common usage is -DDD.
The output from bitbake -DDD -v targetname can reveal why
BitBake chose a certain version of a package or why BitBake
picked a certain provider.
This command could also help you in a situation where you think BitBake did something
unexpected.
Sometimes issues on the host development system can cause your build to fail. Following are known, host-specific problems. Be sure to always consult the Release Notes for a look at all release-related issues.
eglibc-initialfails to build: If your development host system has the unpatchedGNU Make 3.82, thedo_installtask fails foreglibc-initialduring the build.Typically, every distribution that ships
GNU Make 3.82as the default already has the patched version. However, some distributions, such as Debian, haveGNU Make 3.82as an option, which is unpatched. You will see this error on these types of distributions. Switch toGNU Make 3.81or patch yourmaketo solve the problem.
To build a specific recipe (.bb file),
you can use the following command form:
$ bitbake -b <somepath/somerecipe.bb>
This command form does not check for dependencies. Consequently, you should use it only when you know dependencies already exist.
Note
You can also specify fragments of the filename. In this case, BitBake checks for a unique match.
You can use the -e BitBake option to
display the parsing environment for a configuration.
The following displays the general parsing environment:
$ bitbake -e
This next example shows the parsing environment for a specific recipe:
$ bitbake -e <recipename>
Best practices exist while writing recipes that both log build progress and act on build conditions such as warnings and errors. Both Python and Bash language bindings exist for the logging mechanism:
Python: For Python functions, BitBake supports several loglevels:
bb.fatal,bb.error,bb.warn,bb.note,bb.plain, andbb.debug.Bash: For Bash functions, the same set of loglevels exist and are accessed with a similar syntax:
bbfatal,bberror,bbwarn,bbnote,bbplain, andbbdebug.
For guidance on how logging is handled in both Python and Bash recipes, see the
logging.bbclass file in the
meta/classes folder of the
Source Directory.
When creating recipes using Python and inserting code that handles build logs, keep in mind the goal is to have informative logs while keeping the console as "silent" as possible. Also, if you want status messages in the log, use the "debug" loglevel.
Following is an example written in Python. The code handles logging for a function that determines the number of tasks needed to be run:
python do_listtasks() {
bb.debug(2, "Starting to figure out the task list")
if noteworthy_condition:
bb.note("There are 47 tasks to run")
bb.debug(2, "Got to point xyz")
if warning_trigger:
bb.warn("Detected warning_trigger, this might be a problem later.")
if recoverable_error:
bb.error("Hit recoverable_error, you really need to fix this!")
if fatal_error:
bb.fatal("fatal_error detected, unable to print the task list")
bb.plain("The tasks present are abc")
bb.debug(2, "Finished figuring out the tasklist")
}
When creating recipes using Bash and inserting code that handles build logs, you have the same goals - informative with minimal console output. The syntax you use for recipes written in Bash is similar to that of recipes written in Python described in the previous section.
Following is an example written in Bash.
The code logs the progress of the do_my_function function.
do_my_function() {
bbdebug 2 "Running do_my_function"
if [ exceptional_condition ]; then
bbnote "Hit exceptional_condition"
fi
bbdebug 2 "Got to point xyz"
if [ warning_trigger ]; then
bbwarn "Detected warning_trigger, this might cause a problem later."
fi
if [ recoverable_error ]; then
bberror "Hit recoverable_error, correcting"
fi
if [ fatal_error ]; then
bbfatal "fatal_error detected"
fi
bbdebug 2 "Completed do_my_function"
}
Here are some other tips that you might find useful:
When adding new packages, it is worth watching for undesirable items making their way into compiler command lines. For example, you do not want references to local system files like
/usr/lib/or/usr/include/.If you want to remove the
psplashboot splashscreen, addpsplash=falseto the kernel command line. Doing so preventspsplashfrom loading and thus allows you to see the console. It is also possible to switch out of the splashscreen by switching the virtual console (e.g. Fn+Left or Fn+Right on a Zaurus).
Many factors can influence the quality of a build. For example, if you upgrade a recipe to use a new version of an upstream software package or you experiment with some new configuration options, subtle changes can occur that you might not detect until later. Consider the case where your recipe is using a newer version of an upstream package. In this case, a new version of a piece of software might introduce an optional dependency on another library, which is auto-detected. If that library has already been built when the software is building, the software will link to the built library and that library will be pulled into your image along with the new software even if you did not want the library.
The buildhistory class exists to help you maintain
the quality of your build output.
You can use the class to highlight unexpected and possibly unwanted
changes in the build output.
When you enable build history, it records information about the contents of
each package and image and then commits that information to a local Git
repository where you can examine the information.
The remainder of this section describes the following:
How you can enable and disable build history
How to understand what the build history contains
How to limit the information used for build history
How to examine the build history from both a command-line and web interface
Build history is disabled by default.
To enable it, add the following statements to the end of your
conf/local.conf file found in the
Build Directory:
INHERIT += "buildhistory"
BUILDHISTORY_COMMIT = "1"
Enabling build history as previously described causes the build process to collect build output information and commit it to a local Git repository.
Note
Enabling build history increases your build times slightly, particularly for images, and increases the amount of disk space used during the build.
You can disable build history by removing the previous statements
from your conf/local.conf file.
However, you should realize that enabling and disabling
build history in this manner can change the
do_package task checksums which, if you
are using the OEBasicHash signature generator (the default
for many current distro configurations including
DISTRO = "poky" and
DISTRO = "") will result in the packaging
tasks being re-run during the subsequent build.
To disable the build history functionality without causing the
packaging tasks to be re-run, add this statement to your
conf/local.conf file:
BUILDHISTORY_FEATURES = ""
Build history information is kept in
$TMPDIR/buildhistory
in the Build Directory.
The following is an example abbreviated listing:
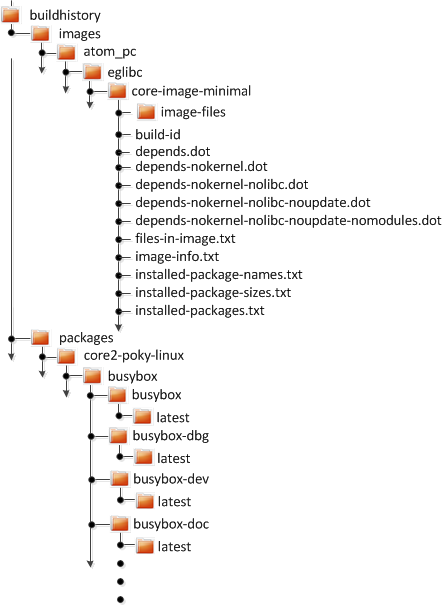 |
At the top level, there is a metadata-revs file
that lists the revisions of the repositories for the layers enabled
when the build was produced.
The rest of the data splits into separate
packages, images and
sdk directories, the contents of which are
described below.
The history for each package contains a text file that has
name-value pairs with information about the package.
For example, buildhistory/packages/core2-poky-linux/busybox/busybox/latest
contains the following:
PV = 1.19.3
PR = r3
RDEPENDS = update-rc.d eglibc (>= 2.13)
RRECOMMENDS = busybox-syslog busybox-udhcpc
PKGSIZE = 564701
FILES = /usr/bin/* /usr/sbin/* /usr/libexec/* /usr/lib/lib*.so.* \
/etc /com /var /bin/* /sbin/* /lib/*.so.* /usr/share/busybox \
/usr/lib/busybox/* /usr/share/pixmaps /usr/share/applications \
/usr/share/idl /usr/share/omf /usr/share/sounds /usr/lib/bonobo/servers
FILELIST = /etc/busybox.links /etc/init.d/hwclock.sh /bin/busybox /bin/sh
Most of these name-value pairs correspond to variables used
to produce the package.
The exceptions are FILELIST, which is the
actual list of files in the package, and
PKGSIZE, which is the total size of files
in the package in bytes.
There is also a file corresponding to the recipe from which the
package came (e.g.
buildhistory/packages/core2-poky-linux/busybox/latest):
PV = 1.19.3
PR = r3
DEPENDS = virtual/i586-poky-linux-gcc virtual/i586-poky-linux-compilerlibs \
virtual/libc update-rc.d-native
PACKAGES = busybox-httpd busybox-udhcpd busybox-udhcpc busybox-syslog \
busybox-mdev busybox-dbg busybox busybox-doc busybox-dev \
busybox-staticdev busybox-locale
Finally, for those recipes fetched from a version control
system (e.g., Git), a file exists that lists source revisions
that are specified in the recipe and lists the actual revisions
used during the build.
Listed and actual revisions might differ when
SRCREV
is set to
${AUTOREV}.
Here is an example assuming
buildhistory/packages/emenlow-poky-linux/linux-yocto/latest_srcrev):
# SRCREV_machine = "b5c37fe6e24eec194bb29d22fdd55d73bcc709bf"
SRCREV_machine = "b5c37fe6e24eec194bb29d22fdd55d73bcc709bf"
# SRCREV_emgd = "caea08c988e0f41103bbe18eafca20348f95da02"
SRCREV_emgd = "caea08c988e0f41103bbe18eafca20348f95da02"
# SRCREV_meta = "c2ed0f16fdec628242a682897d5d86df4547cf24"
SRCREV_meta = "c2ed0f16fdec628242a682897d5d86df4547cf24"
You can use the buildhistory-collect-srcrevs
command to collect the stored SRCREV values
from build history and report them in a format suitable for use in
global configuration (e.g., local.conf
or a distro include file) to override floating
AUTOREV values to a fixed set of revisions.
Here is some example output from this command:
# emenlow-poky-linux
SRCREV_machine_pn-linux-yocto = "b5c37fe6e24eec194bb29d22fdd55d73bcc709bf"
SRCREV_emgd_pn-linux-yocto = "caea08c988e0f41103bbe18eafca20348f95da02"
SRCREV_meta_pn-linux-yocto = "c2ed0f16fdec628242a682897d5d86df4547cf24"
# core2-poky-linux
SRCREV_pn-kmod = "62081c0f68905b22f375156d4532fd37fa5c8d33"
SRCREV_pn-blktrace = "d6918c8832793b4205ed3bfede78c2f915c23385"
SRCREV_pn-opkg = "649"
Note
Here are some notes on using thebuildhistory-collect-srcrevs command:
By default, only values where the
SRCREVwas not hardcoded (usually whenAUTOREVwas used) are reported. Use the-aoption to see allSRCREVvalues.The output statements might not have any effect if overrides are applied elsewhere in the build system configuration. Use the
-foption to add theforcevariableoverride to each output line if you need to work around this restriction.The script does apply special handling when building for multiple machines. However, the script does place a comment before each set of values that specifies which triplet to which they belong as shown above (e.g.,
emenlow-poky-linux).
The files produced for each image are as follows:
image-files:A directory containing selected files from the root filesystem. The files are defined byBUILDHISTORY_IMAGE_FILES.build-id:Human-readable information about the build configuration and metadata source revisions.*.dot:Dependency graphs for the image that are compatible withgraphviz.files-in-image.txt:A list of files in the image with permissions, owner, group, size, and symlink information.image-info.txt:A text file containing name-value pairs with information about the image. See the following listing example for more information.installed-package-names.txt:A list of installed packages by name only.installed-package-sizes.txt:A list of installed packages ordered by size.installed-packages.txt:A list of installed packages with full package filenames.
Note
Installed package information is able to be gathered and produced even if package management is disabled for the final image.
Here is an example of image-info.txt:
DISTRO = poky
DISTRO_VERSION = 1.1+snapshot-20120207
USER_CLASSES = image-mklibs image-prelink
IMAGE_CLASSES = image_types
IMAGE_FEATURES = debug-tweaks x11-base apps-x11-core \
package-management ssh-server-dropbear package-management
IMAGE_LINGUAS = en-us en-gb
IMAGE_INSTALL = task-core-boot task-base-extended
BAD_RECOMMENDATIONS =
ROOTFS_POSTPROCESS_COMMAND = buildhistory_get_image_installed ; rootfs_update_timestamp ;
IMAGE_POSTPROCESS_COMMAND = buildhistory_get_imageinfo ;
IMAGESIZE = 171816
Other than IMAGESIZE, which is the
total size of the files in the image in Kbytes, the
name-value pairs are variables that may have influenced the
content of the image.
This information is often useful when you are trying to determine
why a change in the package or file listings has occurred.
As you can see, build history produces image information,
including dependency graphs, so you can see why something
was pulled into the image.
If you are just interested in this information and not
interested in collecting history or any package information,
you can enable writing only image information without
any history by adding the following
to your conf/local.conf file found in the
Build Directory:
INHERIT += "buildhistory"
BUILDHISTORY_COMMIT = "0"
BUILDHISTORY_FEATURES = "image"
Build history collects similar information on the contents
of SDKs (e.g., meta-toolchain
or bitbake -c populate_sdk imagename)
as compared to information it collects for images.
The following list shows the files produced for each SDK:
files-in-sdk.txt:A list of files in the SDK with permissions, owner, group, size, and symlink information. This list includes both the host and target parts of the SDK.sdk-info.txt:A text file containing name-value pairs with information about the SDK. See the following listing example for more information.The following information appears under each of the
hostandtargetdirectories for the portions of the SDK that run on the host and on the target, respectively:depends.dot:Dependency graph for the SDK that is compatible withgraphviz.installed-package-names.txt:A list of installed packages by name only.installed-package-sizes.txt:A list of installed packages ordered by size.installed-packages.txt:A list of installed packages with full package filenames.
Here is an example of sdk-info.txt:
DISTRO = poky
DISTRO_VERSION = 1.3+snapshot-20130327
SDK_NAME = poky-eglibc-i686-arm
SDK_VERSION = 1.3+snapshot
SDKMACHINE =
SDKIMAGE_FEATURES = dev-pkgs dbg-pkgs
BAD_RECOMMENDATIONS =
SDKSIZE = 352712
Other than SDKSIZE, which is the
total size of the files in the SDK in Kbytes, the
name-value pairs are variables that might have influenced the
content of the SDK.
This information is often useful when you are trying to
determine why a change in the package or file listings
has occurred.
You can examine build history output from the command line or from a web interface.
To see any changes that have occurred (assuming you have
BUILDHISTORY_COMMIT = "1"), you can simply
use any Git command that allows you to view the history of
a repository.
Here is one method:
$ git log -p
You need to realize, however, that this method does show changes that are not significant (e.g. a package's size changing by a few bytes).
A command-line tool called buildhistory-diff
does exist, though, that queries the Git repository and prints just
the differences that might be significant in human-readable form.
Here is an example:
$ ~/poky/poky/scripts/buildhistory-diff . HEAD^
Changes to images/qemux86_64/eglibc/core-image-minimal (files-in-image.txt):
/etc/anotherpkg.conf was added
/sbin/anotherpkg was added
* (installed-package-names.txt):
* anotherpkg was added
Changes to images/qemux86_64/eglibc/core-image-minimal (installed-package-names.txt):
anotherpkg was added
packages/qemux86_64-poky-linux/v86d: PACKAGES: added "v86d-extras"
* PR changed from "r0" to "r1"
* PV changed from "0.1.10" to "0.1.12"
packages/qemux86_64-poky-linux/v86d/v86d: PKGSIZE changed from 110579 to 144381 (+30%)
* PR changed from "r0" to "r1"
* PV changed from "0.1.10" to "0.1.12"
To see changes to the build history using a web interface, follow
the instruction in the README file here.
http://git.yoctoproject.org/cgit/cgit.cgi/buildhistory-web/.
Here is a sample screenshot of the interface:
 |
This chapter takes a more detailed look at the Yocto Project development environment. The following diagram represents the development environment at a high level. The remainder of this chapter expands on the fundamental input, output, process, and Metadata) blocks in the Yocto Project development environment.
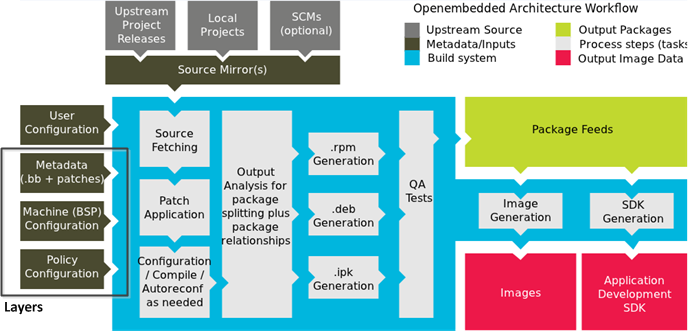 |
The generalized Yocto Project Development Environment consists of several functional areas:
User Configuration: Metadata you can use to control the build process.
Metadata Layers: Various layers that provide software, machine, and distro Metadata.
Source Files: Upstream releases, local projects, and SCMs.
Build System: Processes under the control of BitBake. This block expands on how BitBake fetches source, applies patches, completes compilation, analyzes output for package generation, creates and tests packages, generates images, and generates cross-development tools.
Package Feeds: Directories containing output packages (rpm, deb or ipk), which are subsequently used in the construction of an image or SDK, produced by the build system. These feeds can also be copied and shared using a web server or other means to facilitate extending or updating existing images on devices at runtime if runtime package management is enabled.
Images: Images produced by the development process. Where do they go? Can you mess with them (i.e. freely delete them or move them?).
Application Development SDK: Cross-development tools that are produced along with an image or separately with BitBake.
User configuration helps define the build. Through user configuration, you can tell BitBake the target architecture for which you are building the image, where to store downloaded source, and other build properties.
The following figure shows an expanded representation of the "User Configuration" box of the general Yocto Project Development Environment figure:
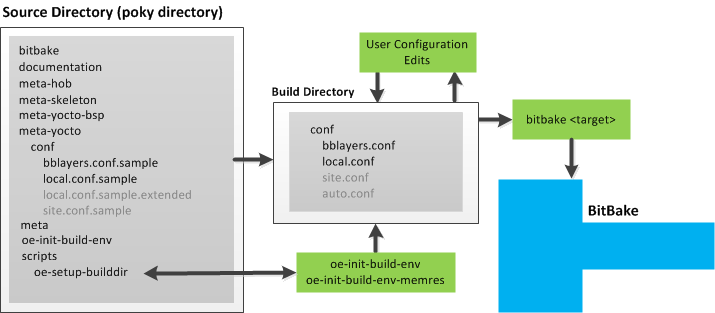 |
BitBake needs some basic configuration files in order to complete
a build.
These files are *.conf files.
The minimally necessary ones reside as example files in the
Source Directory.
For simplicity, this section refers to the Source Directory as
the "Poky Directory."
When you clone the poky Git repository or you
download and unpack a Yocto Project release, you can set up the
Source Directory to be named anything you want.
For this discussion, the cloned repository uses the default
name poky.
Note
The Poky repository is primarily an aggregation of existing repositories. It is not a canonical upstream source.
The meta-yocto layer inside Poky contains
a conf directory that has example
configuration files.
These example files are used as a basis for creating actual
configuration files when you source the build environment
script
(i.e.
oe-init-build-env
or
oe-init-build-env-memres).
Sourcing the build environment script creates a
Build Directory
if one does not already exist.
BitBake uses the Build Directory for all its work during builds.
The Build Directory has a conf directory that
contains default versions of your local.conf
and bblayers.conf configuration files.
These default configuration files are created only if versions
do not already exist in the Build Directory at the time you
source the build environment setup script.
Because the Poky repository is fundamentally an aggregation of
existing repositories, some users might be familiar with running
the oe-init-build-env or
oe-init-build-env-memres script in the context
of separate OpenEmbedded-Core and BitBake repositories rather than a
single Poky repository.
This discussion assumes the script is executed from within a cloned
or unpacked version of Poky.
Depending on where the script is sourced, different sub-scripts
are called to set up the Build Directory (Yocto or OpenEmbedded).
Specifically, the script
scripts/oe-setup-builddir inside the
poky directory sets up the Build Directory and seeds the directory
(if necessary) with configuration files appropriate for the
Yocto Project development environment.
Note
Thescripts/oe-setup-builddir script
uses the $TEMPLATECONF variable to
determine which sample configuration files to locate.
The local.conf file provides many
basic variables that define a build environment.
Here is a list of a few.
To see the default configurations in a local.conf
file created by the build environment script, see the
local.conf.sample in the
meta-yocto layer:
Parallelism Options: Controlled by the
BB_NUMBER_THREADSandPARALLEL_MAKEvariables.Target Machine Selection: Controlled by the
MACHINEvariable.Download Directory: Controlled by the
DL_DIRvariable.Shared State Directory: Controlled by the
SSTATE_DIRvariable.Build Output: Controlled by the
TMPDIRvariable.
Note
Configurations set in theconf/local.conf
file can also be set in the
conf/site.conf and
conf/auto.conf configuration files.
The bblayers.conf file tells BitBake what
layers you want considered during the build.
By default, the layers listed in this file include layers
minimally needed by the build system.
However, you must manually add any custom layers you have created.
You can find more information on working with the
bblayers.conf file in the
"Enabling Your Layer"
section in the Yocto Project Development Manual.
The files site.conf and
auto.conf are not created by the environment
initialization script.
If you want these configuration files, you must create them
yourself:
site.conf: You can use theconf/site.confconfiguration file to configure multiple build directories. For example, suppose you had several build environments and they shared some common features. You can set these default build properties here. A good example is perhaps the level of parallelism you want to use through theBB_NUMBER_THREADSandPARALLEL_MAKEvariables.One useful scenario for using the
conf/site.conffile is to extend yourBBPATHvariable to include the path to aconf/site.conf. Then, when BitBake looks for Metadata usingBBPATH, it finds theconf/site.conffile and applies your common configurations found in the file. To override configurations in a particular build directory, alter the similar configurations within that build directory'sconf/local.conffile.auto.conf: This file is not hand-created. Rather, the file is usually created and written to by an autobuilder. The settings put into the file are typically the same as you would find in theconf/local.confor theconf/site.conffiles.
You can edit all configuration files to further define any particular build environment. This process is represented by the "User Configuration Edits" box in the figure.
When you launch your build with the
bitbake <target> command, BitBake
sorts out the configurations to ultimately define your build
environment.
The previous section described the user configurations that define BitBake's global behavior. This section takes a closer look at the layers the build system uses to further control the build. These layers provide Metadata for the software, machine, and policy.
In general, three types of layer input exist:
Policy Configuration: Distribution Layers provide top-level or general policies for the image or SDK being built. For example, this layer would dictate whether BitBake produces RPM or IPK packages.
Machine Configuration: Board Support Package (BSP) layers provide machine configurations. This type of information is specific to a particular target architecture.
Metadata: Software layers contain user-supplied recipe files, patches, and append files.
The following figure shows an expanded representation of the Metadata, Machine Configuration, and Policy Configuration input (layers) boxes of the general Yocto Project Development Environment figure:
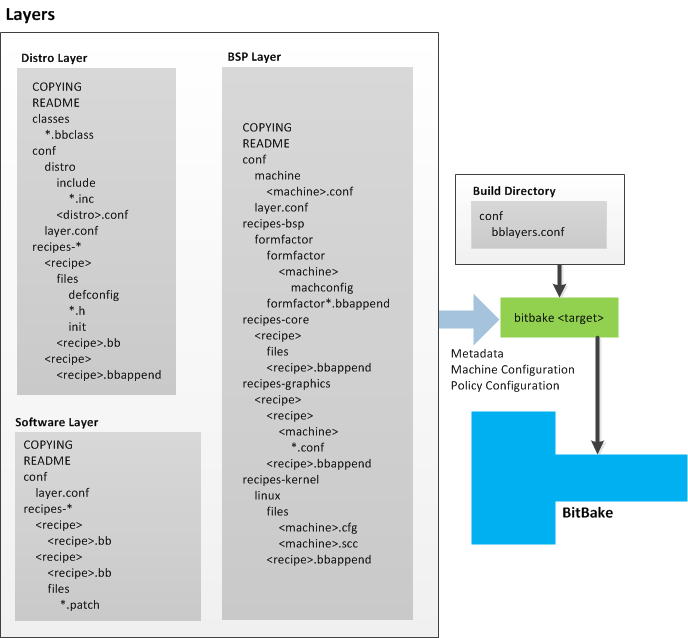 |
In general, all layers have a similar structure.
They all contain a licensing file
(e.g. COPYING) if the layer is to be
distributed, a README file as good practice
and especially if the layer is to be distributed, a
configuration directory, and recipe directories.
The Yocto Project has many layers that can be used. You can see a web-interface listing of them on the Source Repositories page. The layers are shown at the bottom categorized under "Yocto Metadata Layers." These layers are fundamentally a subset of the OpenEmbedded Metadata Index, which lists all layers provided by the OpenEmbedded community.
Note
Layers exist in the Yocto Project Source Repositories that cannot be found in the OpenEmbedded Metadata Index. These layers are either deprecated or experimental in nature.
BitBake uses the conf/bblayers.conf file,
which is part of the user configuration, to find what layers it
should be using as part of the build.
For more information on layers, see the "Understanding and Creating Layers" section in the Yocto Project Development Manual.
The distribution layer provides policy configurations for your
distribution.
Best practices dictate that you isolate these types of
configurations into their own layer.
Settings you provide in
conf/<distro>.conf override similar
settings that BitBake finds in your
conf/local.conf file in the Build
Directory.
The following list provides some explanation and references for what you typically find in the distribution layer:
classes: Class files (
.bbclass) hold common functionality that can be shared among recipes in the distribution. When your recipes inherit a class, they take on the settings and functions for that class. You can read more about class files in the "Classes" section.conf: This area holds configuration files for the layer (
conf/layer.conf), the distribution (conf/distro/<distro>.conf), and any distribution-wide include files.recipes-*: Recipes and append files that affect common functionality across the distribution. This area could include recipes and append files to add distribution-specific configuration, initialization scripts, custom image recipes, and so forth.
The BSP Layer provides machine configurations. Everything in this layer is specific to the machine for which you are building the image or the SDK. A common structure or form is defined for BSP layers. You can learn more about this structure in the Yocto Project Board Support Package (BSP) Developer's Guide.
Note
In order for a BSP layer to be considered compliant with the Yocto Project, it must meet some structural requirements.
The BSP Layer's configuration directory contains
configuration files for the machine
(conf/machine/<machine>.conf) and,
of course, the layer (conf/layer.conf).
The remainder of the layer is dedicated to specific recipes
by function: recipes-bsp,
recipes-core,
recipes-graphics, and
recipes-kernel.
Metadata can exist for multiple formfactors, graphics
support systems, and so forth.
Note
While the figure shows severalrecipes-*
directories, not all these directories appear in all
BSP layers.
The software layer provides the Metadata for additional software packages used during the build. This layer does not include Metadata that is specific to the distribution or the machine, which are found in their respective layers.
This layer contains any new recipes that your project needs in the form of recipe files.
In order for the OpenEmbedded build system to create an image or any target, it must be able to access source files. The general Yocto Project Development Environment figure represents source files using the "Upstream Project Releases", "Local Projects", and "SCMs (optional)" boxes. The figure represents mirrors, which also play a role in locating source files, with the "Source Mirror(s)" box.
The method by which source files are ultimately organized is a function of the project. For example, for released software, projects tend to use tarballs or other archived files that can capture the state of a release guaranteeing that it is statically represented. On the other hand, for a project that is more dynamic or experimental in nature, a project might keep source files in a repository controlled by a Source Control Manager (SCM) such as Git. Pulling source from a repository allows you to control the point in the repository (the revision) from which you want to build software. Finally, a combination of the two might exist, which would give the consumer a choice when deciding where to get source files.
BitBake uses the
SRC_URI
variable to point to source files regardless of their location.
Each recipe must have a SRC_URI variable
that points to the source.
Another area that plays a significant role in where source files
come from is pointed to by the
DL_DIR
variable.
This area is a cache that can hold previously downloaded source.
You can also instruct the OpenEmbedded build system to create
tarballs from Git repositories, which is not the default behavior,
and store them in the DL_DIR by using the
BB_GENERATE_MIRROR_TARBALLS
variable.
Judicious use of a DL_DIR directory can
save the build system a trip across the Internet when looking
for files.
A good method for using a download directory is to have
DL_DIR point to an area outside of your
Build Directory.
Doing so allows you to safely delete the Build Directory
if needed without fear of removing any downloaded source file.
The remainder of this section provides a deeper look into the source files and the mirrors. Here is a more detailed look at the source file area of the base figure:
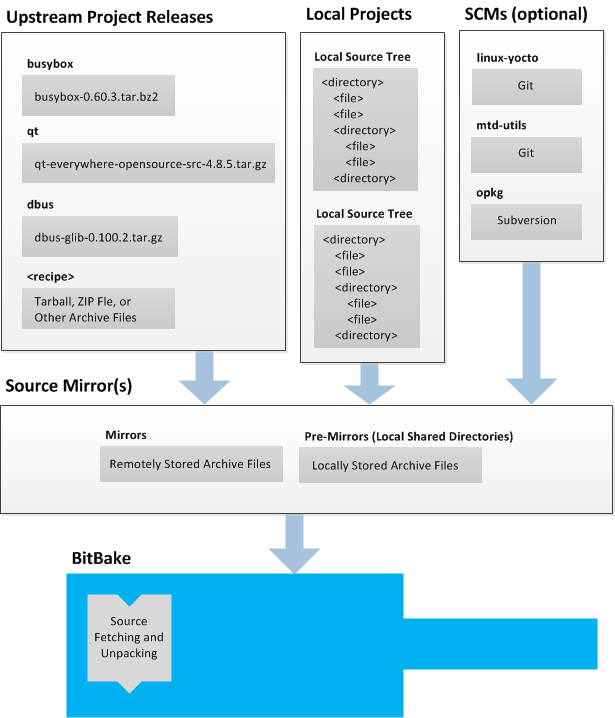 |
Upstream project releases exist anywhere in the form of an archived file (e.g. tarball or zip file). These files correspond to individual recipes. For example, the figure uses specific releases each for BusyBox, Qt, and Dbus. An archive file can be for any released product that can be built using a recipe.
Local projects are custom bits of software the user provides. These bits reside somewhere local to a project - perhaps a directory into which the user checks in items (e.g. a local directory containing a development source tree used by the group).
The canonical method through which to include a local project
is to use the
externalsrc.bbclass
class to include that local project.
You use either the local.conf or a
recipe's append file to override or set the
recipe to point to the local directory on your disk to pull
in the whole source tree.
For information on how to use the
externalsrc.bbclass, see the
"externalsrc.bbclass"
section.
Another place the build system can get source files from is
through an SCM such as Git or Subversion.
In this case, a repository is cloned or checked out.
The do_fetch task inside BitBake uses
the SRC_URI
variable and the argument's prefix to determine the correct
fetcher module.
Note
For information on how to have the OpenEmbedded build system generate tarballs for Git repositories and place them in theDL_DIR
directory, see the
BB_GENERATE_MIRROR_TARBALLS
variable.
When fetching a repository, BitBake uses the
SRCREV
variable to determine the specific revision from which to
build.
Two kinds of mirrors exist: pre-mirrors and regular mirrors.
The PREMIRRORS
and
MIRRORS
variables point to these, respectively.
BitBake checks pre-mirrors before looking upstream for any
source files.
Pre-mirrors are appropriate when you have a shared directory
that is not a directory defined by the
DL_DIR
variable.
A Pre-mirror typically points to a shared directory that is
local to your organization.
Regular mirrors can be any site across the Internet that is used as an alternative location for source code should the primary site not be functioning for some reason or another.
When the OpenEmbedded build system generates an image or an SDK, it gets the packages from a package feed area located in the Build Directory. The general Yocto Project Development Environment figure shows this package feeds area in the upper-right corner.
This section looks a little closer into the package feeds area used by the build system. Here is a more detailed look at the area:
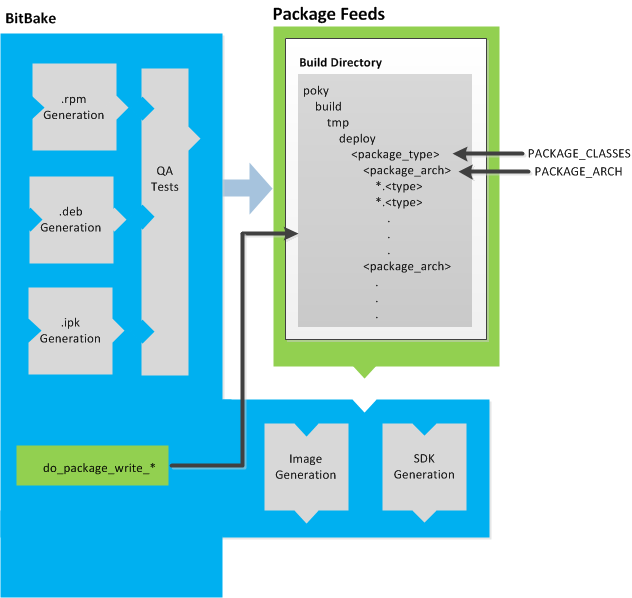 |
Package feeds are an intermediary step in the build process.
BitBake generates packages whose type is defined by the
PACKAGE_CLASSES
variable.
Before placing the packages into package feeds,
the build process validates them with generated output quality
assurance checks through the
insane.bbclass
class.
The package feed area resides in
tmp/deploy of the Build Directory.
Folders are created that correspond to the package type
(IPK, DEB, or RPM) created.
Further organization is derived through the value of the
PACKAGE_ARCH
variable for each package.
For example, packages can exist for the i586 or qemux86
architectures.
The package files themselves reside within the appropriate
architecture folder.
BitBake uses the do_package_write_* task to
place generated packages into the package holding area (e.g.
do_package_write_ipk for IPK packages).
The OpenEmbedded build system uses BitBake to produce images. You can see from the general Yocto Project Development Environment figure, the BitBake area consists of several functional areas. This section takes a closer look at each of those areas.
The first stages of building a recipe are to fetch and unpack the source code:
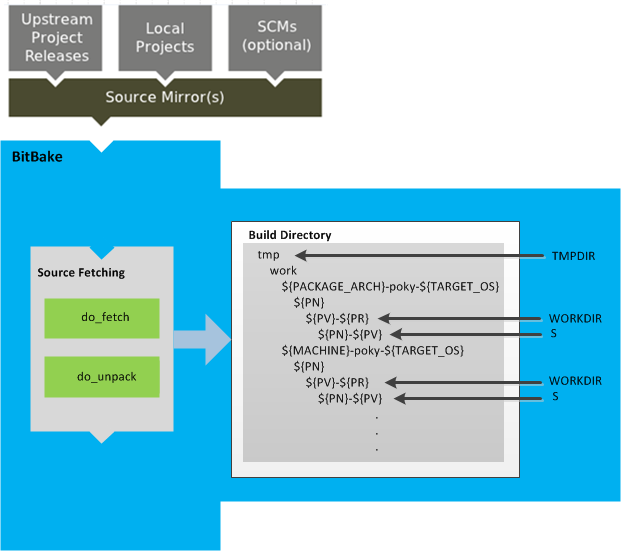 |
The do_fetch and
do_unpack tasks fetch the source files
and unpack them into the work directory.
By default, everything is accomplished in the
Build Directory,
which has a defined structure.
For additional general information on the Build Directory,
see the
"build/"
section.
Unpacked source files are pointed to by the
S variable.
Each recipe has an area in the Build Directory where the
unpacked source code resides.
The name of that directory for any given recipe is defined from
several different variables.
You can see the variables that define these directories
by looking at the figure:
Briefly, the S directory contains the
unpacked source files for a recipe.
The WORKDIR directory is where all the
building goes on for a given recipe.
Once source code is fetched and unpacked, BitBake locates patch files and applies them to the source files:
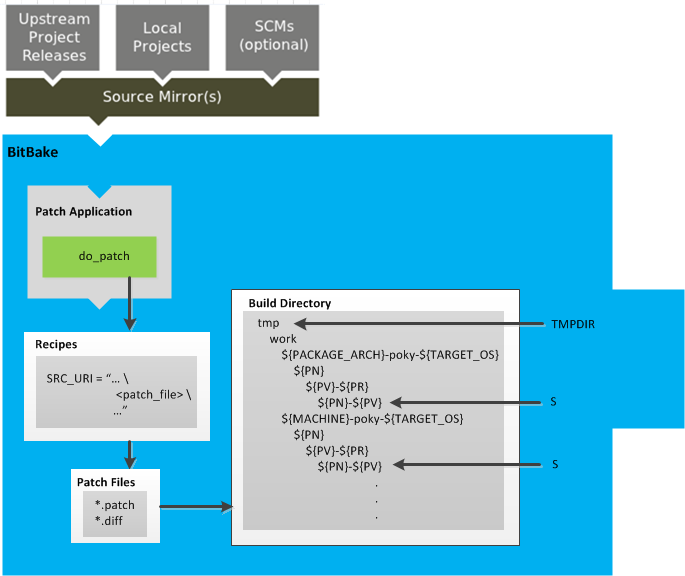 |
The do_patch task processes recipes by
using the
SRC_URI
variable to locate applicable patch files, which by default
are *.patch or
*.diff files, or any file if
"apply=yes" is specified for the file in
SRC_URI.
BitBake finds and applies multiple patches for a single recipe
in the order in which it finds the patches.
Patches are applied to the recipe's source files located in the
S directory.
For more information on how the source directories are created, see the "Source Fetching" section.
After source code is patched, BitBake executes tasks that configure and compile the source code:
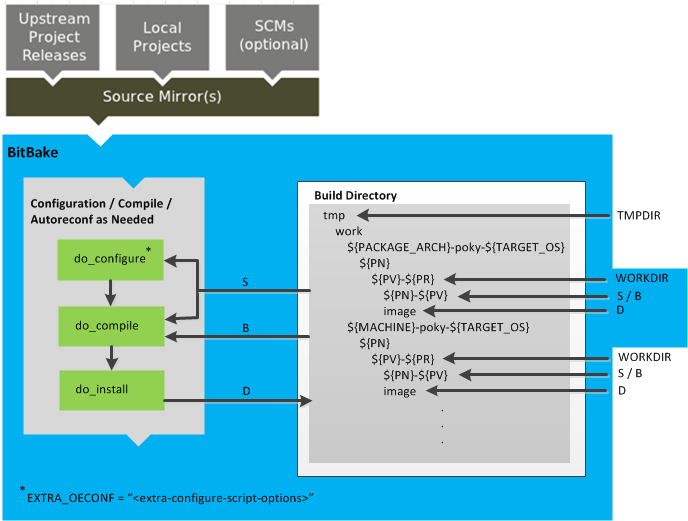 |
This step in the build process consists of three tasks:
do_configure: This task configures the source by enabling and disabling any build-time and configuration options for the software being built. Configurations can come from the recipe itself as well as from an inherited class. Additionally, the software itself might configure itself depending on the target for which it is being built.The configurations handled by the
do_configuretask are specific to source code configuration for the source code being built by the recipe.If you are using
autotools.bbclass, you can add additional configuration options by using theEXTRA_OECONFvariable. For information on how this variable works within that class, see themeta/classes/autotools.bbclassfile.do_compile: Once a configuration task has been satisfied, BitBake compiles the source using thedo_compiletask. Compilation occurs in the directory pointed to by theBvariable. Realize that theBdirectory is, by default, the same as theSdirectory.do_install: Once compilation is done, BitBake executes thedo_installtask. This task copies files from theBdirectory and places them in a holding area pointed to by theDvariable.
After source code is configured and compiled, the OpenEmbedded build system analyzes the results and splits the output into packages:
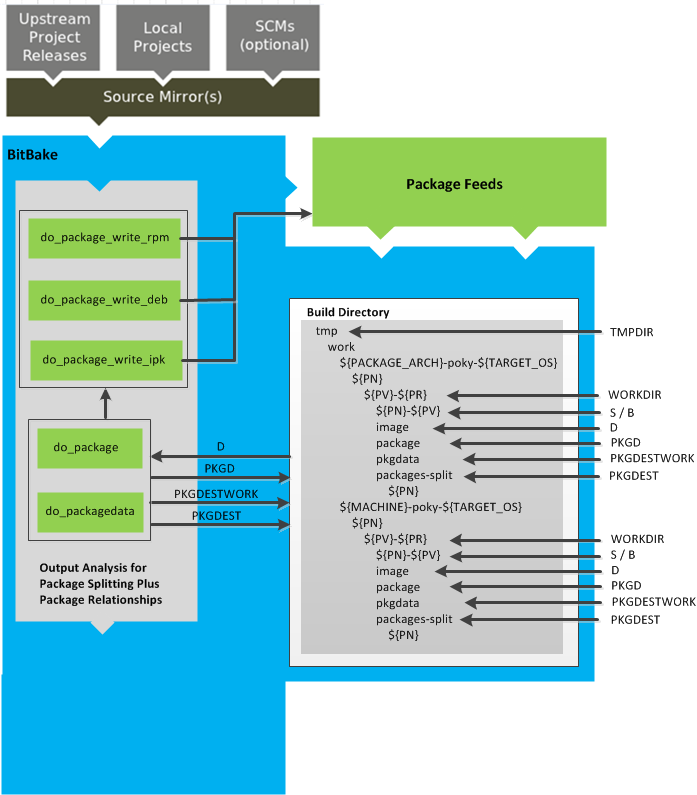 |
The do_package and
do_packagedata tasks combine to analyze
the files found in the
D directory
and split them into subsets based on available packages and
files.
The analyzing process involves the following as well as other
items: splitting out debugging symbols,
looking at shared library dependencies between packages,
and looking at package relationships.
The do_packagedata task creates package
metadata based on the analysis such that the
OpenEmbedded build system can generate the final packages.
Working, staged, and intermediate results of the analysis
and package splitting process use these areas:
The FILES
variable defines the files that go into each package in
PACKAGES.
If you want details on how this is accomplished, you can
look at
package.bbclass.
Depending on the type of packages being created (RPM, DEB, or
IPK), the do_package_write_* task
creates the actual packages and places them in the
Package Feed area, which is
${TMPDIR}/deploy.
You can see the
"Package Feeds"
section for more detail on that part of the build process.
Note
Support for creating feeds directly from thedeploy/* directories does not exist.
Creating such feeds usually requires some kind of feed
maintenance mechanism that would upload the new packages
into an official package feed (e.g. the
Ångström distribution).
This functionality is highly distribution-specific
and thus is not provided out of the box.
Once packages are split and stored in the Package Feeds area, the OpenEmbedded build system uses BitBake to generate the root filesystem image:
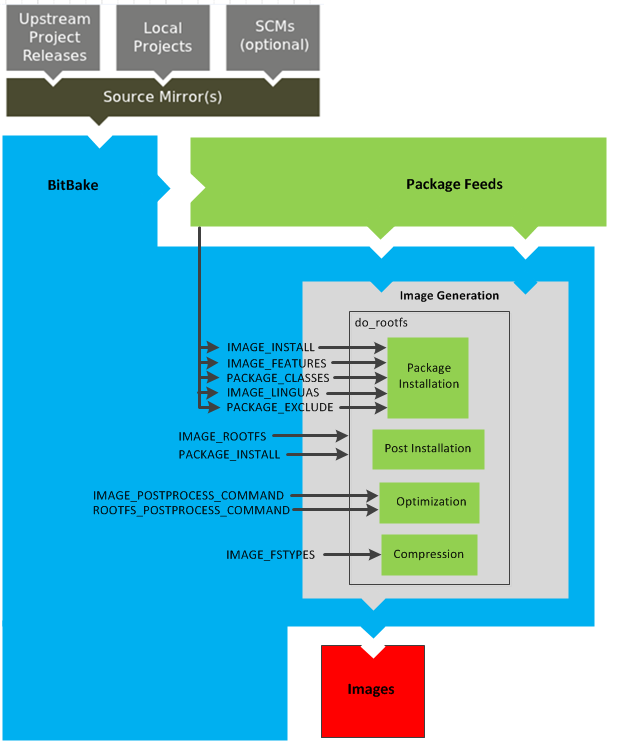 |
The image generation process consists of several stages and
depends on many variables.
The do_rootfs task uses these key variables
to help create the list of packages to actually install:
IMAGE_INSTALL: Lists out the base set of packages to install from the Package Feeds area.PACKAGE_EXCLUDE: Specifies packages that should not be installed.IMAGE_FEATURES: Specifies features to include in the image. Most of these features map to additional packages for installation.PACKAGE_CLASSES: Specifies the package backend to use and consequently helps determine where to locate packages within the Package Feeds area.IMAGE_LINGUAS: Determines the language(s) for which additional language support packages are installed.
Package installation is under control of the package manager (e.g. smart/rpm, opkg, or apt/dpkg) regardless of whether or not package management is enabled for the target. At the end of the process, if package management is not enabled for the target, the package manager's data files are deleted from the root filesystem.
During image generation, the build system attempts to run all post-installation scripts. Any that fail to run on the build host are run on the target when the target system is first booted. If you are using a read-only root filesystem, all the post installation scripts must succeed during the package installation phase since the root filesystem cannot be written into.
During Optimization, optimizing processes are run across
the image.
These processes include mklibs and
prelink.
The mklibs process optimizes the size
of the libraries.
A prelink process optimizes the dynamic
linking of shared libraries to reduce start up time of
executables.
Part of the image generation process includes compressing the root filesystem image. Compression is accomplished through several optimization routines designed to reduce the overall size of the image.
After the root filesystem has been constructed, the image
generation process turns everything into an image file or
a set of image files.
The formats used for the root filesystem depend on the
IMAGE_FSTYPES
variable.
Note
The entire image generation process is run under Pseudo. Running under Pseudo ensures that the files in the root filesystem have correct ownership.The OpenEmbedded build system uses BitBake to generate the Software Development Kit (SDK) installer script:
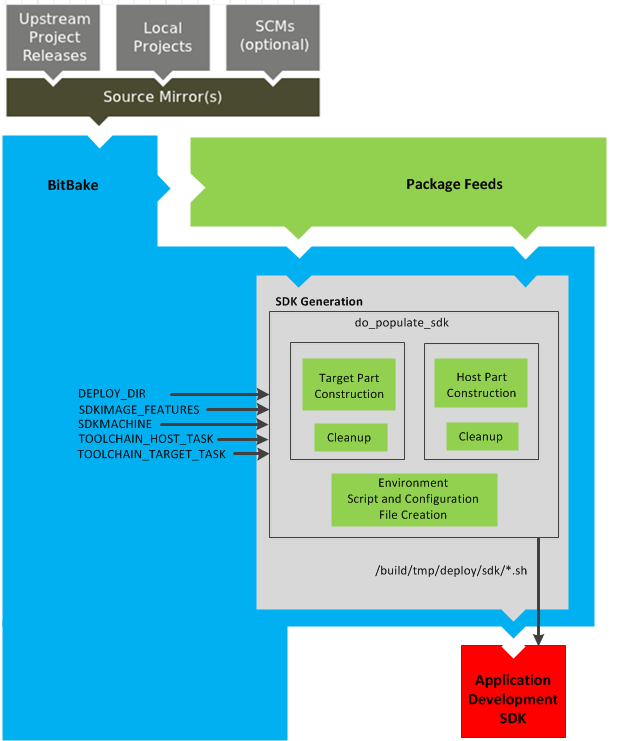 |
Note
For more information on the cross-development toolchain generation, see the "Cross-Development Toolchain Generation" section.
Like image generation, the SDK script process consists of
several stages and depends on many variables.
The do_populate_sdk task uses these
key variables to help create the list of packages to actually
install.
For information on the variables listed in the figure, see the
"Application Development SDK"
section.
The do_populate_sdk task handles two
parts: a target part and a host part.
The target part is the part built for the target hardware and
includes libraries and headers.
The host part is the part of the SDK that runs on the
SDKMACHINE.
Once both parts are constructed, the
do_populate_sdk task performs some cleanup
on both parts.
After the cleanup, the task creates a cross-development
environment setup script and any configuration files that
might be needed.
The final output of the task is the Cross-development
toolchain installation script (.sh file),
which includes the environment setup script.
The images produced by the OpenEmbedded build system are compressed forms of the root filesystem that are ready to boot on a target device. You can see from the general Yocto Project Development Environment figure that BitBake output in part consists of images. This section is going to look more closely at this output:
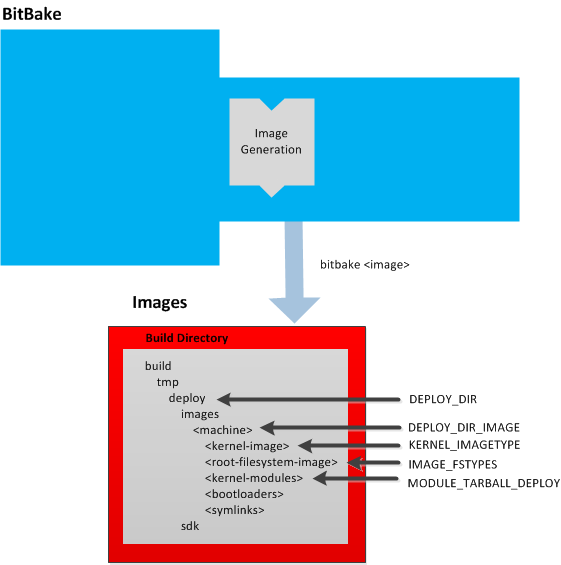 |
For a list of example images that the Yocto Project provides, see the "Images" chapter.
Images are written out to the
Build Directory
inside the tmp/deploy/images/<machine>/
folder as shown in the figure.
This folder contains any files expected to be loaded on the
target device.
The
DEPLOY_DIR
variable points to the deploy directory,
while the
DEPLOY_DIR_IMAGE
variable points to the appropriate directory containing images for
the current configuration.
<kernel-image>: A kernel binary file. TheKERNEL_IMAGETYPEvariable setting determines the naming scheme for the kernel image file. Depending on that variable, the file could begin with a variety of naming strings. Thedeploy/images/<machine>directory can contain multiple image files for the machine.<root-filesystem-image>: Root filesystems for the target device (e.g.*.ext3or*.bz2files). TheIMAGE_FSTYPESvariable setting determines the root filesystem image type. Thedeploy/images/<machine>directory can contain multiple root filesystems for the machine.<kernel-modules>: Tarballs that contain all the modules built for the kernel. Kernel module tarballs exist for legacy purposes and can be suppressed by setting theMODULE_TARBALL_DEPLOYvariable to "0". Thedeploy/images/<machine>directory can contain multiple kernel module tarballs for the machine.<bootloaders>: Bootloaders supporting the image, if applicable to the target machine. Thedeploy/images/<machine>directory can contain multiple bootloaders for the machine.<symlinks>: Thedeploy/images/<machine>folder contains a symbolic link that points to the most recently built file for each machine. These links might be useful for external scripts that need to obtain the latest version of each file.
In the general Yocto Project Development Environment figure, the output labeled "Application Development SDK" represents an SDK. This section is going to take a closer look at this output:
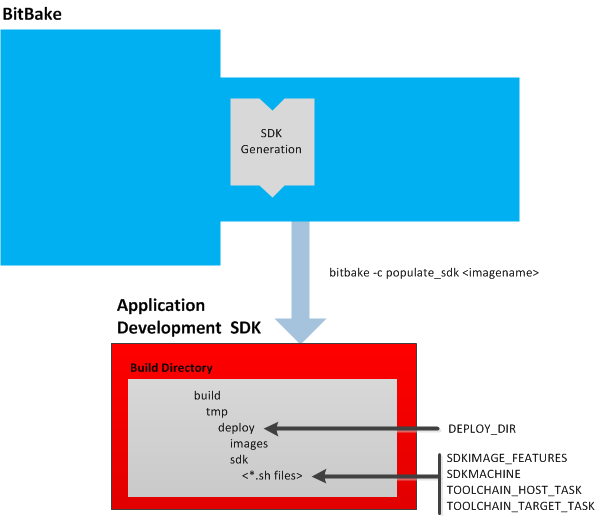 |
The specific form of this output is a self-extracting
SDK installer (*.sh) that, when run,
installs the SDK, which consists of a cross-development
toolchain, a set of libraries and headers, and an SDK
environment setup script.
Running this installer essentially sets up your
cross-development environment.
You can think of the cross-toolchain as the "host"
part because it runs on the SDK machine.
You can think of the libraries and headers as the "target"
part because they are built for the target hardware.
The setup script is added so that you can initialize the
environment before using the tools.
Note
The Yocto Project supports several methods by which you can set up this cross-development environment. These methods include downloading pre-built SDK installers, building and installing your own SDK installer, or running an Application Development Toolkit (ADT) installer to install not just cross-development toolchains but also additional tools to help in this type of development.
For background information on cross-development toolchains in the Yocto Project development environment, see the "Cross-Development Toolchain Generation" section. For information on setting up a cross-development environment, see the "Installing the ADT and Toolchains" section in the Yocto Project Application Developer's Guide.
Once built, the SDK installers are written out to the
deploy/sdk folder inside the
Build Directory
as shown in the figure at the beginning of this section.
Several variables exist that help configure these files:
DEPLOY_DIR: Points to thedeploydirectory.SDKMACHINE: Specifies the architecture of the machine on which the cross-development tools are run to create packages for the target hardware.SDKIMAGE_FEATURES: Lists the features to include in the "target" part of the SDK.TOOLCHAIN_HOST_TASK: Lists packages that make up the host part of the SDK (i.e. the part that runs on theSDKMACHINE). When you usebitbake -c populate_sdk <imagename>to create the SDK, a set of default packages apply. This variable allows you to add more packages.TOOLCHAIN_TARGET_TASK: Lists packages that make up the target part of the SDK (i.e. the part built for the target hardware).
This chapter provides technical details for various parts of the Yocto Project. Currently, topics include Yocto Project components, shared state (sstate) cache, x32, and Licenses.
The BitBake task executor together with various types of configuration files form the OpenEmbedded Core. This section overviews these by describing what they are used for and how they interact.
BitBake handles the parsing and execution of the data files. The data itself is of various types:
Recipes: Provides details about particular pieces of software.
Class Data: Abstracts common build information (e.g. how to build a Linux kernel).
Configuration Data: Defines machine-specific settings, policy decisions, and so forth. Configuration data acts as the glue to bind everything together.
For more information on data, see the "Yocto Project Terms" section in the Yocto Project Development Manual.
BitBake knows how to combine multiple data sources together and refers to each data source as a layer. For information on layers, see the "Understanding and Creating Layers" section of the Yocto Project Development Manual.
Following are some brief details on these core components. For more detailed information on these components, see the "Source Directory Structure" chapter.
BitBake is the tool at the heart of the OpenEmbedded build system and is responsible for parsing the Metadata, generating a list of tasks from it, and then executing those tasks. To see a list of the options BitBake supports, use either of the following commands:
$ bitbake -h
$ bitbake --help
The most common usage for BitBake is bitbake <packagename>, where
packagename is the name of the package you want to build
(referred to as the "target" in this manual).
The target often equates to the first part of a .bb filename.
So, to process the matchbox-desktop_1.2.3.bb recipe file, you
might type the following:
$ bitbake matchbox-desktop
Several different versions of matchbox-desktop might exist.
BitBake chooses the one selected by the distribution configuration.
You can get more details about how BitBake chooses between different
target versions and providers in the
"Preferences and Providers" section.
BitBake also tries to execute any dependent tasks first.
So for example, before building matchbox-desktop, BitBake
would build a cross compiler and eglibc if they had not already
been built.
Note
This release of the Yocto Project does not support theglibc
GNU version of the Unix standard C library. By default, the OpenEmbedded build system
builds with eglibc.
A useful BitBake option to consider is the -k or
--continue option.
This option instructs BitBake to try and continue processing the job as much
as possible even after encountering an error.
When an error occurs, the target that
failed and those that depend on it cannot be remade.
However, when you use this option other dependencies can still be processed.
The .bb files are usually referred to as "recipes."
In general, a recipe contains information about a single piece of software.
This information includes the location from which to download the
unaltered source, any source patches to be applied to that source
(if needed), which special configuration options to apply,
how to compile the source files, and how to package the compiled output.
The term "package" is sometimes used to refer to recipes. However,
since the word "package" is used for the packaged output from the OpenEmbedded
build system (i.e. .ipk or .deb files),
this document avoids using the term "package" when referring to recipes.
Class files (.bbclass) contain information that
is useful to share between
Metadata files.
An example is the Autotools class, which contains
common settings for any application that Autotools uses.
The "Classes" chapter provides details
about common classes and how to use them.
The configuration files (.conf) define various configuration variables
that govern the OpenEmbedded build process.
These files fall into several areas that define machine configuration options,
distribution configuration options, compiler tuning options, general common configuration
options, and user configuration options in local.conf, which is found
in the
Build Directory.
The Yocto Project does most of the work for you when it comes to creating cross-development toolchains. This section provides some technical background information on how cross-development toolchains are created and used. For more information on toolchains, you can also see the the Yocto Project Application Developer's Guide.
In the Yocto Project development environment, cross-development toolchains are used to build the image and applications that run on the target hardware. With just a few commands, the OpenEmbedded build system creates these necessary toolchains for you.
The following figure shows a high-level build environment regarding toolchain construction and use.
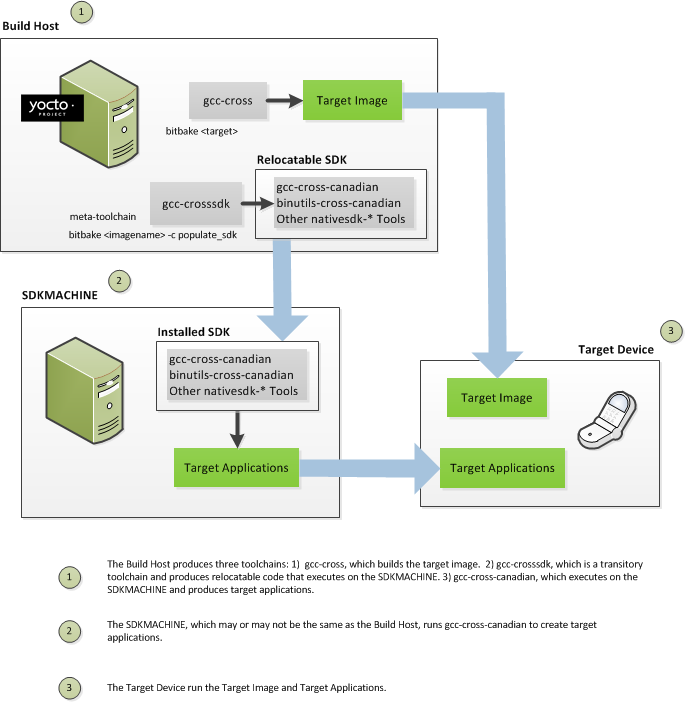 |
Most of the work occurs on the Build Host.
This is the machine used to build images and generally work within the
the Yocto Project environment.
When you run BitBake to create an image, the OpenEmbedded build system
uses the host gcc compiler to bootstrap a
cross-compiler named gcc-cross.
The gcc-cross compiler is what BitBake uses to
compile source files when creating the target image.
You can think of gcc-cross simply as an
automatically generated cross-compiler that is used internally within
BitBake only.
The chain of events that occurs when gcc-cross is
bootstrapped is as follows:
gcc -> binutils-cross -> gcc-cross-initial -> linux-libc-headers -> eglibc-initial -> eglibc -> gcc-cross -> gcc-runtime
gcc: The build host's GNU Compiler Collection (GCC).binutils-cross: The bare minimum binary utilities needed in order to run thegcc-cross-initialphase of the bootstrap operation.gcc-cross-initial: An early stage of the bootstrap process for creating the cross-compiler. This stage builds enough of thegcc-cross, the C library, and other pieces needed to finish building the final cross-compiler in later stages. This tool is a "native" package (i.e. it is designed to run on the build host).linux-libc-headers: Headers needed for the cross-compiler.eglibc-initial: An initial version of the Embedded GLIBC needed to bootstrapeglibc.gcc-cross: The final stage of the bootstrap process for the cross-compiler. This stage results in the actual cross-compiler that BitBake uses when it builds an image for a targeted device.Note
If you are replacing this cross compiler toolchain with a custom version, you must replacegcc-cross.This tool is also a "native" package (i.e. it is designed to run on the build host).
gcc-runtime: Runtime libraries resulting from the toolchain bootstrapping process. This tool produces a binary that consists of the runtime libraries need for the targeted device.
You can use the OpenEmbedded build system to build an installer for
the relocatable SDK used to develop applications.
When you run the installer, it installs the toolchain, which contains
the development tools (e.g., the
gcc-cross-canadian),
binutils-cross-canadian, and other
nativesdk-* tools you need to cross-compile and
test your software.
The figure shows the commands you use to easily build out this
toolchain.
This cross-development toolchain is built to execute on the
SDKMACHINE,
which might or might not be the same
machine as the Build Host.
Note
If your target architecture is supported by the Yocto Project, you can take advantage of pre-built images that ship with the Yocto Project and already contain cross-development toolchain installers.
Here is the bootstrap process for the relocatable toolchain:
gcc -> binutils-crosssdk -> gcc-crosssdk-initial -> linux-libc-headers -> eglibc-initial -> nativesdk-eglibc -> gcc-crosssdk -> gcc-cross-canadian
gcc: The build host's GNU Compiler Collection (GCC).binutils-crosssdk: The bare minimum binary utilities needed in order to run thegcc-crosssdk-initialphase of the bootstrap operation.gcc-crosssdk-initial: An early stage of the bootstrap process for creating the cross-compiler. This stage builds enough of thegcc-crosssdkand supporting pieces so that the final stage of the bootstrap process can produce the finished cross-compiler. This tool is a "native" binary that runs on the build host.linux-libc-headers: Headers needed for the cross-compiler.eglibc-initial: An initial version of the Embedded GLIBC needed to bootstrapnativesdk-eglibc.nativesdk-eglibc: The Embedded GLIBC needed to bootstrap thegcc-crosssdk.gcc-crosssdk: The final stage of the bootstrap process for the relocatable cross-compiler. Thegcc-crosssdkis a transitory compiler and never leaves the build host. Its purpose is to help in the bootstrap process to create the eventual relocatablegcc-cross-canadiancompiler, which is relocatable. This tool is also a "native" package (i.e. it is designed to run on the build host).gcc-cross-canadian: The final relocatable cross-compiler. When run on theSDKMACHINE, this tool produces executable code that runs on the target device.
By design, the OpenEmbedded build system builds everything from scratch unless BitBake can determine that parts do not need to be rebuilt. Fundamentally, building from scratch is attractive as it means all parts are built fresh and there is no possibility of stale data causing problems. When developers hit problems, they typically default back to building from scratch so they know the state of things from the start.
Building an image from scratch is both an advantage and a disadvantage to the process. As mentioned in the previous paragraph, building from scratch ensures that everything is current and starts from a known state. However, building from scratch also takes much longer as it generally means rebuilding things that do not necessarily need to be rebuilt.
The Yocto Project implements shared state code that supports incremental builds. The implementation of the shared state code answers the following questions that were fundamental roadblocks within the OpenEmbedded incremental build support system:
What pieces of the system have changed and what pieces have not changed?
How are changed pieces of software removed and replaced?
How are pre-built components that do not need to be rebuilt from scratch used when they are available?
For the first question, the build system detects changes in the "inputs" to a given task by creating a checksum (or signature) of the task's inputs. If the checksum changes, the system assumes the inputs have changed and the task needs to be rerun. For the second question, the shared state (sstate) code tracks which tasks add which output to the build process. This means the output from a given task can be removed, upgraded or otherwise manipulated. The third question is partly addressed by the solution for the second question assuming the build system can fetch the sstate objects from remote locations and install them if they are deemed to be valid.
Note
The OpenEmbedded build system does not maintainPR information
as part of the shared state packages.
Consequently, considerations exist that affect maintaining shared
state feeds.
For information on how the OpenEmbedded works with packages and can
track incrementing PR information, see the
"Incrementing a Package Revision Number"
section.
The rest of this section goes into detail about the overall incremental build architecture, the checksums (signatures), shared state, and some tips and tricks.
When determining what parts of the system need to be built, BitBake
works on a per-task basis rather than a per-recipe basis.
You might wonder why using a per-task basis is preferred over a per-recipe basis.
To help explain, consider having the IPK packaging backend enabled and then switching to DEB.
In this case, do_install and do_package
outputs are still valid.
However, with a per-recipe approach, the build would not include the
.deb files.
Consequently, you would have to invalidate the whole build and rerun it.
Rerunning everything is not the best solution.
Also, in this case, the core must be "taught" much about specific tasks.
This methodology does not scale well and does not allow users to easily add new tasks
in layers or as external recipes without touching the packaged-staging core.
The shared state code uses a checksum, which is a unique signature of a task's inputs, to determine if a task needs to be run again. Because it is a change in a task's inputs that triggers a rerun, the process needs to detect all the inputs to a given task. For shell tasks, this turns out to be fairly easy because the build process generates a "run" shell script for each task and it is possible to create a checksum that gives you a good idea of when the task's data changes.
To complicate the problem, there are things that should not be included in
the checksum.
First, there is the actual specific build path of a given task -
the WORKDIR.
It does not matter if the work directory changes because it should not
affect the output for target packages.
Also, the build process has the objective of making native or cross packages relocatable.
The checksum therefore needs to exclude WORKDIR.
The simplistic approach for excluding the work directory is to set
WORKDIR to some fixed value and create the checksum
for the "run" script.
Another problem results from the "run" scripts containing functions that might or might not get called. The incremental build solution contains code that figures out dependencies between shell functions. This code is used to prune the "run" scripts down to the minimum set, thereby alleviating this problem and making the "run" scripts much more readable as a bonus.
So far we have solutions for shell scripts. What about Python tasks? The same approach applies even though these tasks are more difficult. The process needs to figure out what variables a Python function accesses and what functions it calls. Again, the incremental build solution contains code that first figures out the variable and function dependencies, and then creates a checksum for the data used as the input to the task.
Like the WORKDIR case, situations exist where dependencies
should be ignored.
For these cases, you can instruct the build process to ignore a dependency
by using a line like the following:
PACKAGE_ARCHS[vardepsexclude] = "MACHINE"
This example ensures that the PACKAGE_ARCHS variable does not
depend on the value of MACHINE, even if it does reference it.
Equally, there are cases where we need to add dependencies BitBake is not able to find. You can accomplish this by using a line like the following:
PACKAGE_ARCHS[vardeps] = "MACHINE"
This example explicitly adds the MACHINE variable as a
dependency for PACKAGE_ARCHS.
Consider a case with in-line Python, for example, where BitBake is not
able to figure out dependencies.
When running in debug mode (i.e. using -DDD), BitBake
produces output when it discovers something for which it cannot figure out
dependencies.
The Yocto Project team has currently not managed to cover those dependencies
in detail and is aware of the need to fix this situation.
Thus far, this section has limited discussion to the direct inputs into a task. Information based on direct inputs is referred to as the "basehash" in the code. However, there is still the question of a task's indirect inputs - the things that were already built and present in the Build Directory. The checksum (or signature) for a particular task needs to add the hashes of all the tasks on which the particular task depends. Choosing which dependencies to add is a policy decision. However, the effect is to generate a master checksum that combines the basehash and the hashes of the task's dependencies.
At the code level, there are a variety of ways both the basehash and the dependent task hashes can be influenced. Within the BitBake configuration file, we can give BitBake some extra information to help it construct the basehash. The following statement effectively results in a list of global variable dependency excludes - variables never included in any checksum:
BB_HASHBASE_WHITELIST ?= "TMPDIR FILE PATH PWD BB_TASKHASH BBPATH DL_DIR \
SSTATE_DIR THISDIR FILESEXTRAPATHS FILE_DIRNAME HOME LOGNAME SHELL TERM \
USER FILESPATH STAGING_DIR_HOST STAGING_DIR_TARGET COREBASE PRSERV_HOST \
PRSERV_DUMPDIR PRSERV_DUMPFILE PRSERV_LOCKDOWN PARALLEL_MAKE \
CCACHE_DIR EXTERNAL_TOOLCHAIN CCACHE CCACHE_DISABLE LICENSE_PATH SDKPKGSUFFIX"
The previous example excludes
WORKDIR
since that variable is actually constructed as a path within
TMPDIR, which is on
the whitelist.
The rules for deciding which hashes of dependent tasks to include through
dependency chains are more complex and are generally accomplished with a
Python function.
The code in meta/lib/oe/sstatesig.py shows two examples
of this and also illustrates how you can insert your own policy into the system
if so desired.
This file defines the two basic signature generators OE-Core
uses: "OEBasic" and "OEBasicHash".
By default, there is a dummy "noop" signature handler enabled in BitBake.
This means that behavior is unchanged from previous versions.
OE-Core uses the "OEBasicHash" signature handler by default
through this setting in the bitbake.conf file:
BB_SIGNATURE_HANDLER ?= "OEBasicHash"
The "OEBasicHash" BB_SIGNATURE_HANDLER is the same as the
"OEBasic" version but adds the task hash to the stamp files.
This results in any
Metadata
change that changes the task hash, automatically
causing the task to be run again.
This removes the need to bump PR
values, and changes to Metadata automatically ripple across the build.
It is also worth noting that the end result of these signature generators is to make some dependency and hash information available to the build. This information includes:
BB_BASEHASH_task-<taskname> - the base hashes for each task in the recipe
BB_BASEHASH_<filename:taskname> - the base hashes for each dependent task
BBHASHDEPS_<filename:taskname> - The task dependencies for each task
BB_TASKHASH - the hash of the currently running task
Checksums and dependencies, as discussed in the previous section, solve half the problem of supporting a shared state. The other part of the problem is being able to use checksum information during the build and being able to reuse or rebuild specific components.
The shared state class (sstate.bbclass)
is a relatively generic implementation of how to "capture" a snapshot of a given task.
The idea is that the build process does not care about the source of a task's output.
Output could be freshly built or it could be downloaded and unpacked from
somewhere - the build process does not need to worry about its origin.
There are two types of output, one is just about creating a directory
in WORKDIR.
A good example is the output of either do_install or
do_package.
The other type of output occurs when a set of data is merged into a shared directory
tree such as the sysroot.
The Yocto Project team has tried to keep the details of the implementation hidden in
sstate.bbclass.
From a user's perspective, adding shared state wrapping to a task
is as simple as this do_deploy example taken from
deploy.bbclass:
DEPLOYDIR = "${WORKDIR}/deploy-${PN}"
SSTATETASKS += "do_deploy"
do_deploy[sstate-name] = "deploy"
do_deploy[sstate-inputdirs] = "${DEPLOYDIR}"
do_deploy[sstate-outputdirs] = "${DEPLOY_DIR_IMAGE}"
python do_deploy_setscene () {
sstate_setscene(d)
}
addtask do_deploy_setscene
do_deploy[dirs] = "${DEPLOYDIR} ${B}"
In this example, we add some extra flags to the task, a name field ("deploy"), an
input directory where the task sends data, and the output
directory where the data from the task should eventually be copied.
We also add a _setscene variant of the task and add the task
name to the SSTATETASKS list.
If you have a directory whose contents you need to preserve, you can do this with a line like the following:
do_package[sstate-plaindirs] = "${PKGD} ${PKGDEST}"
This method, as well as the following example, also works for multiple directories.
do_package[sstate-inputdirs] = "${PKGDESTWORK} ${SHLIBSWORKDIR}"
do_package[sstate-outputdirs] = "${PKGDATA_DIR} ${SHLIBSDIR}"
do_package[sstate-lockfile] = "${PACKAGELOCK}"
These methods also include the ability to take a lockfile when manipulating shared state directory structures since some cases are sensitive to file additions or removals.
Behind the scenes, the shared state code works by looking in
SSTATE_DIR and
SSTATE_MIRRORS
for shared state files.
Here is an example:
SSTATE_MIRRORS ?= "\
file://.* http://someserver.tld/share/sstate/PATH \n \
file://.* file:///some/local/dir/sstate/PATH"
Note
The shared state directory (SSTATE_DIR) is
organized into two-character subdirectories, where the subdirectory
names are based on the first two characters of the hash.
If the shared state directory structure for a mirror has the
same structure as SSTATE_DIR, you must
specify "PATH" as part of the URI to enable the build system
to map to the appropriate subdirectory.
The shared state package validity can be detected just by looking at the filename since the filename contains the task checksum (or signature) as described earlier in this section. If a valid shared state package is found, the build process downloads it and uses it to accelerate the task.
The build processes use the *_setscene tasks
for the task acceleration phase.
BitBake goes through this phase before the main execution code and tries
to accelerate any tasks for which it can find shared state packages.
If a shared state package for a task is available, the shared state
package is used.
This means the task and any tasks on which it is dependent are not
executed.
As a real world example, the aim is when building an IPK-based image,
only the do_package_write_ipk tasks would have their
shared state packages fetched and extracted.
Since the sysroot is not used, it would never get extracted.
This is another reason why a task-based approach is preferred over a
recipe-based approach, which would have to install the output from every task.
The code in the build system that supports incremental builds is not simple code. This section presents some tips and tricks that help you work around issues related to shared state code.
When things go wrong, debugging needs to be straightforward. Because of this, the Yocto Project team included strong debugging tools:
Whenever a shared state package is written out, so is a corresponding
.siginfofile. This practice results in a pickled Python database of all the metadata that went into creating the hash for a given shared state package.If you run BitBake with the
--dump-signatures(or-S) option, BitBake dumps out.siginfofiles in the stamp directory for every task it would have executed instead of building the specified target package.There is a
bitbake-diffsigscommand that can process.siginfofiles. If you specify one of these files, BitBake dumps out the dependency information in the file. If you specify two files, BitBake compares the two files and dumps out the differences between the two. This more easily helps answer the question of "What changed between X and Y?"
The OpenEmbedded build system uses checksums and shared state cache to avoid unnecessarily rebuilding tasks. Collectively, this scheme is known as "shared state code."
As with all schemes, this one has some drawbacks.
It is possible that you could make implicit changes to your
code that the checksum calculations do not take into
account (i.e. implicit changes).
These implicit changes affect a task's output but do not trigger
the shared state code into rebuilding a recipe.
Consider an example during which a tool changes its output.
Assume that the output of rpmdeps changes.
The result of the change should be that all the
package and
package_write_rpm shared state cache
items become invalid.
However, because the change to the output is
external to the code and therefore implicit,
the associated shared state cache items do not become
invalidated.
In this case, the build process uses the cached items rather
than running the task again.
Obviously, these types of implicit changes can cause problems.
To avoid these problems during the build, you need to understand the effects of any changes you make. Realize that changes you make directly to a function are automatically factored into the checksum calculation. Thus, these explicit changes invalidate the associated area of sstate cache. However, you need to be aware of any implicit changes that are not obvious changes to the code and could affect the output of a given task.
When you identify an implicit change, you can easily take steps
to invalidate the cache and force the tasks to run.
The steps you can take are as simple as changing a function's
comments in the source code.
For example, to invalidate package shared state files, change
the comment statements of do_package or
the comments of one of the functions it calls.
Even though the change is purely cosmetic, it causes the
checksum to be recalculated and forces the OpenEmbedded build
system to run the task again.
Note
For an example of a commit that makes a cosmetic change to invalidate shared state, see this commit.x32 is a processor-specific Application Binary Interface (psABI) for x86_64. An ABI defines the calling conventions between functions in a processing environment. The interface determines what registers are used and what the sizes are for various C data types.
Some processing environments prefer using 32-bit applications even when running on Intel 64-bit platforms. Consider the i386 psABI, which is a very old 32-bit ABI for Intel 64-bit platforms. The i386 psABI does not provide efficient use and access of the Intel 64-bit processor resources, leaving the system underutilized. Now consider the x86_64 psABI. This ABI is newer and uses 64-bits for data sizes and program pointers. The extra bits increase the footprint size of the programs, libraries, and also increases the memory and file system size requirements. Executing under the x32 psABI enables user programs to utilize CPU and system resources more efficiently while keeping the memory footprint of the applications low. Extra bits are used for registers but not for addressing mechanisms.
While the x32 psABI specifications are not fully finalized, this Yocto Project release supports current development specifications of x32 psABI. As of this release of the Yocto Project, x32 psABI support exists as follows:
You can create packages and images in x32 psABI format on x86_64 architecture targets.
You can successfully build many recipes with the x32 toolchain.
You can create and boot
core-image-minimalandcore-image-satoimages.
As of this Yocto Project release, the x32 psABI kernel and library interfaces specifications are not finalized.
Future Plans for the x32 psABI in the Yocto Project include the following:
Enhance and fix the few remaining recipes so they work with and support x32 toolchains.
Enhance RPM Package Manager (RPM) support for x32 binaries.
Support larger images.
Follow these steps to use the x32 spABI:
Enable the x32 psABI tuning file for
x86_64machines by editing theconf/local.conflike this:MACHINE = "qemux86-64" DEFAULTTUNE = "x86-64-x32" baselib = "${@d.getVar('BASE_LIB_tune-' + (d.getVar('DEFAULTTUNE', True) \ or 'INVALID'), True) or 'lib'}" #MACHINE = "genericx86" #DEFAULTTUNE = "core2-64-x32"As usual, use BitBake to build an image that supports the x32 psABI. Here is an example:
$ bitbake core-image-satoAs usual, run your image using QEMU:
$ runqemu qemux86-64 core-image-sato
Wayland is a computer display server protocol that provides a method for compositing window managers to communicate directly with applications and video hardware and expects them to communicate with input hardware using other libraries. Using Wayland with supporting targets can result in better control over graphics frame rendering than an application might otherwise achieve.
The Yocto Project provides the Wayland protocol libraries and the reference Weston compositor as part of its release. This section describes what you need to do to implement Wayland and use the compositor when building an image for a supporting target.
The Wayland protocol libraries and the reference Weston compositor
ship as integrated packages in the meta layer
of the
Source Directory.
Specifically, you can find the recipes that build both Wayland
and Weston at meta/recipes-graphics/wayland.
You can build both the Wayland and Weston packages for use only with targets that accept the Mesa 3D and Direct Rendering Infrastructure, which is also known as Mesa DRI. This implies that you cannot build and use the packages if your target uses, for example, the Intel® Embedded Media and Graphics Driver (Intel® EMGD) that overrides Mesa DRI.
Note
Due to lack of EGL support, Weston 1.0.3 will not run directly on the emulated QEMU hardware. However, this version of Weston will run under X emulation without issues.To enable Wayland, you need to enable it to be built and enable it to be included in the image.
To cause Mesa to build the wayland-egl
platform and Weston to build Wayland with Kernel Mode
Setting
(KMS)
support, include the "wayland" flag in the
DISTRO_FEATURES
statement in your local.conf file:
DISTRO_FEATURES_append = " wayland"
Note
If X11 has been enabled elsewhere, Weston will build Wayland with X11 support
To install the Wayland feature into an image, you must
include the following
CORE_IMAGE_EXTRA_INSTALL
statement in your local.conf file:
CORE_IMAGE_EXTRA_INSTALL += "wayland weston"
To run Weston inside X11, enabling it as described earlier and building a Sato image is sufficient. If you are running your image under Sato, a Weston Launcher appears in the "Utility" category.
Alternatively, you can run Weston through the command-line interpretor (CLI), which is better suited for development work. To run Weston under the CLI, you need to do the following after your image is built:
Run these commands to export
XDG_RUNTIME_DIR:mkdir -p /tmp/$USER-weston chmod 0700 /tmp/$USER-weston export XDG_RUNTIME_DIR=/tmp/$USER-westonLaunch Weston in the shell:
weston
This section describes the mechanism by which the OpenEmbedded build system tracks changes to licensing text. The section also describes how to enable commercially licensed recipes, which by default are disabled.
For information that can help you maintain compliance with various open source licensing during the lifecycle of the product, see the "Maintaining Open Source License Compliance During Your Project's Lifecycle" section in the Yocto Project Development Manual.
The license of an upstream project might change in the future.
In order to prevent these changes going unnoticed, the
LIC_FILES_CHKSUM
variable tracks changes to the license text. The checksums are validated at the end of the
configure step, and if the checksums do not match, the build will fail.
The LIC_FILES_CHKSUM
variable contains checksums of the license text in the source code for the recipe.
Following is an example of how to specify LIC_FILES_CHKSUM:
LIC_FILES_CHKSUM = "file://COPYING;md5=xxxx \
file://licfile1.txt;beginline=5;endline=29;md5=yyyy \
file://licfile2.txt;endline=50;md5=zzzz \
..."
The build system uses the
S variable as
the default directory used when searching files listed in
LIC_FILES_CHKSUM.
The previous example employs the default directory.
Consider this next example:
LIC_FILES_CHKSUM = "file://src/ls.c;beginline=5;endline=16;\
md5=bb14ed3c4cda583abc85401304b5cd4e"
LIC_FILES_CHKSUM = "file://${WORKDIR}/license.html;md5=5c94767cedb5d6987c902ac850ded2c6"
The first line locates a file in
${S}/src/ls.c.
The second line refers to a file in
WORKDIR.
Note that LIC_FILES_CHKSUM variable is
mandatory for all recipes, unless the
LICENSE variable is set to "CLOSED".
As mentioned in the previous section, the
LIC_FILES_CHKSUM variable lists all the
important files that contain the license text for the source code.
It is possible to specify a checksum for an entire file, or a specific section of a
file (specified by beginning and ending line numbers with the "beginline" and "endline"
parameters, respectively).
The latter is useful for source files with a license notice header,
README documents, and so forth.
If you do not use the "beginline" parameter, then it is assumed that the text begins on the
first line of the file.
Similarly, if you do not use the "endline" parameter, it is assumed that the license text
ends with the last line of the file.
The "md5" parameter stores the md5 checksum of the license text. If the license text changes in any way as compared to this parameter then a mismatch occurs. This mismatch triggers a build failure and notifies the developer. Notification allows the developer to review and address the license text changes. Also note that if a mismatch occurs during the build, the correct md5 checksum is placed in the build log and can be easily copied to the recipe.
There is no limit to how many files you can specify using the
LIC_FILES_CHKSUM variable.
Generally, however, every project requires a few specifications for license tracking.
Many projects have a "COPYING" file that stores the license information for all the source
code files.
This practice allows you to just track the "COPYING" file as long as it is kept up to date.
Tip
If you specify an empty or invalid "md5" parameter, BitBake returns an md5 mis-match error and displays the correct "md5" parameter value during the build. The correct parameter is also captured in the build log.Tip
If the whole file contains only license text, you do not need to use the "beginline" and "endline" parameters.
By default, the OpenEmbedded build system disables
components that have commercial or other special licensing
requirements.
Such requirements are defined on a
recipe-by-recipe basis through the LICENSE_FLAGS variable
definition in the affected recipe.
For instance, the
poky/meta/recipes-multimedia/gstreamer/gst-plugins-ugly
recipe contains the following statement:
LICENSE_FLAGS = "commercial"
Here is a slightly more complicated example that contains both an explicit recipe name and version (after variable expansion):
LICENSE_FLAGS = "license_${PN}_${PV}"
In order for a component restricted by a LICENSE_FLAGS
definition to be enabled and included in an image, it
needs to have a matching entry in the global
LICENSE_FLAGS_WHITELIST variable, which is a variable
typically defined in your local.conf file.
For example, to enable
the poky/meta/recipes-multimedia/gstreamer/gst-plugins-ugly
package, you could add either the string
"commercial_gst-plugins-ugly" or the more general string
"commercial" to LICENSE_FLAGS_WHITELIST.
See the
"License Flag Matching" section
for a full explanation of how LICENSE_FLAGS matching works.
Here is the example:
LICENSE_FLAGS_WHITELIST = "commercial_gst-plugins-ugly"
Likewise, to additionally enable the package built from the recipe containing
LICENSE_FLAGS = "license_${PN}_${PV}", and assuming
that the actual recipe name was emgd_1.10.bb,
the following string would enable that package as well as
the original gst-plugins-ugly package:
LICENSE_FLAGS_WHITELIST = "commercial_gst-plugins-ugly license_emgd_1.10"
As a convenience, you do not need to specify the complete license string in the whitelist for every package. You can use an abbreviated form, which consists of just the first portion or portions of the license string before the initial underscore character or characters. A partial string will match any license that contains the given string as the first portion of its license. For example, the following whitelist string will also match both of the packages previously mentioned as well as any other packages that have licenses starting with "commercial" or "license".
LICENSE_FLAGS_WHITELIST = "commercial license"
License flag matching allows you to control what recipes the
OpenEmbedded build system includes in the build.
Fundamentally, the build system attempts to match
LICENSE_FLAGS strings found in
recipes against LICENSE_FLAGS_WHITELIST
strings found in the whitelist.
A match causes the build system to include a recipe in the
build, while failure to find a match causes the build system to
exclude a recipe.
In general, license flag matching is simple. However, understanding some concepts will help you correctly and effectively use matching.
Before a flag
defined by a particular recipe is tested against the
contents of the whitelist, the expanded string
_${PN} is appended to the flag.
This expansion makes each LICENSE_FLAGS
value recipe-specific.
After expansion, the string is then matched against the
whitelist.
Thus, specifying
LICENSE_FLAGS = "commercial"
in recipe "foo", for example, results in the string
"commercial_foo".
And, to create a match, that string must appear in the
whitelist.
Judicious use of the LICENSE_FLAGS
strings and the contents of the
LICENSE_FLAGS_WHITELIST variable
allows you a lot of flexibility for including or excluding
recipes based on licensing.
For example, you can broaden the matching capabilities by
using license flags string subsets in the whitelist.
Note
When using a string subset, be sure to use the part of the expanded string that precedes the appended underscore character (e.g.usethispart_1.3,
usethispart_1.4, and so forth).
For example, simply specifying the string "commercial" in
the whitelist matches any expanded
LICENSE_FLAGS definition that starts with
the string "commercial" such as "commercial_foo" and
"commercial_bar", which are the strings the build system
automatically generates for hypothetical recipes named
"foo" and "bar" assuming those recipes simply specify the
following:
LICENSE_FLAGS = "commercial"
Thus, you can choose to exhaustively enumerate each license flag in the whitelist and allow only specific recipes into the image, or you can use a string subset that causes a broader range of matches to allow a range of recipes into the image.
This scheme works even if the
LICENSE_FLAGS string already
has _${PN} appended.
For example, the build system turns the license flag
"commercial_1.2_foo" into "commercial_1.2_foo_foo" and would
match both the general "commercial" and the specific
"commercial_1.2_foo" strings found in the whitelist, as
expected.
Here are some other scenarios:
You can specify a versioned string in the recipe such as "commercial_foo_1.2" in a "foo" recipe. The build system expands this string to "commercial_foo_1.2_foo". Combine this license flag with a whitelist that has the string "commercial" and you match the flag along with any other flag that starts with the string "commercial".
Under the same circumstances, you can use "commercial_foo" in the whitelist and the build system not only matches "commercial_foo_1.2" but also matches any license flag with the string "commercial_foo", regardless of the version.
You can be very specific and use both the package and version parts in the whitelist (e.g. "commercial_foo_1.2") to specifically match a versioned recipe.
Other helpful variables related to commercial
license handling exist and are defined in the
poky/meta/conf/distro/include/default-distrovars.inc file:
COMMERCIAL_AUDIO_PLUGINS ?= ""
COMMERCIAL_VIDEO_PLUGINS ?= ""
COMMERCIAL_QT = ""
If you want to enable these components, you can do so by making sure you have
statements similar to the following
in your local.conf configuration file:
COMMERCIAL_AUDIO_PLUGINS = "gst-plugins-ugly-mad \
gst-plugins-ugly-mpegaudioparse"
COMMERCIAL_VIDEO_PLUGINS = "gst-plugins-ugly-mpeg2dec \
gst-plugins-ugly-mpegstream gst-plugins-bad-mpegvideoparse"
COMMERCIAL_QT ?= "qmmp"
LICENSE_FLAGS_WHITELIST = "commercial_gst-plugins-ugly commercial_gst-plugins-bad commercial_qmmp"
Of course, you could also create a matching whitelist
for those components using the more general "commercial"
in the whitelist, but that would also enable all the
other packages with LICENSE_FLAGS containing
"commercial", which you may or may not want:
LICENSE_FLAGS_WHITELIST = "commercial"
Specifying audio and video plug-ins as part of the
COMMERCIAL_AUDIO_PLUGINS and
COMMERCIAL_VIDEO_PLUGINS statements
or commercial Qt components as part of
the COMMERCIAL_QT statement (along
with the enabling LICENSE_FLAGS_WHITELIST) includes the
plug-ins or components into built images, thus adding
support for media formats or components.
- 5.1. Moving to the Yocto Project 1.3 Release
- 5.2. Moving to the Yocto Project 1.4 Release
- 5.3. Moving to the Yocto Project 1.5 Release
- 5.3.1. Host Dependency Changes
- 5.3.2.
atom-pcBoard Support Package (BSP) - 5.3.3. BitBake
- 5.3.4. QA Warnings
- 5.3.5. Directory Layout Changes
- 5.3.6. Shortened Git
SRCREVValues - 5.3.7.
IMAGE_FEATURES - 5.3.8.
run - 5.3.9. Removal of Package Manager Database Within Image Recipes
- 5.3.10. Images Now Rebuild Only on Changes Instead of Every Time
- 5.3.11. Task Recipes
- 5.3.12. BusyBox
- 5.3.13. Automated Image Testing
- 5.3.14. Build History
- 5.3.15.
udev - 5.3.16. Removed and Renamed Recipes
- 5.3.17. Other Changes
This chapter provides information you can use to migrate work to a newer Yocto Project release. You can find the same information in the release notes for a given release.
This section provides migration information for moving to the Yocto Project 1.3 Release from the prior release.
Differences include changes for
SSTATE_MIRRORS
and bblayers.conf.
The shared state cache (sstate-cache), as pointed to by
SSTATE_DIR, by default
now has two-character subdirectories to prevent issues arising
from too many files in the same directory.
Also, native sstate-cache packages will go into a subdirectory named using
the distro ID string.
If you copy the newly structured sstate-cache to a mirror location
(either local or remote) and then point to it in
SSTATE_MIRRORS,
you need to append "PATH" to the end of the mirror URL so that
the path used by BitBake before the mirror substitution is
appended to the path used to access the mirror.
Here is an example:
SSTATE_MIRRORS = "file://.* http://someserver.tld/share/sstate/PATH"
The meta-yocto layer consists of two parts
that correspond to the Poky reference distribution and the
reference hardware Board Support Packages (BSPs), respectively:
meta-yocto and
meta-yocto-bsp.
When running BitBake or Hob for the first time after upgrading,
your conf/bblayers.conf file will be
updated to handle this change and you will be asked to
re-run or restart for the changes to take effect.
Differences include changes for the following:
Python function whitespace
proto=inSRC_URInativesdkTask recipes
IMAGE_FEATURESRemoved recipes
All Python functions must now use four spaces for indentation.
Previously, an inconsistent mix of spaces and tabs existed,
which made extending these functions using
_append or _prepend
complicated given that Python treats whitespace as
syntactically significant.
If you are defining or extending any Python functions (e.g.
populate_packages, do_unpack,
do_patch and so forth) in custom recipes
or classes, you need to ensure you are using consistent
four-space indentation.
Any use of proto= in
SRC_URI
needs to be changed to protocol=.
In particular, this applies to the following URIs:
svn://bzr://hg://osc://
Other URIs were already using protocol=.
This change improves consistency.
The suffix nativesdk is now implemented
as a prefix, which simplifies a lot of the packaging code for
nativesdk recipes.
All custom nativesdk recipes and any
references need to be updated to use
nativesdk-* instead of
*-nativesdk.
"Task" recipes are now known as "Package groups" and have
been renamed from task-*.bb to
packagegroup-*.bb.
Existing references to the previous task-*
names should work in most cases as there is an automatic
upgrade path for most packages.
However, you should update references in your own recipes and
configurations as they could be removed in future releases.
You should also rename any custom task-*
recipes to packagegroup-*, and change
them to inherit packagegroup instead of
task, as well as taking the opportunity
to remove anything now handled by
packagegroup.bbclass, such as providing
-dev and -dbg
packages, setting
LIC_FILES_CHKSUM,
and so forth.
See the
"packagegroup.bbclass"
section for further details.
Image recipes that previously included "apps-console-core"
in IMAGE_FEATURES
should now include "splash" instead to enable the boot-up
splash screen.
Retaining "apps-console-core" will still include the splash
screen but generates a warning.
The "apps-x11-core" and "apps-x11-games"
IMAGE_FEATURES features have been removed.
The following recipes have been removed. For most of them, it is unlikely that you would have any references to them in your own Metadata. However, you should check your metadata against this list to be sure:
libx11-trim: Replaced bylibx11, which has a negligible size difference with modern Xorg.xserver-xorg-lite: Usexserver-xorg, which has a negligible size difference when DRI and GLX modules are not installed.xserver-kdrive: Effectively unmaintained for many years.mesa-xlib: No longer serves any purpose.galago: Replaced by telepathy.gail: Functionality was integrated into GTK+ 2.13.eggdbus: No longer needed.gcc-*-intermediate: The build has been restructured to avoid the need for this step.libgsmd: Unmaintained for many years. Functionality now provided byofonoinstead.contacts, dates, tasks, eds-tools: Largely unmaintained PIM application suite. It has been moved to
meta-gnomeinmeta-openembedded.
In addition to the previously listed changes, the
meta-demoapps directory has also been removed
because the recipes in it were not being maintained and many
had become obsolete or broken.
Additionally, these recipes were not parsed in the default configuration.
Many of these recipes are already provided in an updated and
maintained form within the OpenEmbedded community layers such as
meta-oe and meta-gnome.
For the remainder, you can now find them in the
meta-extras repository, which is in the
Yocto Project
Source Repositories.
The naming scheme for kernel output binaries has been changed to
now include
PE as part of the
filename:
KERNEL_IMAGE_BASE_NAME ?= "${KERNEL_IMAGETYPE}-${PE}-${PV}-${PR}-${MACHINE}-${DATETIME}"
Because the PE variable is not set by default,
these binary files could result with names that include two dash
characters.
Here is an example:
bzImage--3.10.9+git0+cd502a8814_7144bcc4b8-r0-qemux86-64-20130830085431.bin
This section provides migration information for moving to the Yocto Project 1.4 Release from the prior release.
Differences include the following:
Comment Continuation: If a comment ends with a line continuation (\) character, then the next line must also be a comment. Any instance where this is not the case, now triggers a warning. You must either remove the continuation character, or be sure the next line is a comment.
Package Name Overrides: The runtime package specific variables
RDEPENDS,RRECOMMENDS,RSUGGESTS,RPROVIDES,RCONFLICTS,RREPLACES,FILES,ALLOW_EMPTY, and the pre, post, install, and uninstall script functionspkg_preinst,pkg_postinst,pkg_prerm, andpkg_postrmshould always have a package name override. For example, useRDEPENDS_${PN}for the main package instead ofRDEPENDS. BitBake uses more strict checks when it parses recipes.
Differences include the following:
Shared State Code: The shared state code has been optimized to avoid running unnecessary tasks. For example,
bitbake -c rootfs some-imagefrom shared state no longer populates the target sysroot since that is not necessary. Instead, the system just needs to extract the output package contents, re-create the packages, and construct the root filesystem. This change is unlikely to cause any problems unless you have missing declared dependencies.Scanning Directory Names: When scanning for files in
SRC_URI, the build system now usesFILESOVERRIDESinstead ofOVERRIDESfor the directory names. In general, the values previously inOVERRIDESare now inFILESOVERRIDESas well. However, if you relied upon an additional value you previously added toOVERRIDES, you might now need to add it toFILESOVERRIDESunless you are already adding it through theMACHINEOVERRIDESorDISTROOVERRIDESvariables, as appropriate. For more related changes, see the "Variables" section.
A new oe-git-proxy script has been added to
replace previous methods of handling proxies and fetching source
from Git.
See the meta-yocto/conf/site.conf.sample file
for information on how to use this script.
If you have created your own custom
etc/network/interfaces file by creating
an append file for the netbase recipe,
you now need to create an append file for the
init-ifupdown recipe instead, which you can
find in the
Source Directory
at meta/recipes-core/init-ifupdown.
For information on how to use append files, see the
"Using .bbappend Files"
in the Yocto Project Development Manual.
Support for remote debugging with the Eclipse IDE is now
separated into an image feature
(eclipse-debug) that corresponds to the
packagegroup-core-eclipse-debug package group.
Previously, the debugging feature was included through the
tools-debug image feature, which corresponds
to the packagegroup-core-tools-debug
package group.
The following variables have changed:
SANITY_TESTED_DISTROS: This variable now uses a distribution ID, which is composed of the host distributor ID followed by the release. Previously,SANITY_TESTED_DISTROSwas composed of the description field. For example, "Ubuntu 12.10" becomes "Ubuntu-12.10". You do not need to worry about this change if you are not specifically setting this variable, or if you are specifically setting it to "".SRC_URI: The${PN},${PF},${P}, andFILE_DIRNAMEdirectories have been dropped from the default value of theFILESPATHvariable, which is used as the search path for finding files referred to inSRC_URI. If you have a recipe that relied upon these directories, which would be unusual, then you will need to add the appropriate paths within the recipe or, alternatively, rearrange the files. The most common locations are still covered by${BP},${BPN}, and "files", which all remain in the default value ofFILESPATH.
If runtime package management is enabled and the RPM backend is selected, Smart is now installed for package download, dependency resolution, and upgrades instead of Zypper. For more information on how to use Smart, run the following command on the target:
smart --help
The following recipes were moved from their previous locations because they are no longer used by anything in the OpenEmbedded-Core:
clutter-box2d: Now resides in themeta-oelayer.evolution-data-server: Now resides in themeta-gnomelayer.gthumb: Now resides in themeta-gnomelayer.gtkhtml2: Now resides in themeta-oelayer.gupnp: Now resides in themeta-multimedialayer.gypsy: Now resides in themeta-oelayer.libcanberra: Now resides in themeta-gnomelayer.libgdata: Now resides in themeta-gnomelayer.libmusicbrainz: Now resides in themeta-multimedialayer.metacity: Now resides in themeta-gnomelayer.polkit: Now resides in themeta-oelayer.zeroconf: Now resides in themeta-networkinglayer.
The following list shows what has been removed or renamed:
evieext: Removed because it has been removed fromxserversince 2008.Gtk+ DirectFB: Removed support because upstream Gtk+ no longer supports it as of version 2.18.
libxfontcache / xfontcacheproto: Removed because they were removed from the Xorg server in 2008.libxp / libxprintapputil / libxprintutil / printproto: Removed because the XPrint server was removed from Xorg in 2008.libxtrap / xtrapproto: Removed because their functionality was broken upstream.linux-yocto 3.0 kernel: Removed with linux-yocto 3.8 kernel being added. The linux-yocto 3.2 and linux-yocto 3.4 kernels remain as part of the release.
lsbsetup: Removed with functionality now provided bylsbtest.matchbox-stroke: Removed because it was never more than a proof-of-concept.matchbox-wm-2 / matchbox-theme-sato-2: Removed because they are not maintained. However,matchbox-wmandmatchbox-theme-satoare still provided.mesa-dri: Renamed tomesa.mesa-xlib: Removed because it was no longer useful.mutter: Removed because nothing ever uses it and the recipe is very old.orinoco-conf: Removed because it has become obsolete.update-modules: Removed because it is no longer used. The kernel modulepostinstallandpostrmscripts can now do the same task without the use of this script.web: Removed because it is not maintained. Superseded byweb-webkit.xf86bigfontproto: Removed because upstream it has been disabled by default since 2007. Nothing usesxf86bigfontproto.xf86rushproto: Removed because its dependency inxserverwas spurious and it was removed in 2005.zypper / libzypp / sat-solver: Removed and been functionally replaced with Smart (python-smartpm) when RPM packaging is used and package management is enabled on the target.
This section provides migration information for moving to the Yocto Project 1.5 Release from the prior release.
The OpenEmbedded build system now has some additional requirements on the host system:
Python 2.7.3+
Tar 1.24+
Git 1.7.5+
Patched version of Make if you are using 3.82. Most distributions that provide Make 3.82 use the patched version.
If the Linux distribution you are using on your build host does not provide packages for these, you can install and use the Buildtools tarball, which provides an SDK-like environment containing them.
For more information on this requirement, see the "Required Git, tar, and Python Versions" section.
The atom-pc hardware reference BSP has been
replaced by a genericx86 BSP.
This BSP is not necessarily guaranteed to work on all x86
hardware, but it will run on a wider range of systems than the
atom-pc did.
Note
Additionally, agenericx86-64 BSP has been
added for 64-bit systems.
The following changes have been made that relate to BitBake:
BitBake now supports a
_removeoperator. The addition of this operator means you will have to rename any items in recipe space (functions, variables) whose names currently contain_remove_or end with_removeto avoid unexpected behavior.BitBake's global method pool has been removed. This method is not particularly useful and led to clashes between recipes containing functions that had the same name.
The "none" server backend has been removed. The "process" server backend has been serving well as the default for a long time now.
The
bitbake-runtaskscript has been removed.${P}and${PF}are no longer added toPROVIDESby default inbitbake.conf. These version-specificPROVIDESitems were seldom used. Attempting to use them could result in two versions being built simultaneously rather than just one version due to the way BitBake resolves dependencies.
The following changes have been made to the package QA checks:
If you have customized
ERROR_QAorWARN_QAvalues in your configuration, check that they contain all of the issues that you wish to be reported. Previous Yocto Project versions contained a bug that meant that any item not mentioned inERROR_QAorWARN_QAwould be treated as a warning. Consequently, several important items were not already in the default value ofWARN_QA. All of the possible QA checks are now documented in the "insane.bbclass" section.An additional QA check has been added to check if
/usr/share/info/diris being installed. Your recipe should delete this file withindo_installif "make install" is installing it.If you are using the buildhistory class, the check for the package version going backwards is now controlled using a standard QA check. Thus, if you have customized your
ERROR_QAorWARN_QAvalues and still wish to have this check performed, you should add "version-going-backwards" to your value for one or the other variables depending on how you wish it to be handled. See the documented QA checks in the "insane.bbclass" section.
The following directory changes exist:
Output SDK installer files are now named to include the image name and tuning architecture through the
SDK_NAMEvariable.Images and related files are now installed into a directory that is specific to the machine, instead of a parent directory containing output files for multiple machines. The
DEPLOY_DIR_IMAGEvariable continues to point to the directory containing images for the currentMACHINEand should be used anywhere there is a need to refer to this directory. Therunqemuscript now uses this variable to find images and kernel binaries and will use BitBake to determine the directory. Alternatively, you can set theDEPLOY_DIR_IMAGEvariable in the external environment.When buildhistory is enabled, its output is now written under the Build Directory rather than
TMPDIR. Doing so makes it easier to deleteTMPDIRand preserve the build history. Additionally, data for produced SDKs is now split byIMAGE_NAME.The
pkgdatadirectory produced as part of the packaging process has been collapsed into a single machine-specific directory. This directory is located undersysrootsand uses a machine-specific name (i.e.tmp/sysroots/<machine>/pkgdata).
BitBake will now shorten revisions from Git repositories from the
normal 40 characters down to 10 characters within
SRCPV
for improved usability in path and file names.
This change should be safe within contexts where these revisions
are used because the chances of spatially close collisions
is very low.
Distant collisions are not a major issue in the way
the values are used.
The following changes have been made that relate to
IMAGE_FEATURES:
The value of
IMAGE_FEATURESis now validated to ensure invalid feature items are not added. Some users mistakenly add package names to this variable instead of usingIMAGE_INSTALLin order to have the package added to the image, which does not work. This change is intended to catch those kinds of situations. ValidIMAGE_FEATURESare drawn fromPACKAGE_GROUPdefinitions,COMPLEMENTARY_GLOBand a new "validitems" varflag onIMAGE_FEATURES. The "validitems" varflag change allows additional features to be added if they are not provided using the previous two mechanisms.The previously deprecated "apps-console-core"
IMAGE_FEATURESitem is no longer supported. Add "splash" toIMAGE_FEATURESif you wish to have the splash screen enabled, since this is all that apps-console-core was doing.
The run directory from the Filesystem
Hierarchy Standard 3.0 has been introduced.
You can find some of the implications for this change
here.
The change also means that recipes that install files to
/var/run must be changed.
You can find a guide on how to make these changes
here.
The image core-image-minimal no longer adds
remove_packaging_data_files to
ROOTFS_POSTPROCESS_COMMAND.
This addition is now handled automatically when "package-management"
is not in
IMAGE_FEATURES.
If you have custom image recipes that make this addition,
you should remove the lines, as they are not needed and might
interfere with correct operation of postinstall scripts.
The do_rootfs and other related image
construction tasks are no longer marked as "nostamp".
Consequently, they will only be re-executed when their inputs have
changed.
Previous versions of the OpenEmbedded build system always rebuilt
the image when requested rather when necessary.
The previously deprecated task.bbclass has
now been dropped.
For recipes that previously inherited from this task, you should
rename them from task-* to
packagegroup-* and inherit packagegroup
instead.
For more information, see the
"packagegroup.bbclass"
section.
By default, we now split BusyBox into two binaries:
one that is suid root for those components that need it, and
another for the rest of the components.
Splitting BusyBox allows for optimization that eliminates the
tinylogin recipe as recommended by upstream.
You can disable this split by setting
BUSYBOX_SPLIT_SUID
to "0".
A new automated image testing framework has been added
through the
testimage*.bbclass
class.
This framework replaces the older
imagetest-qemu framework.
You can learn more about performing automated image tests in the "Performing Automated Runtime Testing" section.
Following are changes to Build History:
Installed package sizes:
installed-package-sizes.txtfor an image now records the size of the files installed by each package instead of the size of each compressed package archive file.The dependency graphs (
depends*.dot) now use the actual package names instead of replacing dashes, dots and plus signs with underscores.The
buildhistory-diffandbuildhistory-collect-srcrevsutilities have improved command-line handling. Use the‐‐helpoption for each utility for more information on the new syntax.
For more information on Build History, see the "Maintaining Build Output Quality" section.
Following are changes to udev:
udevno longer brings inudev-extraconfautomatically throughRRECOMMENDS, since this was originally intended to be optional. If you need the extra rules, then addudev-extraconfto your image.udevno longer brings inpciutils-idsorusbutils-idsthroughRRECOMMENDS. These are not needed byudevitself and removing them saves around 350KB.
The
linux-yocto3.2 kernel has been removed.libtool-nativesdkhas been renamed tonativesdk-libtool.tinyloginhas been removed. It has been replaced by a suid portion of Busybox. See the "BusyBox" section for more information.external-python-tarballhas been renamed tobuildtools-tarball.web-webkithas been removed. It has been functionally replaced bymidori.imakehas been removed. It is no longer needed by any other recipe.transfig-nativehas been removed. It is no longer needed by any other recipe.anjuta-remote-runhas been removed. Anjuta IDE integration has not been officially supported for several releases.
Following is a list of short entries describing other changes:
run-postinsts: Make this generic.base-files: Remove the unnecessarymedia/xxxdirectories.alsa-state: Provide an emptyasound.confby default.classes/image: EnsureBAD_RECOMMENDATIONSsupports pre-renamed package names.classes/rootfs_rpm: ImplementBAD_RECOMMENDATIONSfor RPM.systemd: Removesystemd_unitdirifsystemdis not inDISTRO_FEATURES.systemd: Removeinit.ddir ifsystemdunit file is present andsysvinitis not a distro feature.libpam: Deny all services for theOTHERentries.image.bbclass: Moveruntime_mapping_renameto avoid conflict withmultilib. SeeYOCTO #4993in Bugzilla for more information.linux-dtb: Use kernel build system to generate thedtbfiles.kern-tools: Switch from guilt to newkgit-s2qtool.
- 6.1. Top-Level Core Components
- 6.2. The Build Directory -
build/ - 6.2.1.
build/conf/local.conf - 6.2.2.
build/conf/bblayers.conf - 6.2.3.
build/conf/sanity_info - 6.2.4.
build/downloads/ - 6.2.5.
build/sstate-cache/ - 6.2.6.
build/tmp/ - 6.2.7.
build/tmp/buildstats/ - 6.2.8.
build/tmp/cache/ - 6.2.9.
build/tmp/deploy/ - 6.2.10.
build/tmp/deploy/deb/ - 6.2.11.
build/tmp/deploy/rpm/ - 6.2.12.
build/tmp/deploy/ipk/ - 6.2.13.
build/tmp/deploy/licenses/ - 6.2.14.
build/tmp/deploy/images/ - 6.2.15.
build/tmp/sysroots/ - 6.2.16.
build/tmp/stamps/ - 6.2.17.
build/tmp/log/ - 6.2.18.
build/tmp/work/
- 6.2.1.
- 6.3. The Metadata -
meta/ - 6.3.1.
meta/classes/ - 6.3.2.
meta/conf/ - 6.3.3.
meta/conf/machine/ - 6.3.4.
meta/conf/distro/ - 6.3.5.
meta/files/ - 6.3.6.
meta/lib/ - 6.3.7.
meta/recipes-bsp/ - 6.3.8.
meta/recipes-connectivity/ - 6.3.9.
meta/recipes-core/ - 6.3.10.
meta/recipes-devtools/ - 6.3.11.
meta/recipes-extended/ - 6.3.12.
meta/recipes-gnome/ - 6.3.13.
meta/recipes-graphics/ - 6.3.14.
meta/recipes-kernel/ - 6.3.15.
meta/recipes-lsb4/ - 6.3.16.
meta/recipes-multimedia/ - 6.3.17.
meta/recipes-qt/ - 6.3.18.
meta/recipes-rt/ - 6.3.19.
meta/recipes-sato/ - 6.3.20.
meta/recipes-support/ - 6.3.21.
meta/site/ - 6.3.22.
meta/recipes.txt
- 6.3.1.
The Source Directory consists of several components. Understanding them and knowing where they are located is key to using the Yocto Project well. This chapter describes the Source Directory and gives information about the various files and directories.
For information on how to establish a local Source Directory on your development system, see the "Getting Set Up" section in the Yocto Project Development Manual.
Note
The OpenEmbedded build system does not support file or directory names that contain spaces. Be sure that the Source Directory you use does not contain these types of names.This section describes the top-level components of the Source Directory.
This directory includes a copy of BitBake for ease of use. The copy usually matches the current stable BitBake release from the BitBake project. BitBake, a Metadata interpreter, reads the Yocto Project Metadata and runs the tasks defined by that data. Failures are usually from the Metadata and not from BitBake itself. Consequently, most users do not need to worry about BitBake.
When you run the bitbake command, the
main BitBake executable, which resides in the
bitbake/bin/ directory, starts.
Sourcing an environment setup script (e.g.
oe-init-build-env
or
oe-init-build-env-memres)
places the scripts and
bitbake/bin directories (in that order) into
the shell's PATH environment variable.
For more information on BitBake, see the BitBake documentation
included in the bitbake/doc/manual directory of the
Source Directory.
This directory contains user configuration files and the output
generated by the OpenEmbedded build system in its standard configuration where
the source tree is combined with the output.
The Build Directory
is created initially when you source
the OpenEmbedded build environment setup script
(i.e.
oe-init-build-env
or
oe-init-build-env-memres).
It is also possible to place output and configuration
files in a directory separate from the
Source Directory
by providing a directory name when you source
the setup script.
For information on separating output from your local
Source Directory files, see the
"oe-init-build-env
and
"oe-init-build-env-memres"
sections.
This directory holds the source for the Yocto Project documentation
as well as templates and tools that allow you to generate PDF and HTML
versions of the manuals.
Each manual is contained in a sub-folder.
For example, the files for this manual reside in
the ref-manual/ directory.
This directory contains the OpenEmbedded Core metadata.
The directory holds recipes, common classes, and machine
configuration for emulated targets (qemux86,
qemuarm, and so forth.)
This directory contains the Yocto Project reference hardware Board Support Packages (BSPs). For more information on BSPs, see the Yocto Project Board Support Package (BSP) Developer's Guide.
This directory contains template recipes used by Hob, which is a Yocto Project build user interface. For more information on the Hob, see the Hob Project web page.
This directory contains various integration scripts that implement
extra functionality in the Yocto Project environment (e.g. QEMU scripts).
The oe-init-build-env
and
oe-init-build-env-memres
scripts append this directory to the shell's
PATH environment variable.
The scripts directory has useful scripts that assist in contributing
back to the Yocto Project, such as create-pull-request and
send-pull-request.
This script is one of two scripts that set up the OpenEmbedded build
environment.
For information on the other script, see the
"oe-init-build-env-memres"
section.
Running this script with the source command in
a shell makes changes to PATH and sets other
core BitBake variables based on the current working directory.
You need to run an environment setup script before running BitBake
commands.
The script uses other scripts within the
scripts directory to do the bulk of the work.
By default, running this script without a
Build Directory
argument creates the build directory
in your current working directory.
If you provide a Build Directory argument when you
source the script, you direct the OpenEmbedded
build system to create a Build Directory of your choice.
For example, the following command creates a Build Directory named
mybuilds that is outside of the
Source Directory:
$ source oe-init-build-env ~/mybuilds
Note
The OpenEmbedded build system does not support file or directory names that contain spaces. If you attempt to run theoe-init-build-env script
from a Source Directory that contains spaces in either the filenames
or directory names, the script returns an error indicating no such
file or directory.
Be sure to use a Source Directory free of names containing spaces.
This script is one of two scripts that set up the OpenEmbedded
build environment.
Aside from setting up the environment, this script starts a
memory-resident BitBake server.
For information on the other setup script, see the
"oe-init-build-env"
section.
Memory-resident BitBake resides in memory until you specifically remove it using the following BitBake command:
$ bitbake -m
Running this script with the source command in
a shell makes changes to PATH and sets other
core BitBake variables based on the current working directory.
One of these variables is the
BBSERVER
variable, which allows the OpenEmbedded build system to locate
the server that is running BitBake.
You need to run an environment setup script before using BitBake commands. Following is the script syntax:
$ source oe-init-build-env-memres <port_number> <build_dir>
The script uses other scripts within the
scripts directory to do the bulk of the work.
If you do not provide a port number with the script, the BitBake server at port "12345" is started.
By default, running this script without a
Build Directory
argument creates a build directory named
build.
If you provide a Build Directory argument when you
source the script, the Build Directory is
created using that name.
For example, the following command starts the BitBake server using
the default port "12345" and creates a Build Directory named
mybuilds that is outside of the
Source Directory:
$ source oe-init-build-env-memres ~/mybuilds
Note
The OpenEmbedded build system does not support file or directory names that contain spaces. If you attempt to run theoe-init-build-env-memres script
from a Source Directory that contains spaces in either the
filenames or directory names, the script returns an error
indicating no such file or directory.
Be sure to use a Source Directory free of names containing
spaces.
The OpenEmbedded build system creates the
Build Directory
during the build.
By default, this directory is named build.
This configuration file contains all the local user configurations
for your build environment.
The local.conf file contains documentation on
the various configuration options.
Any variable set here overrides any variable set elsewhere within
the environment unless that variable is hard-coded within a file
(e.g. by using '=' instead of '?=').
Some variables are hard-coded for various reasons but these
variables are relatively rare.
Edit this file to set the
MACHINE
for which you want to build, which package types you wish to use
(PACKAGE_CLASSES),
the location from which you want to access downloaded files
(DL_DIR),
and how you want your host machine to use resources
(BB_NUMBER_THREADS
and
PARALLEL_MAKE).
If local.conf is not present when you
start the build, the OpenEmbedded build system creates it from
local.conf.sample when
you source the top-level build environment
setup script (i.e.
oe-init-build-env
or
oe-init-build-env-memres).
The source local.conf.sample file used
depends on the $TEMPLATECONF script variable,
which defaults to meta-yocto/conf
when you are building from the Yocto Project development
environment and defaults to meta/conf when
you are building from the OpenEmbedded Core environment.
Because the script variable points to the source of the
local.conf.sample file, this implies that
you can configure your build environment from any layer by setting
the variable in the top-level build environment setup script as
follows:
TEMPLATECONF=<your_layer>/conf
Once the build process gets the sample file, it uses
sed to substitute final
${OEROOT}
values for all ##OEROOT## values.
Note
You can see how theTEMPLATECONF variable
is used by looking at the
scripts/oe-setup-builddir script in the
Source Directory.
You can find the Yocto Project version of the
local.conf.sample file in the
meta-yocto/conf directory.
This configuration file defines
layers,
which are directory trees, traversed (or walked) by BitBake.
The bblayers.conf file uses the
BBLAYERS
variable to list the layers BitBake tries to find, and uses the
BBLAYERS_NON_REMOVABLE
variable to list layers that must not be removed.
If bblayers.conf is not present when you
start the build, the OpenEmbedded build system creates it from
bblayers.conf.sample when
you source the top-level build environment
setup script (i.e.
oe-init-build-env
or
oe-init-build-env-memres).
The source bblayers.conf.sample file used
depends on the $TEMPLATECONF script variable,
which defaults to meta-yocto/conf
when you are building from the Yocto Project development
environment and defaults to meta/conf when
you are building from the OpenEmbedded Core environment.
Because the script variable points to the source of the
bblayers.conf.sample file, this implies that
you can base your build from any layer by setting the variable in
the top-level build environment setup script as follows:
TEMPLATECONF=<your_layer>/conf
Once the build process gets the sample file, it uses
sed to substitute final
${OEROOT}
values for all ##OEROOT## values.
Note
You can see how theTEMPLATECONF variable
scripts/oe-setup-builddir script in the
Source Directory.
You can find the Yocto Project version of the
bblayers.conf.sample file in the
meta-yocto/conf directory.
This file indicates the state of the sanity checks and is created during the build.
This directory contains downloaded upstream source tarballs.
You can reuse the directory for multiple builds or move
the directory to another location.
You can control the location of this directory through the
DL_DIR variable.
This directory contains the shared state cache.
You can reuse the directory for multiple builds or move
the directory to another location.
You can control the location of this directory through the
SSTATE_DIR variable.
This directory receives all of the OpenEmbedded build system's output.
BitBake creates this directory if it does not exist.
As a last resort, to clean up a build and start it from scratch (other than the downloads),
you can remove everything in the tmp directory or get rid of the
directory completely.
If you do, you should also completely remove the
build/sstate-cache directory.
When BitBake parses the metadata, it creates a cache file of the result that can be used when subsequently running commands. BitBake stores these results here on a per-machine basis.
This directory contains any "end result" output from the
OpenEmbedded build process.
The DEPLOY_DIR
variable points to this directory.
For more detail on the contents of the deploy
directory, see the
"Images" and
"Application Development SDK"
sections.
This directory receives any .deb packages produced by
the build process.
The packages are sorted into feeds for different architecture types.
This directory receives any .rpm packages produced by
the build process.
The packages are sorted into feeds for different architecture types.
This directory receives package licensing information.
For example, the directory contains sub-directories for bash,
busybox, and eglibc (among others) that in turn
contain appropriate COPYING license files with other licensing information.
For information on licensing, see the
"Maintaining Open Source License Compliance During Your Product's Lifecycle"
section.
This directory receives complete filesystem images. If you want to flash the resulting image from a build onto a device, look here for the image.
Be careful when deleting files in this directory.
You can safely delete old images from this directory (e.g.
core-image-*, hob-image-*,
etc.).
However, the kernel (*zImage*, *uImage*, etc.),
bootloader and other supplementary files might be deployed here prior to building an
image.
Because these files are not directly produced from the image, if you
delete them they will not be automatically re-created when you build the image again.
If you do accidentally delete files here, you will need to force them to be re-created. In order to do that, you will need to know the target that produced them. For example, these commands rebuild and re-create the kernel files:
$ bitbake -c clean virtual/kernel
$ bitbake virtual/kernel
This directory contains shared header files and libraries as well as other shared data. Packages that need to share output with other packages do so within this directory. The directory is subdivided by architecture so multiple builds can run within the one Build Directory.
This directory holds information that BitBake uses for accounting purposes to track what tasks have run and when they have run. The directory is sub-divided by architecture, package name, and version. Following is an example:
stamps/all-poky-linux/distcc-config/1.0-r0.do_build-2fdd....2do
Although the files in the directory are empty of data, BitBake uses the filenames and timestamps for tracking purposes.
This directory contains general logs that are not otherwise placed using the
package's WORKDIR.
Examples of logs are the output from the check_pkg or
distro_check tasks.
Running a build does not necessarily mean this directory is created.
This directory contains architecture-specific work sub-directories
for packages built by BitBake.
All tasks execute from the appropriate work directory.
For example, the source for a particular package is unpacked,
patched, configured and compiled all within its own work directory.
Within the work directory, organization is based on the package group
and version for which the source is being compiled
as defined by the
WORKDIR.
It is worth considering the structure of a typical work directory.
As an example, consider linux-yocto-kernel-3.0
on the machine qemux86
built within the Yocto Project.
For this package, a work directory of
tmp/work/qemux86-poky-linux/linux-yocto/3.0+git1+<.....>,
referred to as the
WORKDIR, is created.
Within this directory, the source is unpacked to
linux-qemux86-standard-build and then patched by Quilt.
(See the
"Using a Quilt Flow"
section in the Yocto Project Development Manual for more information.)
Within the linux-qemux86-standard-build directory,
standard Quilt directories linux-3.0/patches
and linux-3.0/.pc are created,
and standard Quilt commands can be used.
There are other directories generated within WORKDIR.
The most important directory is WORKDIR/temp/,
which has log files for each task (log.do_*.pid)
and contains the scripts BitBake runs for each task
(run.do_*.pid).
The WORKDIR/image/ directory is where "make
install" places its output that is then split into sub-packages
within WORKDIR/packages-split/.
As mentioned previously, Metadata is the core of the Yocto Project. Metadata has several important subdivisions:
This directory contains the *.bbclass files.
Class files are used to abstract common code so it can be reused by multiple
packages.
Every package inherits the base.bbclass file.
Examples of other important classes are autotools.bbclass, which
in theory allows any Autotool-enabled package to work with the Yocto Project with minimal effort.
Another example is kernel.bbclass that contains common code and functions
for working with the Linux kernel.
Functions like image generation or packaging also have their specific class files
such as image.bbclass, rootfs_*.bbclass and
package*.bbclass.
For reference information on classes, see the "Classes" chapter.
This directory contains the core set of configuration files that start from
bitbake.conf and from which all other configuration
files are included.
See the include statements at the end of the
bitbake.conf file and you will note that even
local.conf is loaded from there.
While bitbake.conf sets up the defaults, you can often override
these by using the (local.conf) file, machine file or
the distribution configuration file.
This directory contains all the machine configuration files.
If you set MACHINE = "qemux86",
the OpenEmbedded build system looks for a qemux86.conf file in this
directory.
The include directory contains various data common to multiple machines.
If you want to add support for a new machine to the Yocto Project, look in this directory.
The contents of this directory controls any distribution-specific
configurations.
For the Yocto Project, the defaultsetup.conf is the main file here.
This directory includes the versions and the
SRCDATE definitions for applications that are configured here.
An example of an alternative configuration might be poky-bleeding.conf.
Although this file mainly inherits its configuration from Poky.
This directory contains common license files and several text files used by the build system. The text files contain minimal device information and lists of files and directories with known permissions.
This directory contains OpenEmbedded Python library code used during the build process.
This directory contains anything linking to specific hardware or hardware configuration information such as "u-boot" and "grub".
This directory contains libraries and applications related to communication with other devices.
This directory contains what is needed to build a basic working Linux image including commonly used dependencies.
This directory contains tools that are primarily used by the build system. The tools, however, can also be used on targets.
This directory contains non-essential applications that add features compared to the alternatives in core. You might need this directory for full tool functionality or for Linux Standard Base (LSB) compliance.
This directory contains all things related to the GTK+ application framework.
This directory contains X and other graphically related system libraries
This directory contains the kernel and generic applications and libraries that have strong kernel dependencies.
This directory contains recipes specifically added to support the Linux Standard Base (LSB) version 4.x.
This directory contains codecs and support utilities for audio, images and video.
This directory contains all things related to the Qt application framework.
This directory contains package and image recipes for using and testing
the PREEMPT_RT kernel.
This directory contains the Sato demo/reference UI/UX and its associated applications and configuration data.
This directory contains recipes used by other recipes, but that are not directly included in images (i.e. dependencies of other recipes).
This directory contains a list of cached results for various architectures. Because certain "autoconf" test results cannot be determined when cross-compiling due to the tests not able to run on a live system, the information in this directory is passed to "autoconf" for the various architectures.
BitBake is a program written in Python that interprets the Metadata used by the OpenEmbedded build system. At some point, developers wonder what actually happens when you enter:
$ bitbake core-image-sato
This chapter provides an overview of what happens behind the scenes from BitBake's perspective.
Note
BitBake strives to be a generic "task" executor that is capable of handling complex dependency relationships. As such, it has no real knowledge of what the tasks being executed actually do. BitBake just considers a list of tasks with dependencies and handles Metadata consisting of variables in a certain format that get passed to the tasks.
BitBake parses configuration files, classes, and .bb files.
The first thing BitBake does is look for the bitbake.conf file.
This file resides in the
Source Directory
within the meta/conf/ directory.
BitBake finds it by examining its
BBPATH environment
variable and looking for the meta/conf/
directory.
The bitbake.conf file lists other configuration
files to include from a conf/
directory below the directories listed in BBPATH.
In general, the most important configuration file from a user's perspective
is local.conf, which contains a user's customized
settings for the OpenEmbedded build environment.
Other notable configuration files are the distribution
configuration file (set by the
DISTRO variable)
and the machine configuration file
(set by the
MACHINE variable).
The DISTRO and MACHINE BitBake environment
variables are both usually set in
the local.conf file.
Valid distribution
configuration files are available in the meta/conf/distro/ directory
and valid machine configuration
files in the meta/conf/machine/ directory.
Within the meta/conf/machine/include/
directory are various tune-*.inc configuration files that provide common
"tuning" settings specific to and shared between particular architectures and machines.
After the parsing of the configuration files, some standard classes are included.
The base.bbclass file is always included.
Other classes that are specified in the configuration using the
INHERIT
variable are also included.
Class files are searched for in a classes subdirectory
under the paths in BBPATH in the same way as
configuration files.
After classes are included, the variable
BBFILES
is set, usually in
local.conf, and defines the list of places to search for
.bb files.
By default, the BBFILES variable specifies the
meta/recipes-*/ directory within Poky.
Adding extra content to BBFILES is best achieved through the use of
BitBake layers as described in the
"Understanding and
Creating Layers" section of the Yocto Project Development Manual.
BitBake parses each .bb file in BBFILES and
stores the values of various variables.
In summary, for each .bb
file the configuration plus the base class of variables are set, followed
by the data in the .bb file
itself, followed by any inherit commands that
.bb file might contain.
Because parsing .bb files is a time
consuming process, a cache is kept to speed up subsequent parsing.
This cache is invalid if the timestamp of the .bb
file itself changes, or if the timestamps of any of the include,
configuration files or class files on which the
.bb file depends change.
Once all the .bb files have been
parsed, BitBake starts to build the target (core-image-sato
in the previous section's example) and looks for providers of that target.
Once a provider is selected, BitBake resolves all the dependencies for
the target.
In the case of core-image-sato, it would lead to
packagegroup-core-x11-sato,
which in turn leads to recipes like matchbox-terminal,
pcmanfm and gthumb.
These recipes in turn depend on eglibc and the toolchain.
Sometimes a target might have multiple providers. A common example is "virtual/kernel", which is provided by each kernel package. Each machine often selects the best kernel provider by using a line similar to the following in the machine configuration file:
PREFERRED_PROVIDER_virtual/kernel = "linux-yocto"
The default PREFERRED_PROVIDER
is the provider with the same name as the target.
Understanding how providers are chosen is made complicated by the fact
that multiple versions might exist.
BitBake defaults to the highest version of a provider.
Version comparisons are made using the same method as Debian.
You can use the
PREFERRED_VERSION
variable to specify a particular version (usually in the distro configuration).
You can influence the order by using the
DEFAULT_PREFERENCE
variable.
By default, files have a preference of "0".
Setting the DEFAULT_PREFERENCE to "-1" makes the
package unlikely to be used unless it is explicitly referenced.
Setting the DEFAULT_PREFERENCE to "1" makes it likely the package is used.
PREFERRED_VERSION overrides any DEFAULT_PREFERENCE setting.
DEFAULT_PREFERENCE is often used to mark newer and more experimental package
versions until they have undergone sufficient testing to be considered stable.
In summary, BitBake has created a list of providers, which is prioritized, for each target.
Each target BitBake builds consists of multiple tasks such as
fetch, unpack,
patch, configure,
and compile.
For best performance on multi-core systems, BitBake considers each task as an independent
entity with its own set of dependencies.
Dependencies are defined through several variables.
You can find information about variables BitBake uses in the BitBake documentation,
which is found in the bitbake/doc/manual directory within the
Source Directory.
At a basic level, it is sufficient to know that BitBake uses the
DEPENDS and
RDEPENDS variables when
calculating dependencies.
Based on the generated list of providers and the dependency information,
BitBake can now calculate exactly what tasks it needs to run and in what
order it needs to run them.
The build now starts with BitBake forking off threads up to the limit set in the
BB_NUMBER_THREADS variable.
BitBake continues to fork threads as long as there are tasks ready to run,
those tasks have all their dependencies met, and the thread threshold has not been
exceeded.
It is worth noting that you can greatly speed up the build time by properly setting
the BB_NUMBER_THREADS variable.
See the
"Building an Image"
section in the Yocto Project Quick Start for more information.
As each task completes, a timestamp is written to the directory specified by the
STAMP variable.
On subsequent runs, BitBake looks within the build/tmp/stamps
directory and does not rerun
tasks that are already completed unless a timestamp is found to be invalid.
Currently, invalid timestamps are only considered on a per
.bb file basis.
So, for example, if the configure stamp has a timestamp greater than the
compile timestamp for a given target, then the compile task would rerun.
Running the compile task again, however, has no effect on other providers
that depend on that target.
This behavior could change or become configurable in future versions of BitBake.
Note
Some tasks are marked as "nostamp" tasks. No timestamp file is created when these tasks are run. Consequently, "nostamp" tasks are always rerun.
Tasks can either be a shell task or a Python task.
For shell tasks, BitBake writes a shell script to
${WORKDIR}/temp/run.do_taskname.pid and then executes the script.
The generated shell script contains all the exported variables, and the shell functions
with all variables expanded.
Output from the shell script goes to the file ${WORKDIR}/temp/log.do_taskname.pid.
Looking at the expanded shell functions in the run file and the output in the log files
is a useful debugging technique.
For Python tasks, BitBake executes the task internally and logs information to the controlling terminal. Future versions of BitBake will write the functions to files similar to the way shell tasks are handled. Logging will be handled in a way similar to shell tasks as well.
Once all the tasks have been completed BitBake exits.
When running a task, BitBake tightly controls the execution environment of the build tasks to make sure unwanted contamination from the build machine cannot influence the build. Consequently, if you do want something to get passed into the build task's environment, you must take a few steps:
Tell BitBake to load what you want from the environment into the data store. You can do so through the
BB_ENV_EXTRAWHITEvariable. For example, assume you want to prevent the build system from accessing your$HOME/.ccachedirectory. The following command tells BitBake to loadCCACHE_DIRfrom the environment into the data store:export BB_ENV_EXTRAWHITE="$BB_ENV_EXTRAWHITE CCACHE_DIR"Tell BitBake to export what you have loaded into the environment store to the task environment of every running task. Loading something from the environment into the data store (previous step) only makes it available in the datastore. To export it to the task environment of every running task, use a command similar to the following in your
local.confor distro configuration file:export CCACHE_DIR
Note
A side effect of the previous steps is that BitBake records the variable as a dependency of the build process in things like the shared state checksums. If doing so results in unnecessary rebuilds of tasks, you can whitelist the variable so that the shared state code ignores the dependency when it creates checksums. For information on this process, see theBB_HASHBASE_WHITELIST
example in the "Checksums (Signatures)" section.
Following is the BitBake help output:
$ bitbake --help
Usage: bitbake [options] [recipename/target ...]
Executes the specified task (default is 'build') for a given set of target recipes (.bb files).
It is assumed there is a conf/bblayers.conf available in cwd or in BBPATH which
will provide the layer, BBFILES and other configuration information.
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-b BUILDFILE, --buildfile=BUILDFILE
Execute tasks from a specific .bb recipe directly.
WARNING: Does not handle any dependencies from other
recipes.
-k, --continue Continue as much as possible after an error. While the
target that failed and anything depending on it cannot
be built, as much as possible will be built before
stopping.
-a, --tryaltconfigs Continue with builds by trying to use alternative
providers where possible.
-f, --force Force the specified targets/task to run (invalidating
any existing stamp file).
-c CMD, --cmd=CMD Specify the task to execute. The exact options
available depend on the metadata. Some examples might
be 'compile' or 'populate_sysroot' or 'listtasks' may
give a list of the tasks available.
-C INVALIDATE_STAMP, --clear-stamp=INVALIDATE_STAMP
Invalidate the stamp for the specified task such as
'compile' and then run the default task for the
specified target(s).
-r PREFILE, --read=PREFILE
Read the specified file before bitbake.conf.
-R POSTFILE, --postread=POSTFILE
Read the specified file after bitbake.conf.
-v, --verbose Output more log message data to the terminal.
-D, --debug Increase the debug level. You can specify this more
than once.
-n, --dry-run Don't execute, just go through the motions.
-S, --dump-signatures
Don't execute, just dump out the signature
construction information.
-p, --parse-only Quit after parsing the BB recipes.
-s, --show-versions Show current and preferred versions of all recipes.
-e, --environment Show the global or per-package environment complete
with information about where variables were
set/changed.
-g, --graphviz Save dependency tree information for the specified
targets in the dot syntax.
-I EXTRA_ASSUME_PROVIDED, --ignore-deps=EXTRA_ASSUME_PROVIDED
Assume these dependencies don't exist and are already
provided (equivalent to ASSUME_PROVIDED). Useful to
make dependency graphs more appealing
-l DEBUG_DOMAINS, --log-domains=DEBUG_DOMAINS
Show debug logging for the specified logging domains
-P, --profile Profile the command and save reports.
-u UI, --ui=UI The user interface to use (e.g. knotty, hob, depexp).
-t SERVERTYPE, --servertype=SERVERTYPE
Choose which server to use, process or xmlrpc.
--revisions-changed Set the exit code depending on whether upstream
floating revisions have changed or not.
--server-only Run bitbake without a UI, only starting a server
(cooker) process.
-B BIND, --bind=BIND The name/address for the bitbake server to bind to.
--no-setscene Do not run any setscene tasks. sstate will be ignored
and everything needed, built.
--remote-server=REMOTE_SERVER
Connect to the specified server.
-m, --kill-server Terminate the remote server.
--observe-only Connect to a server as an observing-only client.
BitBake also contains a set of "fetcher" modules that allow
retrieval of source code from various types of sources.
For example, BitBake can get source code from a disk with the metadata, from websites,
from remote shell accounts, or from Source Code Management (SCM) systems
like cvs/subversion/git.
Fetchers are usually triggered by entries in
SRC_URI.
You can find information about the options and formats of entries for specific
fetchers in the BitBake manual located in the
bitbake/doc/manual directory of the
Source Directory.
One useful feature for certain Source Code Manager (SCM) fetchers is the ability to
"auto-update" when the upstream SCM changes version.
Since this ability requires certain functionality from the SCM, not all
systems support it.
Currently Subversion, Bazaar and to a limited extent, Git support the ability to "auto-update".
This feature works using the SRCREV
variable.
See the
"Using an External SCM" section
in the Yocto Project Development Manual for more information.
- 8.1.
allarch.bbclass - 8.2.
archive*.bbclass - 8.3.
autotools.bbclass - 8.4.
base.bbclass - 8.5.
bin_package.bbclass - 8.6.
binconfig.bbclass - 8.7.
blacklist.bbclass - 8.8.
boot-directdisk.bbclass - 8.9.
bootimg.bbclass - 8.10.
bugzilla.bbclass - 8.11.
buildhistory.bbclass - 8.12.
buildstats.bbclass - 8.13.
ccache.bbclass - 8.14.
chrpath.bbclass - 8.15.
clutter.bbclass - 8.16.
cmake.bbclass - 8.17.
cml1.bbclass - 8.18.
copyleft_compliance.bbclass - 8.19.
core-image.bbclass - 8.20.
cpan.bbclass - 8.21.
cross.bbclass - 8.22.
cross-canadian.bbclass - 8.23.
crosssdk.bbclass - 8.24.
debian.bbclass - 8.25.
deploy.bbclass - 8.26.
devshell.bbclass - 8.27.
distro_features_check.bbclass - 8.28.
distrodata.bbclass - 8.29.
distutils.bbclass - 8.30.
externalsrc.bbclass - 8.31.
extrausers.bbclass - 8.32.
fontcache.bbclass - 8.33.
gconf.bbclass - 8.34.
gettext.bbclass - 8.35.
gnome.bbclass - 8.36.
gnomebase.bbclass - 8.37.
grub-efi.bbclass - 8.38.
gsettings.bbclass - 8.39.
gtk-doc.bbclass - 8.40.
gtk-icon-cache.bbclass - 8.41.
gtk-immodules-cache.bbclass - 8.42.
gzipnative.bbclass - 8.43.
icecc.bbclass - 8.44.
image.bbclass - 8.45.
image_types.bbclass - 8.46.
image_types_uboot.bbclass - 8.47.
image-live.bbclass - 8.48.
image-mklibs.bbclass - 8.49.
image-prelink.bbclass - 8.50.
image-swab.bbclass - 8.51.
image-vmdk.bbclass - 8.52.
insane.bbclass - 8.53.
insserv.bbclass - 8.54.
kernel.bbclass - 8.55.
kernel-arch.bbclass - 8.56.
kernel-module-split.bbclass - 8.57.
kernel-yocto.bbclass - 8.58.
lib_package.bbclass - 8.59.
license.bbclass - 8.60.
linux-kernel-base.bbclass - 8.61.
logging.bbclass - 8.62.
meta.bbclass - 8.63.
metadata_scm.bbclass - 8.64.
mime.bbclass - 8.65.
mirrors.bbclass - 8.66.
module.bbclass - 8.67.
module-base.bbclass - 8.68.
multilib*.bbclass - 8.69.
native.bbclass - 8.70.
nativesdk.bbclass - 8.71.
oelint.bbclass - 8.72.
own-mirrors.bbclass - 8.73.
package.bbclass - 8.74.
package_deb.bbclass - 8.75.
package_ipk.bbclass - 8.76.
package_rpm.bbclass - 8.77.
package_tar.bbclass - 8.78.
packagedata.bbclass - 8.79.
packagegroup.bbclass - 8.80.
packageinfo.bbclass - 8.81.
patch.bbclass - 8.82.
perlnative.bbclass - 8.83.
pixbufcache.bbclass - 8.84.
pkgconfig.bbclass - 8.85.
populate_sdk.bbclass - 8.86.
populate_sdk_*.bbclass - 8.87.
prexport.bbclass - 8.88.
primport.bbclass - 8.89.
prserv.bbclass - 8.90.
ptest.bbclass - 8.91.
python-dir.bbclass - 8.92.
pythonnative.bbclass - 8.93.
qemu.bbclass - 8.94.
qmake*.bbclass - 8.95.
qt4*.bbclass - 8.96.
relocatable.bbclass - 8.97.
rm_work.bbclass - 8.98.
rootfs*.bbclass - 8.99.
sanity.bbclass - 8.100.
scons.bbclass - 8.101.
sdl.bbclass - 8.102.
setuptools.bbclass - 8.103.
sip.bbclass - 8.104.
siteconfig.bbclass - 8.105.
siteinfo.bbclass - 8.106.
spdx.bbclass - 8.107.
sstate.bbclass - 8.108.
staging.bbclass - 8.109.
syslinux.bbclass - 8.110.
systemd.bbclass - 8.111.
terminal.bbclass - 8.112.
testimage.bbclass - 8.113.
tinderclient.bbclass - 8.114.
toaster.bbclass - 8.115.
toolchain-scripts.bbclass - 8.116.
typecheck.bbclass - 8.117.
uboot-config.bbclass - 8.118.
update-alternatives.bbclass - 8.119.
update-rc.d.bbclass - 8.120.
useradd.bbclass - 8.121.
utility-tasks.bbclass - 8.122.
utils.bbclass - 8.123.
vala.bbclass - 8.124.
waf.bbclass
Class files are used to abstract common functionality and share it amongst
multiple recipe (.bb) files.
To use a class file, you simply make sure the recipe inherits the class.
In most cases, when a recipe inherits a class it is enough to enable its
features.
There are cases, however, where in the recipe you might need to set
variables or override some default behavior.
Any Metadata usually
found in a recipe can also be placed in a class file.
Class files are identified by the extension .bbclass
and are usually placed in a classes/ directory beneath
the meta*/ directory found in the
Source Directory.
Class files can also be pointed to by
BUILDDIR
(e.g. build/) in the same way as
.conf files in the conf directory.
Class files are searched for in
BBPATH
using the same method by which .conf files are
searched.
This chapter discusses only the most useful and important classes.
Other classes do exist within the meta/classes
directory in the
Source Directory.
You can reference the .bbclass files directly
for more information.
The allarch class is inherited
by recipes that do not produce architecture-specific output.
The class disables functionality that is normally needed for recipes
that produce executable binaries (such as building the cross-compiler
and a C library as pre-requisites, and splitting out of debug symbols
during packaging).
By default, all recipes inherit the
base and
package
classes, which enable functionality
needed for recipes that produce executable output.
If your recipe, for example, only produces packages that contain
configuration files, media files, or scripts (e.g. Python and Perl),
then it should inherit the allarch class.
The archive* set of classes support releasing
source code and other materials with the binaries.
This set of classes consists of the following:
archive-original-sources.bbclassarchive-patched-sources.bbclassarchive-configured-sources.bbclassarchiver.bbclass
For more details on the source archiver, see the "Maintaining Open Source License Compliance During Your Product's Lifecycle" section in the Yocto Project Development Manual.
The autotools class supports Autotooled
packages.
The autoconf, automake,
and libtool bring standardization.
This class defines a set of tasks (configure, compile etc.) that
work for all Autotooled packages.
It should usually be enough to define a few standard variables
and then simply inherit autotools.
This class can also work with software that emulates Autotools.
For more information, see the
"Autotooled Package"
section in the Yocto Project Development Manual.
It's useful to have some idea of how the tasks defined by this class work and what they do behind the scenes.
do_configure‐ Regenerates the configure script (usingautoreconf) and then launches it with a standard set of arguments used during cross-compilation. You can pass additional parameters toconfigurethrough theEXTRA_OECONFvariable.do_compile‐ Runsmakewith arguments that specify the compiler and linker. You can pass additional arguments through theEXTRA_OEMAKEvariable.do_install‐ Runsmake installand passes in${D}asDESTDIR.
The base class is special in that every
.bb file implicitly inherits the class.
This class contains definitions for standard basic
tasks such as fetching, unpacking, configuring (empty by default),
compiling (runs any Makefile present), installing
(empty by default) and packaging (empty by default).
These classes are often overridden or extended by other classes
such as the
autotools
class or the
package
class.
The class also contains some commonly used functions such as
oe_runmake.
The bin_package class is a
helper class for recipes that extract the contents of a binary package
(e.g. an RPM) and install those contents rather than building the
binary from source.
The binary package is extracted and new packages in the configured
output package format are created.
Note
For RPMs and other packages that do not contain a subdirectory, you should specify a "subdir" parameter. Here is an example where${BP} is used so that
the files are extracted into the subdirectory expected by the
default value of
S:
SRC_URI = "http://example.com/downloads/somepackage.rpm;subdir=${BP}"
The binconfig class helps to correct paths in
shell scripts.
Before pkg-config had become widespread, libraries
shipped shell scripts to give information about the libraries and
include paths needed to build software (usually named
LIBNAME-config).
This class assists any recipe using such scripts.
During staging, the OpenEmbedded build system installs such scripts
into the sysroots/ directory.
Inheriting this class results in all paths in these scripts being
changed to point into the sysroots/ directory so
that all builds that use the script use the correct directories
for the cross compiling layout.
See the
BINCONFIG_GLOB
variable for more information.
The blacklist class prevents
the OpenEmbedded build system from building specific recipes
(blacklists them).
To use this class, inherit the class globally and set
PNBLACKLIST
for each recipe you wish to blacklist.
Specify the PN
value as a variable flag (varflag) and provide a reason, which is
reported, if the package is requested to be built as the value.
For example, if you want to blacklist a recipe called "exoticware",
you add the following to your local.conf
or distribution configuration:
INHERIT += "blacklist"
PNBLACKLIST[exoticware] = "Not supported by our organization."
The boot-directdisk class
creates an image that can be placed directly onto a hard disk using
dd and then booted.
The image uses SYSLINUX.
The end result is a 512 boot sector populated with a
Master Boot Record (MBR) and partition table followed by an MSDOS
FAT16 partition containing SYSLINUX and a Linux kernel completed by
the ext2 and ext3
root filesystems.
The bootimg class creates a bootable
image using SYSLINUX, your kernel and an optional initial RAM disk
(initrd).
When you use this class, two things happen:
A
.hddimgfile is created. This file which is an MSDOS filesystem that contains SYSLINUX, a kernel, aninitrd, and a root filesystem image. All three of these can be written to hard drives directly and also booted on a USB flash disks usingdd.A CD
.isoimage is created. When this file is booted, theinitrdboots and processes the label selected in SYSLINUX. Actions based on the label are then performed (e.g. installing to a hard drive).
The bootimg class supports the
INITRD,
NOISO,
NOHDD, and
ROOTFS
variables.
The bugzilla class supports setting up an
instance of Bugzilla in which you can automatically files bug reports
in response to build failures.
For this class to work, you need to enable the XML-RPC interface in
the instance of Bugzilla.
The buildhistory class records a
history of build output metadata, which can be used to detect possible
regressions as well as used for analysis of the build output.
For more information on using Build History, see the
"Maintaining Build Output Quality"
section.
The buildstats class records
performance statistics about each task executed during the build
(e.g. elapsed time, CPU usage, and I/O usage).
When you use this class, the output goes into the
BUILDSTATS_BASE
directory, which defaults to ${TMPDIR}/buildstats/.
You can analyze the elapsed time using
scripts/pybootchartgui/pybootchartgui.py, which
produces a cascading chart of the entire build process and can be
useful for highlighting bottlenecks.
Collecting build statistics is enabled by default through the
USER_CLASSES
variable from your local.conf file.
Consequently, you do not have to do anything to enable the class.
However, if you want to disable the class, simply remove "buildstats"
from the USER_CLASSES list.
The ccache class enables the
C/C++ Compiler Cache
for the build.
This class is used to give a minor performance boost during the build.
However, using the class can lead to unexpected side-effects.
Thus, it is recommended that you do not use this class.
See http://ccache.samba.org/ for information on
the C/C++ Compiler Cache.
The chrpath class
is a wrapper around the "chrpath" utility, which is used during the
build process for nativesdk,
cross, and
cross-canadian recipes to change
RPATH records within binaries in order to make
them relocatable.
The clutter class consolidates the
major and minor version naming and other common items used by Clutter
and related recipes.
Note
Unlike some other classes related to specific libraries, recipes building other software that uses Clutter do not need to inherit this class unless they use the same recipe versioning scheme that the Clutter and related recipes do.
The cmake class allows for
recipes that need to build software using the CMake build system.
You can use the
EXTRA_OECMAKE
variable to specify additional configuration options to be passed on
the cmake command line.
The cml1 class provides basic support for the
Linux kernel style build configuration system.
The copyleft_compliance class
preserves source code for the purposes of license compliance.
This class is an alternative to the archive*
classes and is still used by some users even though it has been
deprecated in favor of the
archive*
classes.
The core-image class
provides common definitions for the
core-image-* image recipes, such as support for
additional
IMAGE_FEATURES.
The cpan class supports Perl modules.
Recipes for Perl modules are simple. These recipes usually only need to point to the source's archive and then inherit the proper class file. Building is split into two methods depending on which method the module authors used.
Modules that use old
Makefile.PL-based build system requirecpan.bbclassin their recipes.Modules that use
Build.PL-based build system require usingcpan_build.bbclassin their recipes.
The cross class provides support for the recipes
that build the cross-compilation tools.
The cross-canadian class
provides support for the recipes that build the Canadian
Cross-compilation tools for SDKs.
See the
"Cross-Development Toolchain Generation"
section for more discussion on these cross-compilation tools.
The crosssdk class
provides support for the recipes that build the cross-compilation
tools used for building SDKs.
See the
"Cross-Development Toolchain Generation"
section for more discussion on these cross-compilation tools.
The debian class renames output packages so that
they follow the Debian naming policy (i.e. eglibc
becomes libc6 and eglibc-devel
becomes libc6-dev.)
Renaming includes the library name and version as part of the package
name.
If a recipe creates packages for multiple libraries
(shared object files of .so type), use the
LEAD_SONAME
variable in the recipe to specify the library on which to apply the
naming scheme.
The deploy class handles deploying files
to the
DEPLOY_DIR_IMAGE
directory.
The main function of this class is to allow the deploy step to be
accelerated by shared state.
Recipes that inherit this class should define their own
do_deploy function to copy the files to be
deployed to
DEPLOYDIR,
and use addtask to add the task at the appropriate
place, which is usually after do_compile or
do_install.
The class then takes care of staging the files from
DEPLOYDIR to
DEPLOY_DIR_IMAGE.
The devshell class adds the
devshell task.
Distribution policy dictates whether to include this class.
See the
"Using a Development Shell" section
in the Yocto Project Development Manual for more information about
using devshell.
The distro_features_check class
allows individual recipes to check for required and conflicting
DISTRO_FEATURES.
This class provides support for the
REQUIRED_DISTRO_FEATURES
and
CONFLICT_DISTRO_FEATURES
variables.
If any conditions specified in the recipe using the above variables are
not met, the recipe will be skipped.
The distrodata class
provides for automatic checking for upstream recipe updates.
The class creates a comma-separated value (CSV) spreadsheet that
contains information about the recipes.
The information provides the distrodata and
distro_check tasks, which do upstream checking
and also verify if a package is used in multiple major distributions.
The class is not included by default.
To use it, you must include the following files and set the
INHERIT
variable:
include conf/distro/include/distro_alias.inc
include conf/distro/include/recipe_color.inc
include conf/distro/include/maintainers.inc
include conf/distro/include/upstream_tracking.inc
include conf/distro/include/package_regex.inc
INHERIT+= "distrodata"
The distutils class supports recipes for Python
extensions, which are simple.
These recipes usually only need to point to the source's archive and
then inherit the proper class.
Building is split into two methods depending on which method the
module authors used.
Extensions that use an Autotools-based build system require Autotools and
distutils-based classes in their recipes.Extensions that use
distutils-based build systems require thedistutilsclass in their recipes.Extensions that use the setuptools-based build systems require the
setuptoolsclass in their recipes.
The externalsrc class supports building software
from source code that is external to the OpenEmbedded build system.
Building software from an external source tree means that the build
system's normal fetch, unpack, and patch process is not used.
By default, the OpenEmbedded build system uses the
S and
B variables to
locate unpacked recipe source code and to build it, respectively.
When your recipe inherits the externalsrc class,
you use the
EXTERNALSRC
and
EXTERNALSRC_BUILD
variables to ultimately define S and
B.
By default, this class expects the source code to support recipe builds
that use the B
variable to point to the directory in which the OpenEmbedded build
system places the generated objects built from the recipes.
By default, the B directory is set to the
following, which is separate from the source directory
(S):
${WORKDIR}/${BPN}/{PV}/
See these variables for more information:
WORKDIR,
BPN, and
PV,
For more information on the
externalsrc class, see the comments in
meta/classes/externalsrc.bbclass in the
Source Directory.
For information on how to use the externalsrc
class, see the
"Building Software from an External Source"
section in the Yocto Project Development Manual.
The extrausers class allows
additional user and group configuration to be applied at the image
level.
Inheriting this class either globally or from an image recipe allows
additional user and group operations to be performed using the
EXTRA_USERS_PARAMS
variable.
Note
The user and group operations added using theextrausers class are not tied to a specific
recipe outside of the recipe for the image.
Thus, the operations can be performed across the image as a whole.
Use the
useradd
class to add user and group configuration to a specific recipe.
Here is an example that uses this class in an image recipe:
inherit extrausers
EXTRA_USERS_PARAMS = "\
useradd -p '' tester; \
groupadd developers; \
userdel nobody; \
groupdel -g video; \
groupmod -g 1020 developers; \
usermod -s /bin/sh tester; \
"
The fontcache class generates the
proper post-install and post-remove (postinst and postrm)
scriptlets for font packages.
These scriptlets call fc-cache (part of
Fontconfig) to add the fonts to the font
information cache.
Since the cache files are architecture-specific,
fc-cache runs using QEMU if the postinst
scriptlets need to be run on the build host during image creation.
If the fonts being installed are in packages other than the main
package, set
FONT_PACKAGES
to specify the packages containing the fonts.
The gconf class provides common
functionality for recipes that need to install GConf schemas.
The schemas will be put into a separate package
(${PN}-gconf)
that is created automatically when this class is inherited.
This package uses the appropriate post-install and post-remove
(postinst/postrm) scriptlets to register and unregister the schemas
in the target image.
The gettext class provides support for
building software that uses the GNU gettext
internationalization and localization system.
All recipes building software that use
gettext should inherit this class.
The gnome class supports recipes that
build software from the GNOME stack.
This class inherits the
gnomebase,
gtk-icon-cache,
gconf and
mime classes.
The class also disables GObject introspection where applicable.
The gnomebase class is the base
class for recipes that build software from the GNOME stack.
This class sets
SRC_URI to
download the source from the GNOME mirrors as well as extending
FILES
with the typical GNOME installation paths.
The grub-efi
class provides grub-efi-specific functions for
building bootable images.
This class supports several variables:
INITRD: Indicates a filesystem image to use as an initrd (optional).ROOTFS: Indicates a filesystem image to include as the root filesystem (optional).GRUB_GFXSERIAL: Set this to "1" to have graphics and serial in the boot menu.LABELS: A list of targets for the automatic configuration.APPEND: An override list of append strings for eachLABEL.GRUB_OPTS: Additional options to add to the configuration (optional). Options are delimited using semi-colon characters (;).GRUB_TIMEOUT: Timeout before executing the defaultLABEL(optional).
The gsettings class
provides common functionality for recipes that need to install
GSettings (glib) schemas.
The schemas are assumed to be part of the main package.
Appropriate post-install and post-remove (postinst/postrm)
scriptlets are added to register and unregister the schemas in the
target image.
The gtk-doc class
is a helper class to pull in the appropriate
gtk-doc dependencies and disable
gtk-doc.
The gtk-icon-cache class
generates the proper post-install and post-remove (postinst/postrm)
scriptlets for packages that use GTK+ and install icons.
These scriptlets call gtk-update-icon-cache to add
the fonts to GTK+'s icon cache.
Since the cache files are architecture-specific,
gtk-update-icon-cache is run using QEMU if the
postinst scriptlets need to be run on the build host during image
creation.
The gtk-immodules-cache class
generates the proper post-install and post-remove (postinst/postrm)
scriptlets for packages that install GTK+ input method modules for
virtual keyboards.
These scriptlets call gtk-update-icon-cache to add
the input method modules to the cache.
Since the cache files are architecture-specific,
gtk-update-icon-cache is run using QEMU if the
postinst scriptlets need to be run on the build host during image
creation.
If the input method modules being installed are in packages other than
the main package, set
GTKIMMODULES_PACKAGES
to specify the packages containing the modules.
The gzipnative
class enables the use of native versions of gzip
and pigz rather than the versions of these tools
from the build host.
The icecc class supports
Icecream, which
facilitates taking compile jobs and distributing them among remote
machines.
The class stages directories with symlinks from gcc
and g++ to icecc, for both
native and cross compilers.
Depending on each configure or compile, the OpenEmbedded build system
adds the directories at the head of the PATH list
and then sets the ICECC_CXX and
ICEC_CC variables, which are the paths to the
g++ and gcc compilers,
respectively.
For the cross compiler, the class creates a tar.gz
file that contains the Yocto Project toolchain and sets
ICECC_VERSION, which is the version of the
cross-compiler used in the cross-development toolchain, accordingly.
The class handles all three different compile stages
(i.e native ,cross-kernel and target) and creates the necessary
environment tar.gz file to be used by the remote
machines.
The class also supports SDK generation.
If ICECC_PATH
is not set in your local.conf file, then the
class tries to locate the icecc binary
using which.
If
ICECC_ENV_EXEC
is set in your local.conf file, the variable should
point to the icecc-create-env script
provided by the user.
If you do not point to a user-provided script, the build system
uses the default script provided by the recipe
icecc-create-env-native.bb.
Note
This script is a modified version and not the one that comes withicecc.
If you do not want the Icecream distributed compile support to apply
to specific recipes or classes, you can effectively "blacklist" them
by listing the recipes and classes using the
ICECC_USER_PACKAGE_BL
and
ICECC_USER_CLASS_BL,
variables, respectively, in your local.conf file.
Doing so causes the OpenEmbedded build system to handle these
compilations locally.
Additionally, you can list recipes using the
ICECC_USER_PACKAGE_WL
variable in your local.conf file to force
icecc to be enabled for recipes using an empty
PARALLEL_MAKE
variable.
The image class helps support creating images
in different formats.
First, the root filesystem is created from packages using
one of the rootfs*.bbclass
files (depending on the package format used) and then one or more image
files are created.
The
IMAGE_FSTYPESvariable controls the types of images to generate.The
IMAGE_INSTALLvariable controls the list of packages to install into the image.
For information on customizing images, see the "Customizing Images" section in the Yocto Project Development Manual. For information on how images are created, see the "Images" section elsewhere in this manual.
The image_types class defines all of
the standard image output types that you can enable through the
IMAGE_FSTYPES
variable.
You can use this class as a reference on how to add support for custom
image output types.
By default, this class is enabled through the
IMAGE_CLASSES
variable in
image.bbclass.
If you define your own image types using a custom BitBake class and
then use IMAGE_CLASSES to enable it, the custom
class must either inherit image_types or
image_types must also appear in
IMAGE_CLASSES.
The image_types_uboot class
defines additional image types specifically for the U-Boot bootloader.
The image-live class supports building "live"
images.
Normally, you do not use this class directly.
Instead, you add "live" to
IMAGE_FSTYPES.
The image-mklibs class
enables the use of the mklibs utility during the
do_rootfs task, which optimizes the size of
libraries contained in the image.
By default, the class is enabled in the
local.conf.template using the
USER_CLASSES
variable as follows:
USER_CLASSES ?= "buildstats image-mklibs image-prelink"
The image-prelink class
enables the use of the prelink utility during
the do_rootfs task, which optimizes the dynamic
linking of shared libraries to reduce executable startup time.
By default, the class is enabled in the
local.conf.template using the
USER_CLASSES
variable as follows:
USER_CLASSES ?= "buildstats image-mklibs image-prelink"
The image-swab class enables the
Swabber
tool in order to detect and log accesses to the host system during
the OpenEmbedded build process.
Note
This class is currently unmaintained.
The image-vmdk class supports building VMware
VMDK images.
Normally, you do not use this class directly.
Instead, you add "vmdk" to
IMAGE_FSTYPES.
The insane class adds a step to the package
generation process so that output quality assurance checks are
generated by the OpenEmbedded build system.
A range of checks are performed that check the build's output
for common problems that show up during runtime.
Distribution policy usually dictates whether to include this class.
You can configure the sanity checks so that specific test failures either raise a warning or an error message. Typically, failures for new tests generate a warning. Subsequent failures for the same test would then generate an error message once the metadata is in a known and good condition.
Use the
WARN_QA and
ERROR_QA
variables to control the behavior of
these checks at the global level (i.e. in your custom distro
configuration).
However, to skip one or more checks in recipes, you should use
INSANE_SKIP.
For example, to skip the check for symbolic link
.so files in the main package of a recipe,
add the following to the recipe.
You need to realize that the package name override, in this example
${PN}, must be used:
INSANE_SKIP_${PN} += "dev-so"
Please keep in mind that the QA checks exist in order to detect real or potential problems in the packaged output. So exercise caution when disabling these checks.
The following list shows the tests you can list with the
WARN_QA and ERROR_QA
variables:
ldflags:Ensures that the binaries were linked with theLDFLAGSoptions provided by the build system. If this test fails, check that theLDFLAGSvariable is being passed to the linker command.useless-rpaths:Checks for dynamic library load paths (rpaths) in the binaries that by default on a standard system are searched by the linker (e.g./liband/usr/lib). While these paths will not cause any breakage, they do waste space and are unnecessary.rpaths:Checks for rpaths in the binaries that contain build system paths such asTMPDIR. If this test fails, bad-rpathoptions are being passed to the linker commands and your binaries have potential security issues.dev-so:Checks that the.sosymbolic links are in the-devpackage and not in any of the other packages. In general, these symlinks are only useful for development purposes. Thus, the-devpackage is the correct location for them. Some very rare cases do exist for dynamically loaded modules where these symlinks are needed instead in the main package.debug-files:Checks for.debugdirectories in anything but the-dbgpackage. The debug files should all be in the-dbgpackage. Thus, anything packaged elsewhere is incorrect packaging.arch:Checks the Executable and Linkable Format (ELF) type, bit size, and endianness of any binaries to ensure they match the target architecture. This test fails if any binaries don't match the type since there would be an incompatibility. Sometimes software, like bootloaders, might need to bypass this check.debug-deps:Checks that-dbgpackages only depend on other-dbgpackages and not on any other types of packages, which would cause a packaging bug.dev-deps:Checks that-devpackages only depend on other-devpackages and not on any other types of packages, which would be a packaging bug.pkgconfig:Checks.pcfiles for anyTMPDIR/WORKDIRpaths. Any.pcfile containing these paths is incorrect sincepkg-configitself adds the correct sysroot prefix when the files are accessed.textrel:Checks for ELF binaries that contain relocations in their.textsections, which can result in a performance impact at runtime.pkgvarcheck:Checks through the variablesRDEPENDS,RRECOMMENDS,RSUGGESTS,RCONFLICTS,RPROVIDES,RREPLACES,FILES,ALLOW_EMPTY,pkg_preinst,pkg_postinst,pkg_prermandpkg_postrm, and reports if there are variable sets that are not package-specific. Using these variables without a package suffix is bad practice, and might unnecessarily complicate dependencies of other packages within the same recipe or have other unintended consequences.xorg-driver-abi:Checks that all packages containing Xorg drivers have ABI dependencies. Thexserver-xorgrecipe provides driver ABI names. All drivers should depend on the ABI versions that they have been built against. Driver recipes that includexorg-driver-input.incorxorg-driver-video.incwill automatically get these versions. Consequently, you should only need to explicitly add dependencies to binary driver recipes.libexec:Checks if a package contains files in/usr/libexec. This check is not performed if thelibexecdirvariable has been set explicitly to/usr/libexec.staticdev:Checks for static library files (*.a) in non-staticdevpackages.la:Checks.lafiles for anyTMPDIRpaths. Any.lafile containing these paths is incorrect sincelibtooladds the correct sysroot prefix when using the files automatically itself.desktop:Runs thedesktop-file-validateprogram against any.desktopfiles to validate their contents against the specification for.desktopfiles.already-stripped:Checks that produced binaries have not already been stripped prior to the build system extracting debug symbols. It is common for upstream software projects to default to stripping debug symbols for output binaries. In order for debugging to work on the target using-dbgpackages, this stripping must be disabled.split-strip:Reports that splitting or stripping debug symbols from binaries has failed.arch:Checks to ensure the architecture, bit size, and endianness of all output binaries matches that of the target. This test can detect when the wrong compiler or compiler options have been used.installed-vs-shipped:Reports when files have been installed withindo_installbut have not been included in any package by way of theFILESvariable. Files that do not appear in any package cannot be present in an image later on in the build process. Ideally, all installed files should be packaged or not installed at all. These files can be deleted at the end ofdo_installif the files are not needed in any package.dep-cmp:Checks for invalid version comparison statements in runtime dependency relationships between packages (i.e. inRDEPENDS,RRECOMMENDS,RSUGGESTS,RPROVIDES,RREPLACES, andRCONFLICTSvariable values). Any invalid comparisons might trigger failures or undesirable behavior when passed to the package manager.files-invalid:Checks forFILESvariable values that contain "//", which is invalid.incompatible-license:Report when packages are excluded from being created due to being marked with a license that is inINCOMPATIBLE_LICENSE.compile-host-path:Checks thedo_compilelog for indications that paths to locations on the build host were used. Using such paths might result in host contamination of the build output.install-host-path:Checks thedo_installlog for indications that paths to locations on the build host were used. Using such paths might result in host contamination of the build output.libdir:Checks for libraries being installed into incorrect (possibly hardcoded) installation paths. For example, this test will catch recipes that install/lib/bar.sowhen${base_libdir}is "lib32". Another example is when recipes install/usr/lib64/foo.sowhen${libdir}is "/usr/lib".packages-list:Checks for the same package being listed multiple times through thePACKAGESvariable value. Installing the package in this manner can cause errors during packaging.perm-config:Reports lines infs-perms.txtthat have an invalid format.perm-line:Reports lines infs-perms.txtthat have an invalid format.perm-link:Reports lines infs-perms.txtthat specify 'link' where the specified target already exists.pkgname:Checks that all packages inPACKAGEShave names that do not contain invalid characters (i.e. characters other than 0-9, a-z, ., +, and -).pn-overrides:Checks that a recipe does not have a name (PN) value that appears inOVERRIDES. If a recipe is named such that itsPNvalue matches something already inOVERRIDES(e.g.PNhappens to be the same asMACHINEorDISTRO), it can have unexpected consequences. For example, assignments such asFILES_${PN} = "xyz"effectively turn intoFILES = "xyz".unsafe-references-in-binaries:Reports when a binary installed in${base_libdir},${base_bindir}, or${base_sbindir}, depends on another binary installed under${exec_prefix}. This dependency is a concern if you want the system to remain basically operable if/usris mounted separately and is not mounted.Note
Defaults for binaries installed in${base_libdir},${base_bindir}, and${base_sbindir}are/lib,/bin, and/sbin, respectively. The default for a binary installed under${exec_prefix}is/usr.unsafe-references-in-scripts:Reports when a script file installed in${base_libdir},${base_bindir}, or${base_sbindir}, depends on files installed under${exec_prefix}. This dependency is a concern if you want the system to remain basically operable if/usris mounted separately and is not mounted.Note
Defaults for binaries installed in${base_libdir},${base_bindir}, and${base_sbindir}are/lib,/bin, and/sbin, respectively. The default for a binary installed under${exec_prefix}is/usr.var-undefined:Reports when variables fundamental to packaging (i.e.WORKDIR,DEPLOY_DIR,D,PN, andPKGD) are undefined duringdo_package.pkgv-undefined:Checks to see if thePKGVvariable is undefined duringdo_package.buildpaths:Checks for paths to locations on the build host inside the output files. Currently, this test triggers too many false positives and thus is not normally enabled.perms:Currently, this check is unused but reserved.version-going-backwards:If Build History is enabled, reports when a package being written out has a lower version than the previously written package under the same name. If you are placing output packages into a feed and upgrading packages on a target system using that feed, the version of a package going backwards can result in the target system not correctly upgrading to the "new" version of the package.Note
If you are not using runtime package management on your target system, then you do not need to worry about this situation.
The insserv class
uses the insserv utility to update the order of
symbolic links in /etc/rc?.d/ within an image
based on dependencies specified by LSB headers in the
init.d scripts themselves.
The kernel class handles building Linux kernels.
The class contains code to build all kernel trees.
All needed headers are staged into the
STAGING_KERNEL_DIR
directory to allow out-of-tree module builds using
the
module
class.
This means that each built kernel module is packaged separately and inter-module
dependencies are created by parsing the modinfo output.
If all modules are required, then installing the kernel-modules
package installs all packages with modules and various other kernel packages
such as kernel-vmlinux.
Various other classes are used by the kernel
and module classes internally including the
kernel-arch,
module-base,
and
linux-kernel-base
classes.
The kernel-arch class
sets the ARCH environment variable for Linux
kernel compilation (including modules).
The kernel-module-split class
provides common functionality for splitting Linux kernel modules into
separate packages.
The kernel-yocto class
provides common functionality for building from linux-yocto style
kernel source repositories.
The lib_package class
supports recipes that build libraries and produce executable
binaries, where those binaries should not be installed by default
along with the library.
Instead, the binaries are added to a separate
${PN}-bin
package to make their installation optional.
The license class provides license
manifest creation and license exclusion.
This class is enabled by default using the default value for the
INHERIT_DISTRO
variable.
The linux-kernel-base class
provides common functionality for recipes that build out of the Linux
kernel source tree.
These builds goes beyond the kernel itself.
For example, the Perf recipe also inherits this class.
The logging class provides the standard
shell functions used to log messages for various BitBake severity levels
(i.e. bbplain, bbnote,
bbwarn, bberror,
bbfatal, and bbdebug).
This class is enabled by default since it is inherited by
the base class.
The meta class is inherited by recipes
that do not build any output packages themselves, but act as a "meta"
target for building other recipes.
The metadata_scm class provides functionality for
querying the branch and revision of a Source Code Manager (SCM)
repository.
The base
class uses this class to print the revisions of each layer before
starting every build.
The metadata_scm class is enabled by default
because it is inherited by the base class.
The mime class generates the proper
post-install and post-remove (postinst/postrm) scriptlets for packages
that install MIME type files.
These scriptlets call update-mime-database to add
the MIME types to the shared database.
The mirrors class sets up some standard
MIRRORS entries
for source code mirrors.
These mirrors provide a fall-back path in case the upstream source
specified in
SRC_URI
within recipes is unavailable.
This class is enabled by default since it is inherited by the
base class.
The module class provides support for building
out-of-tree Linux kernel modules.
The class inherits the
module-base
and
kernel-module-split
classes, and implements do_compile and
do_install functions.
The class provides everything needed to build and package a kernel
module.
For general information on out-of-tree Linux kernel modules, see the "Incorporating Out-of-Tree Modules" section in the Yocto Project Linux Kernel Development Manual.
The module-base class provides the base
functionality for building Linux kernel modules.
Typically, a recipe that builds software that includes one or
more kernel modules and has its own means of building
the module inherits this class as opposed to inheriting the
module
class.
The multilib* classes provide support
for building libraries with different target optimizations or target
architectures and installing them side-by-side in the same image.
For more information on using the Multilib feature, see the "Combining Multiple Versions of Library Files into One Image" section in the Yocto Project Development Manual.
The native class provides common
functionality for recipes that wish to build tools to run on the build
host (i.e. tools that use the compiler or other tools from the
build host).
You can create a recipe that builds tools that run natively on the host a couple different ways:
Create a
myrecipe-native.bbthat inherits thenativeclass.Create or modify a target recipe that has adds the following:
BBCLASSEXTEND= "native"Inside the recipe, use
_class-nativeand_class-targetoverrides to specify any functionality specific to the respective native or target case.
Although applied differently, the native class is
used with both methods.
The advantage of the second method is that you do not need to have two
separate recipes (assuming you need both) for native and target.
All common parts of the recipe are automatically shared.
The nativesdk class provides common
functionality for recipes that wish to build tools to run as part of
an SDK (i.e. tools that run on
SDKMACHINE).
You can create a recipe that builds tools that run on the SDK machine a couple different ways:
Create a
myrecipe-nativesdk.bbrecipe that inherits thenativesdkclass.Create a
nativesdkvariant of any recipe by adding the following:BBCLASSEXTEND= "nativesdk"Inside the recipe, use
_class-nativesdkand_class-targetoverrides to specify any functionality specific to the respective SDK machine or target case.
Although applied differently, the nativesdk class
is used with both methods.
The advantage of the second method is that you do not need to have two
separate recipes (assuming you need both) for the SDK machine and the
target.
All common parts of the recipe are automatically shared.
The oelint class is an
obsolete lint checking tool that exists in
meta/classes in the
Source Directory.
A number of classes exist that are could be generally useful in
OE-Core but are never actually used within OE-Core itself.
The oelint class is one such example.
However, being aware of this class can reduce the proliferation of
different versions of similar classes across multiple layers.
The own-mirrors class makes it
easier to set up your own
PREMIRRORS
from which to first fetch source before attempting to fetch it from the
upstream specified in
SRC_URI
within each recipe.
To use this class, inherit it globally and specify
SOURCE_MIRROR_URL.
Here is an example:
INHERIT += "own-mirrors"
SOURCE_MIRROR_URL = "http://example.com/my-source-mirror"
You can specify only a single URL in
SOURCE_MIRROR_URL.
The package class supports generating
packages from a build's output.
The core generic functionality is in
package.bbclass.
The code specific to particular package types resides in these
package-specific classes:
package_deb,
package_rpm,
package_ipk,
and
package_tar.
You can control the list of resulting package formats by using the
PACKAGE_CLASSES
variable defined in your conf/local.conf
configuration file, which is located in the
Build Directory.
When defining the variable, you can specify one or more package types.
Since images are generated from packages, a packaging class is
needed to enable image generation.
The first class listed in this variable is used for image generation.
If you take the optional step to set up a repository (package feed) on the development host that can be used by Smart, you can install packages from the feed while you are running the image on the target (i.e. runtime installation of packages). For more information, see the "Using Runtime Package Management" section in the Yocto Project Development Manual.
The package-specific class you choose can affect build-time performance
and has space ramifications.
In general, building a package with IPK takes about thirty percent less
time as compared to using RPM to build the same or similar package.
This comparison takes into account a complete build of the package with
all dependencies previously built.
The reason for this discrepancy is because the RPM package manager
creates and processes more
Metadata than the
IPK package manager.
Consequently, you might consider setting
PACKAGE_CLASSES to "package_ipk" if you are
building smaller systems.
Before making your package manager decision, however, you should consider some further things about using RPM:
RPM starts to provide more abilities than IPK due to the fact that it processes more Metadata. For example, this information includes individual file types, file checksum generation and evaluation on install, sparse file support, conflict detection and resolution for Multilib systems, ACID style upgrade, and repackaging abilities for rollbacks.
For smaller systems, the extra space used for the Berkeley Database and the amount of metadata when using RPM can affect your ability to perform on-device upgrades.
You can find additional information on the effects of the package class at these two Yocto Project mailing list links:
The package_deb class
provides support for creating packages that use the
.deb file format.
The class ensures the packages are written out to the
${DEPLOY_DIR}/deb
directory in a .deb file format.
This class inherits the
package
class and is enabled through the
PACKAGE_CLASSES
variable in the local.conf file.
The package_ipk class
provides support for creating packages that use the
.ipk file format.
The class ensures the packages are written out to the
${DEPLOY_DIR}/ipk
directory in a .ipk file format.
This class inherits the
package
class and is enabled through the
PACKAGE_CLASSES
variable in the local.conf file.
The package_deb class
provides support for creating packages that use the
.rpm file format.
The class ensures the packages are written out to the
${DEPLOY_DIR}/rpm
directory in a .rpm file format.
This class inherits the
package
class and is enabled through the
PACKAGE_CLASSES
variable in the local.conf file.
The package_tar
class provides support for creating packages that use the
.tar file format.
The class ensures the packages are written out to the
${DEPLOY_DIR}/tar
directory in a .tar file format.
This class inherits the
package
class and is enabled through the
PACKAGE_CLASSES
variable in the local.conf file.
Note
You cannot specify thepackage_tar class
first using the PACKAGE_CLASSES variable.
You must use .deb,
.ipk, or .rpm file
formats for your image or SDK.
The packagedata class provides
common functionality for reading pkgdata files
found in
PKGDATA_DIR.
These files contain information about each output package produced by
the OpenEmbedded build system.
This class is enabled by default because it is inherited by the
package
class.
The packagegroup class sets default values
appropriate for package group recipes (e.g.
PACKAGES,
PACKAGE_ARCH,
ALLOW_EMPTY,
and so forth).
It is highly recommended that all package group recipes inherit this class.
For information on how to use this class, see the "Customizing Images Using Custom Package Groups" section in the Yocto Project Development Manual.
Previously, this class was called the task class.
The packageinfo class
gives a BitBake user interface the ability to retrieve information
about output packages from the pkgdata files.
This class is enabled automatically when using the Hob user interface.
The patch class provides all functionality for
applying patches during the do_patch task.
This class is enabled by default because it is inherited by the
base
class.
When inherited by a recipe, the perlnative class
supports using the native version of Perl built by the build system
rather than using the version provided by the build host.
The pixbufcache class generates the proper
post-install and post-remove (postinst/postrm) scriptlets for packages
that install pixbuf loaders, which are used with
gdk-pixbuf.
These scriptlets call update_pixbuf_cache
to add the pixbuf loaders to the cache.
Since the cache files are architecture-specific,
update_pixbuf_cache is run using QEMU if the
postinst scriptlets need to be run on the build host during image
creation.
If the pixbuf loaders being installed are in packages other
than the recipe's main package, set
PIXBUF_PACKAGES
to specify the packages containing the loaders.
The pkg-config class provides a standard way to get
header and library information.
This class aims to smooth integration of
pkg-config into libraries that use it.
During staging, BitBake installs pkg-config data into the
sysroots/ directory.
By making use of sysroot functionality within pkg-config,
this class no longer has to manipulate the files.
The populate_sdk_* classes support SDK creation
and consist of the following classes:
populate_sdk_base: The base class supporting SDK creation under all package managers (i.e. DEB, RPM, and IPK).populate_sdk_deb: Supports creation of the SDK given the Debian package manager.populate_sdk_rpm: Supports creation of the SDK given the RPM package manager.populate_sdk_ipk: Supports creation of the SDK given the IPK package manager.
The populate_sdk_base package inherits the
appropriate populate_sdk_* (i.e.
deb, rpm, and
ipk) based on
IMAGE_PKGTYPE.
The base class ensures all source and destination directories are
established and then populates the SDK.
After populating the SDK, the populate_sdk_base
class constructs two images:
SDK_ARCH-nativesdk,
which contains the cross-compiler and associated tooling, and the
target, which contains a target root filesystem that is configured for
the SDK usage.
These two images reside in
SDK_OUTPUT,
which consists of the following:
${SDK_OUTPUT}/<sdk_arch-nativesdk pkgs>
${SDK_OUTPUT}/${SDKTARGETSYSROOT}/<target pkgs>
Finally, the base populate SDK class creates the toolchain environment setup script, the tarball of the SDK, and the installer.
The respective populate_sdk_deb,
populate_sdk_rpm, and
populate_sdk_ipk classes each support the
specific type of SDK.
These classes are inherited by and used with the
populate_sdk_base class.
The prexport class provides functionality for
exporting
PR values.
Note
This class is not intended to be used directly. Rather, it is enabled when using "bitbake-prserv-tool export".
The primport class provides functionality for
importing
PR values.
Note
This class is not intended to be used directly. Rather, it is enabled when using "bitbake-prserv-tool import".
The prserv class provides functionality for
using a
PR service
in order to automatically manage the incrementing of the
PR variable for
each recipe.
This class is enabled by default because it is inherited by the
package
class.
However, the OpenEmbedded build system will not enable the
functionality of this class unless
PRSERV_HOST
has been set.
The ptest class provides functionality for
packaging and installing runtime tests for recipes that build software
that provides these tests.
This class is intended to be inherited by individual recipes.
However, the class' functionality is largely disabled unless "ptest"
appears in
DISTRO_FEATURES.
See the
"Testing Packages With ptest"
section in the Yocto Project Development Manual for more information
on ptest.
The python-dir class provides the base version,
location, and site package location for Python.
When inherited by a recipe, the pythonnative class
supports using the native version of Python built by the build system
rather than using the version provided by the build host.
The qemu class provides functionality for recipes
that either need QEMU or test for the existence of QEMU.
Typically, this class is used to run programs for a target system on
the build host using QEMU's application emulation mode.
The qmake* classes support recipes that
need to build software that uses Qt's qmake
build system and are comprised of the following:
qmake_base: Provides base functionality for all versions ofqmake.qmake2: Extends base functionality forqmake2.x as used by Qt 4.x.
If you need to set any configuration variables or pass any options to
qmake, you can add these to the
EXTRA_QMAKEVARS_PRE
or
EXTRA_QMAKEVARS_POST
variables, depending on whether the arguments need to be before or
after the .pro file list on the command line,
respectively.
By default, all .pro files are built.
If you want to specify your own subset of .pro
files to be built, specify them in the
QMAKE_PROFILES
variable.
The qt4* classes support recipes that need to
build software that uses the Qt development framework version 4.x
and consist of the following:
qt4e: Supports building against Qt/Embedded, which uses the framebuffer for graphical output.qt4x11: Supports building against Qt/X11.
The classes inherit the
qmake2
class.
The relocatable class enables relocation of
binaries when they are installed into the sysroot.
This class makes use of the
chrpath
class and is used by both the
cross
and
native
classes.
The rm_work class supports deletion of temporary
workspace, which can ease your hard drive demands during builds.
The OpenEmbedded build system can use a substantial amount of disk
space during the build process.
A portion of this space is the work files under the
${TMPDIR}/work directory for each recipe.
Once the build system generates the packages for a recipe, the work
files for that recipe are no longer needed.
However, by default, the build system preserves these files
for inspection and possible debugging purposes.
If you would rather have these files deleted to save disk space
as the build progresses, you can enable rm_work
by adding the following to your local.conf file,
which is found in the
Build Directory.
INHERIT += "rm_work"
If you are modifying and building source code out of the work directory
for a recipe, enabling rm_work will potentially
result in your changes to the source being lost.
To exclude some recipes from having their work directories deleted by
rm_work, you can add the names of the recipe or
recipes you are working on to the RM_WORK_EXCLUDE
variable, which can also be set in your local.conf
file.
Here is an example:
RM_WORK_EXCLUDE += "busybox eglibc"
The rootfs* classes support creating
the root filesystem for an image and consist of the following classes:
The
rootfs_debclass, which supports creation of root filesystems for images built using.debpackages.The
rootfs_rpmclass, which supports creation of root filesystems for images built using.rpmpackages.The
rootfs_ipkclass, which supports creation of root filesystems for images built using.ipkpackages.
The root filesystem is created from packages using one of the
rootfs*.bbclass files as determined by the
PACKAGE_CLASSES
variable.
For information on how root filesystem images are created, see the "Image Generation" section.
The sanity class checks to see if prerequisite
software is present on the host system so that users can be notified
of potential problems that might affect their build.
The class also performs basic user configuration checks from
the local.conf configuration file to
prevent common mistakes that cause build failures.
Distribution policy usually determines whether to include this class.
The scons class supports recipes that need to
build software that uses the SCons build system.
You can use the
EXTRA_OESCONS
variable to specify additional configuration options you want to pass
SCons command line.
The sdl class supports recipes that need to build
software that uses the Simple DirectMedia Layer (SDL) library.
The setuptools class supports Python extensions
that use setuptools-based build systems.
If your recipe uses these build systems, the recipe needs to
inherit the setuptools class.
The siteconfig class
provides functionality for handling site configuration.
The class is used by the
autotools
class to accelerate the do_configure task.
The siteinfo class provides information about
the targets that might be needed by other classes or recipes.
As an example, consider Autotools, which can require tests that must
execute on the target hardware.
Since this is not possible in general when cross compiling, site
information is used to provide cached test results so these tests can
be skipped over but still make the correct values available.
The
meta/site directory
contains test results sorted into different categories such as
architecture, endianness, and the libc used.
Site information provides a list of files containing data relevant to
the current build in the
CONFIG_SITE variable
that Autotools automatically picks up.
The class also provides variables like
SITEINFO_ENDIANNESS
and SITEINFO_BITS
that can be used elsewhere in the metadata.
Because the
base class
includes the siteinfo class, it is always active.
The spdx class integrates real-time license
scanning, generation of SPDX standard output, and verification
of license information during the build.
Note
This class is currently at the prototype stage in the 1.5 release.
The sstate class provides support for Shared
State (sstate).
By default, the class is enabled through the
INHERIT_DISTRO
variable's default value.
For more information on sstate, see the "Shared State Cache" section.
The staging class provides support for staging
files into the sysroot during the
do_populate_sysroot task.
The class is enabled by default because it is inherited by the
base
class.
The syslinux class provides syslinux-specific
functions for building bootable images.
The class supports the following variables:
INITRD: Indicates a filesystem image to use as an initial RAM disk (initrd). This variable is optional.ROOTFS: Indicates a filesystem image to include as the root filesystem. This variable is optional.AUTO_SYSLINUXMENU: Enables creating an automatic menu when set to "1".LABELS: Lists targets for automatic configuration.APPEND: Lists append string overrides for each label.SYSLINUX_OPTS: Lists additional options to add to the syslinux file. Semicolon characters separate multiple options.SYSLINUX_SPLASH: Lists a background for the VGA boot menu when you are using the boot menu.SYSLINUX_DEFAULT_CONSOLE: Set to "console=ttyX" to change kernel boot default console.SYSLINUX_SERIAL: Sets an alternate serial port. Or, turns off serial when the variable is set with an empty string.SYSLINUX_SERIAL_TTY: Sets an alternate "console=tty..." kernel boot argument.
The systemd class provides support for recipes
that install systemd unit files.
The functionality for this class is disabled unless you have "systemd"
in
DISTRO_FEATURES.
Under this class, the recipe or Makefile (i.e. whatever the recipe is
calling during the do_install task) installs unit
files into
${D}${systemd_unitdir}/system.
If the unit files being installed go into packages other than the
main package, you need to set
SYSTEMD_PACKAGES
in your recipe to identify the packages in which the files will be
installed.
You should set
SYSTEMD_SERVICE
to the name of the service file.
You should also use a package name override to indicate the package
to which the value applies.
If the value applies to the recipe's main package, use
${PN}.
Here is an example from the connman recipe:
SYSTEMD_SERVICE_${PN} = "connman.service"
Services are set up to start on boot automatically unless
you have set
SYSTEMD_AUTO_ENABLE
to "disable".
For more information on systemd, see the
"Selecting an Initialization Manager"
section in the Yocto Project Development Manual.
The terminal class provides support for starting
a terminal session.
The
OE_TERMINAL
variable controls which terminal emulator is used for the session.
Other classes use the terminal class anywhere a
separate terminal session needs to be started.
For example, the
patch
class assuming
PATCHRESOLVE
is set to "user", the
cml1
class, and the
devshell
class all use the terminal class.
The testimage class supports running automated
tests against images.
The class handles loading the tests and starting the image.
Note
Currently, there is only support for running these tests under QEMU.
To use the class, you need to perform steps to set up the
environment.
The tests are commands that run on the target system over
ssh.
they are written in Python and make use of the
unittest module.
For information on how to enable, run, and create new tests, see the "Performing Automated Runtime Testing" section.
The tinderclient class submits build results to
an external Tinderbox instance.
Note
This class is currently unmaintained.
The toaster class collects information about
packages and images and sends them as events that the BitBake
user interface can receive.
The class is enabled when the Toaster user interface is running.
This class is not intended to be used directly.
The toolchain-scripts class provides the scripts
used for setting up the environment for installed SDKs.
The typecheck class provides support for
validating the values of variables set at the configuration level
against their defined types.
The OpenEmbedded build system allows you to define the type of a
variable using the "type" varflag.
Here is an example:
IMAGE_FEATURES[type] = "list"
The uboot-config class provides support for
U-Boot configuration for a machine.
Specify the machine in your recipe as follows:
UBOOT_CONFIG ??= <default>
UBOOT_CONFIG[foo] = "config,images"
You can also specify the machine using this method:
UBOOT_MACHINE = "config"
See the
UBOOT_CONFIG
and
UBOOT_MACHINE
variables for additional information.
The update-alternatives class helps the
alternatives system when multiple sources provide the same command.
This situation occurs when several programs that have the same or
similar function are installed with the same name.
For example, the ar command is available from the
busybox, binutils and
elfutils packages.
The update-alternatives class handles
renaming the binaries so that multiple packages can be installed
without conflicts.
The ar command still works regardless of which
packages are installed or subsequently removed.
The class renames the conflicting binary in each package and symlinks
the highest priority binary during installation or removal of packages.
To use this class, you need to define a number of variables:
These variables list alternative commands needed by a package,
provide pathnames for links, default links for targets, and
so forth.
For details on how to use this class, see the comments in the
update-alternatives.bbclass.
Note
You can use theupdate-alternatives command
directly in your recipes.
However, this class simplifies things in most cases.
The update-rc.d class uses
update-rc.d to safely install an
initialization script on behalf of the package.
The OpenEmbedded build system takes care of details such as making
sure the script is stopped before a package is removed and started when
the package is installed.
Three variables control this class:
INITSCRIPT_PACKAGES,
INITSCRIPT_NAME and
INITSCRIPT_PARAMS.
See the variable links for details.
The useradd class supports the addition of users
or groups for usage by the package on the target.
For example, if you have packages that contain system services that
should be run under their own user or group, you can use this class to
enable creation of the user or group.
The meta-skeleton/recipes-skeleton/useradd/useradd-example.bb
recipe in the Source Directory
provides a simple example that shows how to add three
users and groups to two packages.
See the useradd-example.bb recipe for more
information on how to use this class.
The useradd class supports the
USERADD_PACKAGES,
USERADD_PARAM,
GROUPADD_PARAM,
and
GROUPMEMS_PARAM
variables.
The utility-tasks class provides support for
various "utility" type tasks that are applicable to all recipes,
such as do_clean and
do_listtasks.
This class is enabled by default because it is inherited by
the
base
class.
The utils class provides some useful Python
functions that are typically used in inline Python expressions
(e.g. ${@...}).
One example use is for base_contains().
This class is enabled by default because it is inherited by the
base
class.
The vala class supports recipes that need to
build software written using the Vala programming language.
The waf class supports recipes that need to build
software that uses the Waf build system.
You can use the
EXTRA_OECONF
variable to specify additional configuration options to be passed on
the Waf command line.
The OpenEmbedded build system provides several example
images to satisfy different needs.
When you issue the bitbake command you provide a “top-level” recipe
that essentially begins the build for the type of image you want.
Note
Building an image without GNU General Public License Version 3 (GPLv3) components is only supported for minimal and base images. Furthermore, if you are going to build an image using non-GPLv3 components, you must make the following changes in thelocal.conf file
before using the BitBake command to build the minimal or base image:
1. Comment out the EXTRA_IMAGE_FEATURES line
2. Set INCOMPATIBLE_LICENSE = "GPLv3"
From within the poky Git repository, use the following command to list
the supported images:
$ ls meta*/recipes*/images/*.bb
These recipes reside in the meta/recipes-core/images,
meta/recipes-extended/images,
meta/recipes-graphics/images,
meta/recipes-qt/images,
meta/recipes-rt/images,
meta/recipes-sato/images, and
meta-skeleton/recipes-multilib/images directories
within the Source Directory.
Although the recipe names are somewhat explanatory, here is a list that describes them:
build-appliance-image: An example virtual machine that contains all the pieces required to run builds using the build system as well as the build system itself. You can boot and run the image using either the VMware Player or VMware Workstation. For more information on this image, see the Build Appliance page on the Yocto Project website.core-image-base: A console-only image that fully supports the target device hardware.core-image-minimal: A small image just capable of allowing a device to boot.core-image-minimal-dev: Acore-image-minimalimage suitable for development work using the host. The image includes headers and libraries you can use in a host development environment.core-image-minimal-initramfs: Acore-image-minimalimage that has the Minimal RAM-based Initial Root Filesystem (initramfs) as part of the kernel, which allows the system to find the first “init” program more efficiently.core-image-minimal-mtdutils: Acore-image-minimalimage that has support for the Minimal MTD Utilities, which let the user interact with the MTD subsystem in the kernel to perform operations on flash devices.core-image-basic: A console-only image with more full-featured Linux system functionality installed.core-image-lsb: An image that conforms to the Linux Standard Base (LSB) specification.core-image-lsb-dev: Acore-image-lsbimage that is suitable for development work using the host. The image includes headers and libraries you can use in a host development environment.core-image-lsb-sdk: Acore-image-lsbthat includes everything in meta-toolchain but also includes development headers and libraries to form a complete standalone SDK. This image is suitable for development using the target.core-image-clutter: An image with support for the Open GL-based toolkit Clutter, which enables development of rich and animated graphical user interfaces.core-image-directfb: An image that usesdirectfbinstead of X11.core-image-x11: A very basic X11 image with a terminal.core-image-weston: An image that provides the Wayland protocol libraries and the reference Weston compositor. For more information, see the "Wayland" section.qt4e-demo-image: An image that launches into the demo application for the embedded (not based on X11) version of Qt.core-image-rt: Acore-image-minimalimage plus a real-time test suite and tools appropriate for real-time use.core-image-rt-sdk: Acore-image-rtimage that includes everything inmeta-toolchain. The image also includes development headers and libraries to form a complete stand-alone SDK and is suitable for development using the target.core-image-sato: An image with Sato support, a mobile environment and visual style that works well with mobile devices. The image supports X11 with a Sato theme and applications such as a terminal, editor, file manager, media player, and so forth.core-image-sato-dev: Acore-image-satoimage suitable for development using the host. The image includes libraries needed to build applications on the device itself, testing and profiling tools, and debug symbols. This image was formerlycore-image-sdk.core-image-sato-sdk: Acore-image-satoimage that includes everything in meta-toolchain. The image also includes development headers and libraries to form a complete standalone SDK and is suitable for development using the target.core-image-multilib-example: An example image that includes alib32version of Bash into an otherwise standardsatoimage. The image assumes a "lib32" multilib has been enabled in the your configuration.
Tip
From the Yocto Project release 1.1 onwards,-live and
-directdisk images have been replaced by a "live"
option in IMAGE_FSTYPES that will work with any image to produce an
image file that can be
copied directly to a CD or USB device and run as is.
To build a live image, simply add
"live" to IMAGE_FSTYPES within the local.conf
file or wherever appropriate and then build the desired image as normal.
This chapter provides a reference of shipped machine and distro features you can include as part of the image, a reference on image types you can build, and a reference on feature backfilling.
Features provide a mechanism for working out which packages
should be included in the generated images.
Distributions can select which features they want to support through the
DISTRO_FEATURES
variable, which is set in the poky.conf distribution configuration file.
Machine features are set in the
MACHINE_FEATURES
variable, which is set in the machine configuration file and
specifies the hardware features for a given machine.
These two variables combine to work out which kernel modules, utilities, and other packages to include. A given distribution can support a selected subset of features so some machine features might not be included if the distribution itself does not support them.
One method you can use to determine which recipes are checking to see if a
particular feature is contained or not is to grep through
the Metadata
for the feature.
Here is an example that discovers the recipes whose build is potentially
changed based on a given feature:
$ cd poky
$ git grep 'contains.*MACHINE_FEATURES.*<feature>'
The items below are features you can use with
DISTRO_FEATURES
to enable features across your distribution.
Features do not have a one-to-one correspondence to packages,
and they can go beyond simply controlling the installation of a
package or packages.
In most cases, the presence or absence of a feature translates to
the appropriate option supplied to the configure script during
do_configure for the recipes that optionally
support the feature.
Some distro features are also machine features.
These select features make sense to be controlled both at
the machine and distribution configuration level.
See the
COMBINED_FEATURES
variable for more information.
This list only represents features as shipped with the Yocto Project metadata:
alsa: Include ALSA support (OSS compatibility kernel modules installed if available).
bluetooth: Include bluetooth support (integrated BT only).
cramfs: Include CramFS support.
directfb: Include DirectFB support.
ext2: Include tools for supporting for devices with internal HDD/Microdrive for storing files (instead of Flash only devices).
ipsec: Include IPSec support.
ipv6: Include IPv6 support.
irda: Include IrDA support.
keyboard: Include keyboard support (e.g. keymaps will be loaded during boot).
nfs: Include NFS client support (for mounting NFS exports on device).
opengl: Include the Open Graphics Library, which is a cross-language, multi-platform application programming interface used for rendering two and three-dimensional graphics.
pci: Include PCI bus support.
pcmcia: Include PCMCIA/CompactFlash support.
ppp: Include PPP dialup support.
smbfs: Include SMB networks client support (for mounting Samba/Microsoft Windows shares on device).
systemd: Include support for this
initmanager, which is a full replacement of forinitwith parallel starting of services, reduced shell overhead, and other features. Thisinitmanager is used by many distributions.usbgadget: Include USB Gadget Device support (for USB networking/serial/storage).
usbhost: Include USB Host support (allows to connect external keyboard, mouse, storage, network etc).
wayland: Include the Wayland display server protocol and the library that supports it.
wifi: Include WiFi support (integrated only).
The items below are features you can use with
MACHINE_FEATURES.
Features do not have a one-to-one correspondence to packages, and they can
go beyond simply controlling the installation of a package or packages.
Sometimes a feature can influence how certain recipes are built.
For example, a feature might determine whether a particular configure option
is specified within do_configure for a particular
recipe.
This feature list only represents features as shipped with the Yocto Project metadata:
acpi: Hardware has ACPI (x86/x86_64 only)
alsa: Hardware has ALSA audio drivers
apm: Hardware uses APM (or APM emulation)
bluetooth: Hardware has integrated BT
ext2: Hardware HDD or Microdrive
irda: Hardware has IrDA support
keyboard: Hardware has a keyboard
pci: Hardware has a PCI bus
pcmcia: Hardware has PCMCIA or CompactFlash sockets
screen: Hardware has a screen
serial: Hardware has serial support (usually RS232)
touchscreen: Hardware has a touchscreen
usbgadget: Hardware is USB gadget device capable
usbhost: Hardware is USB Host capable
wifi: Hardware has integrated WiFi
The contents of images generated by the OpenEmbedded build system can be controlled by the
IMAGE_FEATURES
and EXTRA_IMAGE_FEATURES
variables that you typically configure in your image recipes.
Through these variables, you can add several different
predefined packages such as development utilities or packages with debug
information needed to investigate application problems or profile applications.
Current list of
IMAGE_FEATURES contains the following:
dbg-pkgs: Installs debug symbol packages for all packages installed in a given image.
dev-pkgs: Installs development packages (headers and extra library links) for all packages installed in a given image.
doc-pkgs: Installs documentation packages for all packages installed in a given image.
nfs-server: Installs an NFS server.
read-only-rootfs: Creates an image whose root filesystem is read-only. See the "Creating a Read-Only Root Filesystem" section in the Yocto Project Development Manual for more information.
splash: Enables showing a splash screen during boot. By default, this screen is provided by
psplash, which does allow customization. If you prefer to use an alternative splash screen package, you can do so by setting theSPLASHvariable to a different package name (or names) within the image recipe or at the distro configuration level.ssh-server-dropbear: Installs the Dropbear minimal SSH server.
ssh-server-openssh: Installs the OpenSSH SSH server, which is more full-featured than Dropbear. Note that if both the OpenSSH SSH server and the Dropbear minimal SSH server are present in
IMAGE_FEATURES, then OpenSSH will take precedence and Dropbear will not be installed.staticdev-pkgs: Installs static development packages (i.e. static libraries containing
*.afiles) for all packages installed in a given image.tools-debug: Installs debugging tools such as
straceandgdb. For information on GDB, see the "Debugging With the GNU Project Debugger (GDB) Remotely" section in the Yocto Project Development Manual. For information on tracing and profiling, see the Yocto Project Profiling and Tracing Manual.tools-profile: Installs profiling tools such as
oprofile,exmap, andLTTng. For general information on user-space tools, see the "User-Space Tools" section in the Yocto Project Application Developer's Guide.tools-sdk: Installs a full SDK that runs on the device.
tools-testapps: Installs device testing tools (e.g. touchscreen debugging).
x11: Installs the X server
x11-base: Installs the X server with a minimal environment.
x11-sato: Installs the OpenedHand Sato environment.
Sometimes it is necessary in the OpenEmbedded build system to extend
MACHINE_FEATURES
or DISTRO_FEATURES
to control functionality that was previously enabled and not able
to be disabled.
For these cases, we need to add an
additional feature item to appear in one of these variables,
but we do not want to force developers who have existing values
of the variables in their configuration to add the new feature
in order to retain the same overall level of functionality.
Thus, the OpenEmbedded build system has a mechanism to
automatically "backfill" these added features into existing
distro or machine configurations.
You can see the list of features for which this is done by
finding the
DISTRO_FEATURES_BACKFILL
and MACHINE_FEATURES_BACKFILL
variables in the meta/conf/bitbake.conf file.
Because such features are backfilled by default into all
configurations as described in the previous paragraph, developers
who wish to disable the new features need to be able to selectively
prevent the backfilling from occurring.
They can do this by adding the undesired feature or features to the
DISTRO_FEATURES_BACKFILL_CONSIDERED
or MACHINE_FEATURES_BACKFILL_CONSIDERED
variables for distro features and machine features respectively.
Here are two examples to help illustrate feature backfilling:
The "pulseaudio" distro feature option: Previously, PulseAudio support was enabled within the Qt and GStreamer frameworks. Because of this, the feature is backfilled and thus enabled for all distros through the
DISTRO_FEATURES_BACKFILLvariable in themeta/conf/bitbake.conffile. However, your distro needs to disable the feature. You can disable the feature without affecting other existing distro configurations that need PulseAudio support by adding "pulseaudio" toDISTRO_FEATURES_BACKFILL_CONSIDEREDin your distro's.conffile. Adding the feature to this variable when it also exists in theDISTRO_FEATURES_BACKFILLvariable prevents the build system from adding the feature to your configuration'sDISTRO_FEATURES, effectively disabling the feature for that particular distro.The "rtc" machine feature option: Previously, real time clock (RTC) support was enabled for all target devices. Because of this, the feature is backfilled and thus enabled for all machines through the
MACHINE_FEATURES_BACKFILLvariable in themeta/conf/bitbake.conffile. However, your target device does not have this capability. You can disable RTC support for your device without affecting other machines that need RTC support by adding the feature to your machine'sMACHINE_FEATURES_BACKFILL_CONSIDEREDlist in the machine's.conffile. Adding the feature to this variable when it also exists in theMACHINE_FEATURES_BACKFILLvariable prevents the build system from adding the feature to your configuration'sMACHINE_FEATURES, effectively disabling RTC support for that particular machine.
This chapter lists common variables used in the OpenEmbedded build system and gives an overview of their function and contents.
A B C D E F G H I K L M O P Q R S T U W
A
- ALLOW_EMPTY
Specifies if an output package should still be produced if it is empty. By default, BitBake does not produce empty packages. This default behavior can cause issues when there is an
RDEPENDSor some other hard runtime requirement on the existence of the package.Like all package-controlling variables, you must always use them in conjunction with a package name override, as in:
ALLOW_EMPTY_${PN} = "1" ALLOW_EMPTY_${PN}-dev = "1" ALLOW_EMPTY_${PN}-staticdev = "1"- ALTERNATIVE
Lists commands in a package that need an alternative binary naming scheme. Sometimes the same command is provided in multiple packages. When this occurs, the OpenEmbedded build system needs to use the alternatives system to create a different binary naming scheme so the commands can co-exist.
To use the variable, list out the package's commands that also exist as part of another package. For example, if the
busyboxpackage has four commands that also exist as part of another package, you identify them as follows:ALTERNATIVE_busybox = "sh sed test bracket"For more information on the alternatives system, see the "
update-alternatives.bbclass" section.- ALTERNATIVE_LINK_NAME
Used by the alternatives system to map duplicated commands to actual locations. For example, if the
bracketcommand provided by thebusyboxpackage is duplicated through another package, you must use theALTERNATIVE_LINK_NAMEvariable to specify the actual location:ALTERNATIVE_LINK_NAME[bracket] = "/usr/bin/["In this example, the binary for the
bracketcommand (i.e.[) from thebusyboxpackage resides in/usr/bin/.Note
IfALTERNATIVE_LINK_NAMEis not defined, it defaults to${bindir}/<name>.For more information on the alternatives system, see the "
update-alternatives.bbclass" section.- ALTERNATIVE_PRIORITY
Used by the alternatives system to create default priorities for duplicated commands. You can use the variable to create a single default regardless of the command name or package, a default for specific duplicated commands regardless of the package, or a default for specific commands tied to particular packages. Here are the available syntax forms:
ALTERNATIVE_PRIORITY = "<priority>" ALTERNATIVE_PRIORITY[<name>] = "<priority>" ALTERNATIVE_PRIORITY_<pkg>[<name>] = "<priority>"For more information on the alternatives system, see the "
update-alternatives.bbclass" section.- ALTERNATIVE_TARGET
Used by the alternatives system to create default link locations for duplicated commands. You can use the variable to create a single default location for all duplicated commands regardless of the command name or package, a default for specific duplicated commands regardless of the package, or a default for specific commands tied to particular packages. Here are the available syntax forms:
ALTERNATIVE_TARGET = "<target>" ALTERNATIVE_TARGET[<name>] = "<target>" ALTERNATIVE_TARGET_<pkg>[<name>] = "<target>"Note
If
ALTERNATIVE_TARGETis not defined, it inherits the value from theALTERNATIVE_LINK_NAMEvariable.If
ALTERNATIVE_LINK_NAMEandALTERNATIVE_TARGETare the same, the target forALTERNATIVE_TARGEThas ".{BPN}" appended to it.Finally, if the file referenced has not been renamed, the alternatives system will rename it to avoid the need to rename alternative files in the
do_installtask while retaining support for the command if necessary.For more information on the alternatives system, see the "
update-alternatives.bbclass" section.- APPEND
An override list of append strings for each
LABEL.See the
grub-eficlass for more information on how this variable is used.- AUTHOR
The email address used to contact the original author or authors in order to send patches and forward bugs.
- AUTO_SYSLINUXMENU
Enables creating an automatic menu. You must set this in your recipe. The
syslinuxclass checks this variable.- AUTOREV
When
SRCREVis set to the value of this variable, it specifies to use the latest source revision in the repository. Here is an example:SRCREV = "${AUTOREV}"
B
- B
The directory within the Build Directory in which the OpenEmbedded build system places generated objects during a recipe's build process. By default, this directory is the same as the
Sdirectory, which is defined as:S = "${WORKDIR}/${BP}/"You can separate the (
S) directory and the directory pointed to by theBvariable. Most Autotools-based recipes support separating these directories. The build system defaults to using separate directories forgccand some kernel recipes.- BAD_RECOMMENDATIONS
Lists "recommended-only" packages to not install. Recommended-only packages are packages installed only through the
RRECOMMENDSvariable. You can prevent any of these "recommended" packages from being installed by listing them with theBAD_RECOMMENDATIONSvariable:BAD_RECOMMENDATIONS = "<package_name> <package_name> <package_name> ..."You can set this variable globally in your
local.conffile or you can attach it to a specific image recipe by using the recipe name override:BAD_RECOMMENDATIONS_pn-<target_image> = "<package_name>"It is important to realize that if you choose to not install packages using this variable and some other packages are dependent on them (i.e. listed in a recipe's
RDEPENDSvariable), the OpenEmbedded build system ignores your request and will install the packages to avoid dependency errors.Support for this variable exists only when using the IPK and RPM packaging backend. Support does not exist for DEB.
See the
NO_RECOMMENDATIONSand thePACKAGE_EXCLUDEvariables for related information.- BB_DANGLINGAPPENDS_WARNONLY
Defines how BitBake handles situations where an append file (
.bbappend) has no corresponding recipe file (.bb). This condition often occurs when layers get out of sync (e.g.oe-corebumps a recipe version and the old recipe no longer exists and the other layer has not been updated to the new version of the recipe yet).The default fatal behavior is safest because it is the sane reaction given something is out of sync. It is important to realize when your changes are no longer being applied.
You can change the default behavior by setting this variable to "1", "yes", or "true" in your
local.conffile, which is located in the Build Directory: Here is an example:BB_DANGLINGAPPENDS_WARNONLY = "1"- BB_DISKMON_DIRS
Monitors disk space and available inodes during the build and allows you to control the build based on these parameters.
Disk space monitoring is disabled by default. To enable monitoring, add the
BB_DISKMON_DIRSvariable to yourconf/local.conffile found in the Build Directory. Use the following form:BB_DISKMON_DIRS = "<action>,<dir>,<threshold> [...]" where: <action> is: ABORT: Immediately abort the build when a threshold is broken. STOPTASKS: Stop the build after the currently executing tasks have finished when a threshold is broken. WARN: Issue a warning but continue the build when a threshold is broken. Subsequent warnings are issued as defined by the BB_DISKMON_WARNINTERVAL variable, which must be defined in the conf/local.conf file. <dir> is: Any directory you choose. You can specify one or more directories to monitor by separating the groupings with a space. If two directories are on the same device, only the first directory is monitored. <threshold> is: Either the minimum available disk space, the minimum number of free inodes, or both. You must specify at least one. To omit one or the other, simply omit the value. Specify the threshold using G, M, K for Gbytes, Mbytes, and Kbytes, respectively. If you do not specify G, M, or K, Kbytes is assumed by default. Do not use GB, MB, or KB.Here are some examples:
BB_DISKMON_DIRS = "ABORT,${TMPDIR},1G,100K WARN,${SSTATE_DIR},1G,100K" BB_DISKMON_DIRS = "STOPTASKS,${TMPDIR},1G" BB_DISKMON_DIRS = "ABORT,${TMPDIR},,100K"The first example works only if you also provide the
BB_DISKMON_WARNINTERVALvariable in theconf/local.conf. This example causes the build system to immediately abort when either the disk space in${TMPDIR}drops below 1 Gbyte or the available free inodes drops below 100 Kbytes. Because two directories are provided with the variable, the build system also issue a warning when the disk space in the${SSTATE_DIR}directory drops below 1 Gbyte or the number of free inodes drops below 100 Kbytes. Subsequent warnings are issued during intervals as defined by theBB_DISKMON_WARNINTERVALvariable.The second example stops the build after all currently executing tasks complete when the minimum disk space in the
${TMPDIR}directory drops below 1 Gbyte. No disk monitoring occurs for the free inodes in this case.The final example immediately aborts the build when the number of free inodes in the
${TMPDIR}directory drops below 100 Kbytes. No disk space monitoring for the directory itself occurs in this case.- BB_DISKMON_WARNINTERVAL
Defines the disk space and free inode warning intervals. To set these intervals, define the variable in your
conf/local.conffile in the Build Directory.If you are going to use the
BB_DISKMON_WARNINTERVALvariable, you must also use theBB_DISKMON_DIRSvariable and define its action as "WARN". During the build, subsequent warnings are issued each time disk space or number of free inodes further reduces by the respective interval.If you do not provide a
BB_DISKMON_WARNINTERVALvariable and you do useBB_DISKMON_DIRSwith the "WARN" action, the disk monitoring interval defaults to the following:BB_DISKMON_WARNINTERVAL = "50M,5K"When specifying the variable in your configuration file, use the following form:
BB_DISKMON_WARNINTERVAL = "<disk_space_interval>,<disk_inode_interval>" where: <disk_space_interval> is: An interval of memory expressed in either G, M, or K for Gbytes, Mbytes, or Kbytes, respectively. You cannot use GB, MB, or KB. <disk_inode_interval> is: An interval of free inodes expressed in either G, M, or K for Gbytes, Mbytes, or Kbytes, respectively. You cannot use GB, MB, or KB.Here is an example:
BB_DISKMON_DIRS = "WARN,${SSTATE_DIR},1G,100K" BB_DISKMON_WARNINTERVAL = "50M,5K"These variables cause the OpenEmbedded build system to issue subsequent warnings each time the available disk space further reduces by 50 Mbytes or the number of free inodes further reduces by 5 Kbytes in the
${SSTATE_DIR}directory. Subsequent warnings based on the interval occur each time a respective interval is reached beyond the initial warning (i.e. 1 Gbytes and 100 Kbytes).- BB_GENERATE_MIRROR_TARBALLS
Causes tarballs of the Git repositories to be placed in the
DL_DIRdirectory. For performance reasons, creating and placing tarballs of the Git repositories is not the default action by the OpenEmbedded build system.BB_GENERATE_MIRROR_TARBALLS = "1"Set this variable in your
local.conffile in the Build Directory.- BB_NUMBER_THREADS
The maximum number of tasks BitBake should run in parallel at any one time. If your host development system supports multiple cores, a good rule of thumb is to set this variable to twice the number of cores.
- BBCLASSEXTEND
Allows you to extend a recipe so that it builds variants of the software. Common variants for recipes exist such as "natives" like
quilt-native, which is a copy of Quilt built to run on the build system; "crosses" such asgcc-cross, which is a compiler built to run on the build machine but produces binaries that run on the targetMACHINE; "nativesdk", which targets the SDK machine instead ofMACHINE; and "mulitlibs" in the form "multilib:<multilib_name>".To build a different variant of the recipe with a minimal amount of code, it usually is as simple as adding the following to your recipe:
BBCLASSEXTEND =+ "native nativesdk" BBCLASSEXTEND =+ "multilib:<multilib_name>"- BBFILE_COLLECTIONS
Lists the names of configured layers. These names are used to find the other
BBFILE_*variables. Typically, each layer will append its name to this variable in itsconf/layer.conffile.- BBFILE_PATTERN
Variable that expands to match files from
BBFILESin a particular layer. This variable is used in theconf/layer.conffile and must be suffixed with the name of the specific layer (e.g.BBFILE_PATTERN_emenlow).- BBFILE_PRIORITY
Assigns the priority for recipe files in each layer.
This variable is useful in situations where the same recipe appears in more than one layer. Setting this variable allows you to prioritize a layer against other layers that contain the same recipe - effectively letting you control the precedence for the multiple layers. The precedence established through this variable stands regardless of a recipe's version (
PVvariable). For example, a layer that has a recipe with a higherPVvalue but for which theBBFILE_PRIORITYis set to have a lower precedence still has a lower precedence.A larger value for the
BBFILE_PRIORITYvariable results in a higher precedence. For example, the value 6 has a higher precedence than the value 5. If not specified, theBBFILE_PRIORITYvariable is set based on layer dependencies (see theLAYERDEPENDSvariable for more information. The default priority, if unspecified for a layer with no dependencies, is the lowest defined priority + 1 (or 1 if no priorities are defined).Tip
You can use the commandbitbake-layers show-layersto list all configured layers along with their priorities.- BBFILES
List of recipe files used by BitBake to build software.
- BBINCLUDELOGS
Variable that controls how BitBake displays logs on build failure.
- BBLAYERS
Lists the layers to enable during the build. This variable is defined in the
bblayers.confconfiguration file in the Build Directory. Here is an example:BBLAYERS = " \ /home/scottrif/poky/meta \ /home/scottrif/poky/meta-yocto \ /home/scottrif/poky/meta-yocto-bsp \ /home/scottrif/poky/meta-mykernel \ " BBLAYERS_NON_REMOVABLE ?= " \ /home/scottrif/poky/meta \ /home/scottrif/poky/meta-yocto \ "This example enables four layers, one of which is a custom, user-defined layer named
meta-mykernel.- BBLAYERS_NON_REMOVABLE
Lists core layers that cannot be removed from the
bblayers.conffile during a build using the Hob.Note
When building an image outside of Hob, this variable is ignored.In order for BitBake to build your image using Hob, your
bblayers.conffile must include themetaandmeta-yoctocore layers. Here is an example that shows these two layers listed in theBBLAYERS_NON_REMOVABLEstatement:BBLAYERS = " \ /home/scottrif/poky/meta \ /home/scottrif/poky/meta-yocto \ /home/scottrif/poky/meta-yocto-bsp \ /home/scottrif/poky/meta-mykernel \ " BBLAYERS_NON_REMOVABLE ?= " \ /home/scottrif/poky/meta \ /home/scottrif/poky/meta-yocto \ "- BBMASK
Prevents BitBake from processing recipes and recipe append files. Use the
BBMASKvariable from within theconf/local.conffile found in the Build Directory.You can use the
BBMASKvariable to "hide" these.bband.bbappendfiles. BitBake ignores any recipe or recipe append files that match the expression. It is as if BitBake does not see them at all. Consequently, matching files are not parsed or otherwise used by BitBake.The value you provide is passed to Python's regular expression compiler. The expression is compared against the full paths to the files. For complete syntax information, see Python's documentation at http://docs.python.org/release/2.3/lib/re-syntax.html.
The following example uses a complete regular expression to tell BitBake to ignore all recipe and recipe append files in the
meta-ti/recipes-misc/directory:BBMASK = "meta-ti/recipes-misc/"If you want to mask out multiple directories or recipes, use the vertical bar to separate the regular expression fragments. This next example masks out multiple directories and individual recipes:
BBMASK = "meta-ti/recipes-misc/|meta-ti/recipes-ti/packagegroup/" BBMASK .= "|.*meta-oe/recipes-support/" BBMASK .= "|.*openldap" BBMASK .= "|.*opencv" BBMASK .= "|.*lzma"Notice how the vertical bar is used to append the fragments.
Note
When specifying a directory name, use the trailing slash character to ensure you match just that directory name.- BBPATH
Used by BitBake to locate
.bbclassand configuration files. This variable is analogous to thePATHvariable.Note
If you run BitBake from a directory outside of the Build Directory, you must be sure to setBBPATHto point to the Build Directory. Set the variable as you would any environment variable and then run BitBake:$ BBPATH = "<build_directory>" $ export BBPATH $ bitbake <target>- BBSERVER
Points to the server that runs memory-resident BitBake. This variable is set by the
oe-init-build-env-memressetup script and should not be hand-edited. The variable is only used when you employ memory-resident BitBake. The setup script exports the value as follows:export BBSERVER=localhost:$portFor more information on how the
BBSERVERis used, see theoe-init-build-env-memresscript, which is located in the Source Directory.- BINCONFIG_GLOB
When inheriting
binconfig.bbclassfrom a recipe, this variable specifies a wildcard for configuration scripts that need editing. The scripts are edited to correct any paths that have been set up during compilation so that they are correct for use when installed into the sysroot and called by the build processes of other recipes.For more information on how this variable works, see
meta/classes/binconfig.bbclassin the Source Directory. You can also find general information on the class in the "binconfig.bbclass" section.- BP
The base recipe name and version but without any special recipe name suffix (i.e.
-native,lib64-, and so forth).BPis comprised of the following:${BPN}-${PV}- BPN
The bare name of the recipe. This variable is a version of the
PNvariable but removes common suffixes such as "-native" and "-cross" as well as removes common prefixes such as multilib's "lib64-" and "lib32-". The exact list of suffixes removed is specified by theSPECIAL_PKGSUFFIXvariable. The exact list of prefixes removed is specified by theMLPREFIXvariable. Prefixes are removed formultilibandnativesdkcases.- BUGTRACKER
Specifies a URL for an upstream bug tracking website for a recipe. The OpenEmbedded build system does not use this variable. Rather, the variable is a useful pointer in case a bug in the software being built needs to be manually reported.
- BUILDDIR
Points to the location of the Build Directory. You can define this directory indirectly through the
oe-init-build-envandoe-init-build-env-memresscripts by passing in a Build Directory path when you run the scripts. If you run the scripts and do not provide a Build Directory path, theBUILDDIRdefaults tobuildin the current directory.- BUILDSTATS_BASE
Points to the location of the directory that holds build statistics when you use and enable the
buildstatsclass. TheBUILDSTATS_BASEdirectory defaults to${TMPDIR}/buildstats/.- BUSYBOX_SPLIT_SUID
For the BusyBox recipe, specifies whether to split the output executable file into two parts: one for features that require
setuid root, and one for the remaining features (i.e. those that do not requiresetuid root).The
BUSYBOX_SPLIT_SUIDvariable defaults to "1", which results in a single output executable file. Set the variable to "0" to split the output file.
C
- CFLAGS
Flags passed to the C compiler for the target system. This variable evaluates to the same as
TARGET_CFLAGS.- CLASSOVERRIDE
An internal variable specifying the special class override that should currently apply (e.g. "class-target", "class-native", and so forth). The classes that use this variable set it to appropriate values.
You do not normally directly interact with this variable. The value for the
CLASSOVERRIDEvariable goes intoOVERRIDESand then can be used as an override. Here is an example where "python-native" is added toDEPENDSonly when building for the native case:DEPENDS_append_class-native = " python-native"- COMBINED_FEATURES
Provides a list of hardware features that are enabled in both
MACHINE_FEATURESandDISTRO_FEATURES. This select list of features contains features that make sense to be controlled both at the machine and distribution configuration level. For example, the "bluetooth" feature requires hardware support but should also be optional at the distribution level, in case the hardware supports Bluetooth but you do not ever intend to use it.For more information, see the
MACHINE_FEATURESandDISTRO_FEATURESvariables.- COMMON_LICENSE_DIR
Points to
meta/files/common-licensesin the Source Directory, which is where generic license files reside.- COMPATIBLE_HOST
A regular expression that resolves to one or more hosts (when the recipe is native) or one or more targets (when the recipe is non-native) with which a recipe is compatible. The regular expression is matched against
HOST_SYS. You can use the variable to stop recipes from being built for classes of systems with which the recipes are not compatible. Stopping these builds is particularly useful with kernels. The variable also helps to increase parsing speed since the build system skips parsing recipes not compatible with the current system.- COMPATIBLE_MACHINE
A regular expression that resolves to one or more target machines with which a recipe is compatible. The regular expression is matched against
MACHINEOVERRIDES. You can use the variable to stop recipes from being built for machines with which the recipes are not compatible. Stopping these builds is particularly useful with kernels. The variable also helps to increase parsing speed since the build system skips parsing recipes not compatible with the current machine.- COMPLEMENTARY_GLOB
Defines wildcards to match when installing a list of complementary packages for all the packages explicitly (or implicitly) installed in an image. The resulting list of complementary packages is associated with an item that can be added to
IMAGE_FEATURES. An example usage of this is the "dev-pkgs" item that when added toIMAGE_FEATURESwill install -dev packages (containing headers and other development files) for every package in the image.To add a new feature item pointing to a wildcard, use a variable flag to specify the feature item name and use the value to specify the wildcard. Here is an example:
COMPLEMENTARY_GLOB[dev-pkgs] = '*-dev'- CONFFILES
Identifies editable or configurable files that are part of a package. If the Package Management System (PMS) is being used to update packages on the target system, it is possible that configuration files you have changed after the original installation and that you now want to remain unchanged are overwritten. In other words, editable files might exist in the package that you do not want reset as part of the package update process. You can use the
CONFFILESvariable to list the files in the package that you wish to prevent the PMS from overwriting during this update process.To use the
CONFFILESvariable, provide a package name override that identifies the resulting package. Then, provide a space-separated list of files. Here is an example:CONFFILES_${PN} += "${sysconfdir}/file1 \ ${sysconfdir}/file2 ${sysconfdir}/file3"A relationship exists between the
CONFFILESandFILESvariables. The files listed withinCONFFILESmust be a subset of the files listed withinFILES. Because the configuration files you provide withCONFFILESare simply being identified so that the PMS will not overwrite them, it makes sense that the files must already be included as part of the package through theFILESvariable.Note
When specifying paths as part of theCONFFILESvariable, it is good practice to use appropriate path variables. For example,${sysconfdir}rather than/etcor${bindir}rather than/usr/bin. You can find a list of these variables at the top of themeta/conf/bitbake.conffile in the Source Directory.- CONFIG_SITE
A list of files that contains
autoconftest results relevant to the current build. This variable is used by the Autotools utilities when runningconfigure.- CONFLICT_DISTRO_FEATURES
When a recipe inherits the
distro_features_checkclass, this variable identifies distribution features that would be in conflict should the recipe be built. In other words, if theCONFLICT_DISTRO_FEATURESvariable lists a feature that also appears inDISTRO_FEATURESwithin the current configuration, an error occurs and the build stops.- CORE_IMAGE_EXTRA_INSTALL
Specifies the list of packages to be added to the image. You should only set this variable in the
local.confconfiguration file found in the Build Directory.This variable replaces
POKY_EXTRA_INSTALL, which is no longer supported.- COREBASE
Specifies the parent directory of the OpenEmbedded Core Metadata layer (i.e.
meta).It is an important distinction that
COREBASEpoints to the parent of this layer and not the layer itself. Consider an example where you have cloned the Poky Git repository and retained thepokyname for your local copy of the repository. In this case,COREBASEpoints to thepokyfolder because it is the parent directory of thepoky/metalayer.
D
- D
The destination directory.
- DATETIME
The date and time on which the current build started. The format is suitable for timestamps.
- DEBUG_BUILD
Specifies to build packages with debugging information. This influences the value of the
SELECTED_OPTIMIZATIONvariable.- DEBUG_OPTIMIZATION
The options to pass in
TARGET_CFLAGSandCFLAGSwhen compiling a system for debugging. This variable defaults to "-O -fno-omit-frame-pointer ${DEBUG_FLAGS} -pipe".- DEFAULT_PREFERENCE
Specifies a weak bias for recipe selection priority.
The most common usage of this is variable is to set it to "-1" within a recipe for a development version of a piece of software. Using the variable in this way causes the stable version of the recipe to build by default in the absence of
PREFERRED_VERSIONbeing used to build the development version.Note
The bias provided byDEFAULT_PREFERENCEis weak and is overridden byBBFILE_PRIORITYif that variable is different between two layers that contain different versions of the same recipe.- DEPENDS
Lists a recipe's build-time dependencies (i.e. other recipe files). The system ensures that all the dependencies listed have been built and have their contents in the appropriate sysroots before the recipe's configure task is executed.
Consider this simple example for two recipes named "a" and "b" that produce similarly named packages. In this example, the
DEPENDSstatement appears in the "a" recipe:DEPENDS = "b"Here, the dependency is such that the
do_configuretask for recipe "a" depends on thedo_populate_sysroottask of recipe "b". This means anything that recipe "b" puts into sysroot is available when recipe "a" is configuring itself.For information on runtime dependencies, see the
RDEPENDSvariable.- DEPLOY_DIR
Points to the general area that the OpenEmbedded build system uses to place images, packages, SDKs and other output files that are ready to be used outside of the build system. By default, this directory resides within the Build Directory as
${TMPDIR}/deploy.For more information on the structure of the Build Directory, see "The Build Directory -
build/" section. For more detail on the contents of thedeploydirectory, see the "Images" and "Application Development SDK" sections.- DEPLOY_DIR_IMAGE
Points to the area that the OpenEmbedded build system uses to place images and other associated output files that are ready to be deployed onto the target machine. The directory is machine-specific as it contains the
${MACHINE}name. By default, this directory resides within the Build Directory as${DEPLOY_DIR}/images/${MACHINE}/.For more information on the structure of the Build Directory, see "The Build Directory -
build/" section. For more detail on the contents of thedeploydirectory, see the "Images" and "Application Development SDK" sections.- DEPLOYDIR
For recipes that inherit the
deployclass, theDEPLOYDIRpoints to a temporary work area for deployed files that is set in thedeployclass as follows:DEPLOYDIR = "${WORKDIR}/deploy-${PN}"Recipes inheriting the
deployclass should copy files to be deployed intoDEPLOYDIR, and the class will take care of copying them intoDEPLOY_DIR_IMAGEafterwards.- DESCRIPTION
The package description used by package managers. If not set,
DESCRIPTIONtakes the value of theSUMMARYvariable.- DISTRO
The short name of the distribution. This variable corresponds to a distribution configuration file whose root name is the same as the variable's argument and whose filename extension is
.conf. For example, the distribution configuration file for the Poky distribution is namedpoky.confand resides in themeta-yocto/conf/distrodirectory of the Source Directory.Within that
poky.conffile, theDISTROvariable is set as follows:DISTRO = "poky"Distribution configuration files are located in a
conf/distrodirectory within the Metadata that contains the distribution configuration. The value forDISTROmust not contain spaces, and is typically all lower-case.Note
If theDISTROvariable is blank, a set of default configurations are used, which are specified withinmeta/conf/distro/defaultsetup.confalso in the Source Directory.- DISTRO_EXTRA_RDEPENDS
Specifies a list of distro-specific packages to add to all images. This variable takes affect through
packagegroup-baseso the variable only really applies to the more full-featured images that includepackagegroup-base. You can use this variable to keep distro policy out of generic images. As with all other distro variables, you set this variable in the distro.conffile.- DISTRO_EXTRA_RRECOMMENDS
Specifies a list of distro-specific packages to add to all images if the packages exist. The packages might not exist or be empty (e.g. kernel modules). The list of packages are automatically installed but you can remove them.
- DISTRO_FEATURES
The software support you want in your distribution for various features. You define your distribution features in the distribution configuration file.
In most cases, the presence or absence of a feature in
DISTRO_FEATURESis translated to the appropriate option supplied to the configure script duringdo_configurefor recipes that optionally support the feature. For example, specifying "x11" inDISTRO_FEATURES, causes every piece of software built for the target that can optionally support X11 to have its X11 support enabled.Two more examples are Bluetooth and NFS support. For a more complete list of features that ships with the Yocto Project and that you can provide with this variable, see the "Distro Features" section.
- DISTRO_FEATURES_BACKFILL
Features to be added to
DISTRO_FEATURESif not also present inDISTRO_FEATURES_BACKFILL_CONSIDERED.This variable is set in the
meta/conf/bitbake.conffile. It is not intended to be user-configurable. It is best to just reference the variable to see which distro features are being backfilled for all distro configurations. See the Feature backfilling section for more information.- DISTRO_FEATURES_BACKFILL_CONSIDERED
Features from
DISTRO_FEATURES_BACKFILLthat should not be backfilled (i.e. added toDISTRO_FEATURES) during the build. See the "Feature Backfilling" section for more information.- DISTRO_NAME
The long name of the distribution.
- DISTRO_PN_ALIAS
Alias names used for the recipe in various Linux distributions.
See the "Handling a Package Name Alias" section in the Yocto Project Development Manual for more information.
- DISTRO_VERSION
The version of the distribution.
- DISTROOVERRIDES
This variable lists overrides specific to the current distribution. By default, the variable list includes the value of the
DISTROvariable. You can extend the variable to apply any variable overrides you want as part of the distribution and are not already inOVERRIDESthrough some other means.- DL_DIR
The central download directory used by the build process to store downloads. By default,
DL_DIRgets files suitable for mirroring for everything except Git repositories. If you want tarballs of Git repositories, use theBB_GENERATE_MIRROR_TARBALLSvariable.You can set this directory by defining the
DL_DIRvariable in theconf/local.conffile. This directory is self-maintaining and you should not have to touch it. By default, the directory isdownloadsin the Build Directory.#DL_DIR ?= "${TOPDIR}/downloads"To specify a different download directory, simply remove the comment from the line and provide your directory.
During a first build, the system downloads many different source code tarballs from various upstream projects. Downloading can take a while, particularly if your network connection is slow. Tarballs are all stored in the directory defined by
DL_DIRand the build system looks there first to find source tarballs.Note
When wiping and rebuilding, you can preserve this directory to speed up this part of subsequent builds.You can safely share this directory between multiple builds on the same development machine. For additional information on how the build process gets source files when working behind a firewall or proxy server, see this specific question in the "FAQ" chapter.
E
- ENABLE_BINARY_LOCALE_GENERATION
Variable that controls which locales for
eglibcare generated during the build (useful if the target device has 64Mbytes of RAM or less).- ERROR_QA
Specifies the quality assurance checks whose failures are reported as errors by the OpenEmbedded build system. You set this variable in your distribution configuration file. For a list of the checks you can control with this variable, see the "
insane.bbclass" section.- EXCLUDE_FROM_WORLD
Directs BitBake to exclude a recipe from world builds (i.e.
bitbake world). During world builds, BitBake locates, parses and builds all recipes found in every layer exposed in thebblayers.confconfiguration file.To exclude a recipe from a world build using this variable, set the variable to "1" in the recipe.
Note
Recipes added toEXCLUDE_FROM_WORLDmay still be built during a world build in order to satisfy dependencies of other recipes. Adding a recipe toEXCLUDE_FROM_WORLDonly ensures that the recipe is not explicitly added to the list of build targets in a world build.- EXTENDPE
Used with file and pathnames to create a prefix for a recipe's version based on the recipe's
PEvalue. IfPEis set and greater than zero for a recipe,EXTENDPEbecomes that value (e.g ifPEis equal to "1" thenEXTENDPEbecomes "1_"). If a recipe'sPEis not set (the default) or is equal to zero,EXTENDPEbecomes "".See the
STAMPvariable for an example.- EXTENDPKGV
The full package version specification as it appears on the final packages produced by a recipe. The variable's value is normally used to fix a runtime dependency to the exact same version of another package in the same recipe:
RDEPENDS_${PN}-additional-module = "${PN} (= ${EXTENDPKGV})"The dependency relationships are intended to force the package manager to upgrade these types of packages in lock-step.
- EXTERNALSRC
If
externalsrc.bbclassis inherited, this variable points to the source tree, which is outside of the OpenEmbedded build system. When set, this variable sets theSvariable, which is what the OpenEmbedded build system uses to locate unpacked recipe source code.For more information on
externalsrc.bbclass, see the "externalsrc.bbclass" section. You can also find information on how to use this variable in the "Building Software from an External Source" section in the Yocto Project Development Manual.- EXTERNALSRC_BUILD
If
externalsrc.bbclassis inherited, this variable points to the directory in which the recipe's source code is built, which is outside of the OpenEmbedded build system. When set, this variable sets theBvariable, which is what the OpenEmbedded build system uses to locate the Build Directory.For more information on
externalsrc.bbclass, see the "externalsrc.bbclass" section. You can also find information on how to use this variable in the "Building Software from an External Source" section in the Yocto Project Development Manual.- EXTRA_IMAGE_FEATURES
The list of additional features to include in an image. Typically, you configure this variable in your
local.conffile, which is found in the Build Directory. Although you can use this variable from within a recipe, best practices dictate that you do not.Note
To enable primary features from within the image recipe, use theIMAGE_FEATURESvariable.Here are some examples of features you can add:
"dbg-pkgs" - Adds -dbg packages for all installed packages including symbol information for debugging and profiling. "debug-tweaks" - Makes an image suitable for development. For example, ssh root access has a blank password. You should remove this feature before you produce a production image. "dev-pkgs" - Adds -dev packages for all installed packages. This is useful if you want to develop against the libraries in the image. "read-only-rootfs" - Creates an image whose root filesystem is read-only. See the "Creating a Read-Only Root Filesystem" section in the Yocto Project Development Manual for more information "tools-debug" - Adds debugging tools such as gdb and strace. "tools-profile" - Adds profiling tools such as oprofile, exmap, lttng and valgrind (x86 only). "tools-sdk" - Adds development tools such as gcc, make, pkgconfig and so forth. "tools-testapps" - Adds useful testing tools such as ts_print, aplay, arecord and so forth.For a complete list of image features that ships with the Yocto Project, see the "Image Features" section.
For an example that shows how to customize your image by using this variable, see the "Customizing Images Using Custom
IMAGE_FEATURESandEXTRA_IMAGE_FEATURES" section in the Yocto Project Development Manual.- EXTRA_IMAGEDEPENDS
A list of recipes to build that do not provide packages for installing into the root filesystem.
Sometimes a recipe is required to build the final image but is not needed in the root filesystem. You can use the
EXTRA_IMAGEDEPENDSvariable to list these recipes and thus specify the dependencies. A typical example is a required bootloader in a machine configuration.- EXTRA_OECMAKE
Additional
cmakeoptions.- EXTRA_OECONF
Additional
configurescript options.- EXTRA_OEMAKE
Additional GNU
makeoptions.- EXTRA_OESCONS
When a recipe inherits the
sconsclass, this variable specifies additional configuration options you want to pass to thesconscommand line.- EXTRA_QMAKEVARS_POST
Configuration variables or options you want to pass to
qmake. Use this variable when the arguments need to be after the.profile list on the command line.This variable is used with recipes that inherit the
qmake_baseclass or other classes that inheritqmake_base.- EXTRA_QMAKEVARS_PRE
Configuration variables or options you want to pass to
qmake. Use this variable when the arguments need to be before the.profile list on the command line.This variable is used with recipes that inherit the
qmake_baseclass or other classes that inheritqmake_base.- EXTRA_USERS_PARAMS
When a recipe inherits the
extrausersclass, this variable provides image level user and group operations. This is a more global method of providing user and group configuration as compared to using theuseraddclass, which ties user and group configurations to a specific recipe.The set list of commands you can configure using the
EXTRA_USERS_PARAMSis shown in theextrausersclass. These commands map to the normal Unix commands of the same names:# EXTRA_USERS_PARAMS = "\ # useradd -p '' tester; \ # groupadd developers; \ # userdel nobody; \ # groupdel -g video; \ # groupmod -g 1020 developers; \ # usermod -s /bin/sh tester; \ # "
F
- FEED_DEPLOYDIR_BASE_URI
Points to the base URL of the server and location within the document-root that provides the metadata and packages required by OPKG to support runtime package management of IPK packages. You set this variable in your
local.conffile.Consider the following example:
FEED_DEPLOYDIR_BASE_URI = "http://192.168.7.1/BOARD-dir"This example assumes you are serving your packages over HTTP and your databases are located in a directory named
BOARD-dir, which is underneath your HTTP server's document-root. In this case, the OpenEmbedded build system generates a set of configuration files for you in your target that work with the feed.- FILES
The list of directories or files that are placed in packages.
To use the
FILESvariable, provide a package name override that identifies the resulting package. Then, provide a space-separated list of files or paths that identifies the files you want included as part of the resulting package. Here is an example:FILES_${PN} += "${bindir}/mydir1/ ${bindir}/mydir2/myfile"Note
When specifying paths as part of theFILESvariable, it is good practice to use appropriate path variables. For example, use${sysconfdir}rather than/etc, or${bindir}rather than/usr/bin. You can find a list of these variables at the top of themeta/conf/bitbake.conffile in the Source Directory.If some of the files you provide with the
FILESvariable are editable and you know they should not be overwritten during the package update process by the Package Management System (PMS), you can identify these files so that the PMS will not overwrite them. See theCONFFILESvariable for information on how to identify these files to the PMS.- FILESEXTRAPATHS
Extends the search path the OpenEmbedded build system uses when looking for files and patches as it processes recipes and append files. The default directories BitBake uses when it processes recipes are initially defined by the
FILESPATHvariable. You can extendFILESPATHvariable by usingFILESEXTRAPATHS.Best practices dictate that you accomplish this by using
FILESEXTRAPATHSfrom within a.bbappendfile and that you prepend paths as follows:FILESEXTRAPATHS_prepend := "${THISDIR}/${PN}:"In the above example, the build system first looks for files in a directory that has the same name as the corresponding append file.
Note
When extending
FILESEXTRAPATHS, be sure to use the immediate expansion (:=) operator. Immediate expansion makes sure that BitBake evaluatesTHISDIRat the time the directive is encountered rather than at some later time when expansion might result in a directory that does not contain the files you need.Also, include the trailing separating colon character if you are prepending. The trailing colon character is necessary because you are directing BitBake to extend the path by prepending directories to the search path.
Here is another common use:
FILESEXTRAPATHS_prepend := "${THISDIR}/files:"In this example, the build system extends the
FILESPATHvariable to include a directory namedfilesthat is in the same directory as the corresponding append file.Here is a final example that specifically adds three paths:
FILESEXTRAPATHS_prepend := "path_1:path_2:path_3:"By prepending paths in
.bbappendfiles, you allow multiple append files that reside in different layers but are used for the same recipe to correctly extend the path.- FILESOVERRIDES
A subset of
OVERRIDESused by the OpenEmbedded build system for creatingFILESPATH. You can find more information on how overrides are handled in the BitBake Manual that is located atbitbake/doc/manualin the Source Directory.By default, the
FILESOVERRIDESvariable is defined as:FILESOVERRIDES = "${TRANSLATED_TARGET_ARCH}:${MACHINEOVERRIDES}:${DISTROOVERRIDES}"Note
Do not hand-edit theFILESOVERRIDESvariable. The values match up with expected overrides and are used in an expected manner by the build system.- FILESPATH
The default set of directories the OpenEmbedded build system uses when searching for patches and files. During the build process, BitBake searches each directory in
FILESPATHin the specified order when looking for files and patches specified by eachfile://URI in a recipe.The default value for the
FILESPATHvariable is defined in thebase.bbclassclass found inmeta/classesin the Source Directory:FILESPATH = "${@base_set_filespath(["${FILE_DIRNAME}/${BP}", \ "${FILE_DIRNAME}/${BPN}", "${FILE_DIRNAME}/files"], d)}"Note
Do not hand-edit theFILESPATHvariable. If you want the build system to look in directories other than the defaults, extend theFILESPATHvariable by using theFILESEXTRAPATHSvariable.Be aware that the default
FILESPATHdirectories do not map to directories in custom layers where append files (.bbappend) are used. If you want the build system to find patches or files that reside with your append files, you need to extend theFILESPATHvariable by using theFILESEXTRAPATHSvariable.- FILESYSTEM_PERMS_TABLES
Allows you to define your own file permissions settings table as part of your configuration for the packaging process. For example, suppose you need a consistent set of custom permissions for a set of groups and users across an entire work project. It is best to do this in the packages themselves but this is not always possible.
By default, the OpenEmbedded build system uses the
fs-perms.txt, which is located in themeta/filesfolder in the Source Directory. If you create your own file permissions setting table, you should place it in your layer or the distro's layer.You define the
FILESYSTEM_PERMS_TABLESvariable in theconf/local.conffile, which is found in the Build Directory, to point to your customfs-perms.txt. You can specify more than a single file permissions setting table. The paths you specify to these files must be defined within theBBPATHvariable.For guidance on how to create your own file permissions settings table file, examine the existing
fs-perms.txt.- FONT_PACKAGES
When a recipe inherits the
fontcacheclass, this variable identifies packages containing font files that need to be cached by Fontconfig. By default, thefontcacheclass assumes that fonts are in the recipe's main package (i.e.${PN}). Use this variable if fonts you need are in a package other than that main package.- FULL_OPTIMIZATION
The options to pass in
TARGET_CFLAGSandCFLAGSwhen compiling an optimized system. This variable defaults to "-O2 -pipe ${DEBUG_FLAGS}".
G
- GROUPADD_PARAM
When a recipe inherits the
useraddclass, this variable specifies for a package what parameters should be passed to thegroupaddcommand if you wish to add a group to the system when the package is installed.Here is an example from the
dbusrecipe:GROUPADD_PARAM_${PN} = "-r netdev"For information on the standard Linux shell command
groupadd, see http://linux.die.net/man/8/groupadd.- GROUPMEMS_PARAM
When a recipe inherits the
useraddclass, this variable specifies for a package what parameters should be passed to thegroupmemscommand if you wish to modify the members of a group when the package is installed.For information on the standard Linux shell command
groupmems, see http://linux.die.net/man/8/groupmems.- GRUB_GFXSERIAL
Configures the GNU GRand Unified Bootloader (GRUB) to have graphics and serial in the boot menu. Set this variable to "1" in your
local.confor distribution configuration file to enable graphics and serial in the menu.See the
grub-eficlass for more information on how this variable is used.- GRUB_OPTS
Additional options to add to the GNU GRand Unified Bootloader (GRUB) configuration. Use a semi-colon character (
;) to separate multiple options.The
GRUB_OPTSvariable is optional. See thegrub-eficlass for more information on how this variable is used.- GRUB_TIMEOUT
Specifies the timeout before executing the default
LABELin the GNU GRand Unified Bootloader (GRUB).The
GRUB_TIMEOUTvariable is optional. See thegrub-eficlass for more information on how this variable is used.- GTKIMMODULES_PACKAGES
For recipes that inherit the
gtk-immodules-cacheclass, this variable specifies the packages that contain the GTK+ input method modules being installed when the modules are in packages other than the main package.
H
- HOMEPAGE
Website where more information about the software the recipe is building can be found.
- HOST_SYS
Specifies the system, including the architecture and the operating system, for with the build is occurring in the context of the current recipe. The OpenEmbedded build system automatically sets this variable. You do not need to set the variable yourself.
Here are two examples:
Given a native recipe on a 32-bit x86 machine running Linux, the value is "i686-linux".
Given a recipe being built for a little-endian MIPS target running Linux, the value might be "mipsel-linux".
I
- ICECC_ENV_EXEC
Points to the
icecc-create-envscript that you provide. This variable is used by theiceccclass. You set this variable in yourlocal.conffile.If you do not point to a script that you provide, the OpenEmbedded build system uses the default script provided by the
icecc-create-env.bbrecipe, which is a modified version and not the one that comes withicecc.- ICECC_PATH
The location of the
iceccbinary. You can set this variable in yourlocal.conffile. If yourlocal.conffile does not define this variable, theiceccclass attempts to define it by locatingiceccusingwhich.- ICECC_USER_CLASS_BL
Identifies user classes that you do not want the Icecream distributed compile support to consider. This variable is used by the
iceccclass. You set this variable in yourlocal.conffile.When you list classes using this variable, you are "blacklisting" them from distributed compilation across remote hosts. Any classes you list will be distributed and compiled locally.
- ICECC_USER_PACKAGE_BL
Identifies user recipes that you do not want the Icecream distributed compile support to consider. This variable is used by the
iceccclass. You set this variable in yourlocal.conffile.When you list packages using this variable, you are "blacklisting" them from distributed compilation across remote hosts. Any packages you list will be distributed and compiled locally.
- ICECC_USER_PACKAGE_WL
Identifies user recipes that use an empty
PARALLEL_MAKEvariable that you want to force remote distributed compilation on using the Icecream distributed compile support. This variable is used by theiceccclass. You set this variable in yourlocal.conffile.- IMAGE_BASENAME
The base name of image output files. This variable defaults to the recipe name (
${PN}).- IMAGE_CLASSES
A list of classes that all images should inherit. You typically use this variable to specify the list of classes that register the different types of images the OpenEmbedded build system creates.
The default value for
IMAGE_CLASSESisimage_types. You can set this variable in yourlocal.confor in a distribution configuration file.For more information, see
meta/classes/image_types.bbclassin the Source Directory.- IMAGE_FEATURES
The primary list of features to include in an image. Typically, you configure this variable in an image recipe. Although you can use this variable from your
local.conffile, which is found in the Build Directory, best practices dictate that you do not.Note
To enable extra features from outside the image recipe, use theEXTRA_IMAGE_FEATURESvariable.For a list of image features that ships with the Yocto Project, see the "Image Features" section.
For an example that shows how to customize your image by using this variable, see the "Customizing Images Using Custom
IMAGE_FEATURESandEXTRA_IMAGE_FEATURES" section in the Yocto Project Development Manual.- IMAGE_FSTYPES
Specifies the formats the OpenEmbedded build system uses during the build when creating the root filesystem. For example, setting
IMAGE_FSTYPESas follows causes the build system to create root filesystems using two formats:.ext3and.tar.bz2:IMAGE_FSTYPES = "ext3 tar.bz2"For the complete list of supported image formats from which you can choose, see
IMAGE_TYPES.Note
If you add "live" toIMAGE_FSTYPESinside an image recipe, be sure that you do so prior to the "inherit image" line of the recipe or the live image will not build.Note
Due to the way this variable is processed, it is not possible to update its contents using_appendor_prepend. To add one or more additional options to this variable the+=operator must be used.- IMAGE_INSTALL
Specifies the packages to install into an image. The
IMAGE_INSTALLvariable is a mechanism for an image recipe and you should use it with care to avoid ordering issues.Image recipes set
IMAGE_INSTALLto specify the packages to install into an image throughimage.bbclass. Additionally, "helper" classes exist, such ascore-image.bbclass, that can takeIMAGE_FEATURESlists and turn these into auto-generated entries inIMAGE_INSTALLin addition to its default contents.Using
IMAGE_INSTALLwith the+=operator from the/conf/local.conffile or from within an image recipe is not recommended as it can cause ordering issues. Sincecore-image.bbclasssetsIMAGE_INSTALLto a default value using the?=operator, using a+=operation againstIMAGE_INSTALLwill result in unexpected behavior when used inconf/local.conf. Furthermore, the same operation from within an image recipe may or may not succeed depending on the specific situation. In both these cases, the behavior is contrary to how most users expect the+=operator to work.When you use this variable, it is best to use it as follows:
IMAGE_INSTALL_append = " package-name"Be sure to include the space between the quotation character and the start of the package name or names.
- IMAGE_LINGUAS
Specifies the list of locales to install into the image during the root filesystem construction process. The OpenEmbedded build system automatically splits locale files, which are used for localization, into separate packages. Setting the
IMAGE_LINGUASvariable ensures that any locale packages that correspond to packages already selected for installation into the image are also installed. Here is an example:IMAGE_LINGUAS = "pt-br de-de"In this example, the build system ensures any Brazilian Portuguese and German locale files that correspond to packages in the image are installed (i.e.
*-locale-pt-brand*-locale-de-deas well as*-locale-ptand*-locale-de, since some software packages only provide locale files by language and not by country-specific language).- IMAGE_NAME
The name of the output image files minus the extension. This variable is derived using the
IMAGE_BASENAME,MACHINE, andDATETIMEvariables:IMAGE_NAME = "${IMAGE_BASENAME}-${MACHINE}-${DATETIME}"- IMAGE_OVERHEAD_FACTOR
Defines a multiplier that the build system applies to the initial image size for cases when the multiplier times the returned disk usage value for the image is greater than the sum of
IMAGE_ROOTFS_SIZEandIMAGE_ROOTFS_EXTRA_SPACE. The result of the multiplier applied to the initial image size creates free disk space in the image as overhead. By default, the build process uses a multiplier of 1.3 for this variable. This default value results in 30% free disk space added to the image when this method is used to determine the final generated image size. You should be aware that post install scripts and the package management system uses disk space inside this overhead area. Consequently, the multiplier does not produce an image with all the theoretical free disk space. SeeIMAGE_ROOTFS_SIZEfor information on how the build system determines the overall image size.The default 30% free disk space typically gives the image enough room to boot and allows for basic post installs while still leaving a small amount of free disk space. If 30% free space is inadequate, you can increase the default value. For example, the following setting gives you 50% free space added to the image:
IMAGE_OVERHEAD_FACTOR = "1.5"Alternatively, you can ensure a specific amount of free disk space is added to the image by using the
IMAGE_ROOTFS_EXTRA_SPACEvariable.- IMAGE_PKGTYPE
Defines the package type (DEB, RPM, IPK, or TAR) used by the OpenEmbedded build system. The variable is defined appropriately by the
package_deb,package_rpm,package_ipk, orpackage_tarclass.The
package_sdk_baseandimageclasses use theIMAGE_PKGTYPEfor packaging up images and SDKs.You should not set the
IMAGE_PKGTYPEmanually. Rather, the variable is set indirectly through the appropriatepackage_*class using thePACKAGE_CLASSESvariable. The OpenEmbedded build system uses the first package type (e.g. DEB, RPM, or IPK) that appears with the variableNote
Files using the.tarformat are never used as a substitute packaging format for DEB, RPM, and IPK formatted files for your image or SDK.- IMAGE_POSTPROCESS_COMMAND
Added by classes to run post processing commands once the OpenEmbedded build system has created the image. You can specify shell commands separated by semicolons:
IMAGE_POSTPROCESS_COMMAND += "<shell_command>; ... "If you need to pass the path to the root filesystem within the command, you can use
${IMAGE_ROOTFS}, which points to the root filesystem image.- IMAGE_ROOTFS
The location of the root filesystem while it is under construction (i.e. during
do_rootfs). This variable is not configurable. Do not change it.- IMAGE_ROOTFS_EXTRA_SPACE
Defines additional free disk space created in the image in Kbytes. By default, this variable is set to "0". This free disk space is added to the image after the build system determines the image size as described in
IMAGE_ROOTFS_SIZE.This variable is particularly useful when you want to ensure that a specific amount of free disk space is available on a device after an image is installed and running. For example, to be sure 5 Gbytes of free disk space is available, set the variable as follows:
IMAGE_ROOTFS_EXTRA_SPACE = "5242880"For example, the Yocto Project Build Appliance specifically requests 40 Gbytes of extra space with the line:
IMAGE_ROOTFS_EXTRA_SPACE = "41943040"- IMAGE_ROOTFS_SIZE
Defines the size in Kbytes for the generated image. The OpenEmbedded build system determines the final size for the generated image using an algorithm that takes into account the initial disk space used for the generated image, a requested size for the image, and requested additional free disk space to be added to the image. Programatically, the build system determines the final size of the generated image as follows:
if (image-du * overhead) < rootfs-size: internal-rootfs-size = rootfs-size + xspace else: internal-rootfs-size = (image-du * overhead) + xspace where: image-du = Returned value of the du command on the image. overhead = IMAGE_OVERHEAD_FACTOR rootfs-size = IMAGE_ROOTFS_SIZE internal-rootfs-size = Initial root filesystem size before any modifications. xspace = IMAGE_ROOTFS_EXTRA_SPACESee the
IMAGE_OVERHEAD_FACTORandIMAGE_ROOTFS_EXTRA_SPACEvariables for related information.- IMAGE_TYPES
Specifies the complete list of supported image types by default:
jffs2 sum.jffs2 cramfs ext2 ext2.gz ext2.bz2 ext3 ext3.gz ext2.lzma btrfs live squashfs squashfs-xz ubi ubifs tar tar.gz tar.bz2 tar.xz cpio cpio.gz cpio.xz cpio.lzma vmdk elfFor more information on how these types of images, see
meta/classes/image_types*.bbclassin the Source Directory.- INC_PR
Helps define the recipe revision for recipes that share a common
includefile. You can think of this variable as part of the recipe revision as set from within an include file.Suppose, for example, you have a set of recipes that are used across several projects. And, within each of those recipes the revision (its
PRvalue) is set accordingly. In this case, when the revision of those recipes changes, the burden is on you to find all those recipes and be sure that they get changed to reflect the updated version of the recipe. In this scenario, it can get complicated when recipes that are used in many places and provide common functionality are upgraded to a new revision.A more efficient way of dealing with this situation is to set the
INC_PRvariable inside theincludefiles that the recipes share and then expand theINC_PRvariable within the recipes to help define the recipe revision.The following provides an example that shows how to use the
INC_PRvariable given a commonincludefile that defines the variable. Once the variable is defined in theincludefile, you can use the variable to set thePRvalues in each recipe. You will notice that when you set a recipe'sPRyou can provide more granular revisioning by appending values to theINC_PRvariable:recipes-graphics/xorg-font/xorg-font-common.inc:INC_PR = "r2" recipes-graphics/xorg-font/encodings_1.0.4.bb:PR = "${INC_PR}.1" recipes-graphics/xorg-font/font-util_1.3.0.bb:PR = "${INC_PR}.0" recipes-graphics/xorg-font/font-alias_1.0.3.bb:PR = "${INC_PR}.3"The first line of the example establishes the baseline revision to be used for all recipes that use the
includefile. The remaining lines in the example are from individual recipes and show how thePRvalue is set.- INCOMPATIBLE_LICENSE
Specifies a space-separated list of license names (as they would appear in
LICENSE) that should be excluded from the build. Recipes that provide no alternatives to listed incompatible licenses are not built. Packages that are individually licensed with the specified incompatible licenses will be deleted.Note
This functionality is only regularly tested using the following setting:INCOMPATIBLE_LICENSE = "GPLv3"Although you can use other settings, you might be required to remove dependencies on or provide alternatives to components that are required to produce a functional system image.- INHIBIT_DEFAULT_DEPS
Prevents the default dependencies, namely the C compiler and standard C library (libc), from being added to
DEPENDS. This variable is usually used within recipes that do not require any compilation using the C compiler.Set the variable to "1" to prevent the default dependencies from being added.
- INHIBIT_PACKAGE_STRIP
If set to "1", causes the build to not strip binaries in resulting packages.
- INHERIT
Causes the named class to be inherited at this point during parsing. The variable is only valid in configuration files.
- INHERIT_DISTRO
Lists classes that will be inherited at the distribution level. It is unlikely that you want to edit this variable.
The default value of the variable is set as follows in the
meta/conf/distro/defaultsetup.conffile:INHERIT_DISTRO ?= "debian devshell sstate license"- INITRAMFS_FSTYPES
Defines the format for the output image of an initial RAM disk (initramfs), which is used during boot. Supported formats are the same as those supported by the
IMAGE_FSTYPESvariable.- INITRD
Indicates a filesystem image to use as an initial RAM disk (
initrd).The
INITRDvariable is an optional variable used with thebuildimgclass.- INITSCRIPT_NAME
The filename of the initialization script as installed to
${sysconfdir}/init.d.This variable is used in recipes when using
update-rc.d.bbclass. The variable is mandatory.- INITSCRIPT_PACKAGES
A list of the packages that contain initscripts. If multiple packages are specified, you need to append the package name to the other
INITSCRIPT_*as an override.This variable is used in recipes when using
update-rc.d.bbclass. The variable is optional and defaults to thePNvariable.- INITSCRIPT_PARAMS
Specifies the options to pass to
update-rc.d. Here is an example:INITSCRIPT_PARAMS = "start 99 5 2 . stop 20 0 1 6 ."In this example, the script has a runlevel of 99, starts the script in initlevels 2 and 5, and stops the script in levels 0, 1 and 6.
The variable is mandatory and is used in recipes when using
update-rc.d.bbclass.- INSANE_SKIP
Specifies the QA checks to skip for a specific package within a recipe. For example, to skip the check for symbolic link
.sofiles in the main package of a recipe, add the following to the recipe. The package name override must be used, which in this example is${PN}:INSANE_SKIP_${PN} += "dev-so"See the "
insane.bbclass" section for a list of the valid QA checks you can specify using this variable.- IPK_FEED_URIS
When the IPK backend is in use and package management is enabled on the target, you can use this variable to set up
opkgin the target image to point to package feeds on a nominated server. Once the feed is established, you can perform installations or upgrades using the package manager at runtime.
K
- KARCH
Defines the kernel architecture used when assembling the configuration. Architectures supported for this release are:
powerpc i386 x86_64 arm qemu mipsYou define the
KARCHvariable in the BSP Descriptions.- KBRANCH
A regular expression used by the build process to explicitly identify the kernel branch that is validated, patched and configured during a build. The
KBRANCHvariable is optional. You can use it to trigger checks to ensure the exact kernel branch you want is being used by the build process.Values for this variable are set in the kernel's recipe file and the kernel's append file. For example, if you are using the Yocto Project kernel that is based on the Linux 3.4 kernel, the kernel recipe file is the
meta/recipes-kernel/linux/linux-yocto_3.4.bbfile. Following is the default value forKBRANCHand the default override for the architectures the Yocto Project supports:KBRANCH_DEFAULT = "standard/base" KBRANCH = "${KBRANCH_DEFAULT}"This branch exists in the
linux-yocto-3.4kernel Git repository http://git.yoctoproject.org/cgit.cgi/linux-yocto-3.4/refs/heads.This variable is also used from the kernel's append file to identify the kernel branch specific to a particular machine or target hardware. The kernel's append file is located in the BSP layer for a given machine. For example, the kernel append file for the Crown Bay BSP is in the
meta-intelGit repository and is namedmeta-crownbay/recipes-kernel/linux/linux-yocto_3.4.bbappend. Here are the related statements from the append file:COMPATIBLE_MACHINE_crownbay = "crownbay" KMACHINE_crownbay = "crownbay" KBRANCH_crownbay = "standard/crownbay" COMPATIBLE_MACHINE_crownbay-noemgd = "crownbay-noemgd" KMACHINE_crownbay-noemgd = "crownbay" KBRANCH_crownbay-noemgd = "standard/crownbay"The
KBRANCH_*statements identify the kernel branch to use when building for the Crown Bay BSP. In this case there are two identical statements: one for each type of Crown Bay machine.- KBRANCH_DEFAULT
Defines the Linux kernel source repository's default branch used to build the Linux kernel. The
KBRANCH_DEFAULTvalue is the default value forKBRANCH. Unless you specify otherwise,KBRANCH_DEFAULTinitializes to "master".- KERNEL_EXTRA_ARGS
Specifies additional
makecommand-line arguments the OpenEmbedded build system passes on when compiling the kernel.- KERNEL_FEATURES
Includes additional metadata from the Yocto Project kernel Git repository. In the OpenEmbedded build system, the default Board Support Packages (BSPs) Metadata is provided through the
KMACHINEandKBRANCHvariables. You can use theKERNEL_FEATURESvariable to further add metadata for all BSPs.The metadata you add through this variable includes config fragments and features descriptions, which usually includes patches as well as config fragments. You typically override the
KERNEL_FEATURESvariable for a specific machine. In this way, you can provide validated, but optional, sets of kernel configurations and features.For example, the following adds
netfilterto all the Yocto Project kernels and adds sound support to theqemux86machine:# Add netfilter to all linux-yocto kernels KERNEL_FEATURES="features/netfilter" # Add sound support to the qemux86 machine KERNEL_FEATURES_append_qemux86=" cfg/sound"- KERNEL_IMAGETYPE
The type of kernel to build for a device, usually set by the machine configuration files and defaults to "zImage". This variable is used when building the kernel and is passed to
makeas the target to build.- KERNEL_PATH
The location of the kernel sources. This variable is set to the value of the
STAGING_KERNEL_DIRwithin themodule.bbclassclass. For information on how this variable is used, see the "Incorporating Out-of-Tree Modules" section.The
KERNEL_SRCvariable is identical to theKERNEL_PATHvariable.- KERNEL_SRC
The location of the kernel sources. This variable is set to the value of the
STAGING_KERNEL_DIRwithin themodule.bbclassclass. For information on how this variable is used, see the "Incorporating Out-of-Tree Modules" section.The
KERNEL_PATHvariable is identical to theKERNEL_SRCvariable.- KFEATURE_DESCRIPTION
Provides a short description of a configuration fragment. You use this variable in the
.sccfile that describes a configuration fragment file. Here is the variable used in a file namedsmp.sccto describe SMP being enabled:define KFEATURE_DESCRIPTION "Enable SMP"- KMACHINE
The machine as known by the kernel. Sometimes the machine name used by the kernel does not match the machine name used by the OpenEmbedded build system. For example, the machine name that the OpenEmbedded build system understands as
qemuarmgoes by a different name in the Linux Yocto kernel. The kernel understands that machine asarm_versatile926ejs. For cases like these, theKMACHINEvariable maps the kernel machine name to the OpenEmbedded build system machine name.Kernel machine names are initially defined in the Yocto Linux Kernel's
metabranch. From themetabranch, look in themeta/cfg/kernel-cache/bsp/<bsp_name>/<bsp-name>-<kernel-type>.sccfile. For example, from themetabranch in thelinux-yocto-3.0kernel, themeta/cfg/kernel-cache/bsp/cedartrail/cedartrail-standard.sccfile has the following:define KMACHINE cedartrail define KTYPE standard define KARCH i386 include ktypes/standard branch cedartrail include cedartrail.sccYou can see that the kernel understands the machine name for the Cedar Trail Board Support Package (BSP) as
cedartrail.If you look in the Cedar Trail BSP layer in the
meta-intelSource Repositories atmeta-cedartrail/recipes-kernel/linux/linux-yocto_3.0.bbappend, you will find the following statements among others:COMPATIBLE_MACHINE_cedartrail = "cedartrail" KMACHINE_cedartrail = "cedartrail" KBRANCH_cedartrail = "yocto/standard/cedartrail" KERNEL_FEATURES_append_cedartrail += "bsp/cedartrail/cedartrail-pvr-merge.scc" KERNEL_FEATURES_append_cedartrail += "cfg/efi-ext.scc" COMPATIBLE_MACHINE_cedartrail-nopvr = "cedartrail" KMACHINE_cedartrail-nopvr = "cedartrail" KBRANCH_cedartrail-nopvr = "yocto/standard/cedartrail" KERNEL_FEATURES_append_cedartrail-nopvr += " cfg/smp.scc"The
KMACHINEstatements in the kernel's append file make sure that the OpenEmbedded build system and the Yocto Linux kernel understand the same machine names.This append file uses two
KMACHINEstatements. The first is not really necessary but does ensure that the machine known to the OpenEmbedded build system ascedartrailmaps to the machine in the kernel also known ascedartrail:KMACHINE_cedartrail = "cedartrail"The second statement is a good example of why the
KMACHINEvariable is needed. In this example, the OpenEmbedded build system uses thecedartrail-nopvrmachine name to refer to the Cedar Trail BSP that does not support the proprietary PowerVR driver. The kernel, however, uses the machine namecedartrail. Thus, the append file must map thecedartrail-nopvrmachine name to the kernel'scedartrailname:KMACHINE_cedartrail-nopvr = "cedartrail"BSPs that ship with the Yocto Project release provide all mappings between the Yocto Project kernel machine names and the OpenEmbedded machine names. Be sure to use the
KMACHINEif you create a BSP and the machine name you use is different than that used in the kernel.- KTYPE
Defines the kernel type to be used in assembling the configuration. The linux-yocto recipes define "standard", "tiny", and "preempt-rt" kernel types. See the "Kernel Types" section in the Yocto Project Linux Kernel Development Manual for more information on kernel types.
You define the
KTYPEvariable in the BSP Descriptions. The value you use must match the value used for theLINUX_KERNEL_TYPEvalue used by the kernel recipe.
L
- LABELS
Provides a list of targets for automatic configuration.
See the
grub-eficlass for more information on how this variable is used.- LAYERDEPENDS
Lists the layers that this recipe depends upon, separated by spaces. Optionally, you can specify a specific layer version for a dependency by adding it to the end of the layer name with a colon, (e.g. "anotherlayer:3" to be compared against
LAYERVERSION_anotherlayerin this case). An error will be produced if any dependency is missing or the version numbers do not match exactly (if specified). This variable is used in theconf/layer.conffile and must be suffixed with the name of the specific layer (e.g.LAYERDEPENDS_mylayer).- LAYERDIR
When used inside the
layer.confconfiguration file, this variable provides the path of the current layer. This variable is not available outside oflayer.confand references are expanded immediately when parsing of the file completes.- LAYERVERSION
Optionally specifies the version of a layer as a single number. You can use this within
LAYERDEPENDSfor another layer in order to depend on a specific version of the layer. This variable is used in theconf/layer.conffile and must be suffixed with the name of the specific layer (e.g.LAYERVERSION_mylayer).- LEAD_SONAME
Specifies the lead (or primary) compiled library file (
.so) that thedebianclass applies its naming policy to given a recipe that packages multiple libraries.This variable works in conjunction with the
debianclass.- LIC_FILES_CHKSUM
Checksums of the license text in the recipe source code.
This variable tracks changes in license text of the source code files. If the license text is changed, it will trigger a build failure, which gives the developer an opportunity to review any license change.
This variable must be defined for all recipes (unless
LICENSEis set to "CLOSED")For more information, see the Tracking License Changes section
- LICENSE
The list of source licenses for the recipe. Follow these rules:
Do not use spaces within individual license names.
Separate license names using | (pipe) when there is a choice between licenses.
Separate license names using & (ampersand) when multiple licenses exist that cover different parts of the source.
You can use spaces between license names.
Here are some examples:
LICENSE = "LGPLv2.1 | GPLv3" LICENSE = "MPL-1 & LGPLv2.1" LICENSE = "GPLv2+"The first example is from the recipes for Qt, which the user may choose to distribute under either the LGPL version 2.1 or GPL version 3. The second example is from Cairo where two licenses cover different parts of the source code. The final example is from
sysstat, which presents a single license.You can also specify licenses on a per-package basis to handle situations where components of the output have different licenses. For example, a piece of software whose code is licensed under GPLv2 but has accompanying documentation licensed under the GNU Free Documentation License 1.2 could be specified as follows:
LICENSE = "GFDL-1.2 & GPLv2" LICENSE_${PN} = "GPLv2" LICENSE_${PN}-doc = "GFDL-1.2"- LICENSE_PATH
Path to additional licenses used during the build. By default, the OpenEmbedded build system uses
COMMON_LICENSE_DIRto define the directory that holds common license text used during the build. TheLICENSE_PATHvariable allows you to extend that location to other areas that have additional licenses:LICENSE_PATH += "/path/to/additional/common/licenses"- LINUX_KERNEL_TYPE
Defines the kernel type to be used in assembling the configuration. The linux-yocto recipes define "standard", "tiny", and "preempt-rt" kernel types. See the "Kernel Types" section in the Yocto Project Linux Kernel Development Manual for more information on kernel types.
If you do not specify a
LINUX_KERNEL_TYPE, it defaults to "standard". Together withKMACHINE, theLINUX_KERNEL_TYPEvariable defines the search arguments used by the kernel tools to find the appropriate description within the kernel Metadata with which to build out the sources and configuration.- LINUX_VERSION
The Linux version from
kernel.orgon which the Linux kernel image being built using the OpenEmbedded build system is based. You define this variable in the kernel recipe. For example, thelinux-yocto-3.4.bbkernel recipe found inmeta/recipes-kernel/linuxdefines the variables as follows:LINUX_VERSION ?= "3.4.24"The
LINUX_VERSIONvariable is used to definePVfor the recipe:PV = "${LINUX_VERSION}+git${SRCPV}"- LINUX_VERSION_EXTENSION
A string extension compiled into the version string of the Linux kernel built with the OpenEmbedded build system. You define this variable in the kernel recipe. For example, the linux-yocto kernel recipes all define the variable as follows:
LINUX_VERSION_EXTENSION ?= "-yocto-${LINUX_KERNEL_TYPE}"Defining this variable essentially sets the Linux kernel configuration item
CONFIG_LOCALVERSION, which is visible through theunamecommand. Here is an example that shows the extension assuming it was set as previously shown:$ uname -r 3.7.0-rc8-custom- LOG_DIR
Specifies the directory to which the OpenEmbedded build system writes overall log files. The default directory is
${TMPDIR}/log.For the directory containing logs specific to each task, see the
Tvariable.
M
- MACHINE
Specifies the target device for which the image is built. You define
MACHINEin thelocal.conffile found in the Build Directory. By default,MACHINEis set to "qemux86", which is an x86-based architecture machine to be emulated using QEMU:MACHINE ?= "qemux86"The variable corresponds to a machine configuration file of the same name, through which machine-specific configurations are set. Thus, when
MACHINEis set to "qemux86" there exists the correspondingqemux86.confmachine configuration file, which can be found in the Source Directory inmeta/conf/machine.The list of machines supported by the Yocto Project as shipped include the following:
MACHINE ?= "qemuarm" MACHINE ?= "qemumips" MACHINE ?= "qemuppc" MACHINE ?= "qemux86" MACHINE ?= "qemux86-64" MACHINE ?= "genericx86" MACHINE ?= "genericx86-64" MACHINE ?= "beagleboard" MACHINE ?= "mpc8315e-rdb" MACHINE ?= "routerstationpro"The last five are Yocto Project reference hardware boards, which are provided in the
meta-yocto-bsplayer.Note
Adding additional Board Support Package (BSP) layers to your configuration adds new possible settings forMACHINE.- MACHINE_ESSENTIAL_EXTRA_RDEPENDS
A list of required machine-specific packages to install as part of the image being built. The build process depends on these packages being present. Furthermore, because this is a "machine essential" variable, the list of packages are essential for the machine to boot. The impact of this variable affects images based on
packagegroup-core-boot, including thecore-image-minimalimage.This variable is similar to the
MACHINE_ESSENTIAL_EXTRA_RRECOMMENDSvariable with the exception that the image being built has a build dependency on the variable's list of packages. In other words, the image will not build if a file in this list is not found.As an example, suppose the machine for which you are building requires
example-initto be run during boot to initialize the hardware. In this case, you would use the following in the machine's.confconfiguration file:MACHINE_ESSENTIAL_EXTRA_RDEPENDS += "example-init"- MACHINE_ESSENTIAL_EXTRA_RRECOMMENDS
A list of recommended machine-specific packages to install as part of the image being built. The build process does not depend on these packages being present. However, because this is a "machine essential" variable, the list of packages are essential for the machine to boot. The impact of this variable affects images based on
packagegroup-core-boot, including thecore-image-minimalimage.This variable is similar to the
MACHINE_ESSENTIAL_EXTRA_RDEPENDSvariable with the exception that the image being built does not have a build dependency on the variable's list of packages. In other words, the image will still build if a package in this list is not found. Typically, this variable is used to handle essential kernel modules, whose functionality may be selected to be built into the kernel rather than as a module, in which case a package will not be produced.Consider an example where you have a custom kernel where a specific touchscreen driver is required for the machine to be usable. However, the driver can be built as a module or into the kernel depending on the kernel configuration. If the driver is built as a module, you want it to be installed. But, when the driver is built into the kernel, you still want the build to succeed. This variable sets up a "recommends" relationship so that in the latter case, the build will not fail due to the missing package. To accomplish this, assuming the package for the module was called
kernel-module-ab123, you would use the following in the machine's.confconfiguration file:MACHINE_ESSENTIAL_EXTRA_RRECOMMENDS += "kernel-module-ab123"Some examples of these machine essentials are flash, screen, keyboard, mouse, or touchscreen drivers (depending on the machine).
- MACHINE_EXTRA_RDEPENDS
A list of machine-specific packages to install as part of the image being built that are not essential for the machine to boot. However, the build process for more fully-featured images depends on the packages being present.
This variable affects all images based on
packagegroup-base, which does not include thecore-image-minimalorcore-image-basicimages.The variable is similar to the
MACHINE_EXTRA_RRECOMMENDSvariable with the exception that the image being built has a build dependency on the variable's list of packages. In other words, the image will not build if a file in this list is not found.An example is a machine that has WiFi capability but is not essential for the machine to boot the image. However, if you are building a more fully-featured image, you want to enable the WiFi. The package containing the firmware for the WiFi hardware is always expected to exist, so it is acceptable for the build process to depend upon finding the package. In this case, assuming the package for the firmware was called
wifidriver-firmware, you would use the following in the.conffile for the machine:MACHINE_EXTRA_RDEPENDS += "wifidriver-firmware"- MACHINE_EXTRA_RRECOMMENDS
A list of machine-specific packages to install as part of the image being built that are not essential for booting the machine. The image being built has no build dependency on this list of packages.
This variable affects only images based on
packagegroup-base, which does not include thecore-image-minimalorcore-image-basicimages.This variable is similar to the
MACHINE_EXTRA_RDEPENDSvariable with the exception that the image being built does not have a build dependency on the variable's list of packages. In other words, the image will build if a file in this list is not found.An example is a machine that has WiFi capability but is not essential For the machine to boot the image. However, if you are building a more fully-featured image, you want to enable WiFi. In this case, the package containing the WiFi kernel module will not be produced if the WiFi driver is built into the kernel, in which case you still want the build to succeed instead of failing as a result of the package not being found. To accomplish this, assuming the package for the module was called
kernel-module-examplewifi, you would use the following in the.conffile for the machine:MACHINE_EXTRA_RRECOMMENDS += "kernel-module-examplewifi"- MACHINE_FEATURES
Specifies the list of hardware features the
MACHINEis capable of supporting. For related information on enabling features, see theDISTRO_FEATURES,COMBINED_FEATURES, andIMAGE_FEATURESvariables.For a list of hardware features supported by the Yocto Project as shipped, see the "Machine Features" section.
- MACHINE_FEATURES_BACKFILL
Features to be added to
MACHINE_FEATURESif not also present inMACHINE_FEATURES_BACKFILL_CONSIDERED.This variable is set in the
meta/conf/bitbake.conffile. It is not intended to be user-configurable. It is best to just reference the variable to see which machine features are being backfilled for all machine configurations. See the "Feature backfilling" section for more information.- MACHINE_FEATURES_BACKFILL_CONSIDERED
Features from
MACHINE_FEATURES_BACKFILLthat should not be backfilled (i.e. added toMACHINE_FEATURES) during the build. See the "Feature backfilling" section for more information.- MACHINEOVERRIDES
Lists overrides specific to the current machine. By default, this list includes the value of
MACHINE. You can extend the list to apply variable overrides for classes of machines. For example, all QEMU emulated machines (e.g. qemuarm, qemux86, and so forth) include a common file namedmeta/conf/machine/include/qemu.incthat prependsMACHINEOVERRIDESwith the following variable override:MACHINEOVERRIDES =. "qemuall:"Applying an override like
qemuallaffects all QEMU emulated machines elsewhere. Here is an example from theconnman-confrecipe:SRC_URI_append_qemuall = "file://wired.config \ file://wired-setup \ "- MAINTAINER
The email address of the distribution maintainer.
- MIRRORS
Specifies additional paths from which the OpenEmbedded build system gets source code. When the build system searches for source code, it first tries the local download directory. If that location fails, the build system tries locations defined by
PREMIRRORS, the upstream source, and then locations specified byMIRRORSin that order.Assuming your distribution (
DISTRO) is "poky", the default value forMIRRORSis defined in theconf/distro/poky.conffile in themeta-yoctoGit repository.- MLPREFIX
Specifies a prefix has been added to
PNto create a special version of a recipe or package, such as a Multilib version. The variable is used in places where the prefix needs to be added to or removed from a the name (e.g. theBPNvariable).MLPREFIXgets set when a prefix has been added toPN.- MODULE_TARBALL_DEPLOY
Controls creation of the
modules-*.tgzfile. Set this variable to "0" to disable creation of this file, which contains all of the kernel modules resulting from a kernel build.- MULTIMACH_TARGET_SYS
Separates files for different machines such that you can build for multiple target machines using the same output directories. See the
STAMPvariable for an example.
N
- NATIVELSBSTRING
A string identifying the host distribution. Strings consist of the host distributor ID followed by the release, as reported by the
lsb_releasetool or as read from/etc/lsb-release. For example, when running a build on Ubuntu 12.10, the value is "Ubuntu-12.10". If this information is unable to be determined, the value resolves to "Unknown".This variable is used by default to isolate native shared state packages for different distributions (e.g. to avoid problems with
glibcversion incompatibilities). Additionally, the variable is checked againstSANITY_TESTED_DISTROSif that variable is set.- NO_RECOMMENDATIONS
Prevents installation of all "recommended-only" packages. Recommended-only packages are packages installed only through the
RRECOMMENDSvariable). Setting theNO_RECOMMENDATIONSvariable to "1" turns this feature on:NO_RECOMMENDATIONS = "1"You can set this variable globally in your
local.conffile or you can attach it to a specific image recipe by using the recipe name override:NO_RECOMMENDATIONS_pn-<target_image> = "<package_name>"It is important to realize that if you choose to not install packages using this variable and some other packages are dependent on them (i.e. listed in a recipe's
RDEPENDSvariable), the OpenEmbedded build system ignores your request and will install the packages to avoid dependency errors.Note
Some recommended packages might be required for certain system functionality, such as kernel modules. It is up to you to add packages with theIMAGE_INSTALLvariable.Support for this variable exists only when using the IPK and RPM packaging backend. Support does not exist for DEB.
See the
BAD_RECOMMENDATIONSand thePACKAGE_EXCLUDEvariables for related information.- NOHDD
Causes the OpenEmbedded build system to skip building the
.hddimgimage. TheNOHDDvariable is used with thebuildimgclass. Set the variable to "1" to prevent the.hddimgimage from being built.- NOISO
Causes the OpenEmbedded build system to skip building the ISO image. The
NOISOvariable is used with thebuildimgclass. Set the variable to "1" to prevent the ISO image from being built.
O
- OE_BINCONFIG_EXTRA_MANGLE
When a recipe inherits the
binconfig.bbclassclass, this variable specifies additional arguments passed to the "sed" command. The sed command alters any paths in configuration scripts that have been set up during compilation. Inheriting this class results in all paths in these scripts being changed to point into thesysroots/directory so that all builds that use the script will use the correct directories for the cross compiling layout.See the
meta/classes/binconfig.bbclassin the Source Directory for details on how this class applies these additional sed command arguments. For general information on thebinconfig.bbclassclass, see the "Binary Configuration Scripts -binconfig.bbclass" section.- OE_IMPORTS
An internal variable used to tell the OpenEmbedded build system what Python modules to import for every Python function run by the system.
Note
Do not set this variable. It is for internal use only.- OE_TERMINAL
Controls how the OpenEmbedded build system spawns interactive terminals on the host development system (e.g. using the BitBake command with the
-c devshellcommand-line option). For more information, see the "Using a Development Shell" section in the Yocto Project Development Manual.You can use the following values for the
OE_TERMINALvariable:auto gnome xfce rxvt screen konsole noneNote
Konsole support only works for KDE 3.x. Also, "auto" is the default behavior forOE_TERMINAL- OEROOT
The directory from which the top-level build environment setup script is sourced. The Yocto Project makes two top-level build environment setup scripts available:
oe-init-build-envandoe-init-build-env-memres. When you run one of these scripts, theOEROOTvariable resolves to the directory that holds the script.For additional information on how this variable is used, see the initialization scripts.
- OLDEST_KERNEL
Declares the oldest version of the Linux kernel that the produced binaries must support. This variable is passed into the build of the Embedded GNU C Library (
eglibc).The default for this variable comes from the
meta/conf/bitbake.confconfiguration file. You can override this default by setting the variable in a custom distribution configuration file.- OVERRIDES
BitBake uses
OVERRIDESto control what variables are overridden after BitBake parses recipes and configuration files. You can find more information on how overrides are handled in the BitBake Manual that is located atbitbake/doc/manualin the Source Directory.
P
- P
The recipe name and version.
Pis comprised of the following:${PN}-${PV}- PACKAGE_ARCH
The architecture of the resulting package or packages.
- PACKAGE_BEFORE_PN
Enables easily adding packages to
PACKAGESbefore${PN}so that those added packages can pick up files that would normally be included in the default package.- PACKAGE_CLASSES
This variable, which is set in the
local.confconfiguration file found in theconffolder of the Build Directory, specifies the package manager the OpenEmbedded build system uses when packaging data.You can provide one or more of the following arguments for the variable:
PACKAGE_CLASSES ?= "package_rpm package_deb package_ipk package_tar"The build system uses only the first argument in the list as the package manager when creating your image or SDK. However, packages will be created using any additional packaging classes you specify. For example, if you use the following in your
local.conffile:PACKAGE_CLASSES ?= "package_ipk package_tar"The OpenEmbedded build system uses the IPK package manager to create your image or SDK as well as generating TAR packages.
You cannot specify the
package_tarclass first in the list. Files using the.tarformat cannot be used as a substitute packaging format for DEB, RPM, and IPK formatted files for your image or SDK.For information on packaging and build performance effects as a result of the package manager in use, see the "
package.bbclass" section.- PACKAGE_EXCLUDE
Lists packages that should not be installed into an image. For example:
PACKAGE_EXCLUDE = "<package_name> <package_name> <package_name> ..."You can set this variable globally in your
local.conffile or you can attach it to a specific image recipe by using the recipe name override:PACKAGE_EXCLUDE_pn-<target_image> = "<package_name>"If you choose to not install a package using this variable and some other package is dependent on it (i.e. listed in a recipe's
RDEPENDSvariable), the OpenEmbedded build system generates a fatal installation error. Because the build system halts the process with a fatal error, you can use the variable with an iterative development process to remove specific components from a system.Support for this variable exists only when using the IPK and RPM packaging backend. Support does not exist for DEB.
See the
NO_RECOMMENDATIONSand theBAD_RECOMMENDATIONSvariables for related information.- PACKAGE_EXTRA_ARCHS
Specifies the list of architectures compatible with the device CPU. This variable is useful when you build for several different devices that use miscellaneous processors such as XScale and ARM926-EJS).
- PACKAGE_GROUP
Defines one or more packages to include in an image when a specific item is included in
IMAGE_FEATURES. When setting the value,PACKAGE_GROUPshould have the name of the feature item as an override. Here is an example:PACKAGE_GROUP_widget = "package1 package2"In this example, if "widget" were added to
IMAGE_FEATURES, "package1" and "package2" would be included in the image.Note
Packages installed by features defined throughPACKAGE_GROUPare often package groups. While similarly named, you should not confuse thePACKAGE_GROUPvariable with package groups, which are discussed elsewhere in the documentation.- PACKAGE_INSTALL
The final list of packages passed to the package manager for installation into the image. Because the package manager controls actual installation of all packages, the list of packages passed using
PACKAGE_INSTALLis not the final list of packages that are actually installed.This variable is internal to the image construction code. Use the
IMAGE_INSTALLvariable to specify packages for installation.- PACKAGECONFIG
This variable provides a means of enabling or disabling features of a recipe on a per-recipe basis.
PACKAGECONFIGblocks are defined in recipes when you specify features and then arguments that define feature behaviors. Here is the basic block structure:PACKAGECONFIG ??= "f1 f2 f3 ..." PACKAGECONFIG[f1] = "--with-f1,--without-f1,build-deps-f1,rt-deps-f1" PACKAGECONFIG[f2] = "--with-f2,--without-f2,build-deps-f2,rt-deps-f2" PACKAGECONFIG[f3] = "--with-f3,--without-f3,build-deps-f3,rt-deps-f3"The
PACKAGECONFIGvariable itself specifies a space-separated list of the features to enable. Following the features, you can determine the behavior of each feature by providing up to four order-dependent arguments, which are separated by commas. You can omit any argument you like but must retain the separating commas. The order is important and specifies the following:Extra arguments that should be added to the configure script argument list (
EXTRA_OECONF) if the feature is enabled.Extra arguments that should be added to
EXTRA_OECONFif the feature is disabled.Additional build dependencies (
DEPENDS) that should be added if the feature is enabled.Additional runtime dependencies (
RDEPENDS) that should be added if the feature is enabled.
Consider the following
PACKAGECONFIGblock taken from thelibrsvgrecipe. In this example the feature iscroco, which has three arguments that determine the feature's behavior.PACKAGECONFIG ??= "croco" PACKAGECONFIG[croco] = "--with-croco,--without-croco,libcroco"The
--with-crocoandlibcrocoarguments apply only if the feature is enabled. In this case,--with-crocois added to the configure script argument list andlibcrocois added toDEPENDS. On the other hand, if the feature is disabled say through a.bbappendfile in another layer, then the second argument--without-crocois added to the configure script rather than--with-croco.The basic
PACKAGECONFIGstructure previously described holds true regardless of whether you are creating a block or changing a block. When creating a block, use the structure inside your recipe.If you want to change an existing
PACKAGECONFIGblock, you can do so one of two ways:Append file: Create an append file named
<recipename>.bbappendin your layer and override the value ofPACKAGECONFIG. You can either completely override the variable:PACKAGECONFIG="f4 f5"Or, you can just append the variable:
PACKAGECONFIG_append = " f4"Configuration file: This method is identical to changing the block through an append file except you edit your
local.confor<mydistro>.conffile. As with append files previously described, you can either completely override the variable:PACKAGECONFIG_pn-<recipename>="f4 f5"Or, you can just amend the variable:
PACKAGECONFIG_append_pn-<recipename> = " f4"
- PACKAGES
The list of packages to be created from the recipe. The default value is the following:
${PN}-dbg ${PN}-staticdev ${PN}-dev ${PN}-doc ${PN}-locale ${PACKAGE_BEFORE_PN} ${PN}- PACKAGES_DYNAMIC
A promise that your recipe satisfies runtime dependencies for optional modules that are found in other recipes.
PACKAGES_DYNAMICdoes not actually satisfy the dependencies, it only states that they should be satisfied. For example, if a hard, runtime dependency (RDEPENDS) of another package is satisfied at build time through thePACKAGES_DYNAMICvariable, but a package with the module name is never actually produced, then the other package will be broken. Thus, if you attempt to include that package in an image, you will get a dependency failure from the packaging system duringdo_rootfs.Typically, if there is a chance that such a situation can occur and the package that is not created is valid without the dependency being satisfied, then you should use
RRECOMMENDS(a soft runtime dependency) instead ofRDEPENDS.For an example of how to use the
PACKAGES_DYNAMICvariable when you are splitting packages, see the "Handling Optional Module Packaging" section in the Yocto Project Development Manual.- PARALLEL_MAKE
Extra options that are passed to the
makecommand during thedo_compiletask in order to specify parallel compilation. This variable is usually in the form-j 4, where the number represents the maximum number of parallel threads make can run. If you development host supports multiple cores a good rule of thumb is to set this variable to twice the number of cores on the host.Note
Individual recipes might clear out this variable if the software being built has problems running itsmakeprocess in parallel.- PARALLEL_MAKEINST
Extra options passed to the
make installcommand during thedo_installtask in order to specify parallel installation. This variable defaults to the value ofPARALLEL_MAKE.Note
Individual recipes might clear out this variable if the software being built has problems running itsmake installprocess in parallel.- PATCHRESOLVE
Determines the action to take when a patch fails. You can set this variable to one of two values: "noop" and "user".
The default value of "noop" causes the build to simply fail when the OpenEmbedded build system cannot successfully apply a patch. Setting the value to "user" causes the build system to launch a shell and places you in the right location so that you can manually resolve the conflicts.
Set this variable in your
local.conffile.- PATCHTOOL
Specifies the utility used to apply patches for a recipe during
do_patch. You can specify one of three utilities: "patch", "quilt", or "git". The default utility used is "quilt" except for the quilt-native recipe itself. Because the quilt tool is not available at the time quilt-native is being patched, it uses "patch".If you wish to use an alternative patching tool, set the variable in the recipe using one of the following:
PATCHTOOL = "patch" PATCHTOOL = "quilt" PATCHTOOL = "git"- PE
the epoch of the recipe. By default, this variable is unset. The field is used to make upgrades possible when the versioning scheme changes in some backwards incompatible way.
- PF
Specifies the recipe or package name and includes all version and revision numbers (i.e.
eglibc-2.13-r20+svnr15508/andbash-4.2-r1/). This variable is comprised of the following:${PN}-${EXTENDPE}${PV}-${PR}- PIXBUF_PACKAGES
When a recipe inherits the
pixbufcacheclass, this variable identifies packages that contain the pixbuf loaders used withgdk-pixbuf. By default, thepixbufcacheclass assumes that the loaders are in the recipe's main package (i.e.${PN}). Use this variable if the loaders you need are in a package other than that main package.- PKGD
Points to the destination directory for files to be packaged before they are split into individual packages. This directory defaults to the following:
${WORKDIR}/packageDo not change this default.
- PKGDATA_DIR
Points to a shared, global-state directory that holds data generated during the packaging process. During the packaging process, the
do_packagedatatask packages data for each recipe and installs it into this temporary, shared area. This directory defaults to the following:${STAGING_DIR_HOST}/pkgdataDo not change this default.
- PKGDEST
Points to the parent directory for files to be packaged after they have been split into individual packages. This directory defaults to the following:
${WORKDIR}/packages-splitUnder this directory, the build system creates directories for each package specified in
PACKAGES. Do not change this default.- PKGDESTWORK
Points to a temporary work area used by the
do_packagetask to write output from thedo_packagedatatask. ThePKGDESTWORKlocation defaults to the following:${WORKDIR}/pkgdataThe
do_packagedatatask then packages the data in the temporary work area and installs it into a shared directory pointed to byPKGDATA_DIR.Do not change this default.
- PN
This variable can have two separate functions depending on the context: a recipe name or a resulting package name.
PNrefers to a recipe name in the context of a file used by the OpenEmbedded build system as input to create a package. The name is normally extracted from the recipe file name. For example, if the recipe is namedexpat_2.0.1.bb, then the default value ofPNwill be "expat".The variable refers to a package name in the context of a file created or produced by the OpenEmbedded build system.
If applicable, the
PNvariable also contains any special suffix or prefix. For example, usingbashto build packages for the native machine,PNisbash-native. Usingbashto build packages for the target and for Multilib,PNwould bebashandlib64-bash, respectively.- PNBLACKLIST
Lists recipes you do not want the OpenEmbedded build system to build. This variable works in conjunction with the
blacklistclass, which the recipe must inherit globally.To prevent a recipe from being built, inherit the class globally and use the variable in your
local.conffile. Here is an example that preventsmyrecipefrom being built:INHERIT += "blacklist" PNBLACKLIST[myrecipe] = "Not supported by our organization."- PR
The revision of the recipe. The default value for this variable is "r0".
- PREFERRED_PROVIDER
If multiple recipes provide an item, this variable determines which recipe should be given preference. You should always suffix the variable with the name of the provided item, and you should set it to the
PNof the recipe to which you want to give precedence. Some examples:PREFERRED_PROVIDER_virtual/kernel ?= "linux-yocto" PREFERRED_PROVIDER_virtual/xserver = "xserver-xf86" PREFERRED_PROVIDER_virtual/libgl ?= "mesa"- PREFERRED_VERSION
If there are multiple versions of recipes available, this variable determines which recipe should be given preference. You must always suffix the variable with the
PNyou want to select, and you should set thePVaccordingly for precedence. You can use the "%" character as a wildcard to match any number of characters, which can be useful when specifying versions that contain long revision numbers that could potentially change. Here are two examples:PREFERRED_VERSION_python = "2.7.3" PREFERRED_VERSION_linux-yocto = "3.10%"- PREMIRRORS
Specifies additional paths from which the OpenEmbedded build system gets source code. When the build system searches for source code, it first tries the local download directory. If that location fails, the build system tries locations defined by
PREMIRRORS, the upstream source, and then locations specified byMIRRORSin that order.Assuming your distribution (
DISTRO) is "poky", the default value forPREMIRRORSis defined in theconf/distro/poky.conffile in themeta-yoctoGit repository.Typically, you could add a specific server for the build system to attempt before any others by adding something like the following to the
local.confconfiguration file in the Build Directory:PREMIRRORS_prepend = "\ git://.*/.* http://www.yoctoproject.org/sources/ \n \ ftp://.*/.* http://www.yoctoproject.org/sources/ \n \ http://.*/.* http://www.yoctoproject.org/sources/ \n \ https://.*/.* http://www.yoctoproject.org/sources/ \n"These changes cause the build system to intercept Git, FTP, HTTP, and HTTPS requests and direct them to the
http://sources mirror. You can usefile://URLs to point to local directories or network shares as well.- PRINC
Causes the
PRvariable of.bbappendfiles to dynamically increment. This increment minimizes the impact of layer ordering.In order to ensure multiple
.bbappendfiles can co-exist,PRINCshould be self-referencing. This variable defaults to 0.Following is an example that increments
PRby two:PRINC := "${@int(PRINC) + 2}"It is advisable not to use strings such as ".= '.1'" with the variable because this usage is very sensitive to layer ordering. You should avoid explicit assignments as they cannot adequately represent multiple
.bbappendfiles.- PROVIDES
A list of aliases that a recipe also provides. These aliases are useful for satisfying dependencies of other recipes during the build (as specified by
DEPENDS).- PRSERV_HOST
The network based
PRservice host and port.The
conf/local.conf.sample.extendedconfiguration file in the Source Directory shows how thePRSERV_HOSTvariable is set:PRSERV_HOST = "localhost:0"You must set the variable if you want to automatically start a local PR service. You can set
PRSERV_HOSTto other values to use a remote PR service.- PV
The version of the recipe. The version is normally extracted from the recipe filename. For example, if the recipe is named
expat_2.0.1.bb, then the default value ofPVwill be "2.0.1".PVis generally not overridden within a recipe unless it is building an unstable (i.e. development) version from a source code repository (e.g. Git or Subversion).
Q
- QMAKE_PROFILES
Specifies your own subset of
.profiles to be built for use withqmake. If you do not set this variable, all.profiles in the directory pointed to bySwill be built by default.This variable is used with recipes that inherit the
qmake_baseclass or other classes that inheritqmake_base.
R
- RCONFLICTS
The list of packages that conflict with packages. Note that packages will not be installed if conflicting packages are not first removed.
Like all package-controlling variables, you must always use them in conjunction with a package name override. Here is an example:
RCONFLICTS_${PN} = "another-conflicting-package-name"BitBake, which the OpenEmbedded build system uses, supports specifying versioned dependencies. Although the syntax varies depending on the packaging format, BitBake hides these differences from you. Here is the general syntax to specify versions with the
RCONFLICTSvariable:RCONFLICTS_${PN} = "<package> (<operator> <version>)"For
operator, you can specify the following:= < > <= >=For example, the following sets up a dependency on version 1.2 or greater of the package
foo:RCONFLICTS_${PN} = "foo (>= 1.2)"- RDEPENDS
Lists a package's runtime dependencies (i.e. other packages) that must be installed in order for the built package to run correctly. If a package in this list cannot be found during the build, you will get a build error.
When you use the
RDEPENDSvariable in a recipe, you are essentially stating that the recipe'sdo_buildtask depends on the existence of a specific package. Consider this simple example for two recipes named "a" and "b" that produce similarly named packages. In this example, theRDEPENDSstatement appears in the "a" recipe:RDEPENDS_${PN} = "b"Here, the dependency is such that the
do_buildtask for recipe "a" depends on thedo_package_writetask of recipe "b". This means the package file for "b" must be available when the output for recipe "a" has been completely built. More importantly, package "a" will be marked as depending on package "b" in a manner that is understood by the package manager in use (i.e. rpm, opkg, or dpkg).The names of the packages you list within
RDEPENDSmust be the names of other packages - they cannot be recipe names. Although package names and recipe names usually match, the important point here is that you are providing package names within theRDEPENDSvariable. For an example of the default list of packages created from a recipe, see thePACKAGESvariable.Because the
RDEPENDSvariable applies to packages being built, you should always use the variable in a form with an attached package name. For example, suppose you are building a development package that depends on theperlpackage. In this case, you would use the followingRDEPENDSstatement:RDEPENDS_${PN}-dev += "perl"In the example, the development package depends on the
perlpackage. Thus, theRDEPENDSvariable has the${PN}-devpackage name as part of the variable.The package name you attach to the
RDEPENDSvariable must appear as it would in thePACKAGESnamespace before any renaming of the output package by classes likedebian.bbclass.In many cases you do not need to explicitly add runtime dependencies using
RDEPENDSsince some automatic handling occurs:shlibdeps: If a runtime package contains a shared library (.so), the build processes the library in order to determine other libraries to which it is dynamically linked. The build process adds these libraries toRDEPENDSwhen creating the runtime package.pcdeps: If the package ships apkg-configinformation file, the build process uses this file to add items to theRDEPENDSvariable to create the runtime packages.
BitBake, which the OpenEmbedded build system uses, supports specifying versioned dependencies. Although the syntax varies depending on the packaging format, BitBake hides these differences from you. Here is the general syntax to specify versions with the
RDEPENDSvariable:RDEPENDS_${PN} = "<package> (<operator> <version>)"For
operator, you can specify the following:= < > <= >=For example, the following sets up a dependency on version 1.2 or greater of the package
foo:RDEPENDS_${PN} = "foo (>= 1.2)"For information on build-time dependencies, see the
DEPENDSvariable.- REQUIRED_DISTRO_FEATURES
When a recipe inherits the
distro_features_checkclass, this variable identifies distribution features that must exist in the current configuration in order for the OpenEmbedded build system to build the recipe. In other words, if theREQUIRED_DISTRO_FEATURESvariable lists a feature that does not appear inDISTRO_FEATURESwithin the current configuration, an error occurs and the build stops.- RM_OLD_IMAGE
Reclaims disk space by removing previously built versions of the same image from the
imagesdirectory pointed to by theDEPLOY_DIRvariable.Set this variable to "1" in your
local.conffile to remove these images.- RM_WORK_EXCLUDE
With
rm_workenabled, this variable specifies a list of recipes whose work directories should not be removed. See the "rm_work.bbclass" section for more details.- ROOTFS
Indicates a filesystem image to include as the root filesystem.
The
ROOTFSvariable is an optional variable used with thebuildimgclass.- ROOTFS_POSTPROCESS_COMMAND
Added by classes to run post processing commands once the OpenEmbedded build system has created the root filesystem. You can specify shell commands separated by semicolons:
ROOTFS_POSTPROCESS_COMMAND += "<shell_command>; ... "If you need to pass the path to the root filesystem within the command, you can use
${IMAGE_ROOTFS}, which points to the root filesystem image.- RPROVIDES
A list of package name aliases that a package also provides. These aliases are useful for satisfying runtime dependencies of other packages both during the build and on the target (as specified by
RDEPENDS).Note
A package's own name is implicitly already in itsRPROVIDESlist.As with all package-controlling variables, you must always use the variable in conjunction with a package name override. Here is an example:
RPROVIDES_${PN} = "widget-abi-2"- RRECOMMENDS
A list of packages that extends the usability of a package being built. The package being built does not depend on this list of packages in order to successfully build, but needs them for the extended usability. To specify runtime dependencies for packages, see the
RDEPENDSvariable.The OpenEmbedded build process automatically installs the list of packages as part of the built package. However, you can remove these packages later if you want. If, during the build, a package from the
RRECOMMENDSlist cannot be found, the build process continues without an error.You can also prevent packages in the list from being installed by using several variables. See the
BAD_RECOMMENDATIONS,NO_RECOMMENDATIONS, andPACKAGE_EXCLUDEvariables for more information.Because the
RRECOMMENDSvariable applies to packages being built, you should always attach an override to the variable to specify the particular package whose usability is being extended. For example, suppose you are building a development package that is extended to support wireless functionality. In this case, you would use the following:RRECOMMENDS_${PN}-dev += "<wireless_package_name>"In the example, the package name (
${PN}-dev) must appear as it would in thePACKAGESnamespace before any renaming of the output package by classes such asdebian.bbclass.BitBake, which the OpenEmbedded build system uses, supports specifying versioned recommends. Although the syntax varies depending on the packaging format, BitBake hides these differences from you. Here is the general syntax to specify versions with the
RRECOMMENDSvariable:RRECOMMENDS_${PN} = "<package> (<operator> <version>)"For
operator, you can specify the following:= < > <= >=For example, the following sets up a recommend on version 1.2 or greater of the package
foo:RRECOMMENDS_${PN} = "foo (>= 1.2)"- RREPLACES
A list of packages replaced by a package. The package manager uses this variable to determine which package should be installed to replace other package(s) during an upgrade. In order to also have the other package(s) removed at the same time, you must add the name of the other package to the
RCONFLICTSvariable.As with all package-controlling variables, you must use this variable in conjunction with a package name override. Here is an example:
RREPLACES_${PN} = "other-package-being-replaced"BitBake, which the OpenEmbedded build system uses, supports specifying versioned replacements. Although the syntax varies depending on the packaging format, BitBake hides these differences from you. Here is the general syntax to specify versions with the
RREPLACESvariable:RREPLACES_${PN} = "<package> (<operator> <version>)"For
operator, you can specify the following:= < > <= >=For example, the following sets up a replacement using version 1.2 or greater of the package
foo:RREPLACES_${PN} = "foo (>= 1.2)"- RSUGGESTS
A list of additional packages that you can suggest for installation by the package manager at the time a package is installed. Not all package managers support this functionality.
As with all package-controlling variables, you must always use this variable in conjunction with a package name override. Here is an example:
RSUGGESTS_${PN} = "useful-package another-package"
S
- S
The location in the Build Directory where unpacked recipe source code resides. This location is within the work directory (
WORKDIR), which is not static. The unpacked source location depends on the recipe name (PN) and recipe version (PV) as follows:${WORKDIR}/${PN}-${PV}As an example, assume a Source Directory top-level folder named
pokyand a default Build Directory atpoky/build. In this case, the work directory the build system uses to keep the unpacked recipe fordbis the following:poky/build/tmp/work/qemux86-poky-linux/db/5.1.19-r3/db-5.1.19- SANITY_TESTED_DISTROS
A list of the host distribution identifiers that the build system has been tested against. Identifiers consist of the host distributor ID followed by the release, as reported by the
lsb_releasetool or as read from/etc/lsb-release. Separate the list items with explicit newline characters (\n). IfSANITY_TESTED_DISTROSis not empty and the current value ofNATIVELSBSTRINGdoes not appear in the list, then the build system reports a warning that indicates the current host distribution has not been tested as a build host.- SDK_ARCH
The target architecture for the SDK. Typically, you do not directly set this variable. Instead, use
SDKMACHINE.- SDK_DEPLOY
The directory set up and used by the
populate_sdk_baseto which the SDK is deployed. Thepopulate_sdk_baseclass definesSDK_DEPLOYas follows:SDK_DEPLOY = "${TMPDIR}/deploy/sdk"- SDK_DIR
The parent directory used by the OpenEmbedded build system when creating SDK output. The
populate_sdk_baseclass defines the variable as follows:SDK_DIR = "${WORKDIR}/sdk"Note
TheSDK_DIRdirectory is a temporary directory as it is part ofWORKDIR. The final output directory isSDK_DEPLOY.- SDK_NAME
The base name for SDK output files. The name is derived from the
DISTRO,TCLIBC,SDK_ARCH,IMAGE_BASENAME, andTUNE_PKGARCHvariables:SDK_NAME = "${DISTRO}-${TCLIBC}-${SDK_ARCH}-${IMAGE_BASENAME}-${TUNE_PKGARCH}"- SDK_OUTPUT
The location used by the OpenEmbedded build system when creating SDK output. The
populate_sdk_baseclass defines the variable as follows:SDK_OUTPUT = "${SDK_DIR}/image"Note
TheSDK_OUTPUTdirectory is a temporary directory as it is part ofWORKDIRby way ofSDK_DIR. The final output directory isSDK_DEPLOY.- SDKIMAGE_FEATURES
Equivalent to
IMAGE_FEATURES. However, this variable applies to the SDK generated from an image using the following command:$ bitbake -c populate_sdk imagename- SDKMACHINE
The architecture of the machine that runs Application Development Toolkit (ADT) items. In other words, packages are built so that they will run on the target you specify with the argument. This implies that you can build out ADT/SDK items that run on an architecture other than that of your build host. For example, you can use an x86_64-based build host to create packages that will run on an i686-based SDK Machine.
You can use "i686" and "x86_64" as possible values for this variable. The variable defaults to "i686" and is set in the
local.conffile in the Build Directory.SDKMACHINE ?= "i686"- SECTION
The section in which packages should be categorized. Package management utilities can make use of this variable.
- SELECTED_OPTIMIZATION
The variable takes the value of
FULL_OPTIMIZATIONunlessDEBUG_BUILD= "1". In this case the value ofDEBUG_OPTIMIZATIONis used.- SERIAL_CONSOLE
Defines a serial console (TTY) to enable using getty. Provide a value that specifies the baud rate followed by the TTY device name separated by a space. You cannot specify more than one TTY device:
SERIAL_CONSOLE = "115200 ttyS0"- SERIAL_CONSOLES
Defines the serial consoles (TTYs) to enable using getty. Provide a value that specifies the baud rate followed by the TTY device name separated by a semicolon. Use spaces to separate multiple devices:
SERIAL_CONSOLES = "115200;ttyS0 115200;ttyS1"- SERIAL_CONSOLES_CHECK
Similar to
SERIAL_CONSOLESexcept the device is checked for existence before attempting to enable it. This variable is currently only supported with SysVinit (i.e. not with systemd).- SIGGEN_EXCLUDE_SAFE_RECIPE_DEPS
A list of recipe dependencies that should not be used to determine signatures of tasks from one recipe when they depend on tasks from another recipe. For example:
SIGGEN_EXCLUDE_SAFE_RECIPE_DEPS += "intone->mplayer2"In this example,
intonedepends onmplayer2.Use of this variable is one mechanism to remove dependencies that affect task signatures and thus force rebuilds when a recipe changes.
Caution
If you add an inappropriate dependency for a recipe relationship, the software might break during runtime if the interface of the second recipe was changed after the first recipe had been built.- SIGGEN_EXCLUDERECIPES_ABISAFE
A list of recipes that are completely stable and will never change. The ABI for the recipes in the list are presented by output from the tasks run to build the recipe. Use of this variable is one way to remove dependencies from one recipe on another that affect task signatures and thus force rebuilds when the recipe changes.
Caution
If you add an inappropriate variable to this list, the software might break at runtime if the interface of the recipe was changed after the other had been built.- SITEINFO_BITS
Specifies the number of bits for the target system CPU. The value should be either "32" or "64".
- SITEINFO_ENDIANNESS
Specifies the endian byte order of the target system. The value should be either "le" for little-endian or "be" for big-endian.
- SOC_FAMILY
Groups together machines based upon the same family of SOC (System On Chip). You typically set this variable in a common
.incfile that you include in the configuration files of all the machines.Note
You must includeconf/machine/include/soc-family.incfor this variable to appear inMACHINEOVERRIDES.- SOLIBS
Defines the suffix for shared libraries used on the target platform. By default, this suffix is ".so.*" for all Linux-based systems and is defined in the
meta/conf/bitbake.confconfiguration file.You will see this variable referenced in the default values of
FILES_${PN}.- SOLIBSDEV
Defines the suffix for the development symbolic link (symlink) for shared libraries on the target platform. By default, this suffix is ".so" for Linux-based systems and is defined in the
meta/conf/bitbake.confconfiguration file.You will see this variable referenced in the default values of
FILES_${PN}-dev.- SOURCE_MIRROR_URL
Defines your own
PREMIRRORSfrom which to first fetch source before attempting to fetch from the upstream specified inSRC_URI.To use this variable, you must globally inherit the
own-mirrorsclass and then provide the URL to your mirrors. Here is an example:INHERIT += "own-mirrors" SOURCE_MIRROR_URL = "http://example.com/my-source-mirror"Note
You can specify only a single URL inSOURCE_MIRROR_URL.- SPECIAL_PKGSUFFIX
A list of prefixes for
PNused by the OpenEmbedded build system to create variants of recipes or packages. The list specifies the prefixes to strip off during certain circumstances such as the generation of theBPNvariable.- SRC_URI
The list of source files - local or remote. This variable tells the OpenEmbedded build system which bits to pull in for the build and how to pull them in. For example, if the recipe or append file only needs to fetch a tarball from the Internet, the recipe or append file uses a single
SRC_URIentry. On the other hand, if the recipe or append file needs to fetch a tarball, apply two patches, and include a custom file, the recipe or append file would include four instances of the variable.The following list explains the available URI protocols:
file://- Fetches files, which are usually files shipped with the Metadata, from the local machine. The path is relative to theFILESPATHvariable. Thus, the build system searches, in order, from the following directories, which are assumed to be a subdirectories of the directory in which the recipe file (.bb) or append file (.bbappend) resides:${BPN}- The base recipe name without any special suffix or version numbers.${BP}-${BPN}-${PV}. The base recipe name and version but without any special package name suffix.files - Files within a directory, which is named
filesand is also alongside the recipe or append file.
Note
If you want the build system to pick up files specified through aSRC_URIstatement from your append file, you need to be sure to extend theFILESPATHvariable by also using theFILESEXTRAPATHSvariable from within your append file.bzr://- Fetches files from a Bazaar revision control repository.git://- Fetches files from a Git revision control repository.osc://- Fetches files from an OSC (OpenSUSE Build service) revision control repository.repo://- Fetches files from a repo (Git) repository.svk://- Fetches files from an SVK revision control repository.http://- Fetches files from the Internet usinghttp.https://- Fetches files from the Internet usinghttps.ftp://- Fetches files from the Internet usingftp.cvs://- Fetches files from a CVS revision control repository.hg://- Fetches files from a Mercurial (hg) revision control repository.p4://- Fetches files from a Perforce (p4) revision control repository.ssh://- Fetches files from a secure shell.svn://- Fetches files from a Subversion (svn) revision control repository.
Standard and recipe-specific options for
SRC_URIexist. Here are standard options:apply- Whether to apply the patch or not. The default action is to apply the patch.striplevel- Which striplevel to use when applying the patch. The default level is 1.patchdir- Specifies the directory in which the patch should be applied. The default is${S}.
Here are options specific to recipes building code from a revision control system:
mindate- Apply the patch only ifSRCDATEis equal to or greater thanmindate.maxdate- Apply the patch only ifSRCDATEis not later thanmindate.minrev- Apply the patch only ifSRCREVis equal to or greater thanminrev.maxrev- Apply the patch only ifSRCREVis not later thanmaxrev.rev- Apply the patch only ifSRCREVis equal torev.notrev- Apply the patch only ifSRCREVis not equal torev.
Here are some additional options worth mentioning:
unpack- Controls whether or not to unpack the file if it is an archive. The default action is to unpack the file.subdir- Places the file (or extracts its contents) into the specified subdirectory ofWORKDIR. This option is useful for unusual tarballs or other archives that do not have their files already in a subdirectory within the archive.name- Specifies a name to be used for association withSRC_URIchecksums when you have more than one file specified inSRC_URI.downloadfilename- Specifies the filename used when storing the downloaded file.
- SRC_URI_OVERRIDES_PACKAGE_ARCH
By default, the OpenEmbedded build system automatically detects whether
SRC_URIcontains files that are machine-specific. If so, the build system automatically changesPACKAGE_ARCH. Setting this variable to "0" disables this behavior.- SRCDATE
The date of the source code used to build the package. This variable applies only if the source was fetched from a Source Code Manager (SCM).
- SRCPV
Returns the version string of the current package. This string is used to help define the value of
PV.The
SRCPVvariable is defined in themeta/conf/bitbake.confconfiguration file in the Source Directory as follows:SRCPV = "${@bb.fetch2.get_srcrev(d)}"Recipes that need to define
PVdo so with the help of theSRCPV. For example, theofonorecipe (ofono_git.bb) located inmeta/recipes-connectivityin the Source Directory definesPVas follows:PV = "0.12-git${SRCPV}"- SRCREV
The revision of the source code used to build the package. This variable applies to Subversion, Git, Mercurial and Bazaar only. Note that if you wish to build a fixed revision and you wish to avoid performing a query on the remote repository every time BitBake parses your recipe, you should specify a
SRCREVthat is a full revision identifier and not just a tag.- SSTATE_DIR
The directory for the shared state cache.
- SSTATE_MIRRORS
Configures the OpenEmbedded build system to search other mirror locations for prebuilt cache data objects before building out the data. This variable works like fetcher
MIRRORSandPREMIRRORSand points to the cache locations to check for the shared objects.You can specify a filesystem directory or a remote URL such as HTTP or FTP. The locations you specify need to contain the shared state cache (sstate-cache) results from previous builds. The sstate-cache you point to can also be from builds on other machines.
If a mirror uses the same structure as
SSTATE_DIR, you need to add "PATH" at the end as shown in the examples below. The build system substitutes the correct path within the directory structure.SSTATE_MIRRORS ?= "\ file://.* http://someserver.tld/share/sstate/PATH \n \ file://.* file:///some/local/dir/sstate/PATH"- STAGING_KERNEL_DIR
The directory with kernel headers that are required to build out-of-tree modules.
- STAMP
Specifies the base path used to create recipe stamp files. The path to an actual stamp file is constructed by evaluating this string and then appending additional information. Currently, the default assignment for
STAMPas set in themeta/conf/bitbake.conffile is:STAMP = "${STAMPS_DIR}/${MULTIMACH_TARGET_SYS}/${PN}/${EXTENDPE}${PV}-${PR}"See
STAMPS_DIR,MULTIMACH_TARGET_SYS,PN,EXTENDPE,PV, andPRfor related variable information.- STAMPS_DIR
Specifies the base directory in which the OpenEmbedded build system places stamps. The default directory is
${TMPDIR}/stamps.- SUMMARY
The short (72 characters or less) summary of the binary package for packaging systems such as
opkg,rpmordpkg. By default,SUMMARYis used to define theDESCRIPTIONvariable ifDESCRIPTIONis not set in the recipe.- SYSLINUX_DEFAULT_CONSOLE
Specifies the kernel boot default console. If you want to use a console other than the default, set this variable in your recipe as follows where "X" is the console number you want to use:
SYSLINUX_DEFAULT_CONSOLE = "console=ttyX"The
syslinuxclass initially sets this variable to null but then checks for a value later.- SYSLINUX_OPTS
Lists additional options to add to the syslinux file. You need to set this variable in your recipe. If you want to list multiple options, separate the options with a semicolon character (
;).The
syslinuxclass uses this variable to create a set of options.- SYSLINUX_SERIAL
Specifies the alternate serial port or turns it off. To turn off serial, set this variable to an empty string in your recipe. The variable's default value is set in the
syslinuxas follows:SYSLINUX_SERIAL ?= "0 115200"The class checks for and uses the variable as needed.
- SYSLINUX_SPLASH
An
.LSSfile used as the background for the VGA boot menu when you are using the boot menu. You need to set this variable in your recipe.The
syslinuxclass checks for this variable and if found, the OpenEmbedded build system installs the splash screen.- SYSLINUX_SERIAL_TTY
Specifies the alternate console=tty... kernel boot argument. The variable's default value is set in the
syslinuxas follows:SYSLINUX_SERIAL_TTY ?= "console=ttyS0,115200"The class checks for and uses the variable as needed.
- SYSROOT_PREPROCESS_FUNCS
A list of functions to execute after files are staged into the sysroot. These functions are usually used to apply additional processing on the staged files, or to stage additional files.
- SYSTEMD_AUTO_ENABLE
For recipes that inherit the
systemdclass, this variable specifies whether the service you have specified inSYSTEMD_SERVICEshould be started automatically or not. By default, the service is enabled to automatically start at boot time. The default setting is in thesystemdclass as follows:SYSTEMD_AUTO_ENABLE ??= "enable"You can disable the service by setting the variable to "disable."
- SYSTEMD_PACKAGES
For recipes that inherit the
systemdclass, this variable locates the systemd unit files when they are not found in the main recipe's package. By default, theSYSTEMD_PACKAGESvariable is set such that the systemd unit files are assumed to reside in the recipes main package:SYSTEMD_PACKAGES ?= "${PN}"If these unit files are not in this recipe's main package, you need to use
SYSTEMD_PACKAGESto list the package or packages in which the build system can find the systemd unit files.- SYSTEMD_SERVICE
For recipes that inherit the
systemdclass, this variable specifies the systemd service name for a package.When you specify this file in your recipe, use a package name override to indicate the package to which the value applies. Here is an example from the connman recipe:
SYSTEMD_SERVICE_${PN} = "connman.service"
T
- T
This variable points to a directory were BitBake places temporary files, which consist mostly of task logs and scripts, when building a particular recipe. The variable is typically set as follows:
T = "${WORKDIR}/temp"The
WORKDIRis the directory into which BitBake unpacks and builds the recipe. The defaultbitbake.conffile sets this variable.The
Tvariable is not to be confused with theTMPDIRvariable, which points to the root of the directory tree where BitBake places the output of an entire build.- TARGET_ARCH
The target machine's architecture. The OpenEmbedded build system supports many architectures. Here is an example list of architectures supported. This list is by no means complete as the architecture is configurable:
arm i586 x86_64 powerpc powerpc64 mips mipsel- TARGET_CFLAGS
Flags passed to the C compiler for the target system. This variable evaluates to the same as
CFLAGS.- TARGET_FPU
Specifies the method for handling FPU code. For FPU-less targets, which include most ARM CPUs, the variable must be set to "soft". If not, the kernel emulation gets used, which results in a performance penalty.
- TARGET_OS
Specifies the target's operating system. The variable can be set to "linux" for
eglibc-based systems and to "linux-uclibc" foruclibc. For ARM/EABI targets, there are also "linux-gnueabi" and "linux-uclibc-gnueabi" values possible.- TCLIBC
Specifies which variant of the GNU standard C library (
libc) to use during the build process. This variable replacesPOKYLIBC, which is no longer supported.You can select
eglibcoruclibc.Note
This release of the Yocto Project does not support theglibcimplementation oflibc.- TCMODE
The toolchain selector. This variable replaces
POKYMODE, which is no longer supported.The
TCMODEvariable selects the external toolchain built using the OpenEmbedded build system or a few supported combinations of the upstream GCC or CodeSourcery Labs toolchain. The variable identifies thetcmode-*files used in themeta/conf/distro/includedirectory, which is found in the Source Directory.By default,
TCMODEis set to "default", which chooses thetcmode-default.incfile. The variable is similar toTCLIBC, which controls the variant of the GNU standard C library (libc) used during the build process:eglibcoruclibc.- TEST_IMAGE
Automatically runs the series of automated tests for images when an image is successfully built.
Note
Currently, there is only support for running these tests under QEMU.These tests are written in Python making use of the
unittestmodule, and the majority of them run commands on the target system overssh. You can set this variable to "1" in yourlocal.conffile in the Build Directory to have the OpenEmbedded build system automatically run these tests after an image successfully builds:TEST_IMAGE = "1"For more information on enabling, running, and writing these tests, see the "Performing Automated Runtime Testing" section in the Yocto Project Development Manual and the "
testimage.bbclass" section.- TEST_QEMUBOOT_TIMEOUT
The time in seconds allowed for an image to boot before automated runtime tests begin to run against an image. The default timeout period to allow the boot process to reach the login prompt is 500 seconds. You can specify a different value in the
local.conffile.For more information on testing images, see the "Performing Automated Runtime Testing" section in the Yocto Project Development Manual.
- TEST_SUITES
An ordered list of tests (modules) to run against an image when performing automated runtime testing.
The OpenEmbedded build system provides a core set of tests that can be used against images.
Note
Currently, there is only support for running these tests under QEMU.Tests include
ping,ssh,dfamong others. You can add your own tests to the list of tests by appendingTEST_SUITESas follows:TEST_SUITES_append = " mytest"Alternatively, you can provide the "auto" option to have all applicable tests run against the image.
TEST_SUITES_append = " auto"Using this option causes the build system to automatically run tests that are applicable to the image. Tests that are not applicable are skipped.
The order in which tests are run is important. Tests that depend on another test must appear later in the list than the test on which they depend. For example, if you append the list of tests with two tests (
test_Aandtest_B) wheretest_Bis dependent ontest_A, then you must order the tests as follows:TEST_SUITES = " test_A test_B"For more information on testing images, see the "Performing Automated Runtime Testing" section in the Yocto Project Development Manual.
- THISDIR
The directory in which the file BitBake is currently parsing is located. Do not manually set this variable.
- TMPDIR
This variable is the base directory the OpenEmbedded build system uses for all build output and intermediate files (other than the shared state cache). By default, the
TMPDIRvariable points totmpwithin the Build Directory.If you want to establish this directory in a location other than the default, you can uncomment and edit the following statement in the
conf/local.conffile in the Source Directory:#TMPDIR = "${TOPDIR}/tmp"- TOOLCHAIN_HOST_TASK
This variable lists packages the OpenEmbedded build system uses when building an SDK, which contains a cross-development environment. The packages specified by this variable are part of the toolchain set that runs on the
SDKMACHINE, and each package should usually have the prefix "nativesdk-". When building an SDK usingbitbake -c populate_sdk <imagename>, a default list of packages is set in this variable, but you can add additional packages to the list.For background information on cross-development toolchains in the Yocto Project development environment, see the "Cross-Development Toolchain Generation" section. For information on setting up a cross-development environment, see the "Installing the ADT and Toolchains" section in the Yocto Project Application Developer's Guide.
- TOOLCHAIN_TARGET_TASK
This variable lists packages the OpenEmbedded build system uses when it creates the target part of an SDK (i.e. the part built for the target hardware), which includes libraries and headers.
For background information on cross-development toolchains in the Yocto Project development environment, see the "Cross-Development Toolchain Generation" section. For information on setting up a cross-development environment, see the "Installing the ADT and Toolchains" section in the Yocto Project Application Developer's Guide.
- TOPDIR
This variable points to the Build Directory. BitBake automatically sets this variable.
- TRANSLATED_TARGET_ARCH
A sanitized version of
TARGET_ARCH. This variable is used where the architecture is needed in a value where underscores are not allowed, for example within package filenames. In this case, dash characters replace any underscore characters used in TARGET_ARCH.Do not edit this variable.
- TUNE_PKGARCH
The package architecture understood by the packaging system to define the architecture, ABI, and tuning of output packages.
U
- UBOOT_CONFIG
Configures the
UBOOT_MACHINEand can also defineIMAGE_FSTYPESfor individual cases.Following is an example from the
meta-fsl-armlayer.UBOOT_CONFIG ??= "sd" UBOOT_CONFIG[sd] = "mx6qsabreauto_config,sdcard" UBOOT_CONFIG[eimnor] = "mx6qsabreauto_eimnor_config" UBOOT_CONFIG[nand] = "mx6qsabreauto_nand_config,ubifs" UBOOT_CONFIG[spinor] = "mx6qsabreauto_spinor_config"In this example, "sd" is selected as the configuration of the possible four for the
UBOOT_MACHINE. The "sd" configuration defines "mx6qsabreauto_config" as the value forUBOOT_MACHINE, while the "sdcard" specifies theIMAGE_FSTYPESto use for the U-boot image.For more information on how the
UBOOT_CONFIGis handled, see theuboot-configclass.- UBOOT_ENTRYPOINT
Specifies the entry point for the U-Boot image. During U-Boot image creation, the
UBOOT_ENTRYPOINTvariable is passed as a command-line parameter to theuboot-mkimageutility.- UBOOT_LOADADDRESS
Specifies the load address for the U-Boot image. During U-Boot image creation, the
UBOOT_LOADADDRESSvariable is passed as a command-line parameter to theuboot-mkimageutility.- UBOOT_LOCALVERSION
Appends a string to the name of the local version of the U-Boot image. For example, assuming the version of the U-Boot image built was "2013.10, the full version string reported by U-Boot would be "2013.10-yocto" given the following statement:
UBOOT_LOCALVERSION = "-yocto"- UBOOT_MACHINE
Specifies the value passed on the
makecommand line when building a U-Boot image. The value indicates the target platform configuration. You typically set this variable from the machine configuration file (i.e.conf/machine/<machine_name>.conf).- UBOOT_MAKE_TARGET
Specifies the target called in the
Makefile. The default target is "all".- UBOOT_SUFFIX
Points to the generated U-Boot extension. For example,
u-boot.sbhas a.sbextension.The default U-Boot extension is
.bin- UBOOT_TARGET
Specifies the target used for building U-Boot. The target is passed directly as part of the "make" command (e.g. SPL and AIS). If you do not specifically set this variable, the OpenEmbedded build process passes and uses "all" for the target during the U-Boot building process.
- USER_CLASSES
A list of classes to globally inherit. These classes are used by the OpenEmbedded build system to enable extra features (e.g.
buildstats,image-mklibs, and so forth).The default list is set in your
local.conffile:USER_CLASSES ?= "buildstats image-mklibs image-prelink"For more information, see
meta-yocto/conf/local.conf.samplein the Source Directory.- USERADD_PACKAGES
When a recipe inherits the
useraddclass, this variable specifies the individual packages within the recipe that require users and/or groups to be added.You must set this variable if the recipe inherits the class. For example, the following enables adding a user for the main package in a recipe:
USERADD_PACKAGES = "${PN}"Note
If follows that if you are going to use theUSERADD_PACKAGESvariable, you need to set one or more of theUSERADD_PARAM,GROUPADD_PARAM, orGROUPMEMS_PARAMvariables.- USERADD_PARAM
When a recipe inherits the
useraddclass, this variable specifies for a package what parameters should be passed to theuseraddcommand if you wish to add a user to the system when the package is installed.Here is an example from the
dbusrecipe:USERADD_PARAM_${PN} = "--system --home ${localstatedir}/lib/dbus \ --no-create-home --shell /bin/false \ --user-group messagebus"For information on the standard Linux shell command
useradd, see http://linux.die.net/man/8/useradd.
W
- WARN_QA
Specifies the quality assurance checks whose failures are reported as warnings by the OpenEmbedded build system. You set this variable in your distribution configuration file. For a list of the checks you can control with this variable, see the "
insane.bbclass" section.- WORKDIR
The pathname of the work directory in which the OpenEmbedded build system builds a recipe. This directory is located within the
TMPDIRdirectory structure and changes as different packages are built.The actual
WORKDIRdirectory depends on several things:For packages that are not dependent on a particular machine,
WORKDIRis defined as follows:${TMPDIR}/work/${PACKAGE_ARCH}-poky-${TARGET_OS}/${PN}/${PV}-${PR}As an example, assume a Source Directory top-level folder name
pokyand a default Build Directory atpoky/build. In this case, the work directory the build system uses to build thev86dpackage is the following:poky/build/tmp/work/qemux86-poky-linux/v86d/01.9-r0For packages that are dependent on a particular machine,
WORKDIRis defined slightly differently:${TMPDIR}/work/${MACHINE}-poky-${TARGET_OS}/${PN}/${PV}-${PR}As an example, again assume a Source Directory top-level folder named
pokyand a default Build Directory atpoky/build. In this case, the work directory the build system uses to build theaclrecipe, which is being built for a MIPS-based device, is the following:poky/build/tmp/work/mips-poky-linux/acl/2.2.51-r2
While you can use most variables in almost any context such as
.conf, .bbclass,
.inc, and .bb files,
some variables are often associated with a particular locality or context.
This chapter describes some common associations.
The following subsections provide lists of variables whose context is configuration: distribution, machine, and local.
This section lists variables whose configuration context is the distribution, or distro.
This section lists variables whose configuration context is the machine.
This section lists variables whose configuration context is the
local configuration through the local.conf
file.
The following subsections provide lists of variables whose context is recipes: required, dependencies, path, and extra build information.
This section lists variables that are required for recipes.
SRC_URI- used in recipes that fetch local or remote files.
This section lists variables that define recipe dependencies.
This section lists variables that define extra build information for recipes.
13.1. | How does Poky differ from OpenEmbedded? |
The term "Poky" refers to the specific reference build system that the Yocto Project provides. Poky is based on OE-Core and BitBake. Thus, the generic term used here for the build system is the "OpenEmbedded build system." Development in the Yocto Project using Poky is closely tied to OpenEmbedded, with changes always being merged to OE-Core or BitBake first before being pulled back into Poky. This practice benefits both projects immediately. | |
13.2. | My development system does not have Python 2.7.3 or greater, which the Yocto Project requires. Can I still use the Yocto Project? |
You can get the required tools on your host development system a couple different ways (i.e. building a tarball or downloading a tarball). See the "Required Git, tar, and Python Versions" section for steps on how to update your build tools. | |
13.3. | How can you claim Poky / OpenEmbedded-Core is stable? |
There are three areas that help with stability;
| |
13.4. | How do I get support for my board added to the Yocto Project? |
Support for an additional board is added by creating a Board Support Package (BSP) layer for it. For more information on how to create a BSP layer, see the "Understanding and Creating Layers" section in the Yocto Project Development Manual and the Yocto Project Board Support Package (BSP) Developer's Guide. Usually, if the board is not completely exotic, adding support in the Yocto Project is fairly straightforward. | |
13.5. | Are there any products built using the OpenEmbedded build system? |
The software running on the Vernier LabQuest is built using the OpenEmbedded build system. See the Vernier LabQuest website for more information. There are a number of pre-production devices using the OpenEmbedded build system and the Yocto Project team announces them as soon as they are released. | |
13.6. | What does the OpenEmbedded build system produce as output? |
Because you can use the same set of recipes to create output of various formats, the output of an OpenEmbedded build depends on how you start it. Usually, the output is a flashable image ready for the target device. | |
13.7. | How do I add my package to the Yocto Project? |
To add a package, you need to create a BitBake recipe. For information on how to add a package, see the section "Writing a Recipe to Add a Package to Your Image" in the Yocto Project Development Manual. | |
13.8. | Do I have to reflash my entire board with a new Yocto Project image when recompiling a package? |
The OpenEmbedded build system can build packages in various
formats such as IPK for OPKG, Debian package
( | |
13.9. | What is GNOME Mobile and what is the difference between GNOME Mobile and GNOME? |
GNOME Mobile is a subset of the GNOME platform targeted at mobile and embedded devices. The main difference between GNOME Mobile and standard GNOME is that desktop-orientated libraries have been removed, along with deprecated libraries, creating a much smaller footprint. | |
13.10. |
I see the error ' |
You are probably running the build on an NTFS filesystem.
Use | |
13.11. |
I see lots of 404 responses for files on
|
Nothing is wrong. The OpenEmbedded build system checks any configured source mirrors before downloading from the upstream sources. The build system does this searching for both source archives and pre-checked out versions of SCM-managed software. These checks help in large installations because it can reduce load on the SCM servers themselves. The address above is one of the default mirrors configured into the build system. Consequently, if an upstream source disappears, the team can place sources there so builds continue to work. | |
13.12. | I have machine-specific data in a package for one machine only but the package is being marked as machine-specific in all cases, how do I prevent this? |
Set | |
13.13. | I'm behind a firewall and need to use a proxy server. How do I do that? |
Most source fetching by the OpenEmbedded build system is done by
http_proxy = http://proxy.yoyodyne.com:18023/
ftp_proxy = http://proxy.yoyodyne.com:18023/
The Yocto Project also includes a
| |
13.14. |
What’s the difference between |
The | |
13.15. | I'm seeing random build failures. Help?! |
If the same build is failing in totally different and random ways, the most likely explanation is:
The OpenEmbedded build system processes a massive amount of data that causes lots of network, disk and CPU activity and is sensitive to even single-bit failures in any of these areas. True random failures have always been traced back to hardware or virtualization issues. | |
13.16. | What do we need to ship for license compliance? |
This is a difficult question and you need to consult your lawyer for the answer for your specific case. It is worth bearing in mind that for GPL compliance, there needs to be enough information shipped to allow someone else to rebuild and produce the same end result you are shipping. This means sharing the source code, any patches applied to it, and also any configuration information about how that package was configured and built. You can find more information on licensing in the "Licensing" and "Maintaining Open Source License Compliance During Your Product's Lifecycle" sections, both of which are in the Yocto Project Development Manual. | |
13.17. | How do I disable the cursor on my touchscreen device? |
You need to create a form factor file as described in the
"Miscellaneous BSP-Specific Recipe Files"
section in the Yocto Project Board Support Packages (BSP)
Developer's Guide.
Set the
HAVE_TOUCHSCREEN=1
| |
13.18. | How do I make sure connected network interfaces are brought up by default? |
The default interfaces file provided by the netbase recipe does not automatically bring up network interfaces. Therefore, you will need to add a BSP-specific netbase that includes an interfaces file. See the "Miscellaneous BSP-Specific Recipe Files" section in the Yocto Project Board Support Packages (BSP) Developer's Guide for information on creating these types of miscellaneous recipe files. For example, add the following files to your layer:
meta-MACHINE/recipes-bsp/netbase/netbase/MACHINE/interfaces
meta-MACHINE/recipes-bsp/netbase/netbase_5.0.bbappend
| |
13.19. | How do I create images with more free space? |
By default, the OpenEmbedded build system creates images that are 1.3 times the size of the populated root filesystem. To affect the image size, you need to set various configurations:
| |
13.20. | Why don't you support directories with spaces in the pathnames? |
The Yocto Project team has tried to do this before but too
many of the tools the OpenEmbedded build system depends on,
such as | |
13.21. | How do I use an external toolchain? |
The toolchain configuration is very flexible and customizable.
It is primarily controlled with the
The default value of
In addition to the toolchain configuration, you also need a
corresponding toolchain recipe file.
This recipe file needs to package up any pre-built objects in
the toolchain such as For information on installing and using cross-development toolchains, see the "Installing the ADT and Toolchains" section in the Yocto Project Application Developer's Guide. For general information on cross-development toolchains, see the "Cross-Development Toolchain Generation" section. | |
13.22. | How does the OpenEmbedded build system obtain source code and will it work behind my firewall or proxy server? |
The way the build system obtains source code is highly configurable. You can setup the build system to get source code in most environments if HTTP transport is available.
When the build system searches for source code, it first
tries the local download directory.
If that location fails, Poky tries
Assuming your distribution is "poky", the OpenEmbedded build
system uses the Yocto Project source
As an example, you could add a specific server for the
build system to attempt before any others by adding something
like the following to the
PREMIRRORS_prepend = "\
git://.*/.* http://www.yoctoproject.org/sources/ \n \
ftp://.*/.* http://www.yoctoproject.org/sources/ \n \
http://.*/.* http://www.yoctoproject.org/sources/ \n \
https://.*/.* http://www.yoctoproject.org/sources/ \n"
These changes cause the build system to intercept Git, FTP,
HTTP, and HTTPS requests and direct them to the
Aside from the previous technique, these options also exist:
BB_NO_NETWORK = "1"
This statement tells BitBake to issue an error instead of trying to access the Internet. This technique is useful if you want to ensure code builds only from local sources. Here is another technique:
BB_FETCH_PREMIRRORONLY = "1"
This statement limits the build system to pulling source
from the Here is another technique:
BB_GENERATE_MIRROR_TARBALLS = "1"
This statement tells the build system to generate mirror tarballs. This technique is useful if you want to create a mirror server. If not, however, the technique can simply waste time during the build.
Finally, consider an example where you are behind an
HTTP-only firewall.
You could make the following changes to the
PREMIRRORS_prepend = "\
ftp://.*/.* http://www.yoctoproject.org/sources/ \n \
http://.*/.* http://www.yoctoproject.org/sources/ \n \
https://.*/.* http://www.yoctoproject.org/sources/ \n"
BB_FETCH_PREMIRRORONLY = "1"
These changes would cause the build system to successfully
fetch source over HTTP and any network accesses to anything
other than the
The build system also honors the standard shell environment
variables | |
13.23. | Can I get rid of build output so I can start over? |
Yes - you can easily do this.
When you use BitBake to build an image, all the build output
goes into the directory created when you run the
build environment setup script (i.e.
Within the Build Directory, is the |
The Yocto Project team is happy for people to experiment with the Yocto Project. A number of places exist to find help if you run into difficulties or find bugs. To find out how to download source code, see the "Yocto Project Release" section in the Yocto Project Development Manual.
If you find problems with the Yocto Project, you should report them using the Bugzilla application at http://bugzilla.yoctoproject.org.
A number of mailing lists maintained by the Yocto Project exist as well as related OpenEmbedded mailing lists for discussion, patch submission and announcements. To subscribe to one of the following mailing lists, click on the appropriate URL in the following list and follow the instructions:
http://lists.yoctoproject.org/listinfo/yocto - General Yocto Project discussion mailing list.
http://lists.openembedded.org/mailman/listinfo/openembedded-core - Discussion mailing list about OpenEmbedded-Core (the core metadata).
http://lists.openembedded.org/mailman/listinfo/openembedded-devel - Discussion mailing list about OpenEmbedded.
http://lists.openembedded.org/mailman/listinfo/bitbake-devel - Discussion mailing list about the BitBake build tool.
http://lists.yoctoproject.org/listinfo/poky - Discussion mailing list about Poky.
http://lists.yoctoproject.org/listinfo/yocto-announce - Mailing list to receive official Yocto Project release and milestone announcements.
Two IRC channels on freenode are available for the Yocto Project and Poky discussions:
#yocto#poky
Here is a list of resources you will find helpful:
The Yocto Project website: The home site for the Yocto Project.
Intel Corporation: The company who acquired OpenedHand in 2008 and began development on the Yocto Project.
OpenEmbedded: The upstream, generic, embedded distribution used as the basis for the build system in the Yocto Project. Poky derives from and contributes back to the OpenEmbedded project.
BitBake: The tool used to process metadata.
BitBake User Manual: A comprehensive guide to the BitBake tool. You can find the BitBake User Manual in the
bitbake/doc/manualdirectory, which is found in the Source Directory.QEMU: An open source machine emulator and virtualizer.
The Yocto Project gladly accepts contributions. You can submit changes to the project either by creating and sending pull requests, or by submitting patches through email. For information on how to do both as well as information on how to find out who is the maintainer for areas of code, see the "How to Submit a Change" section in the Yocto Project Development Manual.